
在之前配置Redis集群:Docker容器实现Redis Cluster(集群)模式 哈希槽分区进行亿级数据存储的文章中有一段:
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
这篇来好好讲讲其中这个--net host是干什么的。
首先这一节的命令并不会特别的多,但是不能不懂,否则之后的compose容器编排和网络设计可能会存在一定的问题。
是什么
咱们不妨先回来来看看VMware的网络模式

桥接、NAT、仅主机、用户自定义。这里就不重复地说这些有啥区别了,但是咱们这节要说的docker网络模式与之有一定的相似之处。
一、Docker不启动时默认的网络情况

这里先把Docker停掉了,然后咱们ifconfig看一眼:
ifconfig

ens33不用多说了,lo为回环。这里可能还会有一个virbr0,在CentOS7的安装过程中如果有选择相关虚拟化的的服务安装系统后,启动网卡时会发现有一个以网桥连接的私网地址的virbr0网卡(virbr0网卡:它还有一个固定的默认IP地址192.168.122.1),是做虚拟机网桥的使用的,其作用是为连接其上的虚机网卡提供 NAT访问外网的功能。当然你也可以选择把它删了,命令如下:
yum remove libvirt-libs.x86_64
二、Docker启动时的网络情况
ifconfig

这时候docker0这个虚拟网桥就冒出来了。 这里有一点可以稍微一下它的ip是172.17.0.1但是它的掩码是255.255.0.0也就是16。
能干什么
容器间的互联和通信以及端口映射
容器IP变动时可以通过服务名直接进行网络通信而不受到影响
常用基本命令
一、ls
docker network ls
最基本的查看,这里可以看到有 bridge host none 。

1.--no-trunc
docker network ls --no-trunc
显示完整的网络ID

2.DRIVER
docker network ls --filter driver=bridge
驱动程序过滤器根据驱动程序匹配网络。以下示例将网络与桥驱动程序相匹配

3.ID
docker network ls --filter id=c2057140d512d3365c463be95ac63b2ca1279d4a6bbb653e228c0a04fbe9b8ef
匹配网络ID的全部或部分。需要注意以下自己的ID

4.format
docker network ls --format "{{.ID}}: {{.Driver}}"
这里使用不带标题的模板,并输出用冒号分隔所有网络的ID和驱动程序条目:

二、create
docker network create van
顾名思义:创建。这里注意,它默认为bridge模式。

三、rm
删除
docker network rm van

四、inspect
docker network inspect bridge
查看网络数据源

这里咱们可以往下看看:

这也就是docker的网桥为啥会叫docker0的原因。
五、connect
用于将容器连接到网络。可以按名称或ID连接容器。 一旦连接,容器可以与同一网络中的其他容器通信。
1.将正在运行的容器连接到网络
docker network connect 网络名 正在运行的容器
2、启动时将容器连接到网络
docker run -itd --network=网络名 即将启动的容器
3.指定容器的IP地址
docker network connect --ip 10.10.10.10 网络名 容器
六、prune
docker network prune
删除所有无用的网络

七、disconnect
docker network disconnect 网络名 容器
强制断开容器的网络连接
网络模式
这里先简单的看一下有哪几种,具体实操在下面。
一、bridge
--network bridge
#没有进行特殊申明的话默认为docker0
为每一个容器分配、设置IP等,并将容器连接到docker0的虚拟网桥。若没有特别申明,则为默认自带一个IP以及网络设置。(一人一个)
二、host
--network host
容器不会虚拟出自己的网卡、IP等,而是使用宿主机的IP和端口。(多人一个)
三、none
--network none
容器有自己独立的Network namespace,但是没有进行任何的相关配置。(有,但是空的)
四、container
--network container:[容器名或容器ID]
新创建的容器不会创建自己的网卡,没有自己的IP,也不会进行相应的配置。而是和一个指定的容器共享IP端口范围等。(自己没有,用别人的)
五、自定义
具体请看文章尾部。
底层IP和容器映射变化
首先我们起一个Ubuntu容器
docker run -it --name u1 ubuntu bash
再起一个,注意这里退出启动时不要exit或者ctrl+D,不然容器也会停止运行,可以用ctrl+P+Q不停止运行并退出。
docker run -it --name u2 ubuntu bash

ps看一眼,以确保都运行成功
docker ps

接下来我们用inspect看看每个容器自己内部的情况:
docker inspect u1
运行效果如下(内容过多,不全部复制了):
[root@vanqiyeah /]# docker inspect u1
[
...以上内容过多,此处省略...
"Networks": {
"bridge": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"NetworkID": "c2057140d512d3365c463be95ac63b2ca1279d4a6bbb653e228c0a04fbe9b8ef",
"EndpointID": "d294c92cb10933beae5e1b557dc9f2a6b2400c875e3af6014eac70a26c982c6f",
"Gateway": "172.17.0.1",
"IPAddress": "172.17.0.2",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "02:42:ac:11:00:02",
"DriverOpts": null
}
}
}
}
]
这里可以看到我们u1默认是bridge,它的IP是172.17.0.2,它的网关是172.17.0.1。接着来看看u2的网络配置:
docker inspect u2 | tail -n 20
内容如下:
[root@vanqiyeah /]# docker inspect u2 | tail -n 20
"Networks": {
"bridge": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"NetworkID": "c2057140d512d3365c463be95ac63b2ca1279d4a6bbb653e228c0a04fbe9b8ef",
"EndpointID": "b124ac94a44f1130aa0d9a105ae775e0ebddb58cdac99c2389a6243ab20811c5",
"Gateway": "172.17.0.1",
"IPAddress": "172.17.0.3",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "02:42:ac:11:00:03",
"DriverOpts": null
}
}
}
}
]
可以看到默认的依旧是bridge,IP地址是172.17.0.3,网关依旧是172.17.0.1。这就是上面所谓的“一人一个”。
接着我们把u2给杀了,然后新起一个u3:
docker rm -f u2
docker run -it --name u3 ubuntu bash
来看看u3的网络配置:
docker inspect u3 | tail -n 20
[root@vanqiyeah /]# docker inspect u3 | tail -n 20
"Networks": {
"bridge": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"NetworkID": "c2057140d512d3365c463be95ac63b2ca1279d4a6bbb653e228c0a04fbe9b8ef",
"EndpointID": "a3c5c9aa670af950c0aede6ce4e048c05158e93fadf02fd4f28eb27a7937718a",
"Gateway": "172.17.0.1",
"IPAddress": "172.17.0.3",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "02:42:ac:11:00:03",
"DriverOpts": null
}
}
}
}
]
这里可以看到,在u2死后,它之前所使用的IP地址被释放,然后被分配给了之后的u3。随着容器实例的变化,其IP也是会变动的。这也说明了一个问题,当底层的IP自行变动之后,咱们还能照旧正常运行之前的容器或服务吗?所以之后必须要对服务进行规划,说白了就是让其通过服务来查找,而不是通过IP。
bridge
我们来看一眼bridge模式:
docker network inspect bridge

[
{
"Name": "bridge",
"Id": "c2057140d512d3365c463be95ac63b2ca1279d4a6bbb653e228c0a04fbe9b8ef",
"Created": "2022-08-05T14:36:53.233199354+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.17.0.0/16",
"Gateway": "172.17.0.1"
}
]
},
可以看到它的网络模式就是bridge,它的范围是本地,驱动模式也是bridge。
Docker服务默认会创建一个 docker0网桥(其上有一个 docker0 内部接口),该桥接网络的名称为docker0,它在内核层连通了其他的物理或虚拟网卡,这就将所有容器和本地主机都放到同一个物理网络。Docker默认指定了 docker0 接口 的 IP 地址和子网掩码,让主机和容器之间可以通过网桥相互通信。可以看一眼默认的网桥名:
docker network inspect bridge | grep name

可以看到默认的网桥名字就叫docker0。
下面来讲讲理论:

1 Docker使用Linux桥接,在宿主机虚拟一个Docker容器网桥(docker0),Docker启动一个容器时会根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP,同时Docker网桥是每个容器的默认网关。因为在同一宿主机内的容器都接入同一个网桥,这样容器之间就能够通过容器的Container-IP直接通信。
2 docker run 的时候,没有指定network的话默认使用的网桥模式就是bridge,使用的就是docker0。在宿主机ifconfig,就可以看到docker0和自己create的network(后面讲)eth0,eth1,eth2……代表网卡一,网卡二,网卡三……,lo代表127.0.0.1,即localhost,inet addr用来表示网卡的IP地址
3 网桥docker0创建一对对等虚拟设备接口一个叫veth,另一个叫eth0,成对匹配。
3.1 整个宿主机的网桥模式都是docker0,类似一个交换机有一堆接口,每个接口叫veth,在本地主机和容器内分别创建一个虚拟接口,并让他们彼此联通(这样一对接口叫veth pair);
3.2 每个容器实例内部也有一块网卡,每个接口叫eth0;
3.3 docker0上面的每个veth匹配某个容器实例内部的eth0,两两配对,一一匹配。
通过上述,将宿主机上的所有容器都连接到这个内部网络上,两个容器在同一个网络下,会从这个网关下各自拿到分配的ip,此时两个容器的网络是互通的。
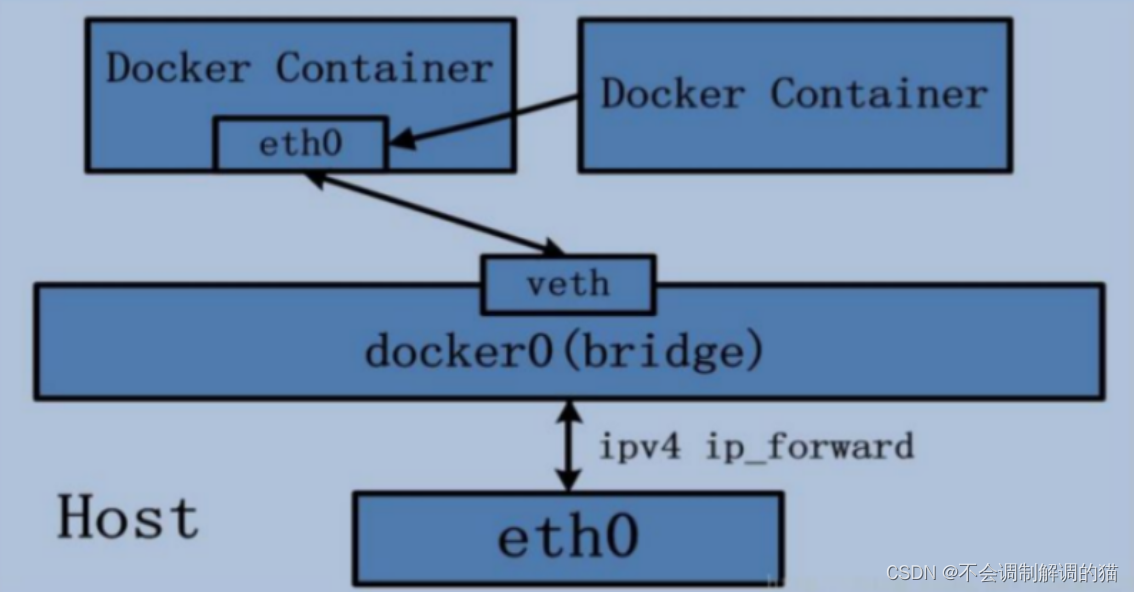
说白了, docker0 bridge 就相当于一个交换机。它用于把宿主机的ens33网卡和上面的容器虚拟网卡进行连接,让其可以进行联网通信。而docker0的IP地址就是上层容器的网关。上图中红框所标出的就类似于进行连接的RJ45水晶头。eth0就相当于是容器中虚拟出的网卡接口,veth相当于交换机上的接口。接下来咱们去容器实例中去看看他们的对印关系:
一、举例
运行以下两行代码,起两个猫猫实例:
docker run -d -p 8081:8080 --name tomcat81 billygoo/tomcat8-jdk8
docker run -d -p 8082:8080 --name tomcat82 billygoo/tomcat8-jdk8
别忘了ps查看确定一下:
docker ps

咱们之前有说过,每个容器在bridge起来后都会自带一个IP地址来跟我们的docker0进行通信。咱们在宿主机上ip add看一眼:
ip add

这里的第一行veth前面有一个18,而结尾的编号是17,这两个数字要记住(蓝框)。
可以看到多了两行veth,而这个veth是不是和咱们上面理论那张图里的所示一致。 接着我们进容器看看:
docker exec -it tomcat81 bash

然后在容器内查看一眼网络:
ip add

可以看看这里的eth0(这个名字是不是也跟上面理论图中的一致呀),咱们可以看到它的编号为17和18,是不是和上面在宿主机中查看的ip add一致,所以说他们是靠这样相互联通的。
咱们再到另外一个容器实例中去看看:
docker exec -it tomcat82 bash
ip add

可以看到这里的编号为19,20和上面宿主机中ip add的20,19相互对应(红框)。
host
直接使用宿主机的 IP 地址与外界进行通信,不再需要额外进行NAT 转换。

容器将不会获得一个独立的Network Namespace(图中左上角), 而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡而是使用宿主机的IP和端口。
一、警告举例
docker run -d -p 8083:8080 --network host --name tomcat83 billygoo/tomcat8-jdk8
这里的--network host就是用于添加host网络模式。效果如下:

可以正常运行,但是报了一个警告。
WARNING: Published ports are discarded when using host network mode
警告:使用主机网络模式时,将丢弃已发布的端口
当然它只是一个警告,容器还是正常起起来了,可以ps看一眼:
docker ps

但是我们可以看到,它在端口映射那一块是空的。原因是docker启动时指定--network=host或-net=host,如果还指定了-p映射端口,那这个时候就会有此警告,并且通过-p设置的参数将不会起到任何作用,端口号会以主机端口号为主,重复时则递增。解决的方法就是使用其它的网络模式(但这里为了演示,没办法),或者直接将其无视就可以了。
二、正确举例
把上述的83给删掉,然后重新起一个:
docker rm -f tomcat83

docker run -d --network host --name tomcat83 billygoo/tomcat8-jdk8

启动时不要添加端口映射,这样会不会报出警告了。 咱们去看一眼它容器的网络配置:
docker inspect tomcat83 | tail -n 20

[root@vanqiyeah /]# docker inspect tomcat83 | tail -n 20
"Networks": {
"host": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"NetworkID": "85809845abf6c31672809da0a424bd9823e3f598273ab5e36b6d3ded11c9e9f9",
"EndpointID": "e1a54b580efa58e681b06881cfc9903710616b33f86fa9590f81a8db0976ee27",
"Gateway": "",
"IPAddress": "",
"IPPrefixLen": 0,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "",
"DriverOpts": null
}
}
}
}
]
可以看到网络是host,由于是跟复用宿主机的网络,所以这里没有自己的网络的IP地址和网关。
看一眼宿主机的网络:
ip add
[root@vanqiyeah /]# ip add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:60:2d:8b brd ff:ff:ff:ff:ff:ff
inet 192.168.150.30/24 brd 192.168.150.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.150.33/24 brd 192.168.150.255 scope global secondary noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::a097:42cb:3b1e:db59/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: virbr0: <BROADCAST,MULTICAST> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 52:54:00:6d:e5:d5 brd ff:ff:ff:ff:ff:ff
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN group default qlen 1000
link/ether 52:54:00:6d:e5:d5 brd ff:ff:ff:ff:ff:ff
5: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:3c:fa:17:bc brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:3cff:fefa:17bc/64 scope link
valid_lft forever preferred_lft forever
18: veth6672af6@if17: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 72:2e:b2:d6:b1:32 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::702e:b2ff:fed6:b132/64 scope link
valid_lft forever preferred_lft forever
20: veth1d34a39@if19: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether ae:0c:42:84:5c:1d brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::ac0c:42ff:fe84:5c1d/64 scope link
valid_lft forever preferred_lft forever
[root@vanqiyeah /]#
然后进去容器再看一眼host模式下的网络:
docker exec -it tomcat83 bash
ip add
内容如下:
root@vanqiyeah:/usr/local/tomcat# ip add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:60:2d:8b brd ff:ff:ff:ff:ff:ff
inet 192.168.150.30/24 brd 192.168.150.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.150.33/24 brd 192.168.150.255 scope global secondary noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::a097:42cb:3b1e:db59/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: virbr0: <BROADCAST,MULTICAST> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 52:54:00:6d:e5:d5 brd ff:ff:ff:ff:ff:ff
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN group default qlen 1000
link/ether 52:54:00:6d:e5:d5 brd ff:ff:ff:ff:ff:ff
5: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:3c:fa:17:bc brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:3cff:fefa:17bc/64 scope link
valid_lft forever preferred_lft forever
18: veth6672af6@if17: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 72:2e:b2:d6:b1:32 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::702e:b2ff:fed6:b132/64 scope link
valid_lft forever preferred_lft forever
20: veth1d34a39@if19: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether ae:0c:42:84:5c:1d brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::ac0c:42ff:fe84:5c1d/64 scope link
valid_lft forever preferred_lft forever
可以看出来它跟宿主机的几乎一致,因为他是完全复用宿主机的网络。它没有想bridge那样的配对。
咱们再回来看一眼,既然它没有映射的端口,那么要怎么捉住这个tomcat容器的猫猫呢。

答案是直接访问默认的8080:

成功捉住了猫猫。
none
直接禁用了网络功能,没有IP地址,没有网关,没有相关配置,有的是有一个lo回环地址127.0.0.1
起一个看看:
docker run -d -p 8084:8080 --network none --name tomcat84 billygoo/tomcat8-jdk8

--network none表示启用none模式,咱们继续看:
docker inspect tomcat84 | tail -n 20
[root@vanqiyeah /]# docker inspect tomcat84 | tail -n 20
"Networks": {
"none": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"NetworkID": "d6fc784e9bde04853f7a3aa310810bc225596a65ec9f42bf4ff336937398cdbf",
"EndpointID": "a68571122249589115da401a4f6897563ca529fed39fdb452c6f10a73892978e",
"Gateway": "",
"IPAddress": "",
"IPPrefixLen": 0,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "",
"DriverOpts": null
}
}
}
}
]
模式为none,没有IP,没有网关,咱们进去容器里面看看ip add:
docker exec -it tomcat84 bash
ip add

可以看到除了lo这个回环以外啥都没有。
container
新建的容器和已经存在的一个容器共享一个网络IP配置而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的IP,而是和一个指定的容器共享IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。
说白了就是在同一层楼上面住了两家人,他们的房子相互分开,但是两家用同一根水管来用水。
一、错误举例
开始起容器,一共两个:
docker run -d -p 8085:8080 --name tomcat85 billygoo/tomcat8-jdk8
docker run -d -p 8086:8080 --network container:tomcat85 --name tomcat86 billygoo/tomcat8-jdk8
发现报错:

docker: Error response from daemon: conflicting options: port publishing and the container type network mode.
docker:来自守护进程的错误响应:选项冲突:端口发布和容器类型网络模式。
docker rm -f tomcat85

原因是于tomcat86和tomcat85公用同一个IP同一个端口(都要使用8080),导致端口冲突,本次举例用tomcat演示不合适(这里直接删了)。所以下面咱们换个镜像继续:
二、正确举例
咱们换一个Alpine来继续:
Alpine Linux 是一款独立的、非商业的通用 Linux 发行版,专为追求安全性、简单性和资源效率的用户而设计。 可能很多人没听说过这个 Linux 发行版本,但是经常用 Docker 的朋友可能都用过,因为他小,简单,安全而著称,所以作为基础镜像是非常好的一个选择,可谓是麻雀虽小但五脏俱全,镜像非常小巧,不到6M的大小,所以特别适合容器打包。
直接run(注意这里是/bin/sh):
docker run -it --name alpine1 alpine /bin/sh
因为它真的很小,所以laq拉取应该会很快

再起一个:
docker run -it --network container:alpine1 --name alpine2 alpine /bin/s

接着我们去 alpine1 用ip add查看一下:
ip add
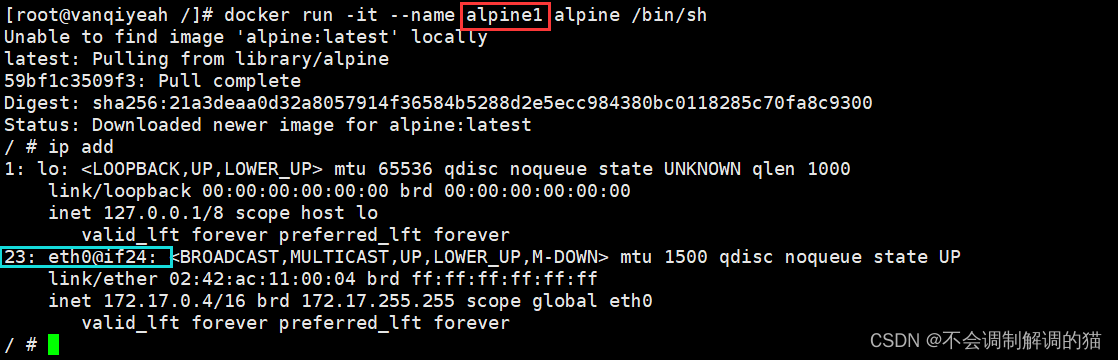
直接看这里的编号,一个23一个24。接着我们去 alpine2 看看:

可以看到这两个容器共用同一个网络和IP。
这时候我们来看看,如果我们把1给宕掉,那么2的网络会怎么样:
exit
#ctrl + D

这里已经把1给宕掉了,接着去看看2的网络状况:
ip add

很明显依赖关系被解除,2的网络也自然断开了。
自定义网络
这里需要简单的提一嘴docker link,
可以去官网看一眼:Legacy container links | Docker Documentation

官网上有提到,在以后的版本中有可能被移除,也就是说这玩意儿已经过时了。那么过时了之后怎么用什么呢,答案是用自定义的网络。
一、使用自定义网络之前
咱们继续使用以下之前的tomcat81和82以用作演示。
因为之前已经起过了,所以这里直接start即可,要是没去停它那就直接用:
docker start tomcat81
docker start tomcat82
这里的两个容器还是之前的bridge模式,咱们用exec进去:
docker exec -it tomcat81 bash
docker exec -it tomcat82 bash

接下来我们看看用IP地址是否能Ping通,再看看通过网络名是否能Ping通:
先来看看各自的IP地址:
ip add | grep inet

然后开Ping:

可以互相Ping通,但是我们之前有提到过,IP地址这东西是会动态变更的,所以实际使用时应该根据服务名来调用。我们来Ping服务名看看:

很明显的Ping不通
ping: tomcat: Name or service not known
ping:tomcat:名称或服务未知
在不实用自定义网络时,如果你把IP地址写死,那么是可以联通的,但是无法根据服务名来进行联通。而在正式的网络规划里面,大多数情况下是不允许把IP地址写死的,或者说这种写死的情况很少,所以我们必须要通过服务名来进行联通和访问。
二、使用自定义网络之后
自定义网络新建时默认依旧是bridge模式,我们先来新建一个van♂的网络:
docker network create van_network
可以看到它的驱动模式默认还是bridge。
接下来要将新建的容器实例加入到新建的网络上,先把之前的删了:
docker rm -f tomcat81
docker rm -f tomcat82

然后开始起新的:
docker run -d -p 8081:8080 --network van_network --name tomcat81 billygoo/tomcat8-jdk8
docker run -d -p 8082:8080 --network van_network --name tomcat82 billygoo/tomcat8-jdk8
这里要注意自己定义的网络名

然后咱们进去看看:
docker exec -it tomcat81 bash
ip add
81:

82:

可以看到他俩在同一网段内,现在我们来Ping服务名看看:

都可以互相Ping通。这里就解决了使用服务名来Ping的问题。最终结论:
自定义网络本身就维护好了主机名和IP的对应关系,也就是IP和域名都能联通
版权归原作者 不会调制解调的猫 所有, 如有侵权,请联系我们删除。