
一.认识Spark
1.什么是Spark
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。

Spark不仅仅可以做类似于MapReduce的离线数据计算,还可以做实时数据计算,并且它还可以实现类似于Hive的SQL计算,等等,所以说它是一个统一的计算引擎。它适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理,迭代算法,交互式查询,流处理。通过在一个统一的框架下支持这些不同的计算,spark使我们可以简单而低耗地把各种处理流程整合在一起。
2.Spark简史
Spark 是于 2009 年作为一个研究项目在加州大学伯克利分校 RAD 实验室(AMPLab 的前身)诞生。实验室中的一些研究人员曾经用过 Hadoop MapReduce。他们发现 MapReduce在迭代计算和交互计算的任务上表现得效率低下。因此,Spark 从一开始就是为交互式查询和迭代算法设计的,同时还支持内存式存储和高效的容错机制。 2009 年,关于 Spark 的研究论文在学术会议上发表,同年Spark 项目正式诞生。其后不久, 相比于 MapReduce,Spark 在某些任务上已经获得了10 ~ 20 倍的性能提升。2011 年,AMPLab 开始基于 Spark 开发更高层的组件,比如 Shark(Spark 上的 Hive)1 和 SparkStreaming。这些组件和其他一些组件一起被称为伯克利数据分析工具栈(BDAS,https://amplab.cs.berkeley.edu/software/)。Spark 最早在 2010 年 3 月开源,并且在
2013 年 6 月交给了 Apache 基金会,现在已经成了 Apache 开源基金会的顶级项目。

3.Spark的特点
(1)快速
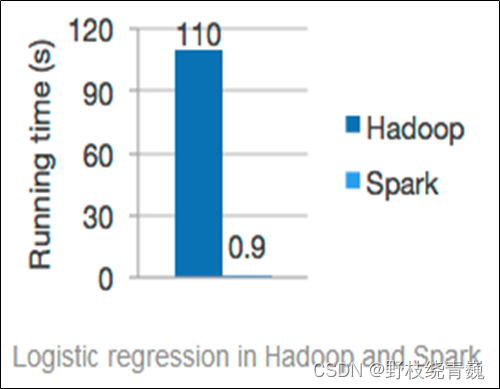
Spark的中间数据存放于内存中,有更高的迭代运算效率
(2)易用
Spark支持使用Scala、Python、Java及R语言快速编写应用。同时Spark提供超过80个高阶算子,使得编写并行应用程序变得容易,并且可以在Scala、Python或R的交互模式下使用Spark。
(3)通用
Spark可以与SQL、Streaming及复杂的分析良好结合。Spark还有一系列的高级工具,包括Spark SQL、MLlib(机器学习库)、GraphX(图计算)和Spark Streaming(流计算),并且支持在一个应用中同时使用这些组件。

(4)随处运行
用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive、Tachyon和任何分布式文件系统读取数据。
(5)代码简洁
Spark支持使用Scala,Python等语言编写代码

4.数据定义
结构化数据:即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据。
非结构化数据:不方便用数据库二维逻辑表来表现的数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。
5.MapReduce和Spark的区别
(1)Spark的速度比MapReduce快,Spark把运算的中间数据存放在内存,迭代计算效率更高;mapreduce的中间结果需要落地,需要保存到磁盘,比较影响性能;
(2)spark容错性高,它通过弹性分布式数据集RDD来实现高效容错;mapreduce容错可能只能重新计算了,成本较高;
(3)spark更加通用,spark提供了transformation和action这两大类的多个功能API,另外还有流式处理sparkstreaming模块、图计算GraphX等;mapreduce只提供了map和reduce两种操作,流计算以及其他模块的支持比较缺乏,计算框架(API)比较局限;
(4)spark框架和生态更为复杂,很多时候spark作业都需要根据不同业务场景的需要进行调优已达到性能要求;mapreduce框架及其生态相对较为简单,对性能的要求也相对较弱,但是运行较为稳定,适合长期后台运行;
(5)Spark API方面- Scala: Scalable Language, 是进行并行计算的最好的语言. 与Java相比,极大的减少代码量(Hadoop框架的很多部分是用Java编写的)。
6.Spark的生态圈
(1)Spark Core
Spark的核心,提供底层框架及核心支持。
(2)BlinkDB
一个用于在海量数据上进行交互式SQL查询的大规模并行查询引擎,允许用户通过权衡数据精度缩短查询响应时间,数据的精度将被控制在允许的误差范围内。
(3)Spark SQL
可以执行SQL查询,支持基本的SQL语法和HiveQL语法,可读取的数据源包括Hive、HDFS、关系数据库(如MySQL)等。
(4)SparkStreaming
可以进行实时数据流式计算。
(5)MLBase
是Spark生态圈的一部分,专注于机器学习领域,学习门槛较低。
MLBase由4部分组成:MLlib、MLI、ML Optimizer和MLRuntime。
(6)Spark GraphX
图计算的应用在很多情况下处理的数据量都是很庞大的。如果用户需要自行编写相关的图计算算法,并且在集群中应用,难度是非常大的。而使用GraphX即可解决这个问题,因为它内置了许多与图相关的算法,如在移动社交关系分析中可使用图计算相关算法进行处理和分析。
(7)SparkR
AMPLab发布的一个R语言开发包,使得R语言编写的程序不只可以在单机运行,也可以作为Spark的作业运行在集群上,极大地提升了R语言的数据处理能力。
二.了解Spark运行架构和原理
7.Spark的架构

基本组件
(1)客户端
用户提交作业的客户端。
(2)Driver
运行Application的main()函数并创建SparkContext。
(3)SparkContext
整个应用的上下文,控制应用的生命周期。
(4)ClusterManager
资源管理器,即在集群上获取资源的外部服务,目前主要有Standalone(Spark原生的资源管理器)和YARN(Hadoop集群的资源管理器)。
(5)SparkWorker
集群中任何可以运行应用程序的节点,运行一个或多个Executor进程。
(6)Executor
执行器,在Spark Worker上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executor。
(7)Task
被发送到某个Executor的具体任务。
8.Spark的运行模式

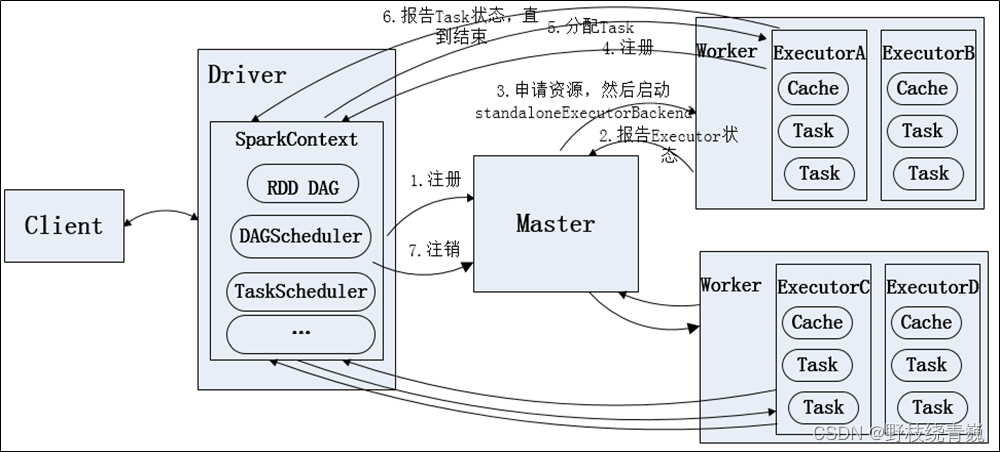
(1)Standalone模式:独立服务器模式使用内置的调度器,因而不需要任何外部调度器,如YARN或Mesos。要以独立服务器模式安装Spark,需要将Spark的二进制安装文件复制到集群的所有机器上。
独立服务器模式下,客户端可通过spark-submit或Spark shell与集群通信。无论那种情况,driver都会与Spark主节点进行通信,以便获取worker节点的信息,此后executor将在worker节点上启动来执行应用。多个客户端可同时与集群通信,然后再worker节点上创建各自的executor,每个客户端都有自己的driver组件。
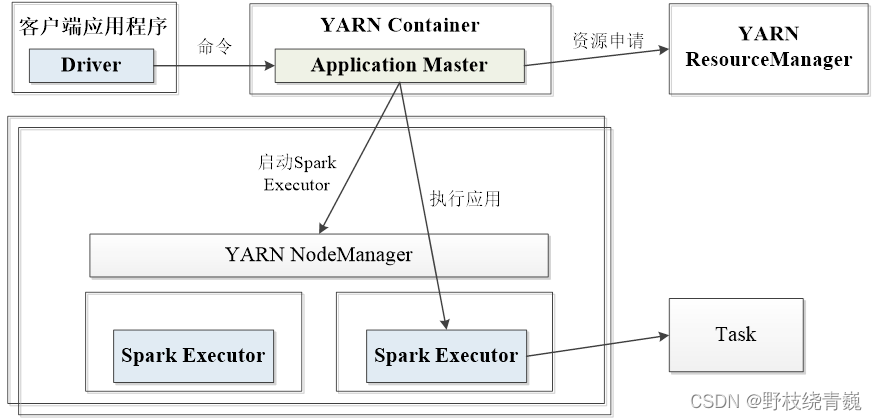
(2)Yarn模式
yarn-cluster运行流程:在集群模式下,driver在集群中的某个节点(一般是应用程序的主节点)上运行。客户端首先与资源管理器通信,请求资源并运行Spark作业。资源管理器会分配容器(0号容器)并响应客户端。然后客户端向集群提交代码,并在0号容器内启动driver和Spark应用主节点。driver与Spark应用主节点协同工作,然后在由资源管理器分配的容器上创建executor。
YARN容器可位于由节管理器控制的任何容器上。因此所有的资源分配都由资源管理器负责。
Spark应用主节点与资源管理器进行沟通,以获取其他容器来启动executor。
在YARN集群模式下,没有shell,因为driver本身在YARN内部。

yarn-client运行流程:在YARN客户端模式下,driver在集群之外的节点(一般都是客户端节点)上运行。driver首先需要与资源管理器通信,从而请求资源并运行Spark作业。资源管理器会分配容器(0号容器)并响应driver。driver在0号容器中启动Spark应用主节点。Spark应用主节点在资源管理器分配的容器中创建executor。
YARN容器可位于集群中由节点管理器控制的任一节点,因此所有的资源分配都由资源管理器负责。
Spark应用主节点与资源管理器进行沟通,以获取其他容器来启动executor。
9.Spark核心数据集
RDD(ResilientDistributedDatasets弹性分布式数据集),可以简单的把RDD理解成一个提供了许多操作接口的数据集合,和一般数据集不同的是,其实际数据分布存储于一批机器中(内存或磁盘中)。
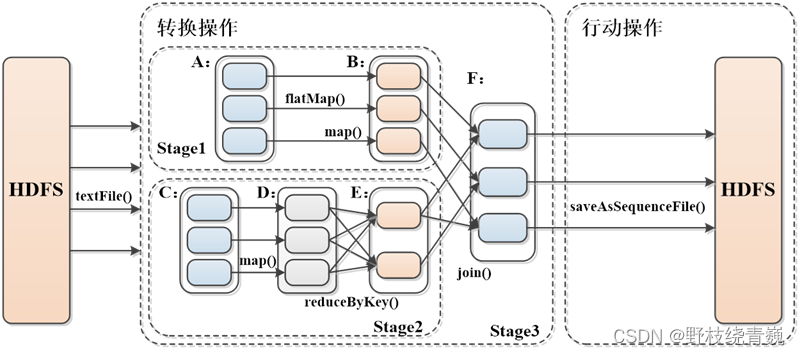
 转换算子和行动算子
转换算子和行动算子
 Spark RDD转换和操作示例
Spark RDD转换和操作示例
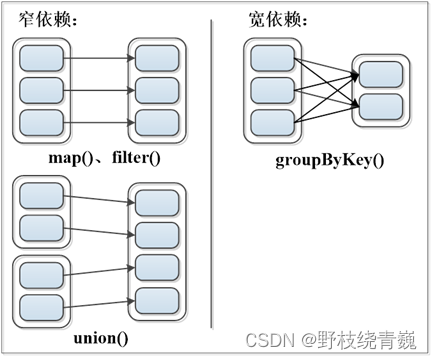
 窄依赖:表现为一个父RDD的分区对应于一个子RDD的分区或者多个父RDD的分区对应于一个子RDD的分区。
窄依赖:表现为一个父RDD的分区对应于一个子RDD的分区或者多个父RDD的分区对应于一个子RDD的分区。
宽依赖:表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。
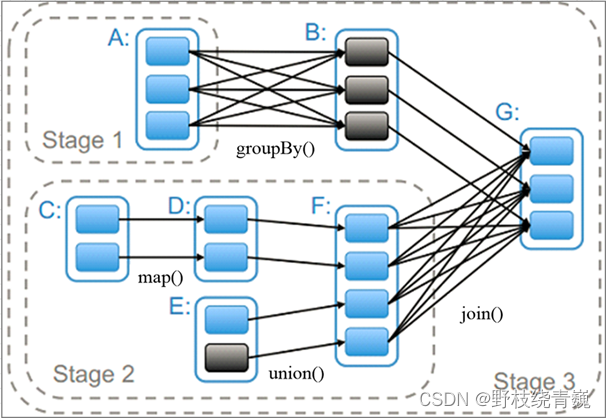
RDD Stage划分
主要是基于Shuffle(宽依赖和窄依赖)
版权归原作者 野枝绕青巍 所有, 如有侵权,请联系我们删除。