
目录
一. 简介
最近在学python的过程中,发现了一个好用的爬虫库
DrissionPage
—— 一个基于 python 的网页自动化工具。据具官方文档(官方网址:
https://drissionpage.cn/
)介绍:
- 它既能控制浏览器,也能收发数据包,还能把两者合而为一。
- 可兼顾浏览器自动化的便利性和 requests 的高效率。
- 它功能强大,内置无数人性化设计和便捷功能。
- 它的语法简洁而优雅,代码量少,对新手友好。
笔者在用的过程中发现还不错,语法简洁方便,可无配置运行。就写一篇文章分享一下这个工具的使用方法。
二. 使用
1. 安装方式
开始之前,我们要先安装一个这个库,注意:*
Python版本要在3.6及以上
*,我们使用
pip
安装,安装命令:
pip install DrissionPage
升级最新稳定版本版本使用:
pip install DrissionPage --upgrade
或者指定版本安装:
pip install DrissionPage==4.0.0b17
2. 基本用法
在我们的Python文件中导入
DrissionPage
库,写一个最简单的demo,我们来爬取百度的热搜榜单。
我们先来观察一下百度首页的页面结构,我们可以看到这些热搜都用到了
title-content-title
类,那我们就可以使用这个类名来获取信息。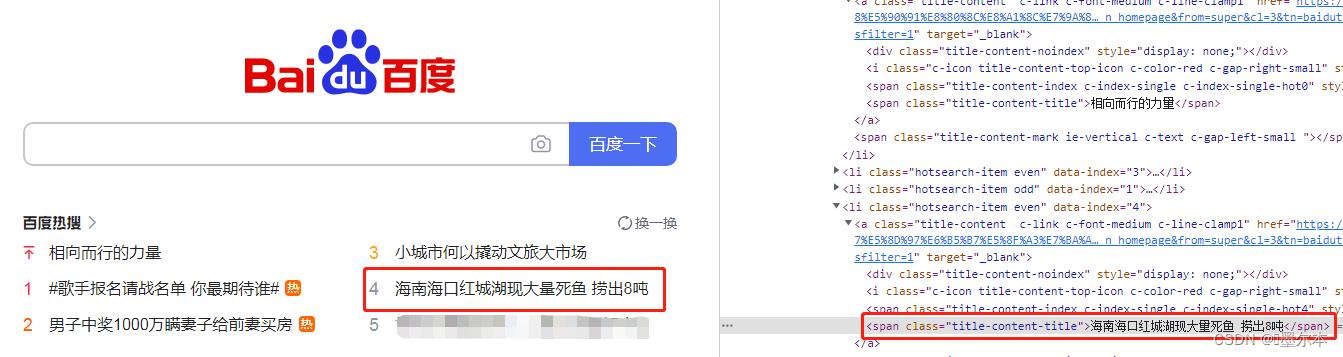
from DrissionPage import ChromiumPage
# 创建ChromiumPage对象时会在指定端口启动浏览器,或接管该端口已有浏览器。# 默认情况下,程序使用 9222 端口
page = ChromiumPage()# 只传入一个url就行,后面那些参数都有默认值
page.get('https://www.baidu.com',retry=99, show_errmsg=True, timeout=10)# 这里我们通过类名获取元素
lists = page.eles('.title-content-title')for i in lists:print(i.text)
执行这个文件,在控制台中我们看到成功获取了我们在页面上看到的那些热搜
怎么样,只要六行代码,是不是很简单呢,那我们接着往下看
在上面的demo中,我们可以使用class类名来获取指定元素,那么你可能要问了,既然能通过类名,是不是也能通过id,标签呢。是的,DrissionPage库提供了多种定位元素的方式,这里列举一下,我们还是以百度首页的
百度一下
按钮为例:
# 获取 id 为 su的元素,也就是搜索按钮
div1 = page.ele('#su')# 获取 type 属性为 submit的元素
p1 = page.ele('@type=submit')# 获取包含“百度一下”文本的元素
div2 = page.ele('百度一下')# 获取所有input元素
div_list = page.eles('tag:input')
ele
是获取匹配到的第一个元素,
eles
是获取匹配到的所有元素,返回一个
list
,还有更多的定位元素的方式,这里就不再赘述了,可移步官网 https://drissionpage.cn/get_elements/usage。
★ 这里解释下
get()
方法:该方法用于跳转到一个网址。当连接失败时,程序会进行重试。该方法返回一个
bool
类型,表示是否连接成功。
参数名称类型说明
url
str
目标 url,可指向本地文件路径 必填
retry
int
重试次数,为None时使用页面参数,默认 3
timeout
float
加载超时时间(秒)
interval
int
重试间隔(秒),为None时使用页面参数,默认 2
show_errmsg
bool
连接出错时是否显示和抛出异常,默认False
3. 模式
在上面的demo中,你会发现启动的时候会自动打开浏览器,那么你可能想,我就要悄悄的爬,不想打开浏览器呢?这个也有的,也就是我们要将的无头模式,还是那段代码,我们只需要加一个
ChromiumOptions
配置就可以以无界面模式启动浏览器。
headless
该方法用于设置是否以无界面模式启动浏览器。
from DrissionPage import ChromiumPage,ChromiumOptions
co = ChromiumOptions().headless(True)
page = ChromiumPage(co)
page.get('https://www.baidu.com',retry=99, show_errmsg=True, timeout=10)
lists = page.eles('.title-content-title')for i in lists:print(i.text)
4. 元素交互
在示例中我们看到页面上只有几条热搜,我们想要获取更多的信息怎么办呢,我们可以看到点击换一换按钮,即可加载更多信息,这也就需要我们要与页面进行交互。如你所知,库也具有元素交互的能力。这里我们以
id
方式获取到这个元素,并且调用
click()
方法进行操作。
from DrissionPage import ChromiumPage,ChromiumOptions
co = ChromiumOptions().headless(False)
page = ChromiumPage(co)
page.get('https://www.baidu.com',retry=99, show_errmsg=True, timeout=10)# 收集数据 defgatherDataBD(page):
lists = page.eles('.title-content-title')for i in lists:print(i.text)# 每次循环完成之后,点击换一换按钮
page.ele('#hotsearch-refresh-btn').click()for _ inrange(3):
gatherDataBD(page)# 如果不继续用该浏览器,可调用此方法关闭哦
page.close()
运行过程中,你会在页面上看到换一换按钮被真实的点击,控制会打印更多的数据。
那么你可能要问了,既然可以这样,为什么不能那样呢?
下面我们以gitee为例,演示一下脚本自动输入元素,并自动登录功能。这里我们先获取到两个输入框,然后调用
input()
方法去输入值,然后我们通过属性值去获取登录按钮并调用
click()
点击事件进行登录。
from DrissionPage import ChromiumPage,ChromiumOptions
co = ChromiumOptions().headless(False)
page = ChromiumPage(co)
page.get('https://gitee.com/login?redirect_to_url=%2F')
page.ele('#user_login').input('你的账号')
page.ele('#user_password').input('你的密码')
page.ele('@type=submit').click()
效果如下:可以看到信息已被填入输入框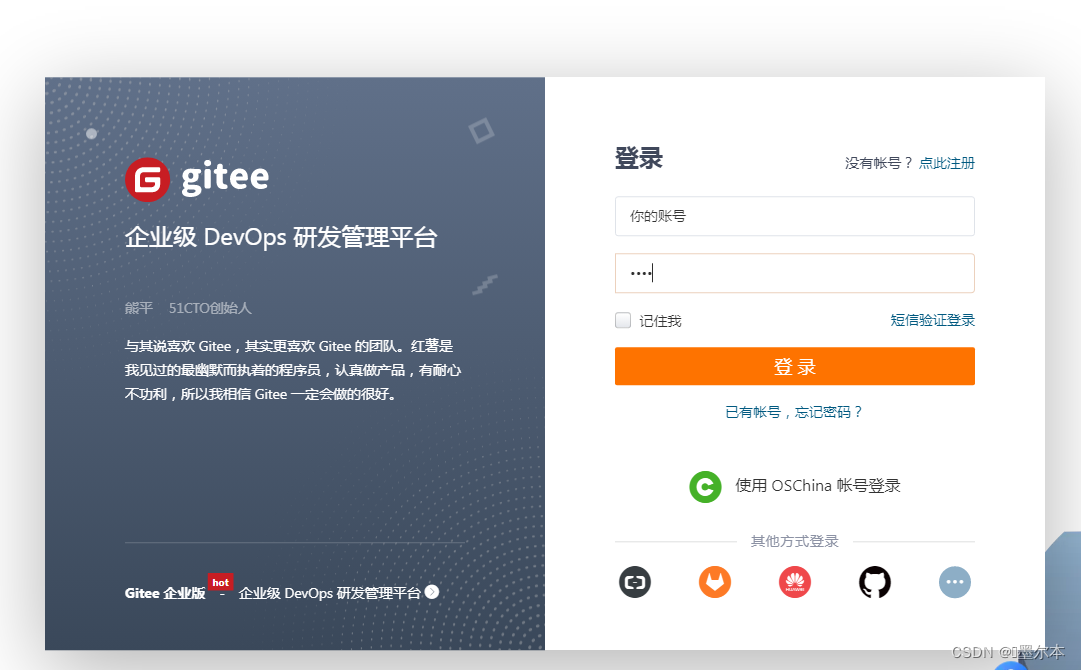
这里提醒大家遵守相关规定合理使用哦!
DrissionPage还提供了很多有用的元素交互的事件,如
focus()
使元素获取焦点、
hover()
悬停在元素上、
click.multi()
实现左键多次点击元素,更多事件请移步:https://drissionpage.cn/ChromiumPage/ele_operation
4. SessionPage
那么如果我们想通过调接口的方式去爬取数据呢,这就用到了
SessionPage
模式了。顾名思义,SessionPage是一个使用
Session(requests 库)
对象的页面,它使用 POM 模式封装了网络连接和 html 解析功能,使收发数据包也可以像操作页面一样便利。
这里我就自己写一个接口,就不用真实的网站接口了。以下是我接口返回的数据: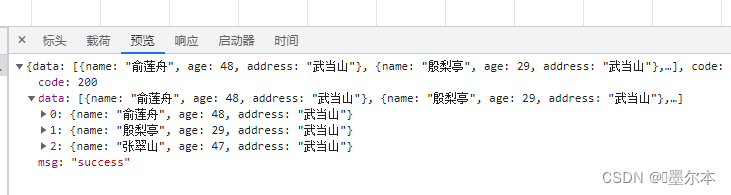
from DrissionPage import SessionPage
apiObj = SessionPage()
apiObj.post('http://localhost:8000/getDataList', retry=5, show_errmsg=True, timeout=10)# 这里可以调用接口获取数据
result = apiObj.json
print(result)
控制台打印如下:可见已经正确获取到
5. 运行JS
假设你有一个自动填充表单的需求,有一个type为
date
类型的
input
框,这里我们使用原生
html
演示,页面效果如下: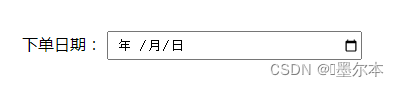
前端代码简化如下:
<!DOCTYPEhtml><html><head><title>表单</title><metacharset="utf-8"><metaname="viewport"content="width=device-width, initial-scale=1"></head><body><formid="orderForm"><divclass="form-group"><labelclass="item-label">下单日期:</label><inputtype="date"name="orderDate"class="normal-input"></div></form></body></html>
你会发现这个框你是没法输入的,你如果直接用
DrissionPage
的
input()
方法,你会发现输入无效。
page.ele('@name=orderDate').input('2024-06-10')
这里看到这个input框,确实被点击了,但是值没有进去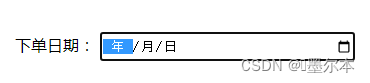
要想对于这种类型的input赋值,只需要在上面的input方法中传一个
by_js
即可,即使用
js
方式输入
page.ele('@name=orderDate').input('2024-06-10',by_js=True)
输入成功:
input()方法接收3个参数:
参数名称类型默认值说明
vals
Any
False
文本值或按键组合,对文件上传控件时输入路径字符串或其组成的列表
clear
bool
False
输入前是否清空文本框
by_js
bool
False
是否用 js 方式输入,为True时不能输入组合键
通过上面的实例你已经知道DrissionPage是可以
执行js
代码的,其实DrissionPage的很多方法都可以以js方式执行,比如
click()
、
to_upload()
。当你发现在使用某些方法无效的时候,不妨试着传入一个
by_js=True
试试,或许有奇效。
除了其中方法提供js执行方式外,
DrissionPage
还可以执行用户自己编写的
js脚本
。
还是上面的那个input时间选择器,我们可以使用以下代码实现:
input_ele = page.ele('@name=orderDate')
input_ele.run_js("document.querySelector('[name=orderDate]').value = '2024-05-25'")# 这两种都可以达到同样的效果,下面的this即指代当前元素
input_ele.run_js("this.value = '2024-06-18'")

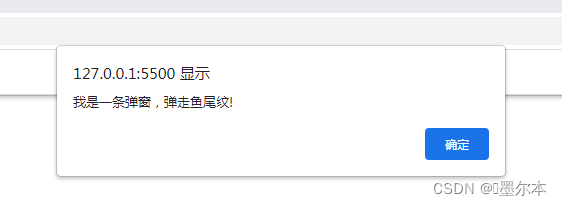
比如我们要打开一个弹窗:
page.run_js('alert("我是一条" + arguments[0] + ",弹走" + arguments[1]);','弹窗','鱼尾纹!')
run_js的参数列表:
参数名称类型默认值说明
script
str
必填js 脚本文本或脚本文件路径
*args
-
无传入的参数,按顺序在js文本中对应
arguments[0]
、
arguments[1]
…
as_expr
bool
False
是否作为表达式运行,为
True
时
args
参数无效
timetout
float
None
js 超时时间,为
None
则使用页面
timeouts.script
设置
6. 结语
好了,以上就是
DrissionPage
基本的使用方式了,你学会了吗?后续我会继续更新本文,介绍更多爬虫实用的方法。觉得本文对您有所帮助的话,可以点个赞支持一下哦!
版权归原作者 ℳ墨尔本 所有, 如有侵权,请联系我们删除。