
前言
大多数可能的code2报错一般是内存不够,所以加下面这个配置可以有效解决这个问题
set hive.auto.convert.join = false; #取消小表加载至内存中
但这个不一定是因为内存不够,其实很多错误都是报这种官方错误的,所以一定要去yarn上看日志。

很多人看日志也找不到问题,因为并没有看到全部日志,翻到最底下,点击check here 才能看到完整日志
1、内存不足导致code2报错
上面已经举例,如果该参数无法解决可以使用如下的配置
set mapreduce.map.memory.mb=4096;
set mapreduce.map.java.opts=-Xmx3686m;
set mapreduce.reduce.memory.mb=6144;
set mapreduce.reduce.java.opts=-Xmx5120m;
set hive.support.concurrency=false;
SET hive.auto.convert.join=false;
set mapred.max.split.size=256000000;
set mapred.min.split.size=10000000;
set mapred.min.split.size.per.node=8000000;
set mapred.min.split.size.per.rack=8000000;
2、动态分区文件过多
错误日志:
Fatal error occurred when node tried to create too many dynamic partitions. The maximum number of dynamic partitions is controlled by hive.exec.max.dynamic.partitions and hive.exec.max.dynamic.partitions.pernode. Maximum was set to 100 partitions per node, number of dynamic partitions on this node: 101
原因:
Hive对其创建的动态分区数量实施限制。默认值为每个节点100个动态分区,所有节点的总(默认)限制为1000个动态分区。但是,这可以调整。
出错位置:
原动态分区配置为:
set hive.exec.dynamic.partition=true;
set hive.exec.max.dynamic.partitions=1000;
用以上设置后不能保证正常,有时候还需要设置 mapred.reduce.tasks 及 dynamic.partitions.pernode 来配合动态分区使用
set hive.exec.dynamic.partition=true;
set hive.exec.max.dynamic.partitions=1000;
set hive.exec.max.dynamic.partitions.pernode=200;
set mapred.reduce.tasks=10;
这几个参数需要满足以下条件:
dynamic.partitions / dynamic.partitions.pernode <= mapred.reduce.tasks
可以指定mapred.reduce.tasks任务数,但这个一般会根据数据量动态调整,不适合直接写死,所以解决方法最好是调大dynamic.partitions.pernode参数的值,不宜过大,不然会在计算过程中产生很多小文件,影响执行效率
动态分区相关配置
set hive.exec.dynamic.partition=true;–是否允许动态分区
默认值:false
是否开启动态分区功能,默认false关闭。
使用动态分区时候,该参数必须设置成true。
set hive.exec.dynamic.partition.mode=nonstrict; --分区模式设置
默认值:strict
动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区。
nonstrict模式:表示允许所有的分区字段都可以使用动态分区。
set hive.exec.max.dynamic.partitions.pernode=1000;–单个节点上的mapper/reducer允许创建的最大分区
默认值:100
在每个执行MR的节点上,最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。
set hive.exec.max.dynamic.partitions=1500;–允许动态分区的最大数量
默认值:1000
在所有执行MR的节点上,最大一共可以创建多少个动态分区。
同上参数解释。
hive.exec.max.created.files=100000;–一个mapreduce作业能创建的HDFS文件最大数
默认值:100000
整个MR Job中,最大可以创建多少个HDFS文件。
一般默认值足够了,除非你的数据量非常大,需要创建的文件数大于100000,可根据实际情况加以调整。
hive.error.on.empty.partition=false;–在动态分区插入产生空结果时是否抛出异常
默认值:false
当有空分区生成时,是否抛出异常。一般不需要设置。
3、hdfs块丢失
可到hdfs的webUI中查看是否有块丢失问题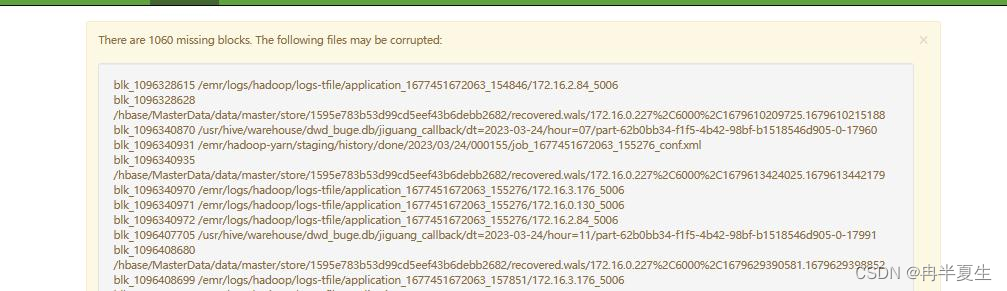
照成块丢失的原因有很多,我举例几个我们碰到的
①集群小文件太多
导致RPC通信异常,ipc的数据包超过设定最大的64MB导致datanode与namenode通信失败,
小文件数量过多导致DataNode内存不足,导致DataNode重启,DataNode要给NameNode上报block信息,由于block信息较多,ipc通信的数据包超过了64MB,NameNode返回异常了,导致DataNode这边出现EOFException的异常,由于这个异常,DataNode没能把block信息上报给NameNode,NameNode就认为block丢失了。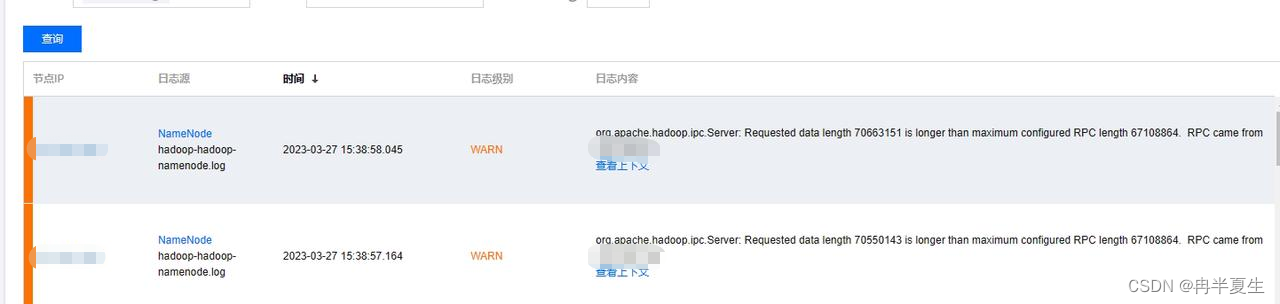
018-09-04 23:24:38,446 WARN org.apache.hadoop.hdfs.server.datanode.DataBlockScanner: No block pool scanner found for block pool id: BP-21853433-xxxxxxxxx-1484835379573
2018-09-05 00:45:13,777 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Unsuccessfully sent block report 0xa7b72c5217b7ac, containing 1 storage report(s), of which we sent 0. The reports had 6076010 total blocks and used 0 RPC(s). This took 1636 msec to generate and 1082 msecs for RPC and NN processing. Got back no commands.
2018-09-05 00:45:13,777 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: IOException in offerService
java.io.EOFException: End of File Exception between local host is: "xxxx"; destination host is: "xxx":53310; : java.io.EOFException; For more details see: http://wiki.apache.org/hadoop/EOFException
at sun.reflect.GeneratedConstructorAccessor8.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:764)
at org.apache.hadoop.ipc.Client.call(Client.java:1473)
at org.apache.hadoop.ipc.Client.call(Client.java:1400)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)
at com.sun.proxy.$Proxy12.blockReport(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolClientSideTranslatorPB.blockReport(DatanodeProtocolClientSideTranslatorPB.java:177)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.blockReport(BPServiceActor.java:524)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.offerService(BPServiceActor.java:750)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:889)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.io.EOFException
at java.io.DataInputStream.readInt(DataInputStream.java:392)
at org.apache.hadoop.ipc.Client$Connection.receiveRpcResponse(Client.java:1072)
at org.apache.hadoop.ipc.Client$Connection.run(Client.java:967)
修改NameNode的hdfs-site.xml配置文件,添加以下配置修改ipc通信的数据包最大的大小:
<property>
<name>ipc.maximum.data.length</name>
<value>134217728</value>
</property>
降低小文件数量方法:
小文件一般是由于spark的insert任务生成的
spark.sql.shuffle.partitions=200 ,spark sql默认shuffle分区是200个,如果数据量比较小时,写hdfs时会产生200个小文件。
spark任务执行前需要加两个配置实现自适应调整可以大大减少小文件的产生
set spark.sql.adaptive.enabled=true
set spark.sql.adaptive.shuffle.targetPostShuffleInputSize=128000000
注意:python使用spark时也需要
import os
os.environ['SPARK_HOME'] = "/usr/local/service/spark"
import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.config("spark.sql.adaptive.enabled", "true") \
.config("spark.sql.adaptive.shuffle.targetPostShuffleInputSize", "128000000") \
.enableHiveSupport().getOrCreate()
②由于其它原因,文件出现损坏,导致不可使用
根据hdfs的WEBUI提示删掉异常文件即可
版权归原作者 冉半夏生 所有, 如有侵权,请联系我们删除。