
hadoop是本文章主要介绍hadoop完全分布式搭建过程。
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,是完全开源的,是由java语言编写的。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了分布式存储,而MapReduce则为海量的数据提供了分布式计算
特别注意:hadoop是三台虚拟机之间实现资源调度,非常容易出错,初学者可以反复练习搭建(不成功不要气馁),搭建过程中一定要仔细,哪怕一个字符敲错就可能使得集群不能成功运行。
环境准备:
宿主机内存最好16G及以上(可满足同时运行三台虚拟机)
centos7虚拟机3台,使用单核单cpu,2G内存,最小安装方式。(尽可能节省资源)
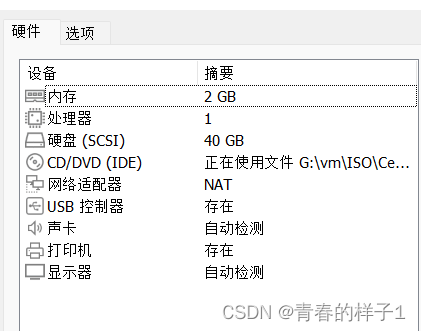

可以选用vmware提供的虚拟机克隆功能,就可以创建一台虚拟机,克隆两台虚拟机。
利用vmware搭建虚拟机请查看以下连接,有详细的虚拟机创建过程。
利用vmware workstation创建自己的linux虚拟机_青春的样子1的博客-CSDN博客本文章介绍如何使用vmware workstation 创建虚拟机。linux是开源项目,centos是服务器使用最多的操作系统,适合新手学习linux,由于centos8官方停止更新和维护,使得企业和用户依然使用centos7版本,此文章手把手介绍安装centos7虚拟机。...............https://blog.csdn.net/weixin_51659640/article/details/125473297?spm=1001.2014.3001.5502
一、前期配置(root用户进行):
1、ssh免密配置
以下为虚拟机名称以及IP地址规划
master 192.168.6.10slave1192.168.6.11slave2192.168.6.12
各节点更改主机名,每个节点配置上述规划的主机名(重启生效)
hostnamectl set-hostname master #更改主机名
配置静态IP地址配置,每个节点配置上述规划的IP地址。
vi /etc/sysconfig/network-scripts/ifcfg-ens33
####配置静态IP地址(你的网卡名可能不为ens33)
BOOTPROTO="static" #更改内容
IPADDR=192.168.6.10 #此行以下为添加内容 设置的为master节点
NETMASK=255.255.255.0
GATEWAY=192.168.6.2 #配置网关,根据自己环境的网关
DNS1=114.114.114.114
NM_CONTROLLER=no #表示该接口将通过该配置文件进行设置,而不是通过网络管理器进行管理。
重启网络服务
systemctl restart network
查看网络是否配置生效

配置主机名与IP映射(三个节点都要配置)
vim /etc/hosts
#在文件末尾添加如下内容
192.168.6.10 master
192.168.6.11 slave1
192.168.6.12 slave2
验证连通性(三个节点分别验证)

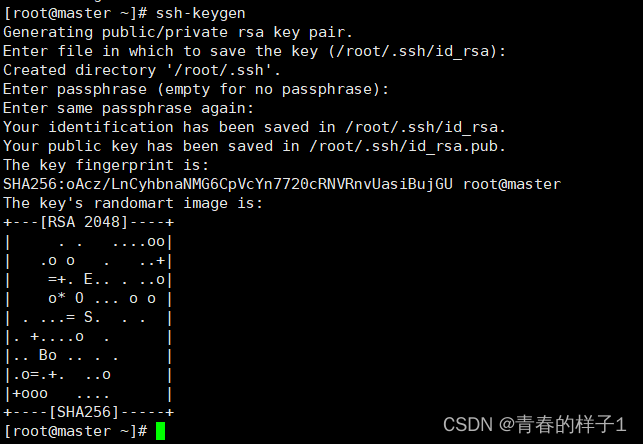
生成秘钥(三个节点生成)
ssh-keygen #按四次回车
秘钥拷贝(将三个节点的秘钥都拷贝到master中)(三个节点执行)
ssh-copy-id master
需要输入yes及master节点root用户密码
拷贝完成后,在master中检查是否拷贝成功(master执行)
cat ~/.ssh/authorized_keys

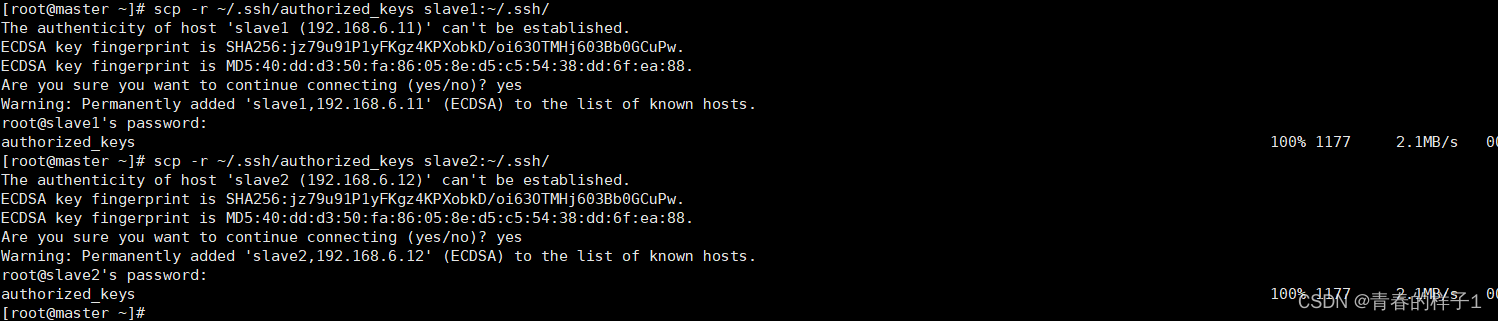
秘钥分发(master执行)
scp -r ~/.ssh/authorized_keys slave1:~/.ssh/
scp -r ~/.ssh/authorized_keys slave2:~/.ssh/
免密登录验证(三个节点)
ssh master
ssh slave1
ssh slave2
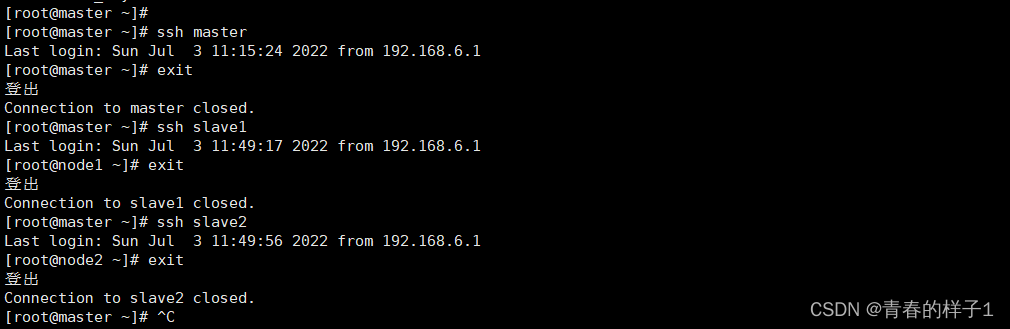
若不成功删除.ssh目录重新配置。
rm -rf ~/.ssh
2、时间同步配置(三个节点)
在线安装ntp
yum install ntp -y
设置时间同步
ntpdate pool.ntp.org
验证
date
3、禁用防火墙(三个节点)
systemctl stop firewalld #关闭防火墙
systemctl disable firewalld #关闭防火墙开机自起

二、开始安装hadoop
安装所需的软件包阿里盘连接
阿里云盘分享https://www.aliyundrive.com/s/jCDudpAngXq
本次实验在root用户下安装hadoop。
安装路径规划
名称
路径
安装包存放目录
/root/package/
软件安装目录
/root/soft/
数据目录
/root/data/
日志目录
/root/log/
1.jdk环境安装与配置
hadoop是由java语言编写的所以要提前安装java环境(三个节点检查)
检查是否存在自带jdk环境
rpm -qa |grep java
如果有自带java环境需要先卸载
rpm -e --nodeps 已安装的jdk
本实验采用jdk1.8版本安装
创建目录/root/package/、/root/soft/目录(三个节点)
mkdir /root/package
mkdir /root/soft

将本地的所需安装包通过xftp上传到master节点的/home/apache/package目录下(master)
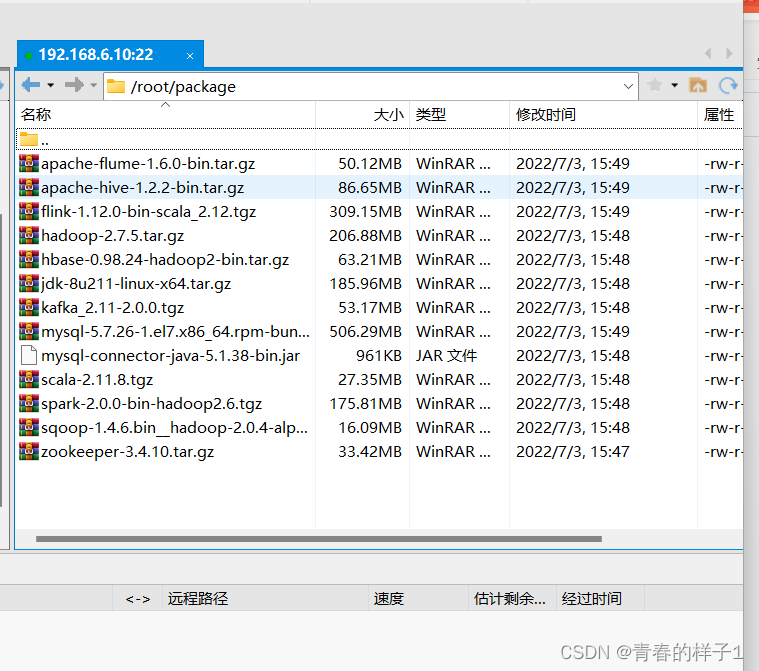
 解压jdk安装包(master执行)
解压jdk安装包(master执行)
tar -zxvf /root/package/jdk-8u211-linux-x64.tar.gz -C /root/soft/
解压成功后,切换到soft目录下,可以看到新增了一个jdk1.8.0_211的目录。
为了配置方便可以将jdk目录改名为java(master执行)
mv /root/soft/jdk1.8.0_211/ /root/soft/java
配置环境变量(master执行)
vi /etc/profile 打开文件在末尾添加如下行
export JAVA_HOME=/root/soft/java
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
将jdk分发给slave1和slave2。确保在slave1和slave2中已经新建目录/root/soft,然后在master终端中执行下面的两条命令将master的jdk安装文件分发给slave1和slave2。(master执行)
scp -r /root/soft/java/ slave1:/root/soft/
scp -r /root/soft/java/ slave2:/root/soft/
将环境变量分发给slave1,slave2(master执行)
scp -r /etc/profile slave1:/etc/
scp -r /etc/profile slave2:/etc/

分发完毕使得立即生效(三个节点执行)
source /etc/profile
检查是否安装完毕(三个节点执行)

2、hadoop安装(以下操作除特殊标注,均为master节点执行)
解压hadoop安装包并重命名。
tar -zxvf /root/package/hadoop-2.7.5.tar.gz -C /root/soft/
mv /root/soft/hadoop-2.7.5/ /root/soft/hadoop
配置文件修改(共6个)
hadoop-env.sh
hadoop-env.sh文件主要配置跟Hadoop环境相关的变量。
vi /root/soft/hadoop/etc/hadoop/hadoop-env.sh
加入如下内容
export JAVA_HOME=/root/soft/java

core-site.xml
core-site.xml是Hadoop的全局配置文件,主要配置Hadoop的公有属性。
mkdir -p /root/data/hdfs/tmp 创建目录
vi /root/soft/hadoop/etc/hadoop/core-site.xml
加入如下配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/data/hdfs/tmp</value>
</property>
</configuration>
hdfs-site.xml
hdfs-site.xml文件主要配置和HDFS相关的属性。
mkdir -p /root/data/hdfs/name
mkdir -p /root/data/hdfs/data
vi /root/soft/hadoop/etc/hadoop/hdfs-site.xml
添加如下配置
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/root/data/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/data/hdfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
mapred-site.xml是MapReduce的配置文件,默认情况下Hadoop中没有该文件,可通过执行cp mapred-site.xml.template mapred-site.xml复制一个,并进行编辑。为了使提交的MapReduce程序运行在分布式模式,而不是本地local模式,可以指定由Yarn作为MapReduce的程序运行框架。
cp /root/soft/hadoop/etc/hadoop/mapred-site.xml.template /root/soft/hadoop/etc/hadoop/mapred-site.xml
vi /root/soft/hadoop/etc/hadoop/mapred-site.xml
加入如下配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
yarn-site.xml文件主要配置YARN的一些信息。
vi /root/soft/hadoop/etc/hadoop/yarn-site.xml
加入如下配置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
slaves
slaves文件主要根据集群规划配置DataNode节点所在的主机名,master节点通过该文件获得集群的子节点名称,然后再通过/etc/hosts文件得到各子节点对应的IP,从而与自己进行通信。
vi /root/soft/hadoop/etc/hadoop/slaves
把原有内容删除,修改为如下内容
slave1
slave2
修改环境变量
vi /etc/profile
末尾添加如下内容
export HADOOP_HOME=/root/soft/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
将hadoop分发值slave1和slave2节点
scp -r /root/soft/hadoop/ slave1:/root/soft/
scp -r /root/soft/hadoop/ slave2:/root/soft/
将环境变量分发给slave1和slave2节点。
scp -r /etc/profile slave1:/etc/
scp -r /etc/profile slave2:/etc/
使得环境变量生效(三个节点)
source /etc/profile
3、hadoop启动
格式化namenode,只能格式化一次,不能重复格式化(master节点)
hdfs namenode -format
在master的终端执行命令start-all.sh启动hadoop集群,该命令可由start-dfs.sh和start-yarn.sh代替,用于分别启动HDFS和YARN。首次启动hadoop时,会提示输入yes/no,输入yes,第二次及以后启动不会输入任何内容。(master)
start-all.sh
检查集群启动情况,执行jps指令,若三个节点进程和如下一直,hadoop搭建成功(三个节点)
jps

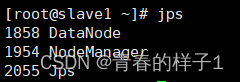
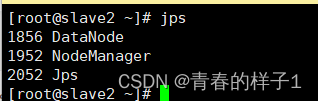
Hadoop集群启动后,可以在浏览器中查看集群运行情况。
在浏览器中输入http://192.168.6.10:50070(或http://master:50070),可以查看HDFS文件系统上存储的目录和文件等信息,如图显示的是NameNode的信息。

三、测试hadoop集群(任意节点执行)
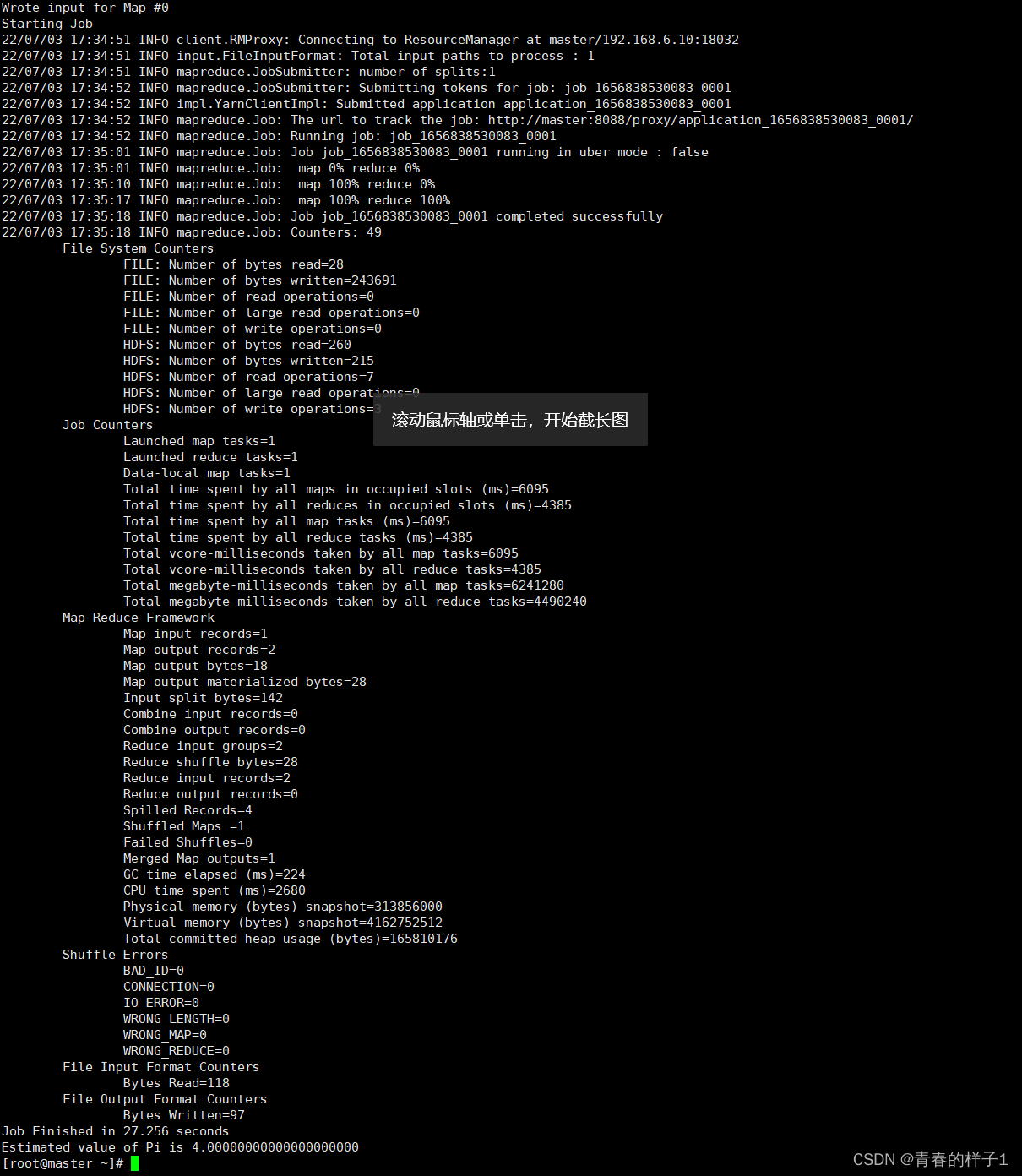
1、运行Hadoop自带的MapReduce例子求pi
hadoop jar /root/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar pi 1 1
2、运行Hadoop自带的WordCount程序(任意节点执行)
首先,创建目录:mkdir /home/apache/data/test,在这个目录下创建文件wctest.txt

在HDFS文件系统中创建一个hdfstest目录
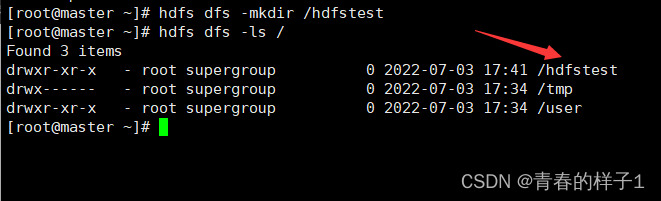

将本地的wctest.txt文件上传到hdfstest目录中
hdfs dfs -put wctest.txt /hdfstest
运行Hadoop自带的WordCount程序
hadoop jar /root/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /hdfstest/wctest.txt /hdfstest/output
查看结果
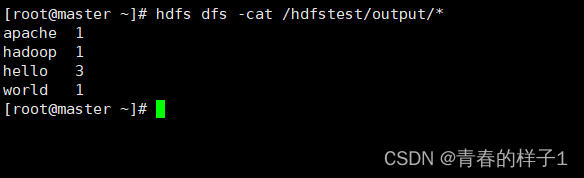
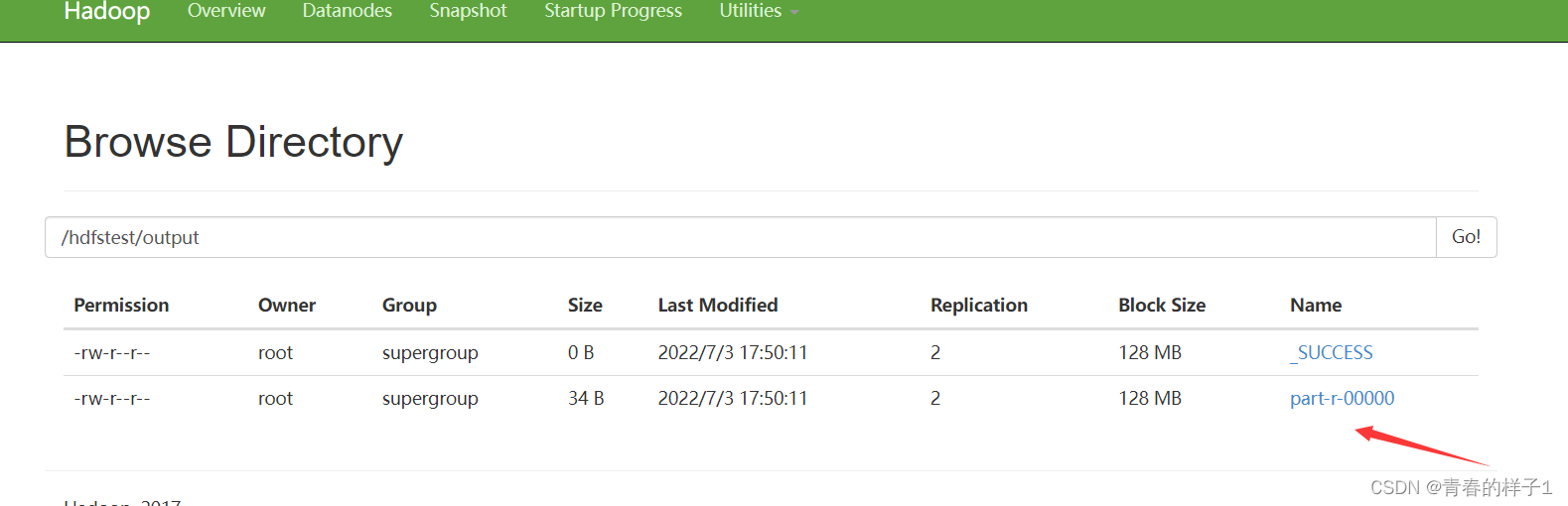
以上测试都没有问题,表明hadoop集群搭建成功。
关闭集群
在master的终端中输入命令用于关闭整个Hadoop集群,如果只是关闭HDFS,可使用stop-hdfs.sh命令。Hadoop集群关闭后,在各个主机上通过jps命令查看进程是否都正常关闭,如果还有僵尸进程存在,则使用kill命令将其杀死。(master)
stop-all.sh
版权归原作者 青春的样子1 所有, 如有侵权,请联系我们删除。