
一、PyFlink 的核心目标
将 Flink 能力输出到 Python 用户,进而可以让 Python 用户使用所有的 Flink 能力。
将 Python 生态现有的分析计算功能运行到 Flink 上,进而增强 Python 生态对大数据问题的解决能力。
二、PyFlink技术架构
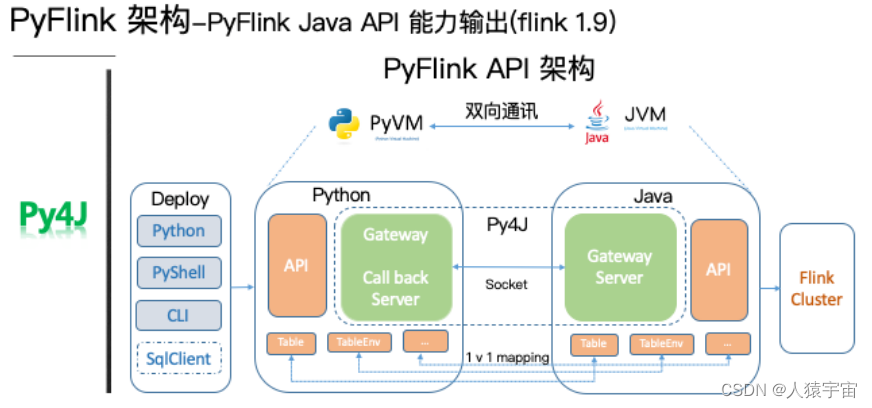
三、PyFlink实用场景
在具体的案例之前我们先简单分享一些 PyFlink 所能适用的业务场景。首先 PyFlink 既然是 Python+Flink,那其适用场景也可以从 java 和 Python 两方面去分析,第一个 Java 所适用的场景 PyFlink 都适用。
第一个,事件驱动型,比如:刷单,监控等;
第二个,数据分析型的,比如:库存,双11大屏等;
第三个适用的场景是数据管道,也就是ETL场景,比如一些日志的解析等;
第四个场景,机器学习,比如个性推荐等。
这些都可以尝试使用 PyFlink 。除此之外还有 Python 生态特有的场景,比如科学计算等。那么这么多的应用场景,PyFlink 到底有哪些可用的 API 呢?
四、PyFlink 的安装
使用具体的 API 开发之前,首先要安装 PyFlink,目前 PyFlink 支持 pip install 进行安装,这里特别提醒一下具体命令是:
pip install apache-Flink
五、PyFlink 案例-阿里云 CDN 实时日志分析
这里以一个阿里云 CDN 实时日志分析的例子来介绍如何用 PyFlink 解决实际的业务问题。CDN 我们都很熟悉,为了进行资源的下载加速。那么 CDN 日志的解析一般有一个通用的架构模式,就是首先要将各个边缘节点的日志数据进行采集,一般会采集到消息队列,然后将消息队列和实时计算集群进行集成进行实时的日志分析,最后将分析的结果写到存储系统里面。消息队列采用 Kafka,实时计算采用Flink,最终将数据存储到 MySQL。
六、kafka 收集日志的两种方式
方法一:配置文件
kafka官网已经提供了非常方便的log4j的集成包 kafka-log4j-appender,我们只需要简单配置log4j文件,就能收集应用程序log到kafka中。
#log4j.rootLogger=WARN,console,kafka
log4j.rootLogger=INFO,console
# forpackagecom.demo.kafka, log would be sent tokafka appender.
#log4j.logger.com.bigdata.xuele.streaming.SparkStreamingKmd*=info,kafka
# appender kafka
log4j.appender.kafka=kafka.producer.KafkaLog4jAppender
log4j.appender.kafka.topic=${kafka.log.topic}
# multiple brokers are separated by comma ",".
log4j.appender.kafka.brokerList=${kafka.log.brokers}
log4j.appender.kafka.compressionType=none
log4j.appender.kafka.syncSend=false
log4j.appender.kafka.layout=org.apache.log4j.PatternLayout
#log4j.appender.kafka.layout.ConversionPattern=%d [%-5p][%t]-[%l]%m%n
log4j.appender.kafka.layout.ConversionPattern=[%d]%p %m (%c)%n
# appender console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
#log4j.appender.console.layout.ConversionPattern=%d [%-5p][%t]-[%l]%m%n
log4j.appender.console.layout.ConversionPattern=[%d][%p][%t]%m%n
log4j.logger.org.eclipse.jetty=WARN
log4j.logger.org.eclipse.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
注意,需要引入maven的依赖包:
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>0.8.2.1</version></dependency>
非常简单,一个maven依赖加一个log4j配置文件即可,如果依然想写入log到本地 文件依然也是可以的,这种方式最简单快速,但是默认的的log日志是一行一行的纯文本,有些场景下我们可能需要json格式的数据。
方法二,java代码
packagecom.kafka;importjava.util.Properties;importjava.util.concurrent.Future;importorg.apache.kafka.clients.producer.KafkaProducer;importorg.apache.kafka.clients.producer.ProducerRecord;importorg.apache.kafka.clients.producer.RecordMetadata;importorg.apache.log4j.Level;importorg.apache.log4j.Logger;importcom.util.Config;publicclassKafkaUtil{static{// 修改kafka日志输出级别Logger.getLogger("org.apache.kafka").setLevel(Level.OFF);}publicstaticvoidsendMessage(String mes){KafkaProducer<String,String> producer =null;try{Properties properties =newProperties();
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("bootstrap.servers",Config.getString("bootstrap.servers"));// 声明kafka
properties.put("acks","all");// 声明kafka
properties.put("retries",0);// 请求失败重试的次数
producer =newKafkaProducer<String,String>(properties);ProducerRecord<String,String>record=newProducerRecord<String,String>(Config.getString("bootstrap.topic"), mes);Future<RecordMetadata> future = producer.send(record);System.out.println(future.get().offset()+" "+ future.get().partition());// }}catch(Exception e){
e.printStackTrace();// flag=false;
producer.close();}finally{
producer.close();}}publicstaticvoidmain(String[] args){while(true){KafkaUtil.sendMessage("null|127.0.0.1|国外|||||http://backserver/car/historyKeyAndHotKey.json|http://bd.2schome.net/|Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.19 Safari/537.36|http://backserver/car/historyKeyAndHotKey.json?keytype=0&|1470189803366185158");// try {// Thread.sleep(1000);// } catch (InterruptedException e) {//// // TODO Auto-generated catch block// e.printStackTrace();//// }}}}
七、阿里云CDN实时日志分析的具体过程
我们在来看看业务统计的需求,为了介绍方便,我们将实际的统计需求进行简化,示例中只进行按地区分组,进行资源访问量,下载量和下载速度的统计。数据格式我们只选取核心的字段,比如:uuid,表示唯一的日志标示,client_ip 表示访问来源,request_time 表示资源下载耗时, response_size 表示资源数据大小。其中我们发现我们需求是按地区分组,但是原始日志里面并没有地区的字段信息,所以我们需要定义一个 Python UDF 根据 client_ip 来查询对应的地区。好,我们首先看如何定义这个 UDF。
1、 阿里云 CDN 实时日志分析 UDF 定义
这里我们用了刚才提到的 named function 的方式定义一个 ip_to_province() 的UDF,输入是 ip 地址,输出是地区名字字符串。我们这里描述了输入类型是一个字符串,输出类型也是一个字符串。当然这里面的查询服务仅供演示,大家在自己的生产环境要替换为可靠的地域查询服务。
import re
import json
from pyFlink.table import DataTypes
from pyFlink.table.udf import udf
from urllib.parse import quote_plus
from urllib.request import urlopen
@udf(input_types=[DataTypes.STRING()], result_type=DataTypes.STRING())defip_to_province(ip):"""
format:
{
'ip': '27.184.139.25',
'pro': '河北省',
'proCode': '130000',
'city': '石家庄市',
'cityCode': '130100',
'region': '灵寿县',
'regionCode': '130126',
'addr': '河北省石家庄市灵寿县 电信',
'regionNames': '',
'err': ''
}
"""try:
urlobj = urlopen( \
'http://whois.pconline.com.cn/ipJson.jsp?ip=%s'% quote_plus(ip))
data =str(urlobj.read(),"gbk")
pos = re.search("{[^{}]+\}", data).span()
geo_data = json.loads(data[pos[0]:pos[1]])if geo_data['pro']:return geo_data['pro']else:return geo_data['err']except:return"UnKnow"
2、 阿里云 CDN 实时日志分析 Connector 定义
我们完成了需求分析和 UDF 的定义,我们开始进行作业的开发了,按照通用的作业结构,需要定义 Source connector 来读取 Kafka 数据,定义 Sink connector 来将计算结果存储到 MySQL。最后是编写统计逻辑。
在这特别说明一下,在 PyFlink 中也支持 SQL DDL 的编写,我们用一个简单的 DDL 描述,就完成了 Source Connector的开发。其中 connector.type 填写 kafka。SinkConnector 也一样,用一行DDL描述即可,其中 connector.type 填写 jdbc。描述 connector 的逻辑非常简单,我们再看看核心统计逻辑是否也一样简单:)
kafka_source_ddl ="""
CREATE TABLE cdn_access_log (
uuid VARCHAR,
client_ip VARCHAR,
request_time BIGINT,
response_size BIGINT,
uri VARCHAR
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'access_log',
'connector.properties.zookeeper.connect' = 'localhost:2181',
'connector.properties.bootstrap.servers' = 'localhost:9092',
'format.type' = 'csv',
'format.ignore-parse-errors' = 'true'
)
"""
mysql_sink_ddl ="""
CREATE TABLE cdn_access_statistic (
province VARCHAR,
access_count BIGINT,
total_download BIGINT,
download_speed DOUBLE
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://localhost:3306/Flink',
'connector.table' = 'access_statistic',
'connector.username' = 'root',
'connector.password' = 'root',
'connector.write.flush.interval' = '1s'
)
"""
3、阿里云 CDN 实时日志分析核心统计逻辑
首先从数据源读取数据,然后需要先将 clien_ip 利用我们刚才定义的 ip_to_province(ip) 转换为具体的地区。之后,在进行按地区分组,统计访问量,下载量和资源下载速度。最后将统计结果存储到结果表中。这个统计逻辑中,我们不仅使用了Python UDF,而且还使用了 Flink 内置的 Java AGG 函数,sum 和 count。
核心的统计逻辑
t_env.from_path("cdn_access_log")\
.select("uuid, ""ip_to_province(client_ip) as province, "# IP 转换为地区名称"response_size, request_time")\
.group_by("province")\
.select(# 计算访问量"province, count(uuid) as access_count, "# 计算下载总量 "sum(response_size) as total_download, "# 计算下载速度"sum(response_size) * 1.0 / sum(request_time) as download_speed") \
.insert_into("cdn_access_statistic")
4、阿里云 CDN 实时日志分析完整代码
我们在整体看一遍完整代码,首先是核心依赖的导入,然后是我们需要创建一个ENV,并设置采用的 planner(目前Flink支持Flink和blink两套 planner)建议大家采用 blink planner。
接下来将我们刚才描述的 kafka 和 mysql 的 ddl 进行表的注册。再将 Python UDF 进行注册,这里特别提醒一点,UDF所依赖的其他文件也可以在API里面进行制定,这样在job提交时候会一起提交到集群。然后是核心的统计逻辑,最后调用 executre 提交作业。这样一个实际的CDN日志实时分析的作业就开发完成了。我们再看一下实际的统计效果。
import os
from pyFlink.datastream import StreamExecutionEnvironment
from pyFlink.table import StreamTableEnvironment, EnvironmentSettings
from enjoyment.cdn.cdn_udf import ip_to_province
from enjoyment.cdn.cdn_connector_ddl import kafka_source_ddl, mysql_sink_ddl
# 创建Table Environment, 并选择使用的Planner
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(
env,
environment_settings=EnvironmentSettings.new_instance().use_blink_planner().build())# 创建Kafka数据源表
t_env.sql_update(kafka_source_ddl)# 创建MySql结果表
t_env.sql_update(mysql_sink_ddl)# 注册IP转换地区名称的UDF
t_env.register_function("ip_to_province", ip_to_province)# 添加依赖的Python文件
t_env.add_Python_file(
os.path.dirname(os.path.abspath(__file__))+"/enjoyment/cdn/cdn_udf.py")
t_env.add_Python_file(os.path.dirname(
os.path.abspath(__file__))+"/enjoyment/cdn/cdn_connector_ddl.py")# 核心的统计逻辑
t_env.from_path("cdn_access_log")\
.select("uuid, ""ip_to_province(client_ip) as province, "# IP 转换为地区名称"response_size, request_time")\
.group_by("province")\
.select(# 计算访问量"province, count(uuid) as access_count, "# 计算下载总量 "sum(response_size) as total_download, "# 计算下载速度"sum(response_size) * 1.0 / sum(request_time) as download_speed") \
.insert_into("cdn_access_statistic")# 执行作业
t_env.execute("pyFlink_parse_cdn_log")
5、阿里云 CDN 实时日志分析运行效果
我们采用 mock 的数据向 kafka 发送 CDN 日志数据,右边实时的按地区统计资源的访问量,下载量和下载速度。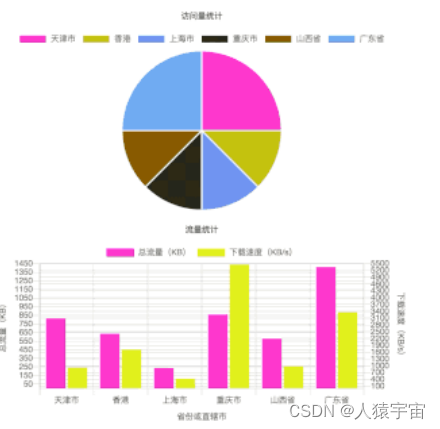
八 、PyFlink 的使用参考
https://help.aliyun.com/document_detail/207345.html
作业开发
作业提交
作业启动
作业暂停与停止
使用Python依赖
版权归原作者 人猿宇宙 所有, 如有侵权,请联系我们删除。