
文章目录
一.基本概念
官网介绍
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计为在所有常见的集群环境中运行,以内存中的速度和任何规模执行计算。
1.无限流有一个开始,但没有定义的结束。它们不会在生成数据时终止并提供数据。必须连续处理无限流,即事件必须在摄取后立即处理。不可能等待所有输入数据到达,因为输入是无限的,并且在任何时间点都不会完成。处理无界数据通常需要按特定顺序(例如事件发生的顺序)引入事件,以便能够推断结果完整性。(即实时数据)
2.有界流具有定义的开始和结束。可以通过在执行任何计算之前引入所有数据来处理有界流。处理有界流不需要有序引入,因为始终可以对有界数据集进行排序。有界流的处理也称为批处理。(即存储的数据)
有状态流处-flink处理流程
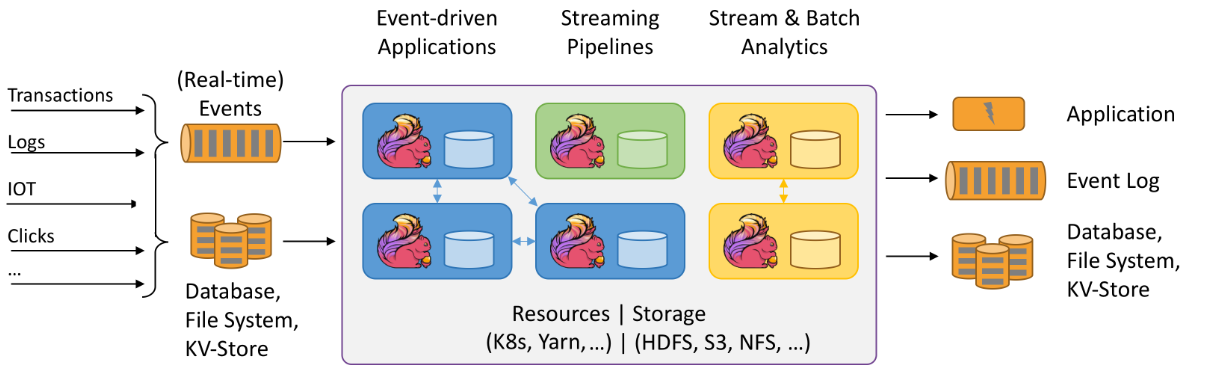
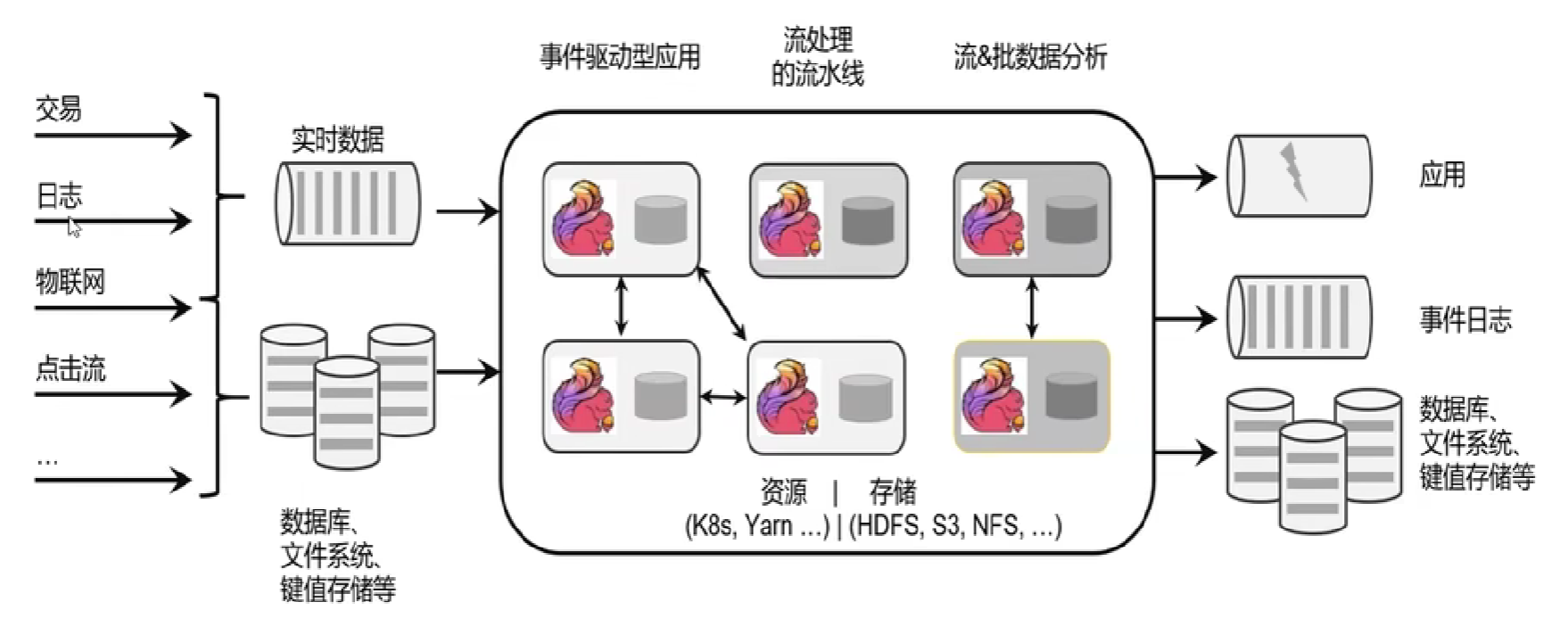
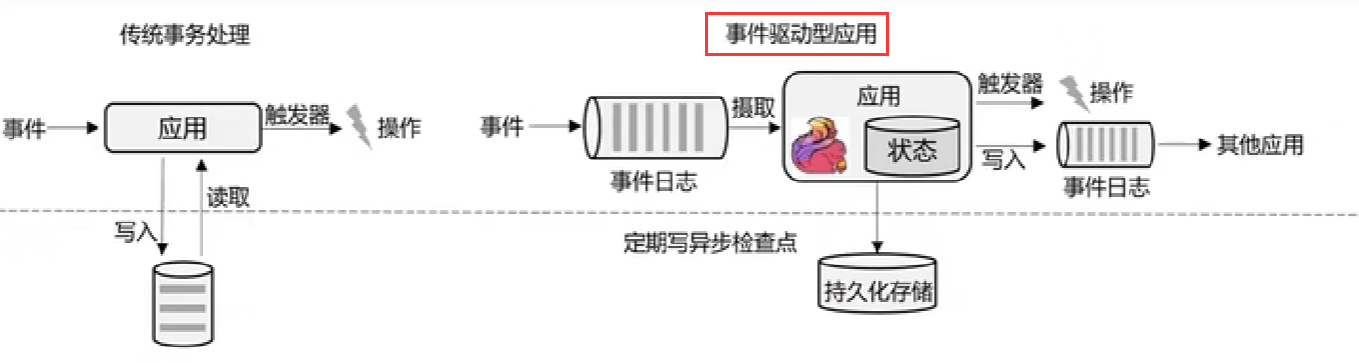
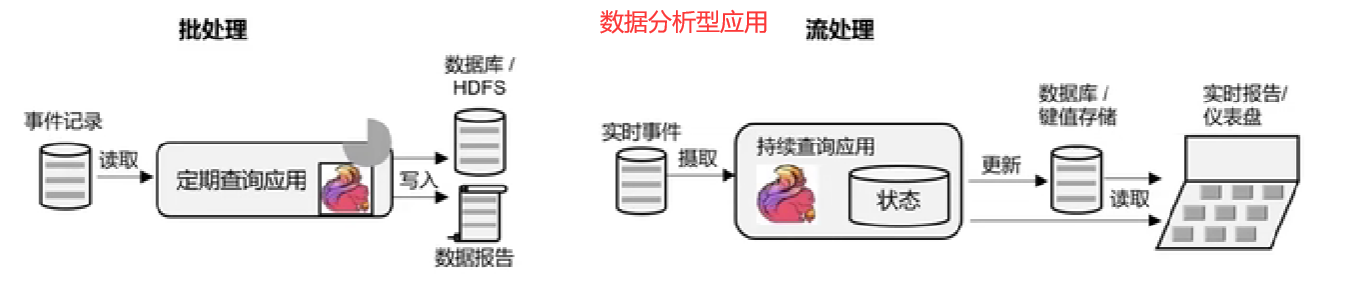
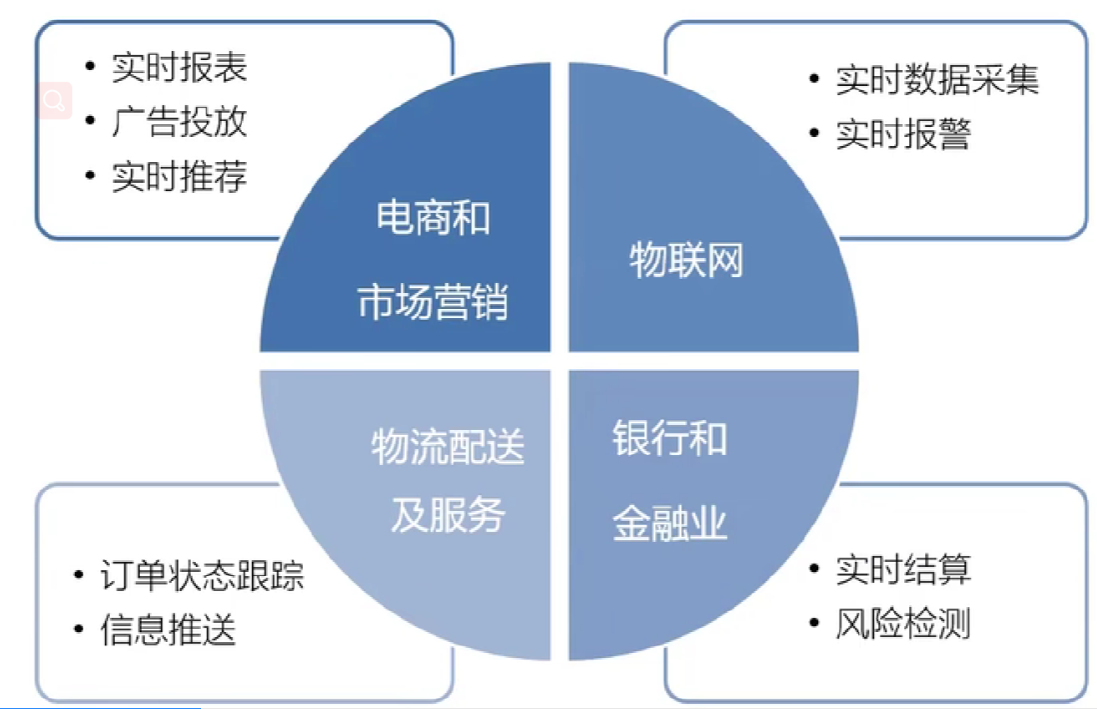
较为合适的应用场景
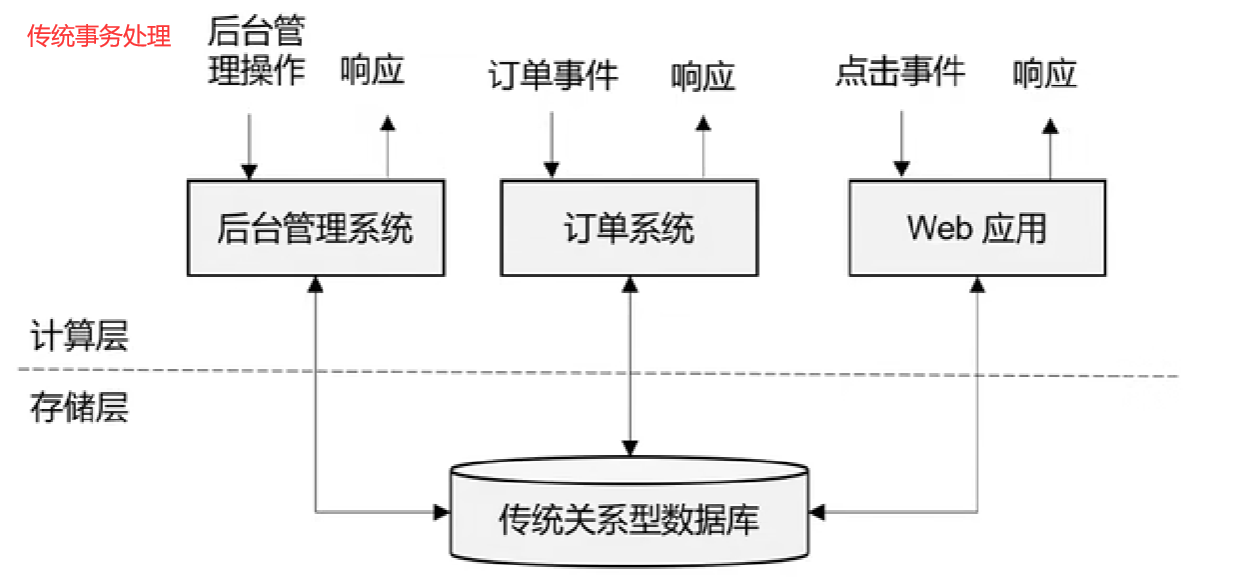
传统事务处理
二.Flink和Spark
- 概念区别- Spark强劲的分布式大数据处理框架.它使用内存中缓存和优化的查询执行方式,可针对任何规模的数据进行快速分析查询,支持跨多个工作负载重用代码—批处理、交互式查询、实时分析、机器学习和图形处理等。Spark底层基于批处理.(流是批处理不可切分的特殊情况)- Flink基于流(批处理是一种有界流)
- 数据模型- spark采用RDD模型,spark streaming 的 DStream 实际上也就是一组组小批数据RDD的集合- flink基本数据模型是数据流,以及事件(Event)序列
- 运行时架构- spark是批计算,将DAG划分为不同的 stage,一个完成后才可以计算下一个- flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理
三. Flink配置文件

jobmanager.sh 资源调度,工作分配脚本
taskmanager.sh 工作任务执行脚本
flink 启动集群后,命令执行器
四. yarn部署flink
4.1 session-cluster模式

# 启动hadhoop集群# -n(--container) taskManager的数量 不建议指定.动态分配# -s(--slot) 每个taskManager的slot数量,默认一个slot一个core.默认每个taskmanager的slot个数为1# -jm: jobManager的内存 mb.# -tm: 每个taskManager的内存 mb# -nm: yarn的appName
./yarn-session.sh -s2-jm1024-tm1024-nmtest-d# 提交job
./flink run -c com.vector.wc.StreamWordCount
FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host localhost -port7777
./flink list -a# 取消yarn-sessionyarn application --kill application_12451231_0001
4.2 pre-job-cluster模式
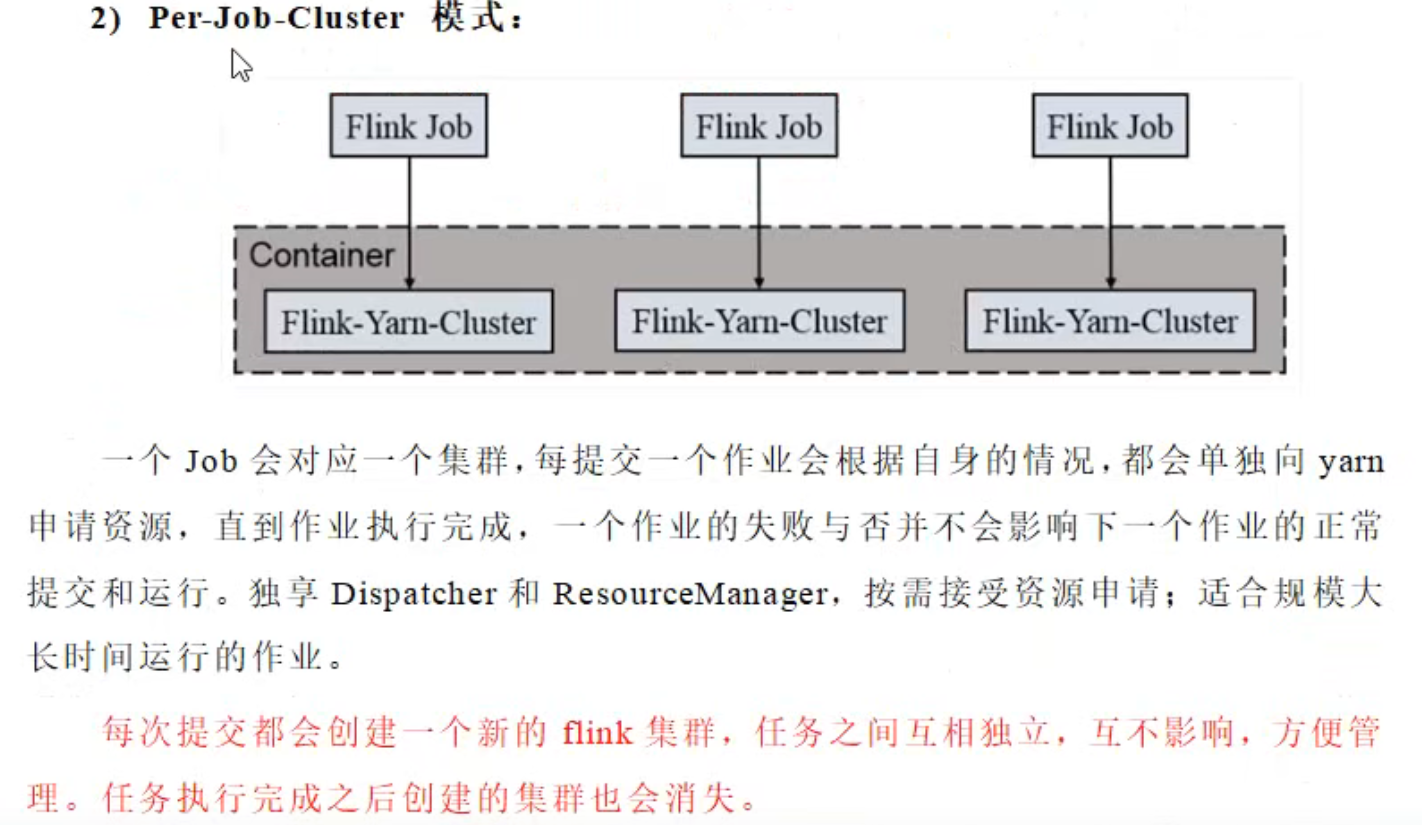
1)启动hadoop集群(略)
2)不启动yarn-session ,直接执行job
./flink run -m yarn-cluster -c com.vector.wc.StreamWordCount
FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host localhost -port7777
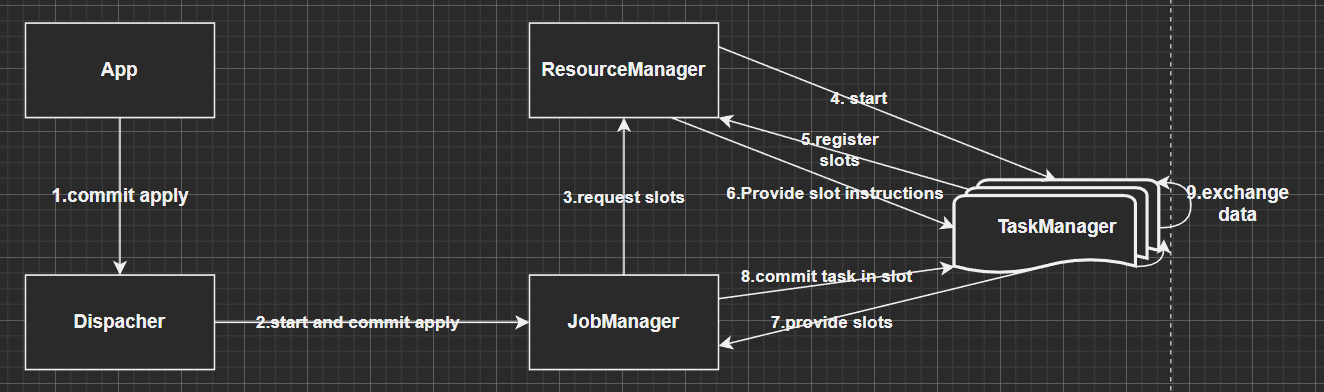
😍五.Flink运行时架构
flink运行时组件: jobManager,TaskManager,ResourceManager,Dispacher
JobManager控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的JobManager所控制执行。
- JobManager 会先接收到要执行的应用程序,这个应用程序会包括: 作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其它资源的JAR包。
- JobManager 会把JobGraph转换成一个物理层面的数据流图,这个图被叫做"“执行图”(ExecutionGraph),包含了所有可以并发执行的任务。
- JobManager 会向资源管理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器( TaskManager)上的插槽((slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。而在运行过程中,JobManager会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调
TaskManager
- Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能够执行的任务数量。
- 启动之后,TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给JobManager调用。JobManager就可以向插槽分配任务(tasks)来执行了。
- 在执行过程中,一个TaskManager可以跟其它运行同一应用程序的TaskManager交换数据。
ResourceManager
- 主要负责管理任务管理器(TaskManager)的插槽(slot) ,TaskManger插槽是Flink中定义的处理资源单元。
- Flink为不同的环境和资源管理工具提供了不同资源管理器,比如YARN.Mesos、K8s,以及standalone部署。
- 当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。
Dispacher
- 可以跨作业运行,它为应用提交提供了REST接口。
- 当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager。
- Dispatcher也会启动一个Web Ul,用来方便地展示和监控作业执行的信息。
- Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式。
5.1 任务提交流程
5.2 如何实现并行计算
并行度 可以在代码中指定,提交job指定,也可以在集群配置给默认的并行度.
优先级:代码>提交job>集群配置的并行度
- 一个特定算子的子任务 (subtask)的个数被称之为其并行度(parallelism) 。一般情况下,一个stream 的并行度,可以认为就是其所有算子中最大的并行度。
slots
推荐按照cpu核心数设置slot
- Flink 中每一个TaskManager都是一个JVM进程,它可能会在独立的线程上执行一个或多个子任务
- 为了控制一个TaskManager能接收多少个task,taskManager通过task slot来进行控制(一个TaskManager至少有一个slot)
- 默认情况下,Flink允许子任务共享slot,即使它们是不同任务的子任务。这样的结果是,一个slot可以保存作业的整个管道。
- Task Slot是静态的概念,是指TaskManager具有的并发执行能力
至少需要的slot数 = SUM(MAX(同一个共享组的任务数,同一个共享组的任务数的最大并行度))
情况1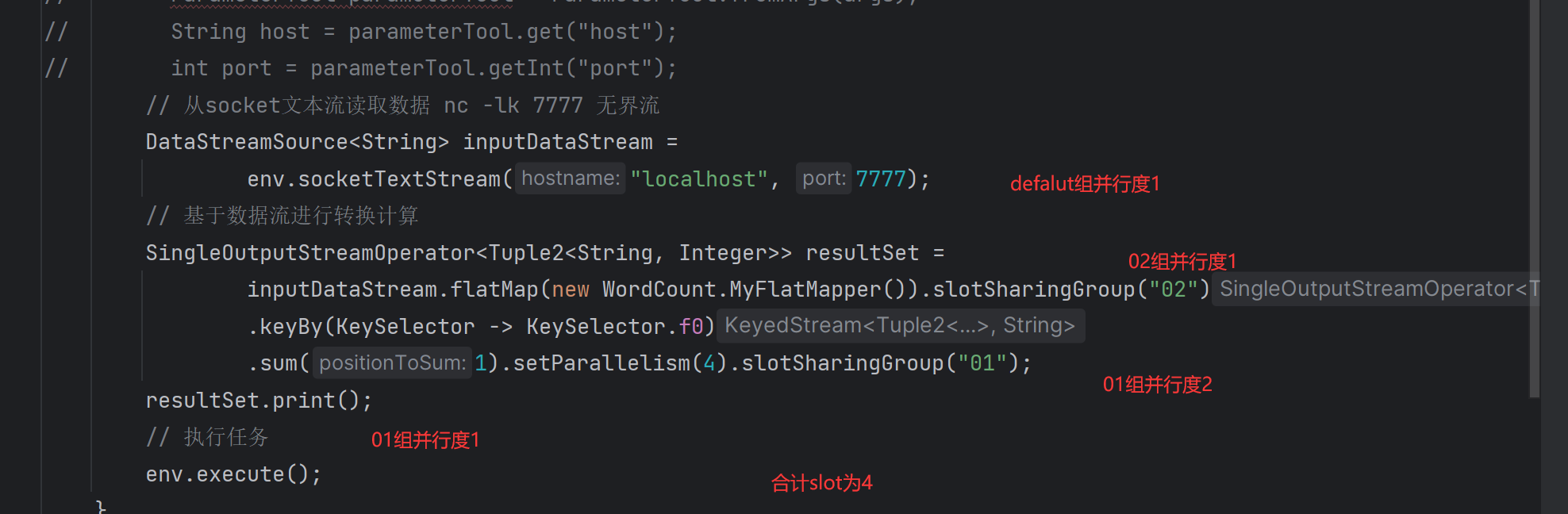
情况2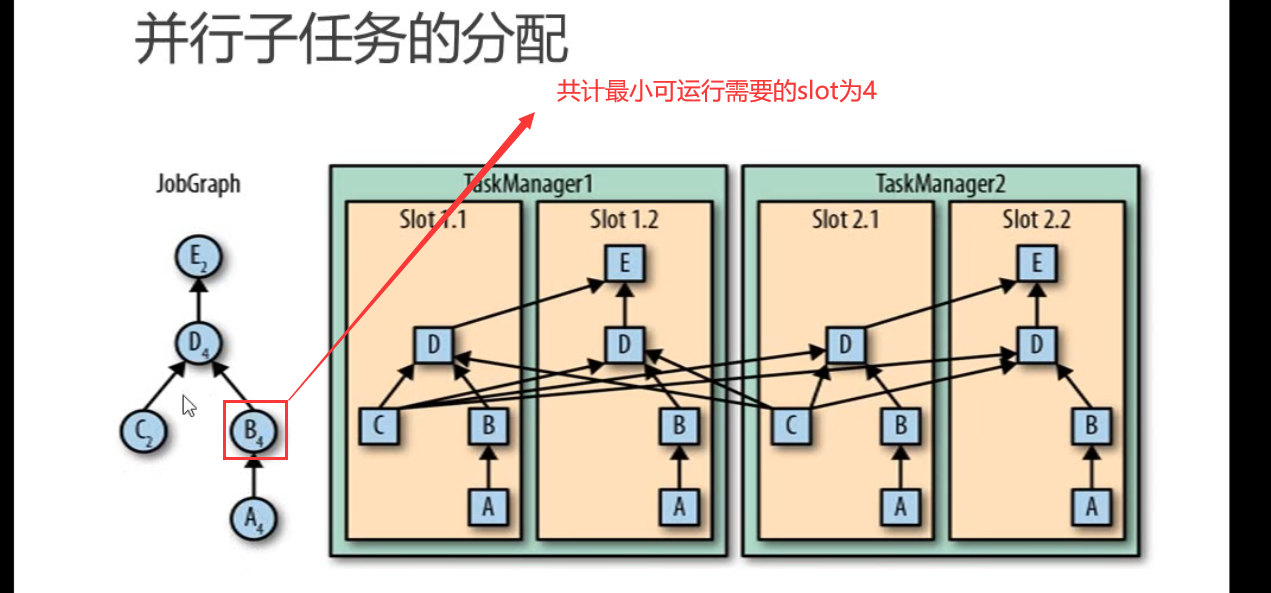
.setParallelism(4).slotSharingGroup("01"); 设置并行度和共享组 显示设置共享组可以指定不同的slot并行执行.如果有地方没配,则和前一个处于同一个共享组.如果为首部.则为defalut共享组
publicclassStreamWordCount{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();// 设置并行度
env.setParallelism(8);// 从文件中读取数据 有界流// String inputPath = System.getProperty("user.dir") + "/src/main/resources/text.txt";// FileSource<String> source = FileSource// .forRecordStreamFormat(// new TextLineInputFormat("UTF-8"),// new Path(inputPath))// .build();// DataStream<String> inputDataStream =// env.fromSource(source, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)), "text");// ParameterTool parameterTool = ParameterTool.fromArgs(args);// String host = parameterTool.get("host");// int port = parameterTool.getInt("port");// 从socket文本流读取数据 nc -lk 7777 无界流DataStreamSource<String> inputDataStream =
env.socketTextStream("localhost",7777);// 基于数据流进行转换计算SingleOutputStreamOperator<Tuple2<String,Integer>> resultSet =
inputDataStream.flatMap(newWordCount.MyFlatMapper()).slotSharingGroup("02").keyBy(KeySelector->KeySelector.f0).sum(1).setParallelism(4).slotSharingGroup("01");
resultSet.print();// 执行任务
env.execute();}publicstaticclassMyFlatMapperimplementsFlatMapFunction<String,Tuple2<String,Integer>>{@OverridepublicvoidflatMap(String s,Collector<Tuple2<String,Integer>> collector)throwsException{// 按句号分词String[] words = s.split("");// 遍历所有word,包成二元组输出for(String word : words){
collector.collect(newTuple2<>(word,1));}}}}
5.3 执行图
Flink 中的执行图可以分成四层: StreamGraph-> JobGraph -> ExecutionGraph->物理执行图
StreamGraph:是根据用户通过Stream API编写的代码生成的最初的图。用来表示程序的拓扑结构。
JobGraph: StreamGraph经过优化后生成了JobGraph,提交给JobManager的数据结构。主要的优化为,将多个符合条件的节点chain 在一起作为一个节点
ExecutionGraph: JobManager根据JobGraph生成ExecutionGraph。ExecutionGraph: 是JobGraph的并行化版本,是调度层最核心的数据结构。
物理执行图: JobManager根据ExecutionGraph对Job进行调度后,在各个TaskManager上部署Task后形成的“图”,并不是一个具体的数据结构。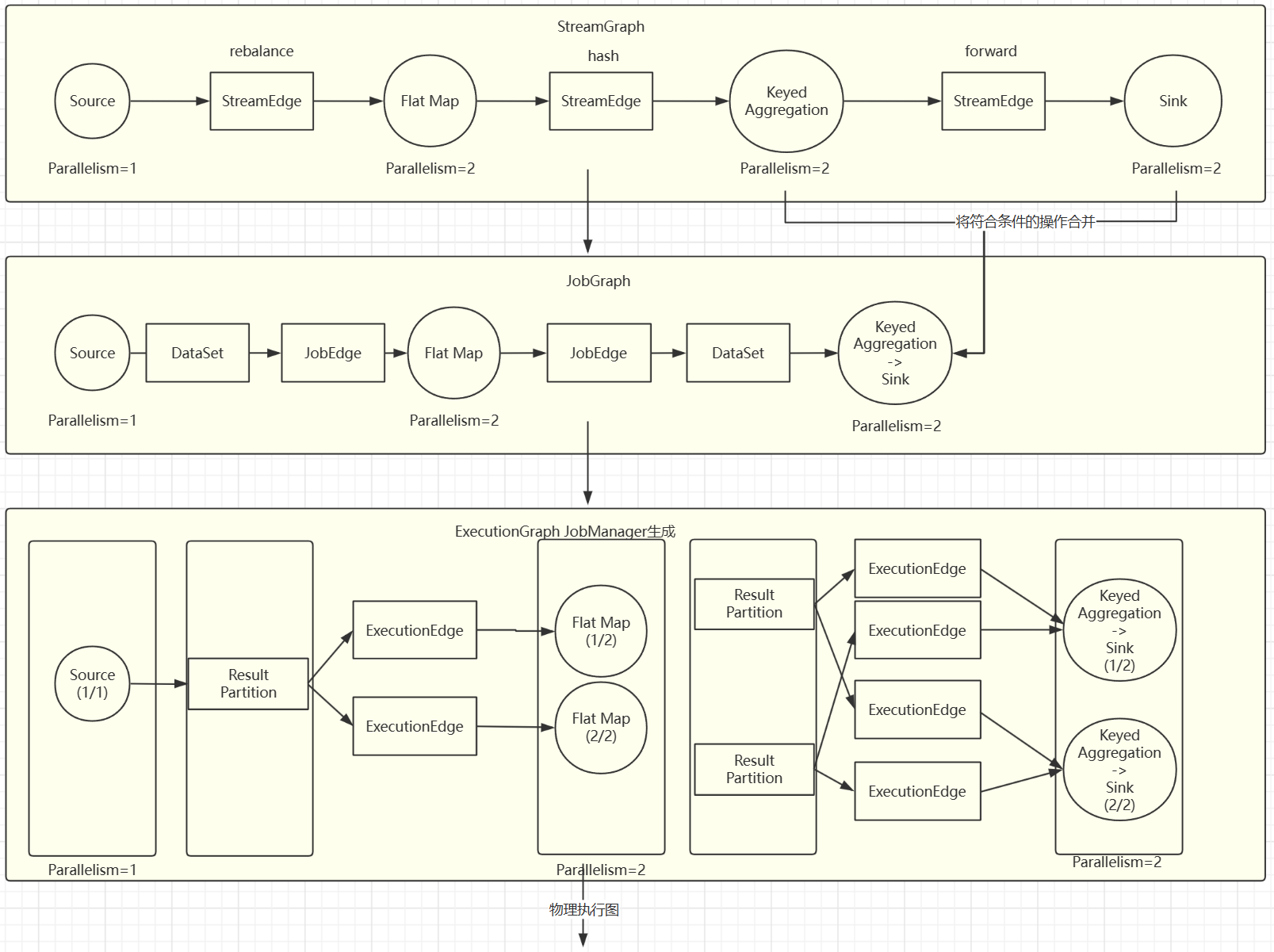
5.4 数据的传输形式
算子之间传输数据的形式可以是one-to-one (forwarding)的模式也可以是redistributing的模式,具体是哪一种形式,取决于算子的种类
One-to-one: stream维护着分区以及元素的顺序(比如source和map之间)。这意味着map算子的子任务看到的元素的个数以及顺序跟source算子的子任务生产的元素的个数、顺序相同。map、fliter、flatMap等算子都是one-to-one的对应关系。
Redistributing: stream的分区会发生改变。每一个算子的子任务依据所选择的transformation发送数据到不同的目标任务。例如,keyBy基于hashCode重分区、而broadcast和rebalance 会随机重新分区,这些算子都会引起redistribute过程,而redistribute过程就类似于Spark 中的shuffle 过程。
5.5 任务链
Flink 采用了一种称为任务链的优化技术,可以在特定条件下减少本地通信的开销。为了满足任务链的要求,必须将两个或多个算子设为相同的并行度,并通过本地转发(local forward)的方式进行连接
·相同并行度的one-to-one操作,Flink这样相连的算子链接在一起形成一个task,原来的算子成为里面的subtask
·并行度相同、并且是one-to-one操作
·位于同一个共享组 三个条件缺一不可
六. 流处理API
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>1.17.0</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.17.0</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>1.17.0</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-base --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-base</artifactId><version>1.17.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>1.17.0</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>1.17.0</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.26</version></dependency>
flink系列 1.17.0版本
创建一个执行环境,表示当前执行程序的上下文。如果程序是独立调用的,则此方法返回本地执行环境;如果从命令行客户端调用程序以提交到集群,则此方法返回此集群的执行环境,也就是说,getExecutionEnvironment会根据查询运行的方式决定返回什么样的运行环境,是最常用的一种创建执行环境的方式。
如果没有设置并行度默认flink-conf.yaml配置文件的1
// 封装了对本地执行环境和远程执行环境的判断 流处理StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();// 批处理ExecutionEnvironment executionEnvironment =ExecutionEnvironment.getExecutionEnvironment();
source.txt
sensor_1,1547718199,35.8
sensor_2,1547718201,15.4
sensor_3,1547718202,6.7
sensor_4,1547718205,38.1
sensor_1,1547718191,32.8
sensor_1,1547714191,26.8
sensor_3,1547718202,6.7
SensorReadingEntity .class
// 传感器温度读数数据类型@Data@AllArgsConstructor@NoArgsConstructorpublicclassSensorReadingEntity{privateString id;privateLong timestamp;privateDouble temperature;}
6.1文件处理
publicclassSourceTest2_File{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();// 从文件中读取数据String inputPath =System.getProperty("user.dir")+"/src/main/resources/source.txt";FileSource<String> build =FileSource.forRecordStreamFormat(newTextLineInputFormat(),newPath(inputPath)).build();DataStream<String> dataStream = env
.fromSource(build,WatermarkStrategy.noWatermarks(),"source.txt");// 打印输出
dataStream.print();
env.execute();}}
😍6.2kafka处理
基本配置
# 修改kafka主机ip 配置localhost或127.0.0.1在wsl上可能会有问题
conf/server.properties
listeners = PLAINTEXT://非回环ip:9092
advertised.listeners=PLAINTEXT://非回环ip:9092
#开启kafka zookeeper服务
bin/zookeeper-server-start.sh config/zookeeper.properties
# 开启kafka服务
bin/kafka-server-start.sh config/server.properties
实例化交换机消息队列
# 交换机ip端口 172.27.188.96:9092 主题交换机名称aaaaa
bin/kafka-console-producer.sh --broker-list 172.27.188.96:9092 --topic aaaaa
java连接代码
publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();String brokers ="172.27.188.96:9092";KafkaSource<String> source =KafkaSource.<String>builder().setBootstrapServers(brokers).setTopics("aaaaa")// .setGroupId("my-group").setStartingOffsets(OffsetsInitializer.latest())// 从最早的数据开始读取.setValueOnlyDeserializer(newSimpleStringSchema())// 只需要value.build();DataStream<String> kafkaSource = env.fromSource(source,WatermarkStrategy.noWatermarks(),"Kafka Source");// 打印
kafkaSource.print();// 执行
env.execute();}

😍6.3 自定义数据源
/**
* @author YuanJie
* @projectName flink
* @package com.vector.apitest
* @className com.vector.apitest.SourceTest4_UDF
* @copyright Copyright 2020 vector, Inc All rights reserved.
* @date 2023/8/21 15:15
*/publicclassSourceTest4_UDF{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);// 从自定义的数据源读取数据DataStream<SensorReading> dataStream = env.addSource(newMySensorSource());// 打印输出
dataStream.print();// 执行
env.execute();}// 实现自定义的SourceFunction<OUT>接口,自定义的数据源privatestaticclassMySensorSourceimplementsSourceFunction<SensorReading>{// 定义一个标志位,用来表示数据源是否正常运行发出数据privateboolean running =true;@Overridepublicvoidrun(SourceContext<SensorReading> sourceContext)throwsException{// 定义一个随机数发生器Random random =newRandom();// 设置10个传感器的初始温度 0~120℃正态分布HashMap<String,Double> sensorTempMap =newHashMap<>();for(int i =0; i <10; i++){
sensorTempMap.put("sensor_"+(i +1),60+ random.nextGaussian()*20);}while(running){// 在while循环中,随机生成SensorReading数据for(String sensorId : sensorTempMap.keySet()){// 在当前温度基础上随机波动Double newTemp = sensorTempMap.get(sensorId)+ random.nextGaussian();
sensorTempMap.put(sensorId, newTemp);
sourceContext.collect(newSensorReading(sensorId,System.currentTimeMillis(), newTemp));}// 每隔1秒钟发送一次传感器数据TimeUnit.MILLISECONDS.sleep(1000L);}}@Overridepublicvoidcancel(){
running =false;}}}
😍6.4 Transform-转换算子
6.4.1 map

6.4.2 flatMap
6.4.3 filter

demo
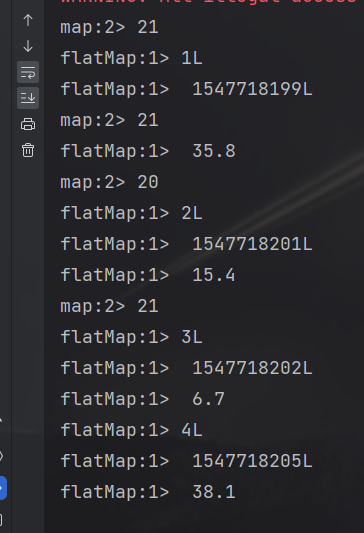
publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);// 从文件读数据FileSource<String> build =FileSource.forRecordStreamFormat(newTextLineInputFormat(),newPath(System.getProperty("user.dir")+"/src/main/resources/source.txt")).build();// map 转换成长度输出DataStream<Integer> map = env.fromSource(build,WatermarkStrategy.noWatermarks(),"source.txt").map(String::length);// flatMap 按逗号分隔DataStream<String> flatMap = env.fromSource(build,WatermarkStrategy.noWatermarks(),"source.txt").flatMap((String s,Collector<String> collector)->{String[] split = s.split(",");for(String s1 : split){
collector.collect(s1);}}).returns(Types.STRING);// filter 筛选 sensor_1 开头的idDataStream<String> filter = env.fromSource(build,WatermarkStrategy.noWatermarks(),"source.txt").filter(s -> s.startsWith("sensor_1"));
map.print("map");
flatMap.print("flatMap");
filter.print("filter");
env.execute();}
6.5 😍分组聚合
6.5.1 keyBy
Flink中分组后才能聚合
根据某个字段将数据分到不同分区.每个分区包含相同的key. 内部以hash形式实现.(存在hash冲突,因此能保证需要的均在某分区,但无法保证该分区key唯一)
6.5.2 滚动聚合算子(Rolling Aggregation)
这些算子可以针对KeyedStream的每一个支流做聚合。
- sum()
- min()
- max()
- minBy()
- maxBy()
demo - max
求每组中首个设备温度变化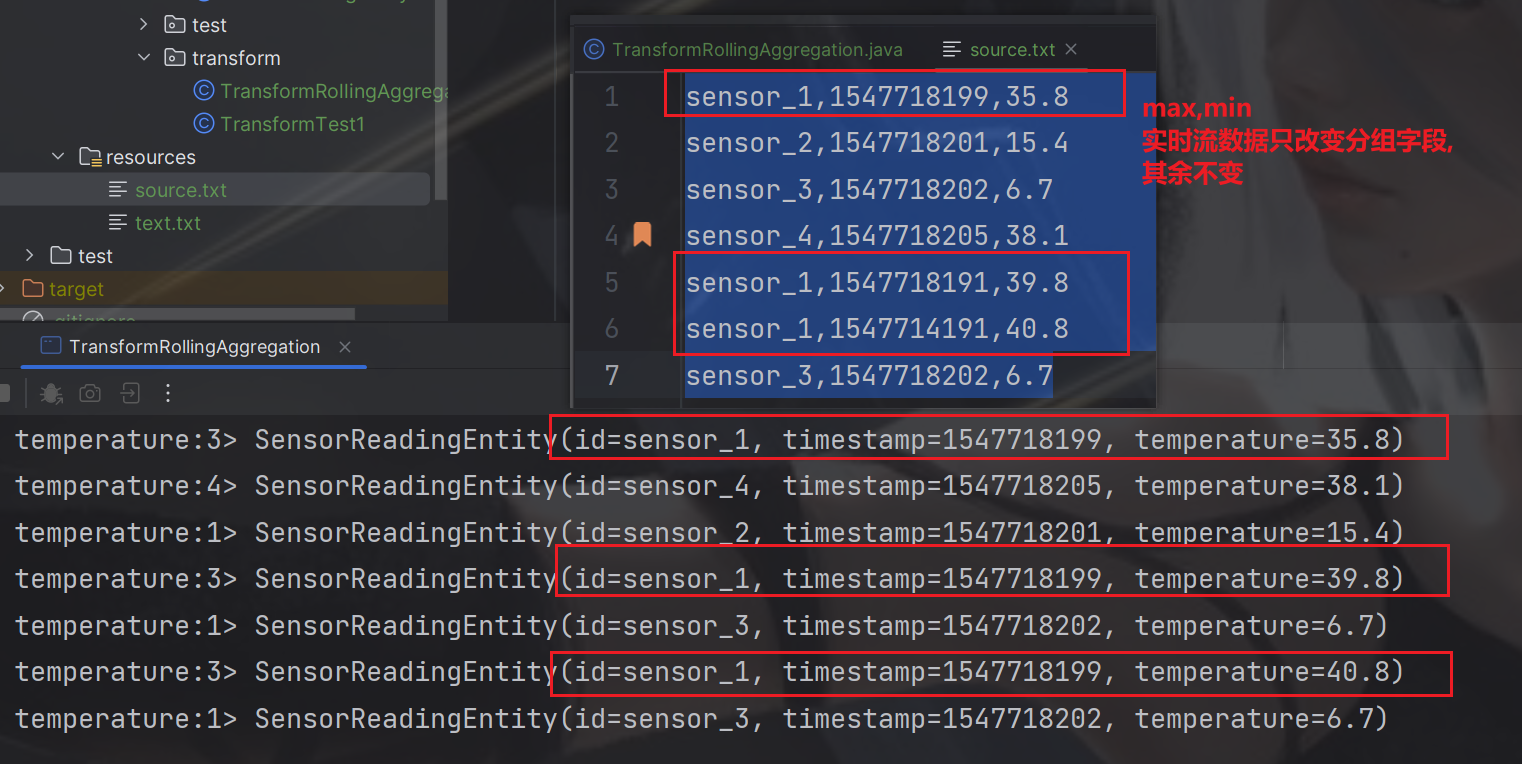
sensor_1,1547718199,35.8
sensor_2,1547718201,15.4
sensor_3,1547718202,6.7
sensor_4,1547718205,38.1
sensor_1,1547718191,39.8
sensor_1,1547714191,40.8
sensor_3,1547718202,6.7
publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);FileSource<String> build =FileSource.forRecordStreamFormat(newTextLineInputFormat(),newPath(System.getProperty("user.dir")+"/src/main/resources/source.txt")).build();DataStream<String> streamSource = env.fromSource(build,WatermarkStrategy.noWatermarks(),"source.txt");// 转换成SensorReading 类型DataStream<SensorReadingEntity> dataStream = streamSource.map(item ->{String[] split = item.split(",");returnnewSensorReadingEntity(split[0],Long.parseLong(split[1]),Double.parseDouble(split[2]));});// 分组 滚动聚合DataStream<SensorReadingEntity> temperature = dataStream.keyBy(SensorReadingEntity::getId)// 滚动聚合.max("temperature");
temperature.print("temperature");
env.execute();}
demo-maxBy
求实时数据中每组当前最大温度数据
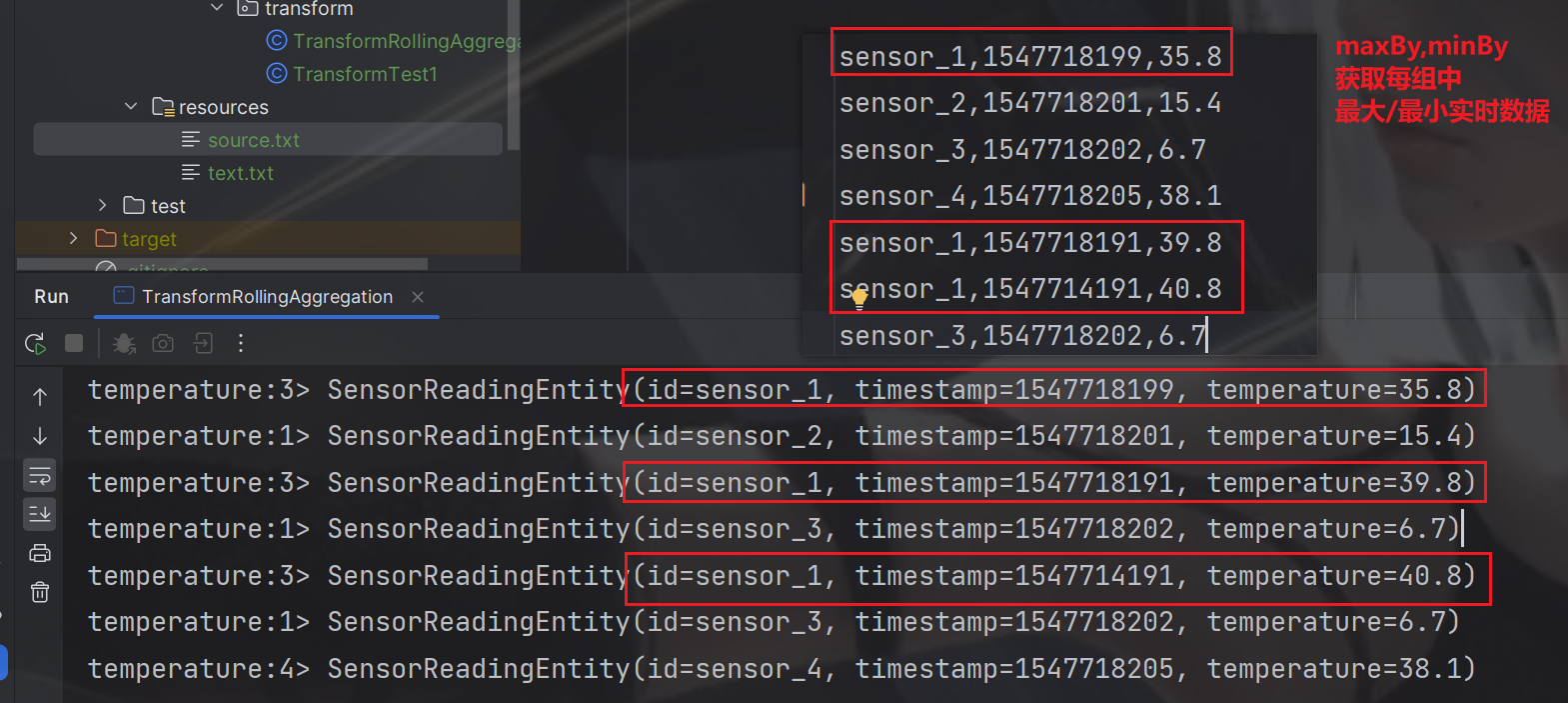
6.5.3 reduce
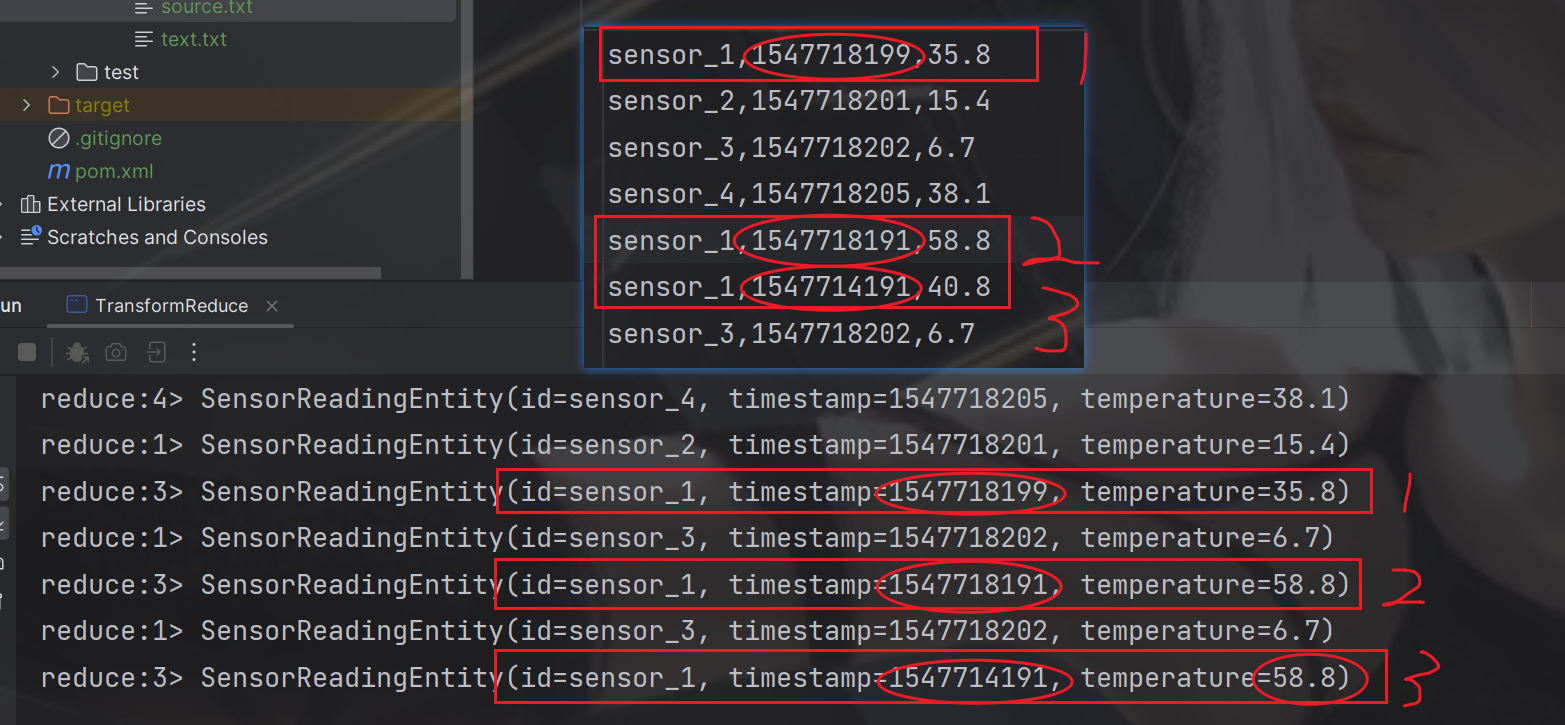
求最大温度值,以及当前最新的时间戳
publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);FileSource<String> build =FileSource.forRecordStreamFormat(newTextLineInputFormat(),newPath(System.getProperty("user.dir")+"/src/main/resources/source.txt")).build();DataStream<String> streamSource = env.fromSource(build,WatermarkStrategy.noWatermarks(),"source.txt");// 转换成SensorReading 类型DataStream<SensorReadingEntity> dataStream = streamSource.map(item ->{String[] split = item.split(",");returnnewSensorReadingEntity(split[0],Long.parseLong(split[1]),Double.parseDouble(split[2]));});// reduce 聚合 求最大温度值,以及当前最新的时间戳DataStream<SensorReadingEntity> reduce = dataStream.keyBy(SensorReadingEntity::getId).reduce((curState, newData)->{returnnewSensorReadingEntity(curState.getId(), newData.getTimestamp(),Math.max(curState.getTemperature(), newData.getTemperature()));});
reduce.print("reduce");
env.execute();}
😍6.6 多流转换算子 分流
以下api的demo集合
sensor_1,1547718199,35.8
sensor_2,1547718201,15.4
sensor_3,1547718202,6.7
sensor_4,1547718205,38.1
sensor_1,1547718191,32.8
sensor_1,1547714191,26.8
sensor_3,1547718202,6.7
publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);FileSource<String> build =FileSource.forRecordStreamFormat(newTextLineInputFormat(),newPath(System.getProperty("user.dir")+"/src/main/resources/source.txt")).build();DataStream<String> streamSource = env.fromSource(build,WatermarkStrategy.noWatermarks(),"source.txt");// 转换成SensorReading 类型DataStream<SensorReadingEntity> dataStream = streamSource.map(item ->{String[] split = item.split(",");returnnewSensorReadingEntity(split[0],Long.parseLong(split[1]),Double.parseDouble(split[2]));});// 分流 侧输出流 定义低温流标识finalOutputTag<SensorReadingEntity> outputTag =newOutputTag<SensorReadingEntity>("low"){};SingleOutputStreamOperator<SensorReadingEntity> process = dataStream.process(newProcessFunction<SensorReadingEntity,SensorReadingEntity>(){@OverridepublicvoidprocessElement(SensorReadingEntity sensorReadingEntity,ProcessFunction<SensorReadingEntity,SensorReadingEntity>.Context context,Collector<SensorReadingEntity> collector)throwsException{if(sensorReadingEntity.getTemperature()>30){
collector.collect(sensorReadingEntity);}else{
context.output(outputTag, sensorReadingEntity);}}});// 低温流 侧输出流
process.getSideOutput(outputTag).print("low");// 高温流 主流
process.print("high");// 连接流(数据类型不同) + 合流(完全相同) 转换为二元组DataStream<Object> map = process.map(item ->{SensorReadingEntity sensorReadingEntity =(SensorReadingEntity) item;returnnewTuple2<>(sensorReadingEntity.getId(), sensorReadingEntity.getTemperature());}).returns(Types.TUPLE(Types.STRING,Types.DOUBLE)).connect(process.getSideOutput(outputTag)).map(newCoMapFunction<Tuple2<String,Double>,SensorReadingEntity,Object>(){@OverridepublicObjectmap1(Tuple2<String,Double> tuple2)throwsException{returnnewTuple3<>(tuple2.f0, tuple2.f1,"高温报警");}@OverridepublicObjectmap2(SensorReadingEntity sensorReadingEntity)throwsException{returnnewTuple2<>(sensorReadingEntity.getId(),"正常");}});
map.print("connect");// union 合流DataStream<SensorReadingEntity> union = process.union(process.getSideOutput(outputTag));
union.print("union");
env.execute();}
6.6.1 getSideOutput 分流输出
用于将实时数据,根据条件分流输出.
根据30℃标准值分为高温主流和低温 侧输出流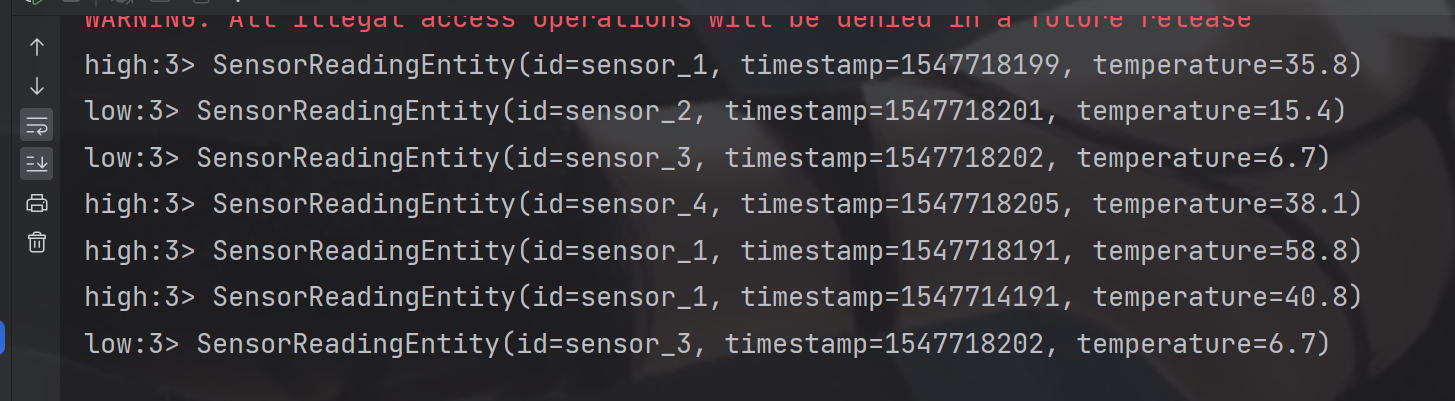
6.6.2 connect 和CoMap 合流
connect只能连接两条流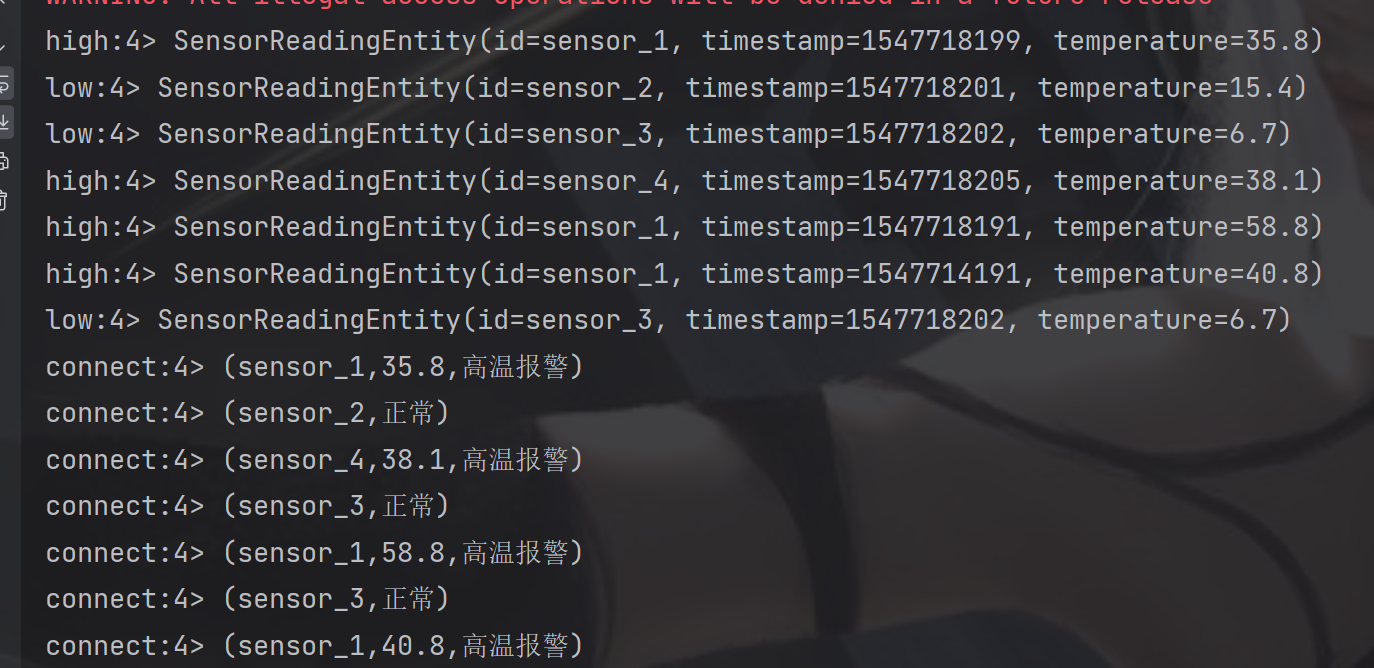
6.6.3 union 合流
可以合并多条流,但是流的类型必须一致
DataStream →DataStream:对两个或者两个以上的DataStream进行union操作,产生一个包含所有DataStream元素的新DataStream.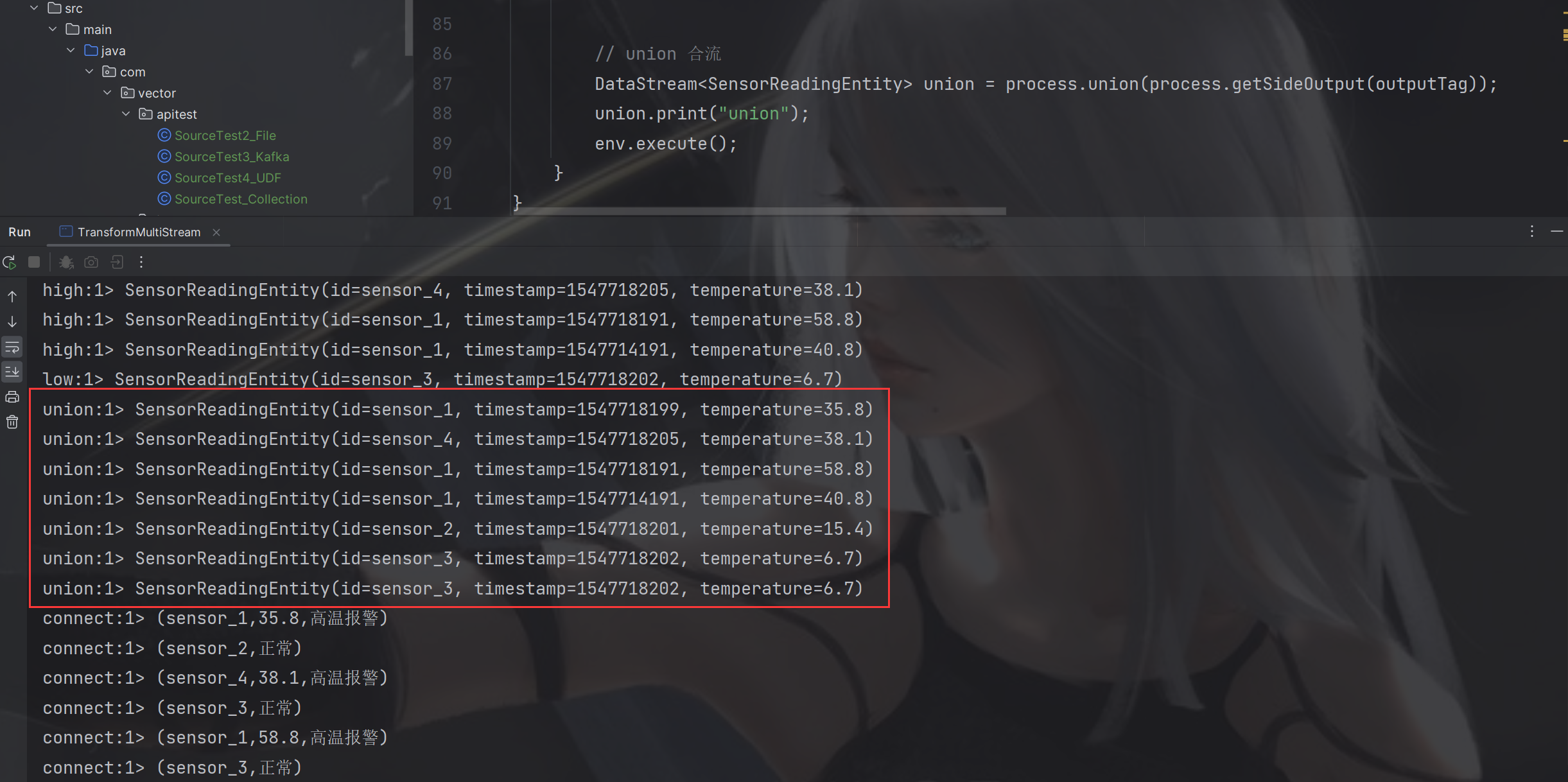
七. 函数类
7.1 😍UDF函数类
Flink暴露了所有udf函数的接口(实现方式为接口或者抽象类)。例如MapFunction,FilterFunction,ProcessFunction等.
7.2 😍RichFunction
“富函数”是DataStream API提供的一个函数类的接口,所有Flink函数类都有其Rich 版本。它与常规函数的不同在于,可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。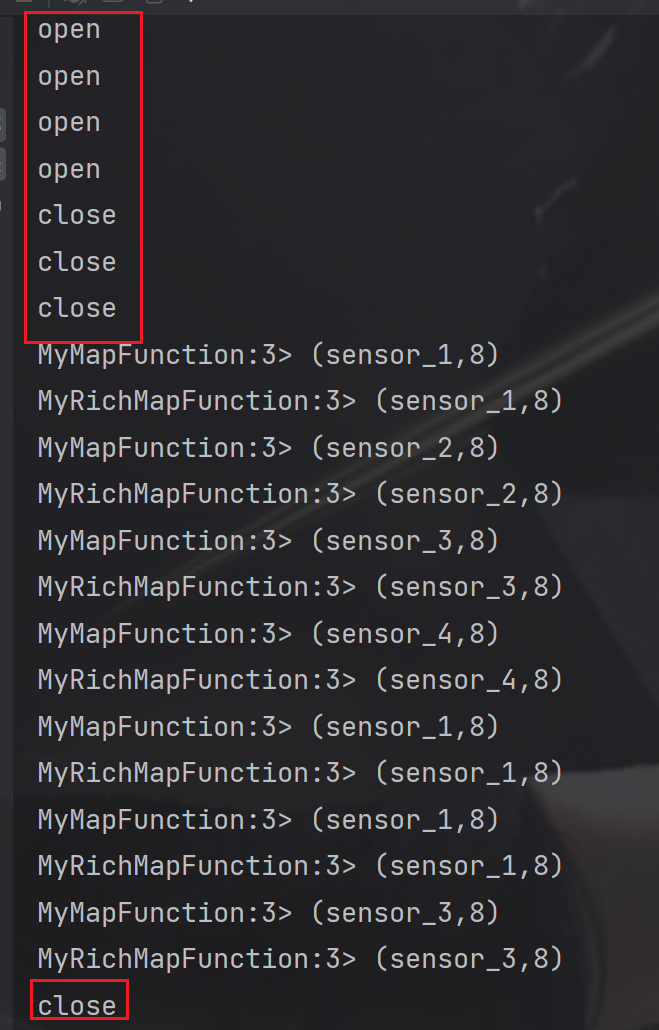
publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);FileSource<String> build =FileSource.forRecordStreamFormat(newTextLineInputFormat(),newPath(System.getProperty("user.dir")+"/src/main/resources/source.txt")).build();DataStream<String> streamSource = env.fromSource(build,WatermarkStrategy.noWatermarks(),"source.txt");// 转换成SensorReading 类型DataStream<SensorReadingEntity> dataStream = streamSource.map(item ->{String[] split = item.split(",");returnnewSensorReadingEntity(split[0],Long.parseLong(split[1]),Double.parseDouble(split[2]));});DataStream<Tuple2<String,Integer>> resultStream = dataStream.map(newMyMapFunction());
resultStream.print("MyMapFunction");DataStream<Tuple2<String,Integer>> resultRichStream = dataStream.map(newMyRichMapFunction());
resultStream.print("MyRichMapFunction");
env.execute();}publicstaticclassMyMapFunctionimplementsMapFunction<SensorReadingEntity,Tuple2<String,Integer>>{@OverridepublicTuple2<String,Integer>map(SensorReadingEntity value)throwsException{returnnewTuple2<>(value.getId(), value.getId().length());}}publicstaticclassMyRichMapFunctionextendsRichMapFunction<SensorReadingEntity,Tuple2<String,Integer>>{@OverridepublicTuple2<String,Integer>map(SensorReadingEntity value)throwsException{returnnewTuple2<>(value.getId(),getRuntimeContext().getIndexOfThisSubtask());}@Overridepublicvoidopen(org.apache.flink.configuration.Configuration parameters)throwsException{// 初始化工作,一般是定义状态,或者建立数据库连接// 每个并行实例都会调用一次System.out.println("open");}@Overridepublicvoidclose()throwsException{// 一般是关闭连接和清空状态的收尾操作// 每个并行实例都会调用一次System.out.println("close");;}}
7.3 重分区
上述介绍KeyBy是Hash重分区
broadcast 下游广播
shuffle 随机把当前任务分配到下游子分区
forward 直通分区
rebalance 轮询分配到下游子分区
rescale 分组轮询到下游子分区
global 只传输到下游第一个子分区
partitionCustom 自定义传输分区
publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);FileSource<String> build =FileSource.forRecordStreamFormat(newTextLineInputFormat(),newPath(System.getProperty("user.dir")+"/src/main/resources/source.txt")).build();DataStream<String> streamSource = env.fromSource(build,WatermarkStrategy.noWatermarks(),"source.txt");
streamSource.print("input");// 1. shuffleDataStream<String> shuffle = streamSource.shuffle();
shuffle.print("shuffle");// 2. rebalanceDataStream<String> rebalance = streamSource.rebalance();
rebalance.print("rebalance");// 3. rescaleDataStream<String> rescale = streamSource.rescale();
rescale.print("rescale");// 4. globalDataStream<String> global = streamSource.global();
global.print("global");// 5. broadcastDataStream<String> broadcast = streamSource.broadcast();
broadcast.print("broadcast");// 6. forwardDataStream<String> forward = streamSource.forward();
forward.print("forward");// 7. keyBy
streamSource.keyBy(item ->{String[] split = item.split(",");return split[0];}).print("keyBy");
env.execute();}
7.4 sink 写入库
Flink没有类似于spark 中 foreach方法,让用户进行迭代的操作。虽有对外的输出操作都要利用sink完成。最后通过类似如下方式完成整个任务最终输出操作。
stream.addsink(newMysink( xxxx))
flink1.17.0提供的连接器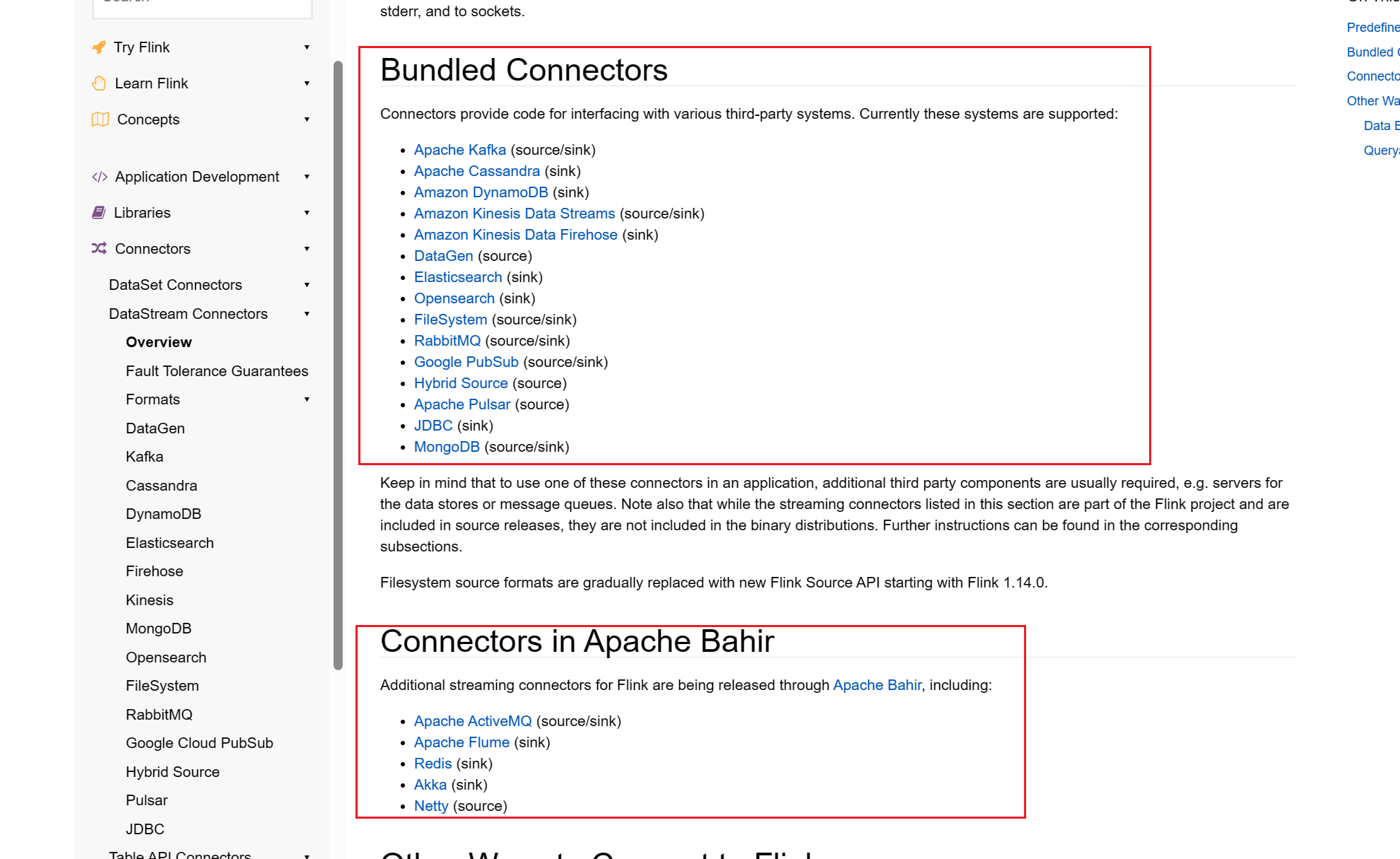
😍7.4.1 读kafka-写kafka
Kafka基本配置
# 修改kafka主机ip 配置localhost或127.0.0.1在wsl上可能会有问题
conf/server.properties
listeners = PLAINTEXT://非回环ip:9092
advertised.listeners=PLAINTEXT://非回环ip:9092
#开启kafka zookeeper服务
bin/zookeeper-server-start.sh config/zookeeper.properties
# 开启kafka服务
bin/kafka-server-start.sh config/server.properties
实例化交换机消息队列
# 交换机ip端口 172.27.181.61:9092 主题交换机名称topic-sink 生产者
bin/kafka-console-producer.sh --broker-list 172.27.181.61:9092 --topic topic-producer
# 消费者
bin/kafka-console-consumer.sh --bootstrap-server 172.27.181.61:9092 --topic topic-sink
publicclassSinkTest1_Kafka{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);String brokers ="172.27.181.61:9092";// 从kafka读取数据KafkaSource<String> source =KafkaSource.<String>builder().setBootstrapServers(brokers).setTopics("topic-producer").setStartingOffsets(OffsetsInitializer.latest())// 从最新的数据开始读取.setValueOnlyDeserializer(newSimpleStringSchema())// 只需要value.build();DataStream<String> kafkaSource = env.fromSource(source,WatermarkStrategy.noWatermarks(),"Kafka Source");// 转换成SensorReading 类型DataStream<String> dataStream = kafkaSource.map(item ->{String[] split = item.split(",");try{returnnewSensorReadingEntity(split[0],Long.parseLong(split[1]),Double.parseDouble(split[2])).toString();}catch(Exception e){return item;}});// 输出到kafkaKafkaSink<String> sink =KafkaSink.<String>builder().setBootstrapServers(brokers).setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic("topic-sink").setValueSerializationSchema(newSimpleStringSchema()).build()).setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)// 至少一次.build();
dataStream.sinkTo(sink);
env.execute();}}

😍7.4.2 读kafka-写非关系数据库redis-redisson-自定义flink连接器
1.flink官方为我们提供了多种连接器,我们可以直接使用
官方连接地址 这里就不讲这种方法了
2.自定义连接器,以整合redisson为例
额外引入pom
<properties><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>1.17.0</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.17.0</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>1.17.0</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-base --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-base</artifactId><version>1.17.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>1.17.0</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>1.17.0</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.26</version></dependency><dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>3.20.0</version></dependency></dependencies>
配置redisson数据源,springboot可以修改该配置
//@Configuration@Slf4j//@ConfigurationProperties(prefix = "redisson")//@DatapublicclassRedissonConfig{// private String host;//private String password;//private Integer database;// @Bean(destroyMethod = "shutdown")publicstaticRedissonClientredisson(){Config config =newConfig();//config.useClusterServers().addNodeAddress("127.0.0.1:6379").setPassword("123456");
config.useSingleServer().setAddress("redis://"+"localhost:6379")// 单机模式.setPassword("123456")// 密码.setSubscriptionConnectionMinimumIdleSize(1)// 对于支持多个Redis连接的RedissonClient对象,.setSubscriptionConnectionPoolSize(50)// 对于支持绑定多个Redisson连接的RedissonClient对象,.setConnectionMinimumIdleSize(32)// 最小空闲连接数.setConnectionPoolSize(64)// 只能用于单机模式.setDnsMonitoringInterval(5000)// DNS监控间隔时间,单位:毫秒.setIdleConnectionTimeout(10000)// 空闲连接超时时间,单位:毫秒.setConnectTimeout(10000)// 连接超时时间,单位:毫秒.setPingConnectionInterval(10000)// 集群状态扫描间隔时间,单位:毫秒.setTimeout(5000)// 命令等待超时时间,单位:毫秒.setRetryAttempts(3)// 命令重试次数.setRetryInterval(1500)// 命令重试发送时间间隔,单位:毫秒.setDatabase(0)// 数据库编号.setSubscriptionsPerConnection(5);// 每个连接的最大订阅数量
config.setCodec(newJsonJacksonCodec());// 设置编码方式returnRedisson.create(config);}}
source.txt
sensor_1,1547718199,35.8
sensor_2,1547718201,15.4
sensor_3,1547718202,6.7
sensor_4,1547718205,38.1
sensor_1,1547718191,32.8
sensor_1,1547714191,26.8
sensor_3,1547718202,6.7
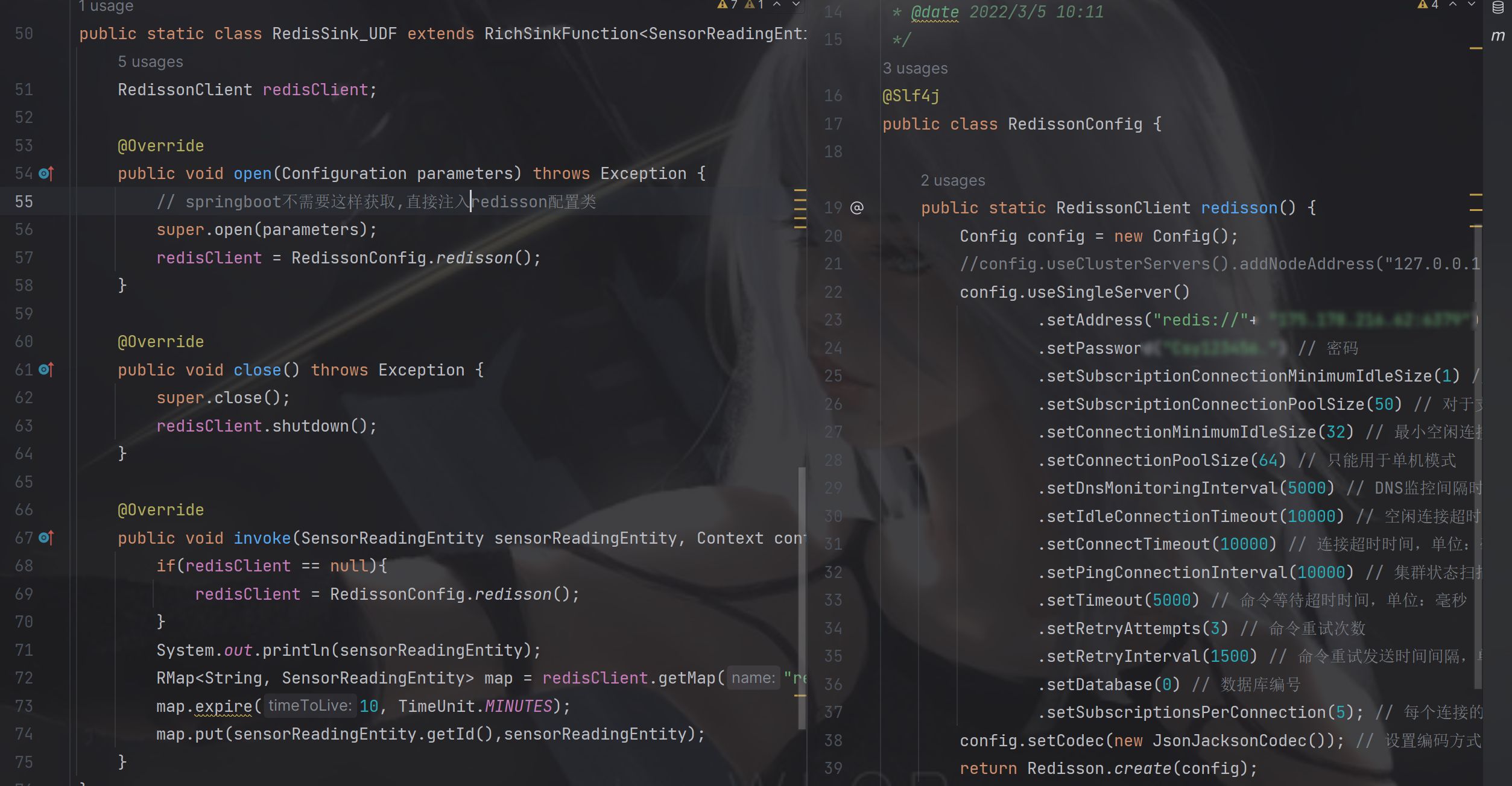
自定义RichSinkFunction
open在创建sink时候只调用一次,所以这里可以用于初始化一些资源配置
invok(Object value, Context context)方法在每次有数据流入时都会调用,所以从源中每过来一个数据都会执行
close()方法用于关闭sink时调用,一般用于释放资源
如果使用springboot整合那直接注入,就不需要在open中初始化
publicclassSinkTest2_Redis_UDF{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);FileSource<String> build =FileSource.forRecordStreamFormat(newTextLineInputFormat(),newPath(System.getProperty("user.dir")+"/src/main/resources/source.txt")).build();DataStream<String> streamSource = env.fromSource(build,WatermarkStrategy.noWatermarks(),"source.txt");// 转换成SensorReading 类型DataStream<SensorReadingEntity> dataStream = streamSource.map(item ->{String[] split = item.split(",");returnnewSensorReadingEntity(split[0],Long.parseLong(split[1]),Double.parseDouble(split[2]));});
dataStream.addSink(newRedisSink_UDF());
env.execute();}publicstaticclassRedisSink_UDFextendsRichSinkFunction<SensorReadingEntity>{RedissonClient redisClient;@Overridepublicvoidopen(Configuration parameters)throwsException{// springboot不需要这样获取,直接注入redisson配置类super.open(parameters);
redisClient =RedissonConfig.redisson();}@Overridepublicvoidclose()throwsException{super.close();
redisClient.shutdown();}@Overridepublicvoidinvoke(SensorReadingEntity sensorReadingEntity,Context context)throwsException{if(redisClient ==null){
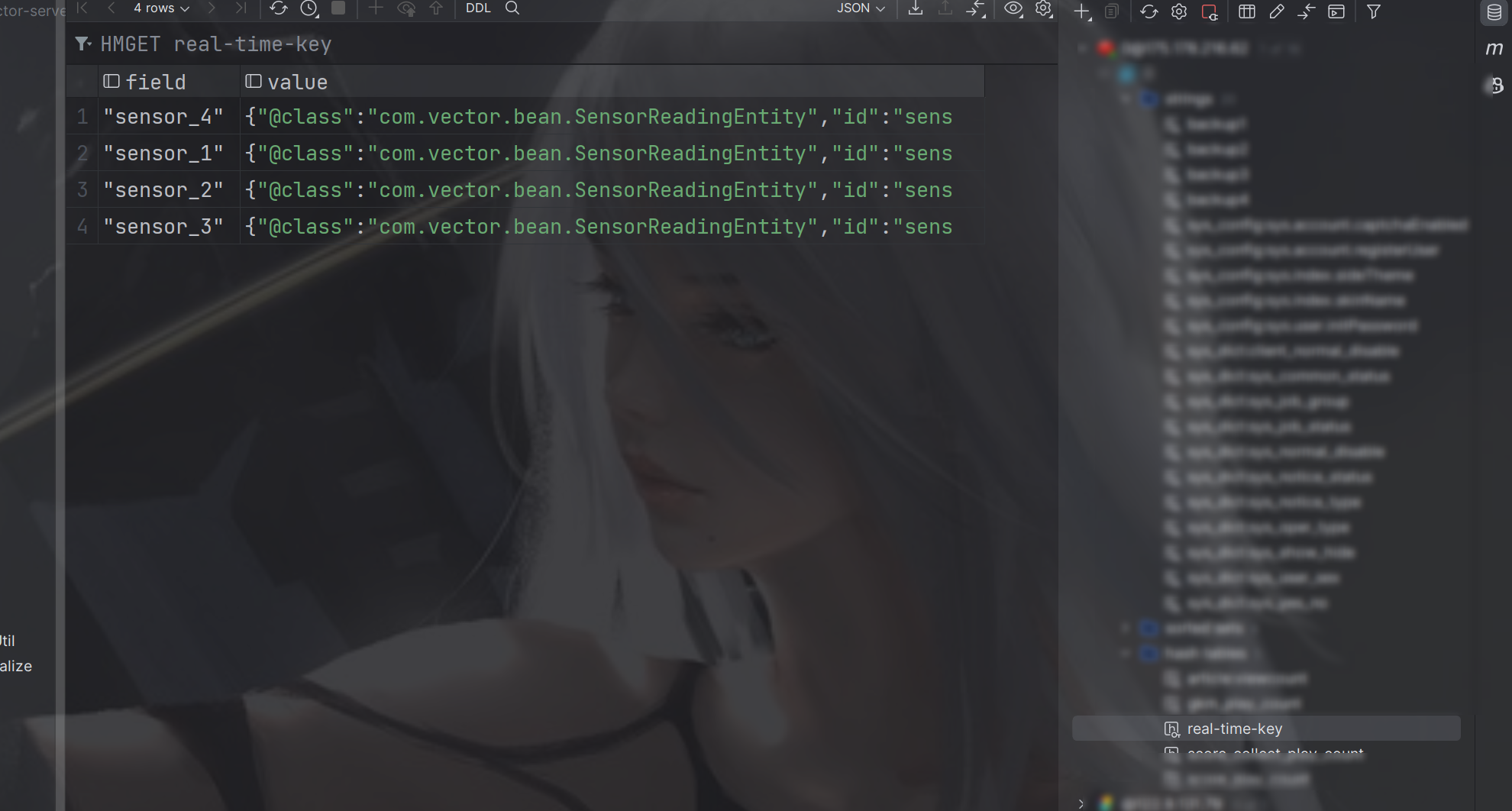
redisClient =RedissonConfig.redisson();}System.out.println(sensorReadingEntity);RMap<String,SensorReadingEntity> map = redisClient.getMap("real-time-key");
map.expire(10,TimeUnit.MINUTES);
map.put(sensorReadingEntity.getId(),sensorReadingEntity);}}}

八. Window API
一般真实的流都是无界的,怎样处理无界的数据? 即需要统计数据到未来某个时间段.
- 可以把无限的数据流进行切分,得到有限的数据集进行处理——也就是得到有界流
- 窗口(window)就是将无限流切割为有限流的一种方式,它会将流数据分发到有限大小的桶(bucket)中进行分析. flink的窗口概念更类似令牌桶(条件桶)的概念,因为无限数据是无法确定数据量的,需要将符合条件的数据放入对应的窗口.乱序数据也因此可以变得有序.
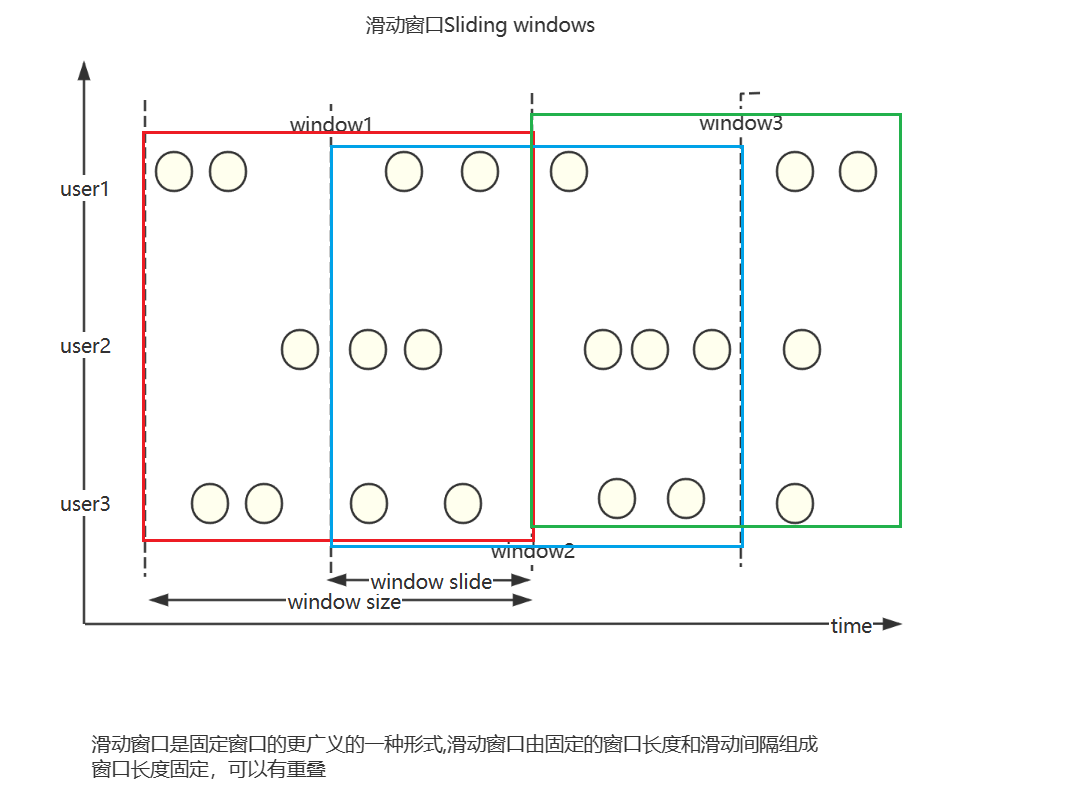
window类型
时间窗口 (按时间截取)
- 滚动时间窗口
- 滑动时间窗口
- 会话窗口
计数窗口 (按数据个数截取)
- 滚动计数窗口
- 滑动计数窗口

会话窗口 session window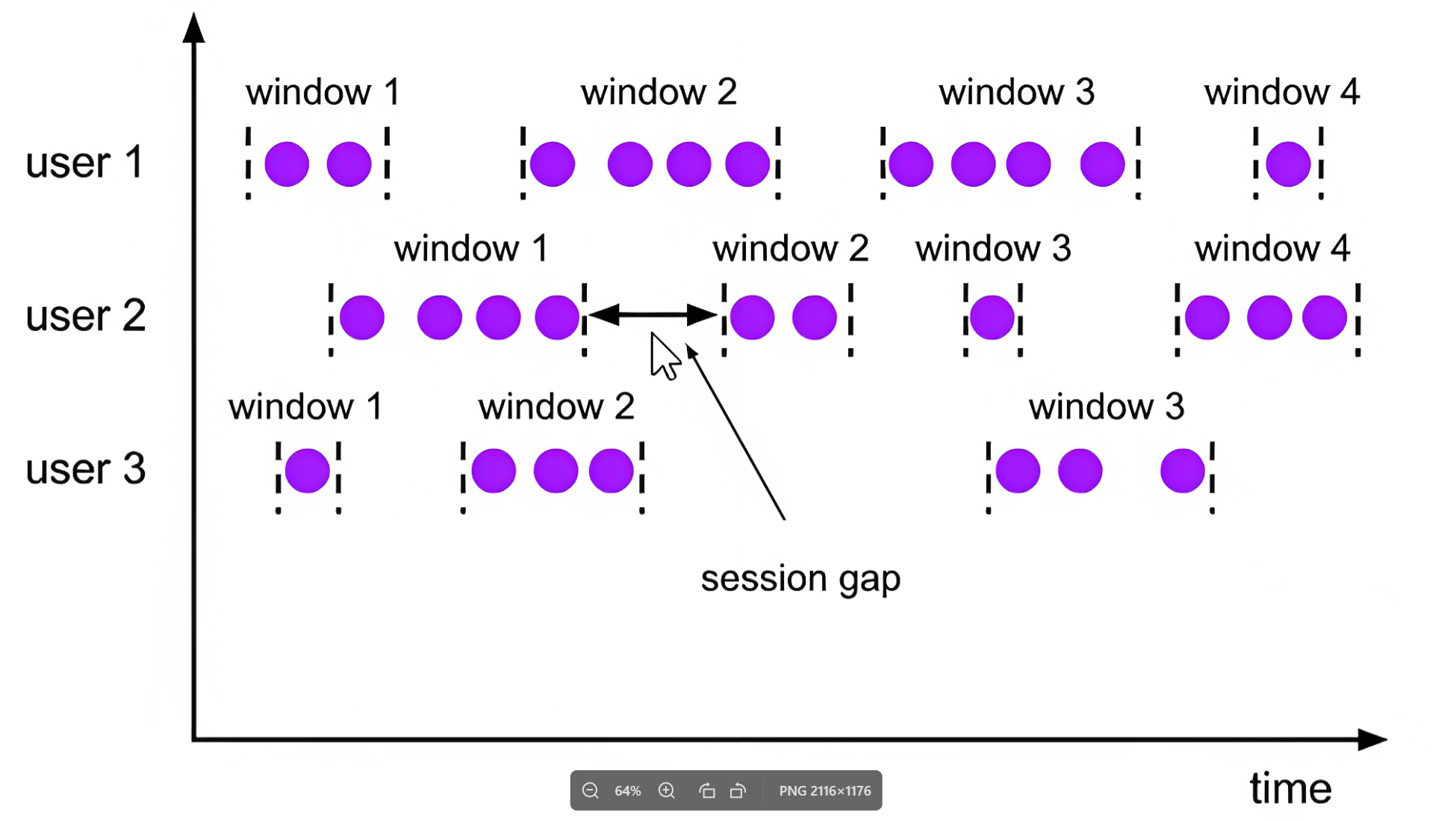
由一系列事件组合一个指定时间长度的timeout间隙组成,也就是一段时间没有接收到新数据就会生成新的窗口
特点:时间无对齐
8.1 窗口分配器 && 窗口函数
窗口分配器———window()方法
我们可以用.window()来定义一个窗口,然后基于这个window去做一些聚合或者其它处理操作。注意window()方法必须在keyBy之后才能用。Flink 提供了更加简单的.timeWindow和.countWindow方法,用于定义时间窗口和计数窗口。
sensor_1,1547718199,35.8
sensor_2,1547718201,15.4
sensor_3,1547718202,6.7
sensor_4,1547718205,38.1
sensor_1,1547718191,58.8
sensor_1,1547714191,40.8
sensor_3,1547718202,6.7
publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);// socketText nc -lk 7777DataStreamSource<String> streamSource = env.socketTextStream("localhost",7777);// 转换成SensorReading 类型DataStream<SensorReadingEntity> dataStream = streamSource.map(item ->{String[] split = item.split(",");returnnewSensorReadingEntity(split[0],Long.parseLong(split[1]),Double.parseDouble(split[2]));});// 窗口测试// dataStream.windowAll(); //globalDataStream<Integer> resultStream = dataStream
.keyBy(SensorReadingEntity::getId)// 滚动窗口 参数1为一个窗口1分钟s接收时间,参数2时间偏移15s开一个窗口.window(TumblingProcessingTimeWindows.of((Time.minutes(1)),Time.seconds(15))).aggregate(newAggregateFunction<SensorReadingEntity,AtomicInteger,Integer>(){@OverridepublicAtomicIntegercreateAccumulator(){returnnewAtomicInteger(0);}@OverridepublicAtomicIntegeradd(SensorReadingEntity sensorReadingEntity,AtomicInteger atomicInteger){
atomicInteger.incrementAndGet();return atomicInteger;}@OverridepublicIntegergetResult(AtomicInteger atomicInteger){return atomicInteger.get();}@OverridepublicAtomicIntegermerge(AtomicInteger atomicInteger,AtomicInteger acc1){int i = atomicInteger.get()+ acc1.get();
atomicInteger.set(i);return atomicInteger;}});
resultStream.print();// dataStream.keyBy(SensorReadingEntity::getId)// // 滑动窗口 1个窗口30s接收时间,窗口间隔15s 开一个窗口// .window(SlidingProcessingTimeWindows.of(Time.seconds(30),Time.seconds(15)));// dataStream.keyBy(SensorReadingEntity::getId)// // session窗口// .window(ProcessingTimeSessionWindows.withGap(Time.minutes(1)));//// dataStream.keyBy(SensorReadingEntity::getId)// // 滚动统计窗口// .countWindow(5);// dataStream.keyBy(SensorReadingEntity::getId)// // 滑动统计窗口// .countWindow(5,3);
env.execute();}
先前的窗口分配器将分组的数据做了分桶. 窗口函数是对桶数据做聚合运算.
window function定义了要对窗口中收集的数据做的计算操作可以分为两类
8.1.1 增量聚合函数(incremental aggregation functions)
- 每条数据到来就进行计算,保持一个简单的状态.
- ReduceFunction, AggregateFunction
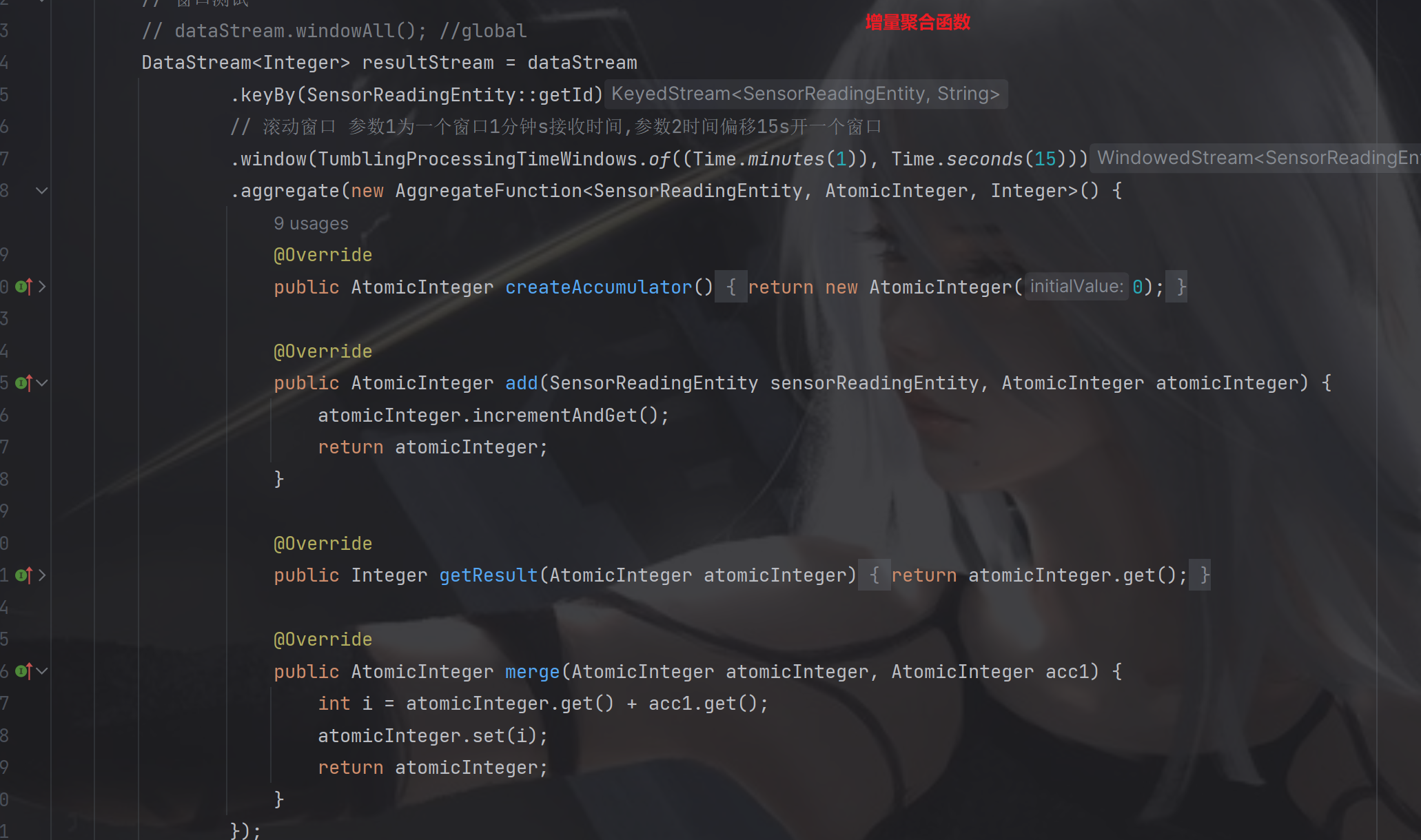 AggregateFunction 参数1 入参类型 参数2 中间累加状态 参数3 输出类型
AggregateFunction 参数1 入参类型 参数2 中间累加状态 参数3 输出类型
8.1.2 全窗口函数(full window functions)
- 先把窗口所有数据收集起来,等到计算的时候会遍历所有数据.
- ProcessWindowFunction,WindowFunction
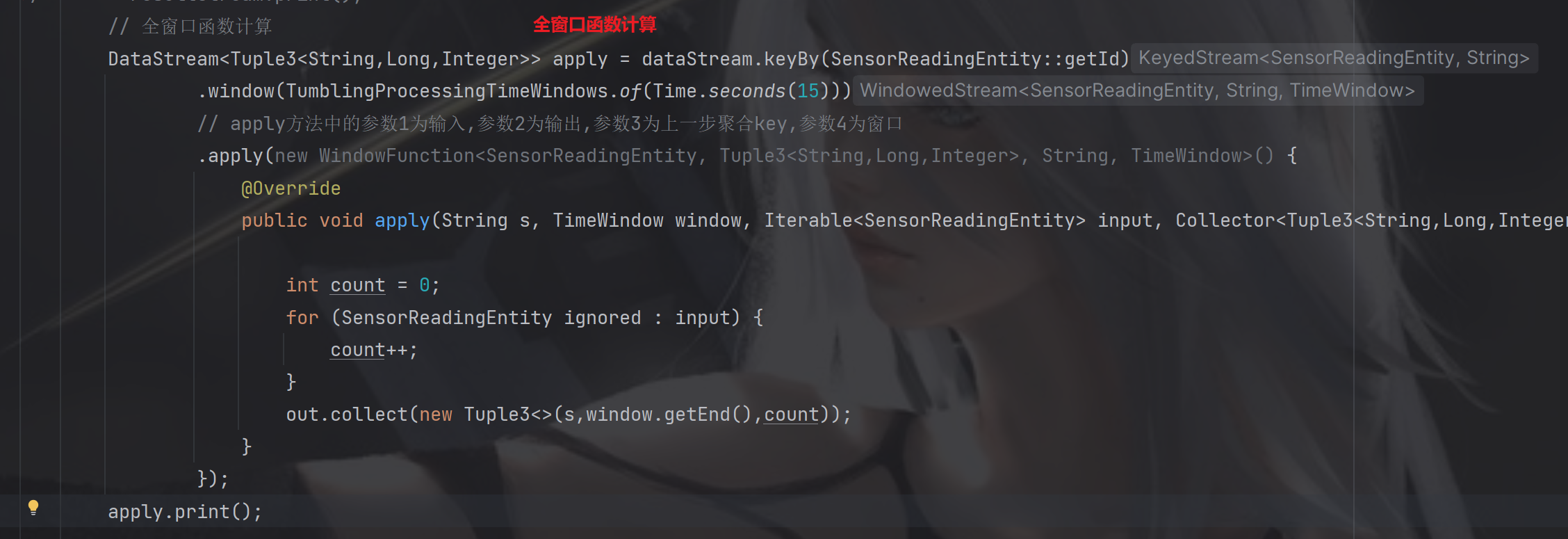
8.1.3 窗口统计函数
publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);// socketText nc -lk 7777DataStreamSource<String> streamSource = env.socketTextStream("localhost",7777);// 转换成SensorReading 类型DataStream<SensorReadingEntity> dataStream = streamSource.map(item ->{String[] split = item.split(",");returnnewSensorReadingEntity(split[0],Long.parseLong(split[1]),Double.parseDouble(split[2]));});// 开窗计数窗口DataStream<Double> aggregate = dataStream.keyBy(SensorReadingEntity::getId).countWindow(10,2).aggregate(newAvgTemp());
aggregate.print();
env.execute();}publicstaticclassAvgTempimplementsAggregateFunction<SensorReadingEntity,Tuple2<Double,Integer>,Double>{@OverridepublicTuple2<Double,Integer>createAccumulator(){returnnewTuple2<>(0.0,0);}@OverridepublicTuple2<Double,Integer>add(SensorReadingEntity sensorReadingEntity,Tuple2<Double,Integer> objects){
objects.f0 += sensorReadingEntity.getTemperature();
objects.f1 +=1;return objects;}@OverridepublicDoublegetResult(Tuple2<Double,Integer> objects){return objects.f0/objects.f1;}@OverridepublicTuple2<Double,Integer>merge(Tuple2<Double,Integer> objects,Tuple2<Double,Integer> acc1){returnnewTuple2<>(objects.f0+acc1.f0,objects.f1+acc1.f1);}}
8.1.4 其他api函数
.trigger()——触发器定义 window 什么时候关闭,触发计算并输出结果
.evictor()——移除器定义移除某些数据的逻辑
.allowedLateness()——允许处理迟到的数据
.sideOutputLateData()——将迟到的数据放入侧输出流
.getSideOutput()——获取侧输出流
8.1.5 windows api总结

九.时间定义
- Event Time 事件创建时间
- Ingestion Time: 数据进入Flink的时间
- Processing Time: 执行本地算子的本地系统时间,和操作系统相关
一般的更关心事件时间.而不是系统处理时间. 以用户产生时间为准,所见即所得.
flink默认时间语义在1.12已改为是事件时间
在Flink 1.12中,默认的流时间特性已更改为 TimeCharacteristic.EventTime,因此您不再需要调用此方法来启用事件时间支持。显式地使用处理时间窗口和计时器在事件时间模式下工作。如果您需要禁用水印,请使用 ExecutionConfig.setAutoWatermarkInterval(长). 如果你正在使用 TimeCharacteristic。IngestionTime,请手动设置合适的 WatermarkStrategy. 如果您正在使用通用的“时间窗口”操作(例如 org.apache.flink.streaming.api.datastream.KeyedStream.timeWindow (org.apache.flink.streaming.api.windowing.time.Time) 根据时间特征改变行为,请使用显式指定处理时间或事件时间的等效操作。
当然还要将事件时间关联数据的时间
,当Flink 以Event Time模式处理数据流时,它会根据数据里的时间戳来处理基于时间的算子. 由于网络、分布式等原因,会导致乱序数据的产生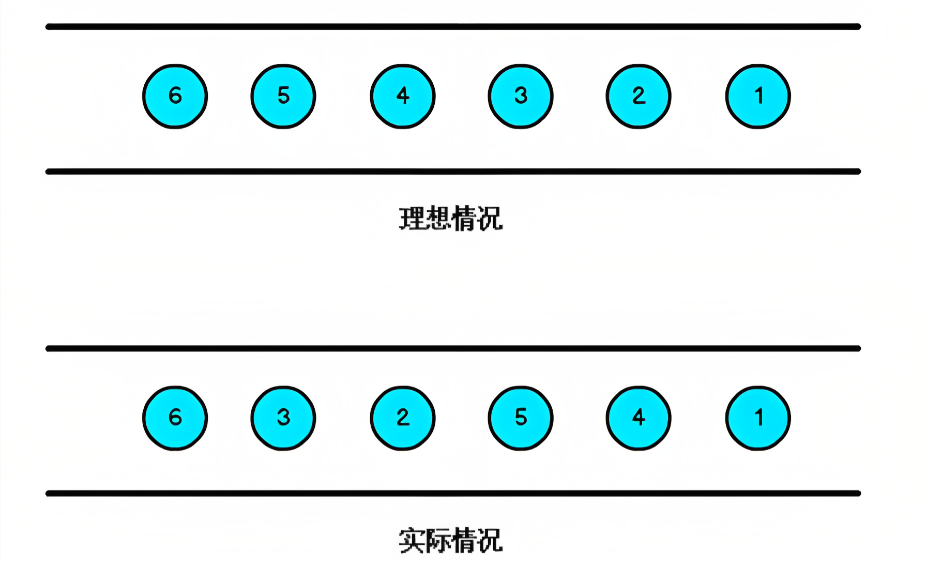
9.1 WaterMark定义
怎样避免乱序数据带来计算不正确?
遇到一个时间戳达到了窗口关闭时间,不应该立刻触发窗口计算,而是等待一段时间,等迟到的数据来了再关闭窗口
Watermark是一种衡量Event Time进展的机制,可以设定延迟触发Watermark是用于处理乱序事件的,而正确的处理乱序事件,
通常用Watermark机制结合window来实现;数据流中的Watermark用于表示timestamp小于Watermark 的数据,都已经到达了,因此,window的执行也是由Watermark触发的。
watermark用来让程序自己平衡延迟和结果正确性
watermark是一条特殊的数据记录
watermark必须单调递增,以确保任务的事件时间时钟在向前推进,而不是在后退
watermark 与数据的时间戳相关
基于上述条件. 当数据乱序来临时 —>
watermark = Max(当前窗口最大事件时间,新来的事件时间) - 设置的延迟时间
即为watermark 标准时间.当watermark 标准时间到达关闭要求,则直接关闭旧窗口
9.2 WaterMark上下游算子传递
WaterMark是慢钟标准时间, 因此广播到下游算子.
由于flink多是并行计算,那并行的上游任务WaterMark可能不相同.那下游获得的WaterMark以哪个上游任务的WaterMark为准呢?
下游WaterMark = Min(上游并行算子)
版权归原作者 呆萌小新@渊洁 所有, 如有侵权,请联系我们删除。