
UML对系统架构的定义是:系统的组织结构,包括系统分解的组成部分,它们的关联性,交互,机制和指导原则,例如对系统群就是定义各子系统的功能和职责,如贷款系统群可能分为进件申请、核额、交易账务、贷后管理、管理台等子系统,对于系统就是定义各模块的功能和层次,例如管理台包括权限管理、用户管理、交易管理、逾期管理、统计分析等功能。
技术架构是指从技术实现层面描述系统,主要是根据系统架构组成部分确定每层使用什么技术框架,例如中间件、WebService等。
那对于数据仓库系统群具体可以分为哪些部分以及他们的具体实现技术如何呢?以下是银行数据仓库的系统功能图:

1、数据源:主要是指行内交易系统、外部采购或合作的第三方数据等3类、包括结构化数据以及非结构化的数据,结构化数据主要是存储在各个行内系统数据库中的表数据,非结构化数据包括图片、语音、文档等类型的数据。
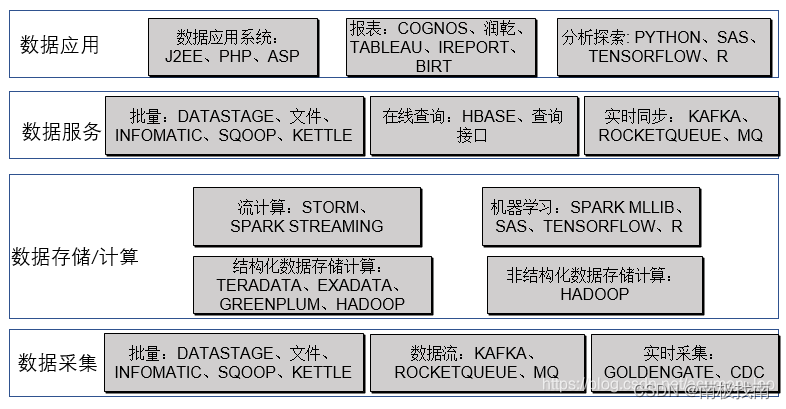
2、数据采集:即如何将数据从数据源获取到数据仓库中,就是我们常说的ETL随着数据仓库功能的发展这部分不仅仅包括批量数据获取还包括实时数据流以及数据库数据实时采集:
(1)批量采集:主要包括从数据源获取大批量的数据,这是银行数据仓库主要的数据采集方式,批量采集的采集数据频率较低,一般是每日凌晨获取上一天的数据,有些场景也可以每小时采集一次,由于采集的数据量一般较大,对数据源也有IO的影响,因此不建议采集频率太高。批量采集需要支持从关系型数据库、内存数据库、文件中批量获取并加载到数据仓库中。
在技术实现中,批量采集工具需要能支持多种数据源的采集和加载,批量采集可选择的工具较多,可以采用商业化软件如IBM的DATASTAGE以及INFORMATICA公司的INFORMATICA,也可以采用开源的SQOOP和KETTLE。也可以采用各关系型数据库以及HADOOP自带的文件导出和导入功能。
(2) 实时采集:指实时同步源系统的数据库数据到数据仓库,这样可以在数据仓库中实时分析数据。实时采集通过专门的工具监控源系统数据库日志进行数据同步,数据源系统无需改造,这种采集方式针对数据统计时效性非常高的场景。
在技术实现中,实时采集工具需要支持从多种类型数据源到多种类型目标数据库的实时同步,这块商业化软件比较成熟,如ORACLE的GOLDENGATE、IBM的InfoSphere Change Data Capture等软件。开源软件中kettle也支持数据库实时同步,但需要在源表增加时间戳字段。
(3)数据流采集:即通过Queue的方式从数据源系统获得数据流消息,数据仓库实时获取Queue中的消息进行实时数据流计算。这种数据采集方式也是面向统计时效非常高的场景,需要数据源系统增加实时发送消息的功能。
在技术实现中,由于数据流计算在互联网公司使用广泛,涌现出许多优秀的开源软件,如开源的KAFKA、ROCKETQUEUE等QUEUE工具,可以支持实时监控文件、数据库的变化并将变化数据发送到QUEUE中的开源软件FLUME。对于MYSQL也可以通过BINLOG和SHYIKO监控MYSQL日志,将数据变化发送到QUEUE中,那在商业化软件中IBM的MQ是各银行经常使用的中间件。
3、数据存储/计算:数据存储计算是数据仓库的主要功能。数据存储主要指结构化数据和非结构化数据的按格式存储,计算指基于存储的数据进行关联、汇总、数值计算等批量处理、实时流计算和复杂的机器学习。
实时流计算主要指对大规模流动数据在不断变化的过程中实时地进行分析,比如实时展示目前银行所有转账的笔数和汇总金额。需要将每笔转账进行不断计算。目前在银行中应用场景还较少,但随着互联网渠道的发展后续也将出现更多的应用场景。
机器学习是专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善,简单来说就是通过数据来发现规律,累积经验,并对新的数据进行分类或预测。比如通过学习近1年的上证指数及交易量的变化来预测明天的上证指数。目前炒的人工智能、深度学习也是属于机器学习范围。目前银行在风控、反欺诈、精准营销等方面也逐步在使用多种机器学习算法来提高成功率。
由于数据仓库是银行的数据枢纽,银行的所有业务数据都会在数据仓库保留,因此数据量较大,一般小银行数据量在TB级,股份制银行大概在PB级,国有大银行在ZB级。因此存储和计算的的可扩展性、性能都很重要。那在目前银行中数据仓库的存储和计算一般采用MPP数据库(大规模并行数据库)和HADOOP相结合的技术方案。
(1)MPP数据库:主要是面向结构化数据存储、批量计算和机器学习。在HADOOP出现前,商用的MPP数据库是数据仓库的主流技术平台,它使用简单,同时具有超大规模计算能力和良好的计算性能、扩展性。如TERADATA公司的TERADATA数据库、ORACLE公司的ORACLE一体机、IBM的NETEZZA一体机。其中TERADATA公司的TERADATA数据库在早期是一枝独秀,我国国有大银行的数据仓库最早建立时大部分都采用了TERADATA数据库。近年来ORACLE的EXADATA市场占有率也逐步提升,开源的MPP数据库最有名的是由商业转为开源GREENPLUM,目前腾讯云的TIBASE、阿里云的HybridDB for PostgreSQL都是基于GREENPLUM优化的。
(2)HADOOP平台:HADOOP平台支持结构化数据和非结构化数据的存储和计算。由于MPP数据库价格高,且扩展性也有一定局限。很难满足互联网公司超大数据量及非结构化数据的计算需求,因此HADOOP软件生态体系应运而生并发展越来越成熟,成为互联网公司大数据处理的标配平台。2015年左右,随着HADOOP平台的完善及商用(商用版本如华为、星环科技;开源版本如CLOUDERA、Hortonworks),银行也逐步使用HADOOP平台和MPP数据一起作为数据仓库的存储和计算平台。其中批量计算一般使用HIVE和SPARK,流计算一般使用STORM和SPARKSTREAMING,机器学习可以采用HADOOP生态的SPARKMLLIB、MAHOUT,也可以使用TENSORFLOW、SAS、R等支持HADOOP平台专门的机器学习工具,目前许多公司在研发推出的人工智能平台(机器学习建模平台)也都把HADOOP平台作为数据存储和计算平台,如第四范式、星环科技等。

4、数据服务:数据服务主要指如何为银行其它系统提供数据服务,随着数据仓库体系的发展,数据仓库不仅仅能按批量的方式提供数据计算结果,还可以实时提供数据服务。
(1)批量接口:按约定的接口方式将数据批量提供给数据应用系统,一般每天1次,可以按文件的方式放到约定的服务器,也可以通过数据采集部分提到的ETL工具直接将数据同步到应用系统的数据库中。
(2)在线查询:提供实时查询的接口,并发布到银行交易总线,由其他业务系统或数据系统实时调用,比如银行的每年的账单总结(类似支付宝每年账单)一般由数据仓库根据每个客户1年的交易流水,统计出转账、消费、收入等数据并提供给渠道系统如手机银行、网上银行进行展示。那在技术实现方面,接口服务开发一般按各行的开发规范来实现,如web service或http+xml,大部分银行使用JAVA进行开发,如果接口TPS不高,一般的MPP数据库也足够支持,无需进行数据移动,如果TPS比较高,可以将数据加工结果放到HADOOP HBASE进行数据存储和查询。
(3)实时同步:实时同步主要是实时数据流计算后将结果实时同步给数据使用系统,同时将结果发布到QUEUE中,由目标系统进行订阅,实时获取。

5、数据应用:数据应用主要是将数据通过数据服务提供给各应用系统,由各系统进行数据分析和成果展示。那主要有以下几类:
(1)数据应用系统:主要指使用数据的系统,在银行包括客户关系管理、管理会计、绩效管理、新资本协议系统群等数据系统,也包括核心、贷款等交易系统。
(2)报表平台:报表平台能将数据快速展示成图表、能通过建立数据立方体(CUBE)提供数据钻取(向上或向下变换数据分析维度)功能,方便业务人员快速查询和分析数据。那报表工具目前商用的比较成熟,展示也更美观,常见的有COGNOS、润乾报表、TABLEAU等,开源的报表工具功能较弱,常用的有birt、ireport、jasperreport、KYLIN(基于hadoop建立CUBE)等。
(3)分析探索:有的银行也叫数据实验室或分析集市,主要指提供给业务人员自行分析的平台,银行业务部门的分析人员经常使用SQL自行分析数据,也会使用SAS或R、PYTHON进行数据挖掘,随着AI技术的深入,也逐步在尝试TENSORFLOW等深度学习的工具来分析银行数据。由于数据分析工作时间不固定,且消耗计算资源较大,因此一般都是单独给业务人员搭建一套或多套的分析环境,每套环境包括HADOOP或数据库作为数据存储,SAS、R、TENSORFLOW等作为分析引擎。同时还需要定期(一般T+1)更新分析环境的数据,提高数据分析的及时性。
6、调度平台:调度平台主要进行各数据采集、加载、计算作业的任务编排和自动运行,比如并行调度作业A、B、C,都结束后调度作业D;调度平台需要支持多操作系统、可运行多种类型脚本或程序,并具有良好的扩展性和可用性,调度平台不仅仅调度数据仓库的加工作业,也需要调度各数据类系统的数据处理任务。使各系统作业能无缝衔接,将数据从源系统到数据仓库、到数据应用系统和数据结果应用全流程串联起来。一般的银行的调度平台每天调度的作业上万个,一些大行每天调度任务数十万个,因此一个稳定、高效、易操作的调度系统不可缺少。目前调度工具比较多,商业化的有IBM CONTROL-M、先进数通的MOIA等,开源的如azkaban、OOZIE等,由于调度系统需要调度各系统并和行内的监控系统进行集成,因此实施时需要一定的客户化工作。
7、运维监控:主要对数据仓库体系中各系统进行技术监控以及调度作业监控,ETL工具、MPP数据库以及HADOOP体系软件都带有监控工具,但还是需要进行一些客户化工作和各银行自有监控体系相结合,在统一界面进行监控、预警、按优先级进行生产问题处理。
8、数据管理:那数据仓库有那么多数据,我们怎么知道需要的数据在哪里?数据质量怎么样?某一个数据字段发生变化会有什么影响?那就需要对数据进行管理或者治理,数据管理就是对数据仓库中的元数据、数据定义、数据质量进行管理,确保数据的规范性、及时性、可追溯性,主要包括以下几个方面:
(1)数据标准:数据标准是指制定和推广应用统一的数据分类分级、记录格式及转换等标准,简单说就是定义各数据表字段的格式及代码值,例如货币种类定义10位长度,其中USD表示美元、CNY表示人民币……那数据标准应该是银行整体的标准,适用于全行的所有系统,但由于各系统建设时已经各有定义,所有一般数据标准都在数据仓库进行标准化,将各源系统字段代码转换到数据标准定义的字段代码,即数据仓库的字段代码。那数据标准系统主要是定义了各字段的类型、长度、精度、代码值以及源系统字段代码值转换到数据标准代码值的映射关系。
(2)元数据管理:元数据指描述数据的数据,比如数据表和数据字段的定义以及关系,那在元数据中除了查询数据仓库中各表和字段的定义外,最重要的还有两个功能:血缘分析和影响分析。血缘分析指字段X是由哪些源表字段按什么规则加工而成的,也就是说字段X的“祖宗”是谁;那影响分析指字段X变化了,比如增加了字段长度或字段含义发生了变化,那会影响到后续哪些字段,也就是字段X的“子孙”是谁;那这两个功能在日常数据分析中使用较多,特别是影响分析,源系统已采集的表结构有变化就会需要分析影响并进行同步修改。
(3)数据质量:数据质量是指数据的可用性、标准规范性、正确性的检查以及数据质量整改的管理流程。由于数据源系统因为人工录入标准不清晰、录入差错、系统异常等原因导致数据差错,例如企业类型字段应该填写大、中、小微3种类型,客户经理对认定的标准不清晰将中型企业填写为了大型企业。例如对公客户地址大部分字段都没有填写;那如何发现这些数据质量问题并通过一系列流程进行数据修改,提高数据准确性和可用性就是数据质量需要做的事情。因此数据质量不仅仅是一个系统、许多数据检验规则,还有一整套数据修改和管理的流程。
以下是平台各部分的技术参考实现,数据管理的系统、运维系统由于客户化程度较高就暂不提供参考:
目前各种云平台已经也提供了数据仓库的技术服务,那从技术功能、性能、可扩展性上可以满足银行的需求,但由于银行的用户数据相当敏感和重要,数据安全非常重要。短时间看,银行数据仓库上共有云还不太现实,但在银行引入私有云及数据仓库技术组件是现阶段更可能实现的方式。
以上是银行数据仓库的整体架构,也可供其他各行业数据仓库架构设计参考,谢谢!
————————————————
版权声明:本文为「acumen_leo」博主
的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/acumen_leo/article/details/90574233
版权归原作者 南极找南 所有, 如有侵权,请联系我们删除。