
在过去的几年中,自然语言处理(NLP)领域因基于注意力的方法的出现而发生了革命性变化。由于它们在捕获单词之间的远程依存关系方面具有出色的功能以及其可扩展的训练能力,因此诸如Transformer模型之类的自注意力体系结构代表了涵盖各种语言任务的当前最新技术水平,其中包括机器翻译,问答和自回归词生成等。
[1]提出了一种无卷积的视频分类方法,该方法专门基于名为“ TimeSformer”的空间和时间上的自注意力而构建,通过直接从一系列帧级块中启用时空特征学习,将标准的Transformer体系结构应用于视频。
TimeSformer已在多个具有挑战性的行为识别数据集上取得了SOTA结果。本文使用的数据集包括Kinetics-400,Kinetics-600,Something-Something-v2,Diving-48和HowTo100M数据集。与现代3D卷积神经网络相比,TimeSformer训练的速度提高了3倍,推理时间仅为后者的十分之一。
此外,TimeSformer的可扩展性使其可以在更长的视频剪辑上训练更大的模型。当前的3D CNN最多只能处理几秒钟的剪辑,而使用TimeSformer,它甚至可以在几分钟的剪辑中使用。它为未来的AI系统了解更复杂的人类行为铺平了道路。
传统的视频分类模型使用3D卷积核来提取特征,而TimeSformer基于Transformer中的自注意力机制,这使它可以捕获整个视频的时间和空间依赖性。该模型将输入视频视为从每一帧中提取的图像小块(patches)的时空序列,并将其应用到视频中。这种用法与NLP中的用法非常相似。NLP的Transformer通过将每个单词与句子中的所有单词进行比较来推断每个单词的意思。这种方法被称为自注意力机制。该模型通过将每个图像块的语义与视频中其他图像块的语义进行比较,得到每个图像块的语义,从而可以同时捕获相邻图像块之间的局部依赖关系和远程图像块之间的全局依赖关系。
众所周知,Transformer的训练非常消耗资源。为了缓解此问题,TimeSformer通过两种方式减少了计算量:
- 将视频分解为一系列不相交的图像块的子集;一种独特的自注意力方法可避免所有图像块序列之间的复杂计算。
- TimeSformer采用了一种称为时间和空间分离注意机制的技术(时空分离注意力)。在时间注意力上,每个图像块仅关注在剩余帧的对应位置处提取的图像块。在空间注意力上,该图像块仅关注相同帧的提取图像块。作者还发现,单独的时空注意机制要好于共同使用的时空注意机制。
这项工作基于图像模型Vision Transformer(ViT),该模型将自注意力机制从图像空间扩展到时空3D空间。
所研究的视频自我注意块的说明。每个注意层在特定的帧级块的时空邻域上实现自我注意(邻域可视化见图2)。使用残差连接来聚合来自每个块内不同注意层的信息。在每个块的末尾应用一个1层线性层的MLP。最终的模型是通过重复地将这些块堆叠在一起来构建的。来源[1]
你可以在下图中清楚地看到注意力机制是如何工作的:

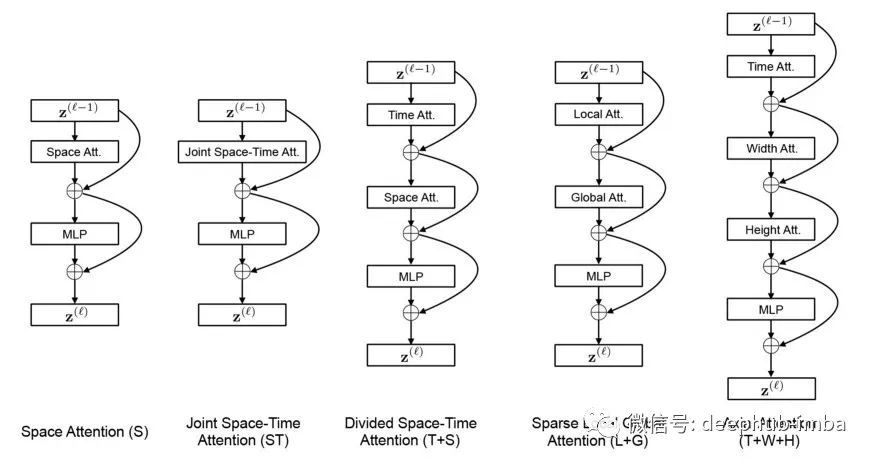
五种时空自注意力图式的可视化。每个视频片段都被视为大小为16 × 16像素的帧级片段序列。为了说明问题,我们用蓝色表示查询块,用非蓝色表示每个方案下的自注意力的时空邻域。没有颜色的小块不用于计算蓝色小块的自注意力。方案中的多种颜色表示沿不同维度(例如,(T+S)的空间和时间)或不同邻近(例如,(L+G))分别应用的注意力。这里计算视频剪辑中的每个块的自注意力,也就是说,每个块都作为一个查询。我们还注意到,虽然注意力模式只显示在两个相邻的帧上,但它以同样的方式扩展到clip.Source[1]的所有帧
图中,蓝色的图像块是查询的图像块,剩余颜色的图像块是每种自我注意策略使用的图像块,没有颜色的图像块不被使用。在该策略中,存在多种颜色的图像块,这意味着注意机制是分开进行的,如T+S,表示T先,S后,L + G是相同的。这里,图中只显示了三帧,但它们适用于整个序列。
通过将输入图像分块,论文研究了五种不同的注意力机制:
- 空间注意力策略:只取同帧图像块。
- 时空共同注意力策略(spatial -temporal common attention mechanism, ST):取所有帧的所有图像。
- 时空分离注意力策略(T+S):首先对同一帧中所有图像块进行自注意力,然后对不同帧中相应位置的图像块再进行自注意力。
- 稀疏全局注意力策略(L + G):第一次使用邻H / 2和W / 2各帧图像块来计算本地的注意力,然后用2图像块空间步长,在整个序列中计算注意力,这可以被视为一种快逼近全局时空的注意力机制。
- 轴向注意力策略(T+W+H):首先在时间维度上执行自注意力,然后在相同纵坐标的图像块上执行自注意力,最后在相同横坐标的图像块上执行自注意力
在K400和SSv2数据集上研究了五种注意力策略,表中报告了视频级别的分类准确率。其中,分离时空的注意力是最好的。
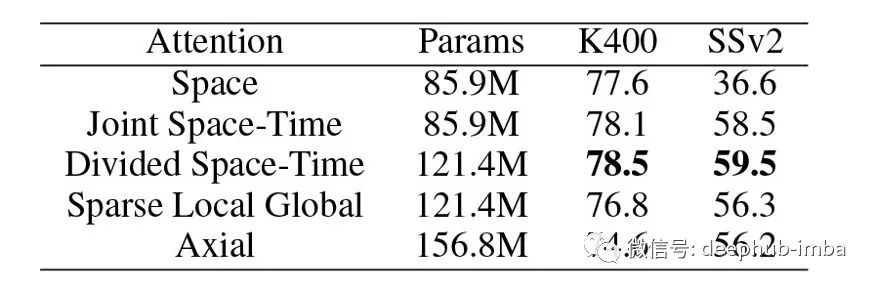
从表中可以看出,对于K400数据集,最好只使用空间信息对其进行分类。这些是前人的研究也发现,但对于SSv2数据集,仅利用空间信息的效果非常差。这说明了建模时间的重要性。
当每个图像块的大小不变时,图像越大,图像块的数量就越大。同时帧数越多,投入注意力机制的数据就越多。论文作者还研究了这些对最终成绩的影响,结果是随着输入信息的丰富,效果的改善非常明显。
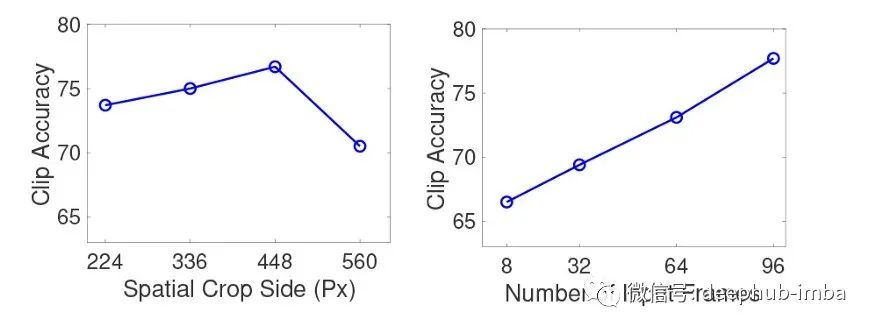
由于视频内存的限制,没有办法测试超过96帧的视频剪辑。作者说这是一个很大的改进,因为目前的卷积模型,输入一般限制在8-32帧。
TimeSformer在几个主要的动作识别基准上取得了最先进的结果,包括kinetic -400和kinetic -600的最佳精度。此外,与其他体系结构相比,论文所提出的模型训练速度更快,测试时间效率更高。
论文地址 :arXiv:2102.05095 Gedas Bertasius, Heng Wang, Lorenzo Torresani,Is Space-Time Attention All You Need for Video Understanding?