
0、环境信息
本文采用阿里云maxcompute的spark环境为基础进行的,搭建本地spark环境参考搭建Windows开发环境_云原生大数据计算服务 MaxCompute-阿里云帮助中心
版本spark 2.4.5,maven版本大于3.8.4
①配置pom依赖 详见2-1
②添加运行jar包
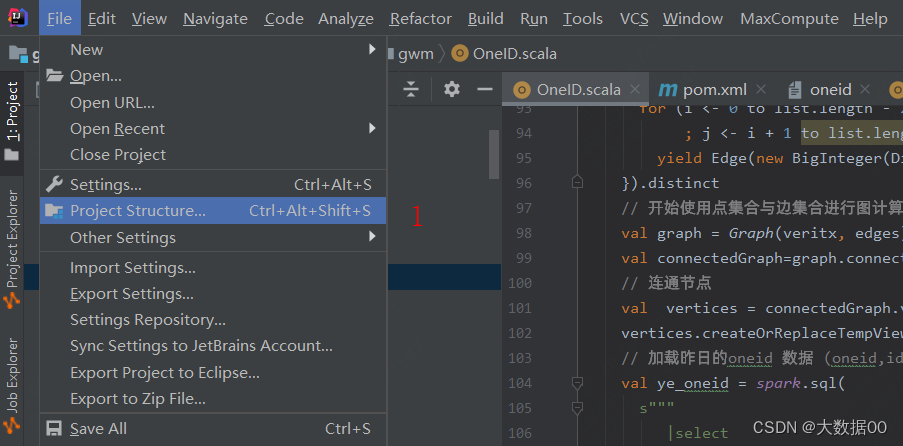

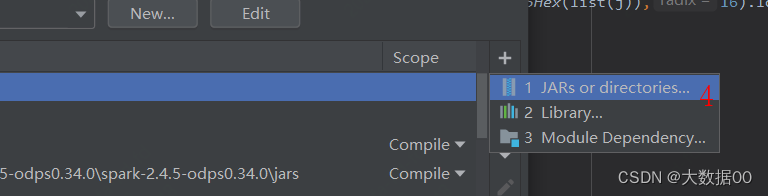
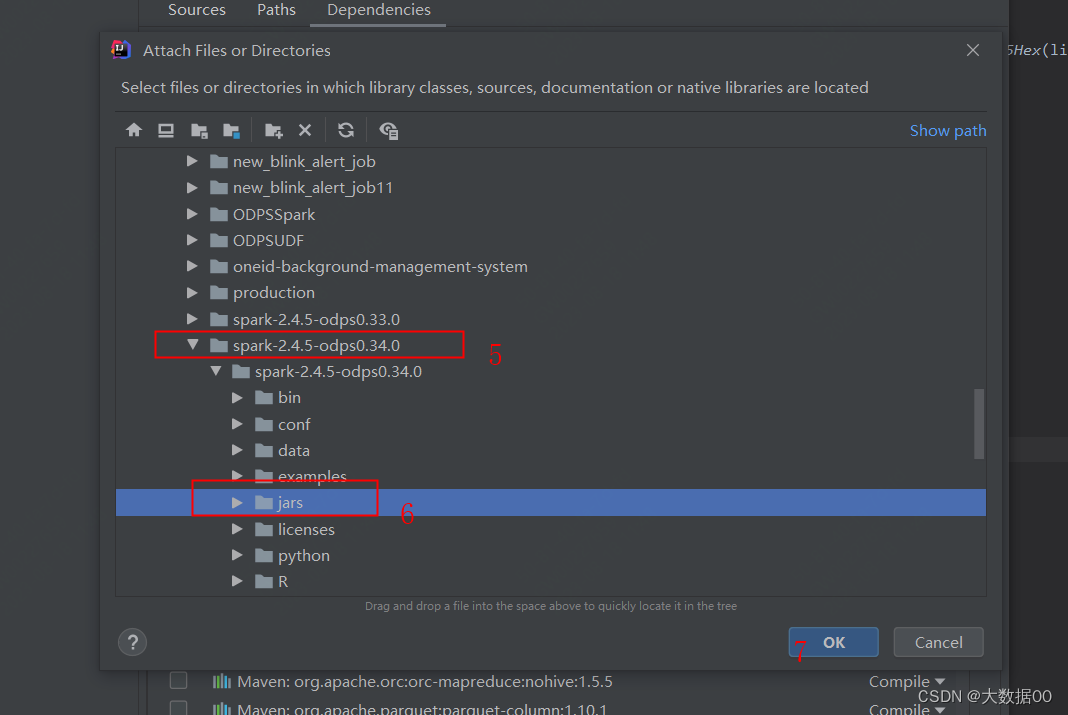
③添加配置信息
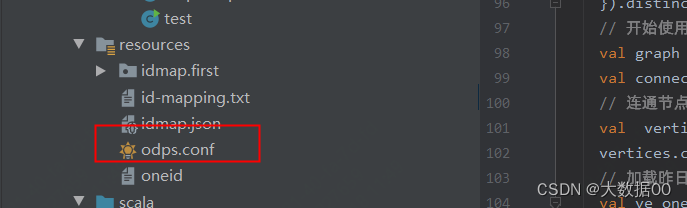
odps.project.name=
odps.access.id=
odps.access.key=
odps.end.point=
1、数据准备
create TABLE dwd_sl_user_ids(
user_name STRING COMMENT '用户'
,user_id STRING COMMENT '用户id'
,device_id STRING COMMENT '设备号'
,id_card STRING COMMENT '身份证号'
,phone STRING COMMENT '电话号'
,pay_id STRING COMMENT '支付账号'
,ssoid STRING COMMENT 'APPID'
) PARTITIONED BY (
ds BIGINT
)
;
INSERT OVERWRITE TABLE dwd_sl_user_ids PARTITION(ds=20230818)
VALUES
('大法_官网','1','device_a','130826','185133','zhi1111','U130311')
,('大神_官网','2','device_b','220317','165133','zhi2222','')
,('耀总_官网','3','','310322','133890','zhi3333','U120311')
,('大法_app','1','device_x','130826','','zhi1111','')
,('大神_app','2','device_b','220317','165133','','')
,('耀总_app','','','','133890','zhi333','U120311')
,('大法_小程序','','device_x','130826','','','U130311')
,('大神_小程序','2','device_b','220317','165133','','U140888')
,('耀总_小程序','','','310322','133890','','U120311')
;
结果表
create TABLE itsl_dev.dwd_patient_oneid_info_df(
oneid STRING COMMENT '生成的ONEID'
,id STRING COMMENT '用户的各类id'
,id_hashcode STRING COMMENT '用户各类ID的id_hashcode'
,guid STRING COMMENT '聚合的guid'
,guid_hashcode STRING COMMENT '聚合的guid_hashcode'
)PARTITIONED BY (
ds BIGINT
);
2、代码准备
①pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.gwm</groupId>
<artifactId>graph</artifactId>
<version>1.0-SNAPSHOT</version>
<name>graph</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<spark.version>2.3.0</spark.version>
<java.version>1.8</java.version>
<cupid.sdk.version>3.3.8-public</cupid.sdk.version>
<scala.version>2.11.8</scala.version>
<scala.binary.version>2.11</scala.binary.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.11</artifactId>
<version>${spark.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>com.thoughtworks.paranamer</groupId>
<artifactId>paranamer</artifactId>
<version>2.8</version>
<!-- <scope>provided</scope>-->
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.5</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>cupid-sdk</artifactId>
<version>${cupid.sdk.version}</version>
<scope>provided</scope>
</dependency>
<!-- <dependency>-->
<!-- <groupId>com.aliyun.odps</groupId>-->
<!-- <artifactId>hadoop-fs-oss</artifactId>-->
<!-- <version>${cupid.sdk.version}</version>-->
<!-- </dependency>-->
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-spark-datasource_${scala.binary.version}</artifactId>
<version>${cupid.sdk.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.73</version>
</dependency>
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.13</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
</dependencies>
<!-- <build>-->
<!-- <pluginManagement><!– lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) –>-->
<!-- <plugins>-->
<!-- <!– clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle –>-->
<!-- <plugin>-->
<!-- <artifactId>maven-clean-plugin</artifactId>-->
<!-- <version>3.1.0</version>-->
<!-- </plugin>-->
<!-- <!– default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging –>-->
<!-- <plugin>-->
<!-- <artifactId>maven-resources-plugin</artifactId>-->
<!-- <version>3.0.2</version>-->
<!-- </plugin>-->
<!-- <plugin>-->
<!-- <artifactId>maven-compiler-plugin</artifactId>-->
<!-- <version>3.8.0</version>-->
<!-- </plugin>-->
<!-- <plugin>-->
<!-- <artifactId>maven-surefire-plugin</artifactId>-->
<!-- <version>2.22.1</version>-->
<!-- </plugin>-->
<!-- <plugin>-->
<!-- <artifactId>maven-jar-plugin</artifactId>-->
<!-- <version>3.0.2</version>-->
<!-- </plugin>-->
<!-- <plugin>-->
<!-- <artifactId>maven-install-plugin</artifactId>-->
<!-- <version>2.5.2</version>-->
<!-- </plugin>-->
<!-- <plugin>-->
<!-- <artifactId>maven-deploy-plugin</artifactId>-->
<!-- <version>2.8.2</version>-->
<!-- </plugin>-->
<!-- <!– site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle –>-->
<!-- <plugin>-->
<!-- <artifactId>maven-site-plugin</artifactId>-->
<!-- <version>3.7.1</version>-->
<!-- </plugin>-->
<!-- <plugin>-->
<!-- <artifactId>maven-project-info-reports-plugin</artifactId>-->
<!-- <version>3.0.0</version>-->
<!-- </plugin>-->
<!-- <plugin>-->
<!-- <groupId>org.scala-tools</groupId>-->
<!-- <artifactId>maven-scala-plugin</artifactId>-->
<!-- <version>2.15.2</version>-->
<!-- <executions>-->
<!-- <execution>-->
<!-- <goals>-->
<!-- <goal>compile</goal>-->
<!-- <goal>testCompile</goal>-->
<!-- </goals>-->
<!-- </execution>-->
<!-- </executions>-->
<!-- </plugin>-->
<!-- </plugins>-->
<!-- </pluginManagement>-->
<!-- </build>-->
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.1</version>
<configuration>
<archive>
<manifest>
<mainClass>com.gwm.OdpsGraphx</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
②代码
package com.gwm
import java.math.BigInteger
import java.text.SimpleDateFormat
import java.util.Calendar
import org.apache.commons.codec.digest.DigestUtils
import org.apache.spark.SparkConf
import org.apache.spark.graphx.{Edge, Graph}
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.spark_project.jetty.util.StringUtil
import scala.collection.mutable.ListBuffer
/**
* @author yangyingchun
* @date 2023/8/18 10:32
* @version 1.0
*/
object OneID {
val sparkConf = (new SparkConf).setAppName("OdpsGraph").setMaster("local[1]")
sparkConf.set("spark.hadoop.odps.access.id", "your's access.id ")
sparkConf.set("spark.hadoop.odps.access.key", "your's access.key")
sparkConf.set("spark.hadoop.odps.end.point", "your's end.point")
sparkConf.set("spark.hadoop.odps.project.name", "your's project.name")
sparkConf.set("spark.sql.catalogImplementation", "hive") //in-memory 2.4.5以上hive
val spark = SparkSession
.builder
.appName("Oneid")
.master("local[1]")
.config("spark.sql.broadcastTimeout", 1200L)
.config("spark.sql.crossJoin.enabled", true)
.config("odps.exec.dynamic.partition.mode", "nonstrict")
.config(sparkConf)
.getOrCreate
val sc = spark.sparkContext
def main(args: Array[String]): Unit = {
val bizdate=args(0)
val c = Calendar.getInstance
val format = new SimpleDateFormat("yyyyMMdd")
c.setTime(format.parse(bizdate))
c.add(Calendar.DATE, -1)
val bizlastdate = format.format(c.getTime)
println(s" 时间参数 ${bizdate} ${bizlastdate}")
// dwd_sl_user_ids 就是我们用户的各个ID ,也就是我们的数据源
// 获取字段,这样我们就可以扩展新的ID 字段,但是不用更新代码
val columns = spark.sql(
s"""
|select
| *
|from
| itsl.dwd_sl_user_ids
|where
| ds='${bizdate}'
|limit
| 1
|""".stripMargin)
.schema.fields.map(f => f.name).filterNot(e=>e.equals("ds")).toList
println("字段信息=>"+columns)
// 获取数据
val dataFrame = spark.sql(
s"""
|select
| ${columns.mkString(",")}
|from
| itsl.dwd_sl_user_ids
|where
| ds='${bizdate}'
|""".stripMargin
)
// 数据准备
val data = dataFrame.rdd.map(row => {
val list = new ListBuffer[String]()
for (column <- columns) {
val value = row.getAs[String](column)
list.append(value)
}
list.toList
})
import spark.implicits._
// 顶点集合
val veritx= data.flatMap(list => {
for (i <- 0 until columns.length if StringUtil.isNotBlank(list(i)) && (!"null".equals(list(i))))
yield (new BigInteger(DigestUtils.md5Hex(list(i)),16).longValue, list(i))
}).distinct
val veritxDF=veritx.toDF("id_hashcode","id")
veritxDF.createOrReplaceTempView("veritx")
// 生成边的集合
val edges = data.flatMap(list => {
for (i <- 0 to list.length - 2 if StringUtil.isNotBlank(list(i)) && (!"null".equals(list(i)))
; j <- i + 1 to list.length - 1 if StringUtil.isNotBlank(list(j)) && (!"null".equals(list(j))))
yield Edge(new BigInteger(DigestUtils.md5Hex(list(i)),16).longValue,new BigInteger(DigestUtils.md5Hex(list(j)),16).longValue, "")
}).distinct
// 开始使用点集合与边集合进行图计算训练
val graph = Graph(veritx, edges)
//计算每个顶点的连接组件成员身份,并返回具有该顶点的图值,该值包含包含该顶点的连接组件中的最低顶点id,迭代次数 控制迭代次数
//todo.1 连通分量 无向图
//输出每个连通子图顶点对应的最小顶点编号
// 应用场景♥♥♥
// 话单分析人物关系
// 企业信息族谱
var vertices: DataFrame = ConnectedComponents.run(graph, 2).vertices.toDF("id_hashcode", "guid_hashcode")
//todo.2 StronglyConnectedComponents 强连通分量 有向图
//输出每个【强】连通子图顶点对应的最小顶点编号
// 应用场景♥♥♥
// 话单分析人物关系
// 企业信息族谱
// var vertices: DataFrame = StronglyConnectedComponents.run(graph, 2).vertices.toDF("id_hashcode", "guid_hashcode")
//todo.3 LabelPropagation无向图标签传播 LPA
//从某个顶点触发,所有能够到达的顶点数量最多的,集中在一起成为一个社区,该顶点成为社区起点。
//标签传播算法返回每个顶点对应的社区起点
// 应用场景♥♥♥
// 游戏通过连天记录在晚间中找代理
// 信息传播源头推断:以消息为主题,查看消息传播的始作俑者
// var vertices: DataFrame = LabelPropagation.run(graph, 2).vertices.toDF("id_hashcode", "guid_hashcode")
//todo.4 TriangleCount函数
//三角计数
//三角形:完全图(热议两点有边)
//三角形计算:一条边的两个顶点有相同邻点,则单个点构成三角形
//返回经过每个顶点的三角形数量
// 应用场景♥♥♥
// 社群发现:社群耦合关系紧密程度(一个人的社交网络中三角函数越多说明社交关系越稳定)
// var vertices: DataFrame = TriangleCount.run(graph)
// .vertices.toDF("id_hashcode", "guid_hashcode")
//todo.5 连通节点
// val connectedGraph = graph.connectedComponents()
// val vertices = connectedGraph.vertices.toDF("id_hashcode","guid_hashcode")
vertices.createOrReplaceTempView("to_graph")
// 加载昨日的oneid 数据 (oneid,id,id_hashcode)
val ye_oneid = spark.sql(
s"""
|select
| oneid,id,id_hashcode
|from
| itsl.dwd_patient_oneid_info_df
|where
| ds='${bizlastdate}'
|""".stripMargin
)
ye_oneid.createOrReplaceTempView("ye_oneid")
// 关联获取 已经存在的 oneid,这里的min 函数就是我们说的oneid 的选择问题
val exists_oneid=spark.sql(
"""
|select
| a.guid_hashcode,min(b.oneid) as oneid
|from
| to_graph a
|inner join
| ye_oneid b
|on
| a.id_hashcode=b.id_hashcode
|group by
| a.guid_hashcode
|""".stripMargin
)
exists_oneid.createOrReplaceTempView("exists_oneid")
var result: DataFrame = spark.sql(
s"""
|select
| nvl(b.oneid,md5(cast(a.guid_hashcode as string))) as oneid,c.id,a.id_hashcode,d.id as guid,a.guid_hashcode,${bizdate} as ds
|from
| to_graph a
|left join
| exists_oneid b
|on
| a.guid_hashcode=b.guid_hashcode
|left join
| veritx c
|on
| a.id_hashcode=c.id_hashcode
|left join
| veritx d
|on
| a.guid_hashcode=d.id_hashcode
|""".stripMargin
)
// 不存在则生成 存在则取已有的 这里nvl 就是oneid 的更新逻辑,存在则获取 不存在则生成
var resultFrame: DataFrame = result.toDF()
resultFrame.show()
resultFrame.write.mode(SaveMode.Append).partitionBy("ds").saveAsTable("dwd_patient_oneid_info_df")
sc.stop
}
}
③ 本地运行必须增加resources信息

3、问题解决
①Exception in thread "main" java.lang.IllegalArgumentException: Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder':
Caused by: java.lang.ClassNotFoundException: org.apache.spark.sql.hive.HiveSessionStateBuilder
缺少Hive相关依赖,增加
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
但其实针对odps不需要加此依赖,只需要按0步配置好环境即可
②Exception in thread "main" org.apache.spark.sql.AnalysisException: Table or view not found: itsl.dwd_sl_user_ids; line 5 pos 3;
需要按照 0 步中按照要求完成环境准备
③Exception in thread "main" org.apache.spark.sql.AnalysisException: The format of the existing table itsl.dwd_patient_oneid_info_df is OdpsTableProvider. It doesn't match the specified format ParquetFileFormat.;
解决:ALTER TABLE dwd_patient_oneid_info_df SET FILEFORMAT PARQUET;
本地读写被禁用 需要上线解决
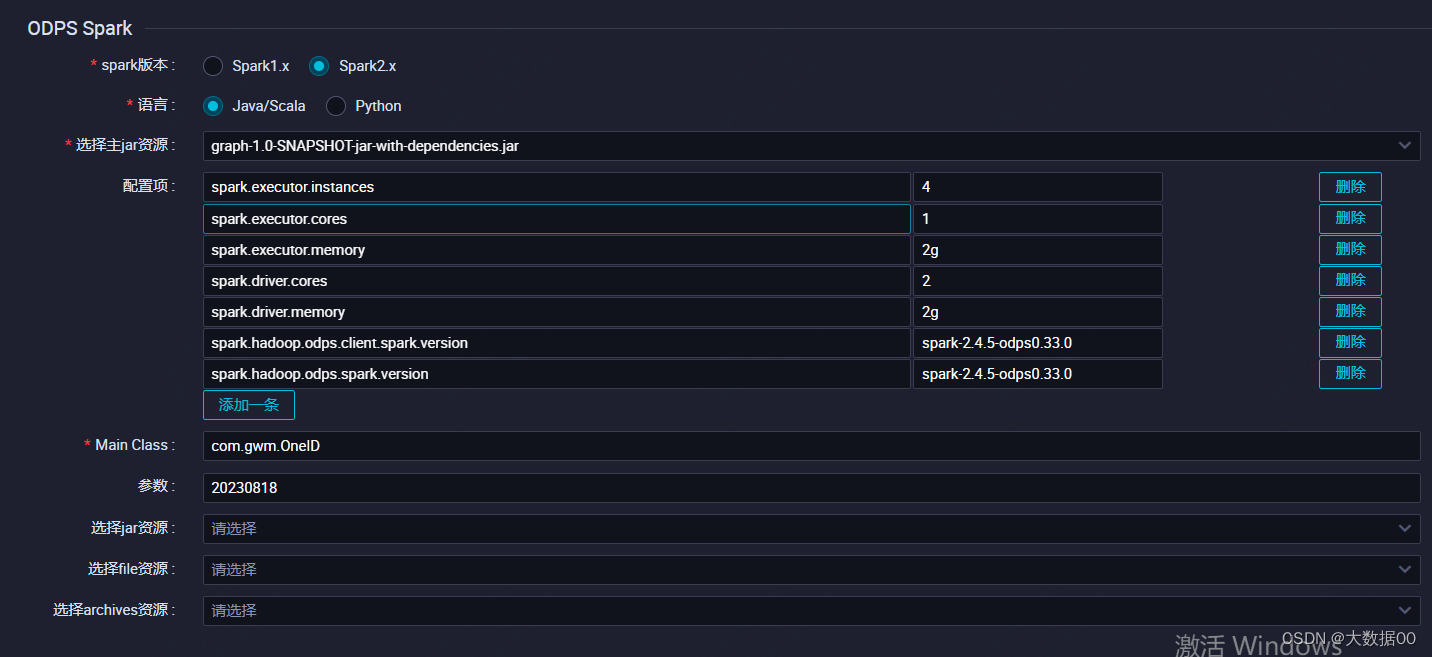
4、打包上传
①需取消
.master("local[1]")
②取消maven依赖
③odps.conf不能打包,建临时文件不放在resources下

本地测试时放resources下
参考用户画像之ID-Mapping_id mapping_大数据00的博客-CSDN博客
上线报
org.apache.spark.sql.AnalysisException: Table or view not found: itsl.dwd_sl_user_ids; line 5 pos 3;
原因是本节③
5、运行及结果
结果
oneid id id_hashcode guid guid_hashcode ds
598e7008ffc3c6adeebd4d619e2368f3 耀总_app 8972546956853102969 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 310322 1464684454693316922 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 zhi333 6097391781232248718 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 3 2895972726640982771 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 耀总_小程序 -6210536828479319643 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 zhi3333 -2388340305120644671 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 133890 -9124021106546307510 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 耀总_官网 -9059665468531982172 133890 -9124021106546307510 20230818
598e7008ffc3c6adeebd4d619e2368f3 U120311 -2948409726589830290 133890 -9124021106546307510 20230818
d39364f7fb05a0729646a766d6d43340 U140888 -8956123177900303496 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 大神_官网 7742134357614280661 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 220317 4342975012645585979 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 device_b 934146606527688393 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 165133 -8678359668161914326 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 大神_app 3787345307522484927 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 大神_小程序 8356079890110865354 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 2 8000222017881409068 U140888 -8956123177900303496 20230818
d39364f7fb05a0729646a766d6d43340 zhi2222 8743693657758842828 U140888 -8956123177900303496 20230818
34330e92b91e164549cf750e428ba9cd 130826 -5006751273669536424 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd device_a -3383445179222035358 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd 1 994258241967195291 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd device_x 3848069073815866650 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd zhi1111 7020506831794259850 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd 185133 -2272106561927942561 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd 大法_app -7101862661925406891 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd U130311 5694117693724929174 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd 大法_官网 -4291733115832359573 大法_app -7101862661925406891 20230818
34330e92b91e164549cf750e428ba9cd 大法_小程序 -5714002662175910850 大法_app -7101862661925406891 20230818
6、思考
如果联通图是循环的怎么处理呢?A是B的朋友,B是C的朋友,C是A的朋友
版权归原作者 大数据00 所有, 如有侵权,请联系我们删除。