
当前我们的业务场景,是基于dataStream代码, 维表数据量很大, 实时性要求很高,所以采用预加载分区维表模式, kafka广播流实时更新配置。
主题:调研预加载分区维表模式
业务特点: 维表配置数据量很大, 实时性要求很高
当前业务场景介绍:当前Flink基于dataStream代码编写, 每个并行度process的open方法加载全量配置数据保存
当前瓶颈点:无法应对超大维表。生产环境维表的配置数据量很大,如果每个并行度都去采用全量的配置会消耗很多内存,同时也会很耗时;有可能加载时间会超过checkpoint设置的timeout时间,导致整个Flink job都起不来,出现Down的情况。
预加载分区维表优点:
一个并行度只加载自己那部分的配置,比如全量配置有1万个,Flnk job 20个并行度,采用分区维表平均下来1个并行度只要加载500个配置;大大减少了内存消耗,缩短了加载时间。
预加载分区维表实现方案
1:job初始化时 每个分区open 只加载自己那部分的配置,不用每个分区都全量加载
2: 自定义Partition分区,需要维护一个分区和配置之间的关联关系, 1,配置会到指定的分区,2.数据流来了要跑到指定的分区,要不然会匹配不到配置; 解决方案:使配置和数据流都有的唯一键做hashcode然后取余, (planId.hashcode% 20).abs ,保证planId会到指定的分区
3: 配置信息实时更新;用户在后台更新了某条配置,同时Flink内部也要实时更新。解决方案:后台将配置传入kafka topic;Flink job消费topic转换成广播流,使用process实时更新分区内的配置信息
4:配置信息要比数据流先到, 要不然会有部分数据流没有匹配到配置, 当前业内有两种解决方案, 第一种:采用processFunction内的open方法去加载所有配置,保证配置比数据流先到, 第二种:将比配置流先到的数据流缓存下来,比如放到ListState里存储下来,等配置流到了之后在去匹配; 当前方案采用的是第一种
衡量指标
总体来讲,关联维表有三个基础的方式:实时数据库查找关联(Per-Record Reference Data Lookup)、预加载维表关联(Pre-Loading of Reference Data)和维表变更日志关联(Reference Data Change Stream),而根据实现上的优化可以衍生出多种关联方式,且这些优化还可以灵活组合产生不同效果(不过为了简单性这里不讨论同时应用多种优化的实现方式)。对于不同的关联方式,我们可以从以下 7 个关键指标来衡量(每个指标的得分将以 1-5 五档来表示):
实现简单性: 设计是否足够简单,易于迭代和维护。
吞吐量: 性能是否足够好。
维表数据的实时性: 维度表的更新是否可以立刻对作业可见。
数据库的负载: 是否对外部数据库造成较大的负载(负载越低分越高)。
内存资源占用: 是否需要大量内存来缓存维表数据(内存占用越少分越高)。
可拓展性: 在更大规模的数据下会不会出现瓶颈。
结果确定性: 在数据延迟或者数据重放情况下,是否可以得到一致的结果。
启动预加载分区维表
对于维表比较大的情况,可以启动预加载维表基础之上增加分区功能。简单来说就是将数据流按字段进行分区,然后每个 Subtask 只需要加在对应分区范围的维表数据。值得注意的是,这里的分区方式并不是用 keyby 这种通用的 hash 分区,而是需要根据业务数据定制化分区策略,然后调用 DataStream#partitionCustom。比如按照 userId 等区间划分,0-999 划分到 subtask 1,1000-1999 划分到 subtask 2,以此类推。而在 open() 方法中,我们再根据 subtask 的 id 和总并行度来计算应该加载的维表数据范围。
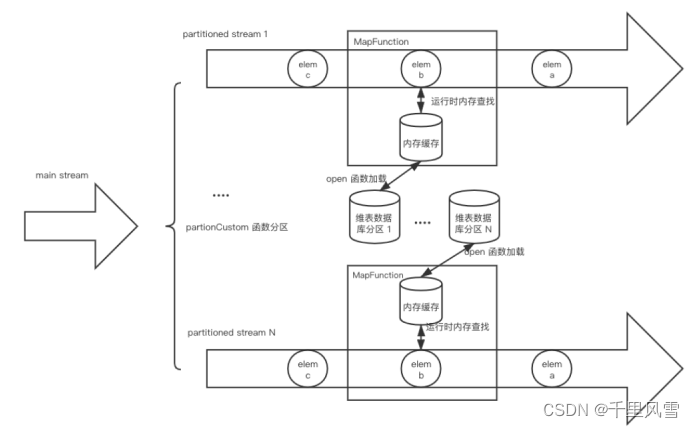
启动预加载分区维表介绍:
通过这种分区方式,维表的大小上限理论上可以线性拓展,解决了维表大小受限于单个 TaskManager 内存的问题(现在是取决于所有 TaskManager 的内存总量),但同时给带来设计和维护分区策略的复杂性。
缓存方式:
之前业务场景是采用的第一种, 但是配置数据量越来越大,已经不能支撑业务,所以模拟调研第三种方式,设计和维护分区策略
代码实验:
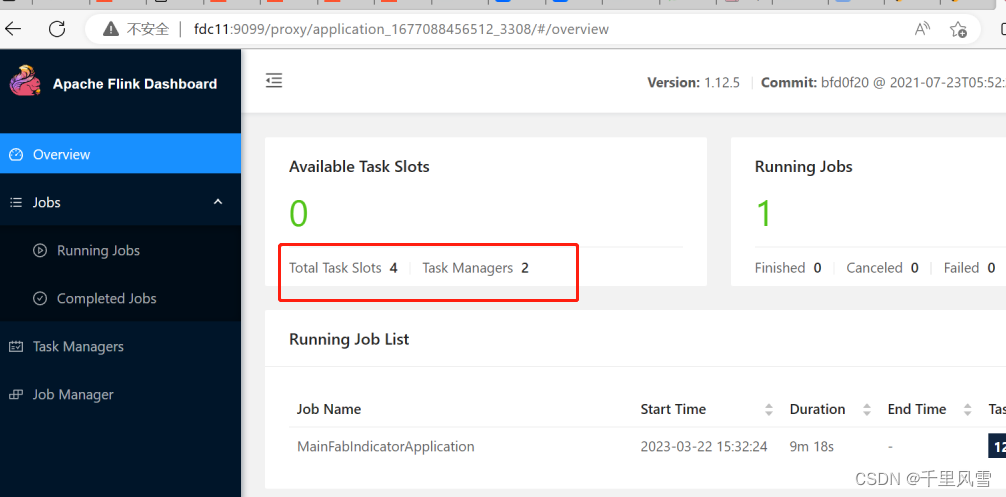
Flink设置4个并行度, 2个taskmanager
-m yarn-cluster -p 4 -yjm 1024m -ytm 2048m -ynm $application_name -ys 2
采用自定义Partition设计和维护分区策略,数据流和维表connect
.filter(_.nonEmpty).map(_.get).partitionCustom(new CustomPartitioner(),data =>{s"${data.datas.controlPlanId}"}).connect(indicatorConfigBroadcastStream).process(new FdcIndicatorConfigBroadcastProcessFunction).name("FdcGenerateIndicator").uid("FdcGenerateIndicator")
自定义Partition分区类
importorg.apache.flink.api.common.functions.Partitioner
importorg.slf4j.{Logger, LoggerFactory}class CustomPartitioner extends Partitioner[String]{lazyprivateval logger: Logger = LoggerFactory.getLogger(classOf[CustomPartitioner])overridedef partition(key:String, numPartitions:Int):Int={
logger.warn("分区总数"+numPartitions)return(key.hashCode % numPartitions).abs
}}
BroadcastProcessFunction
class ConfigBroadcastProcessFunction
extends BroadcastProcessFunction[fdcWindowData, JsonNode,(ListBuffer[(ALGO, IndicatorConfig)], ListBuffer[RawData])]{lazyprivateval logger: Logger = LoggerFactory.getLogger(classOf[FdcIndicatorConfigBroadcastProcessFunction])// 初始化overridedef open(parameters: Configuration):Unit={
logger.warn(s"getIndexOfThisSubtask: ${getRuntimeContext.getIndexOfThisSubtask}")
logger.warn(s"getNumberOfParallelSubtasks: ${getRuntimeContext.getNumberOfParallelSubtasks}")super.open(parameters)// 获取全局变量val p = getRuntimeContext.getExecutionConfig.getGlobalJobParameters.asInstanceOf[ParameterTool]
ProjectConfig.getConfig(p)}// 数据流overridedef processElement(windowData: fdcWindowData, ctx: BroadcastProcessFunction[fdcWindowData,
JsonNode,(ListBuffer[(ALGO, IndicatorConfig)], ListBuffer[RawData])]#ReadOnlyContext,
out: Collector[(ListBuffer[(ALGO, IndicatorConfig)], ListBuffer[RawData])]):Unit={
logger.warn(s"${getRuntimeContext.getIndexOfThisSubtask}")}// 广播流overridedef processBroadcastElement(value: JsonNode, ctx: BroadcastProcessFunction[
fdcWindowData, JsonNode,(ListBuffer[(ALGO, IndicatorConfig)], ListBuffer[RawData])]#Context,
out: Collector[(ListBuffer[(ALGO, IndicatorConfig)], ListBuffer[RawData])]):Unit={}}
打印结果:
taskmanager1; open的时候打印信息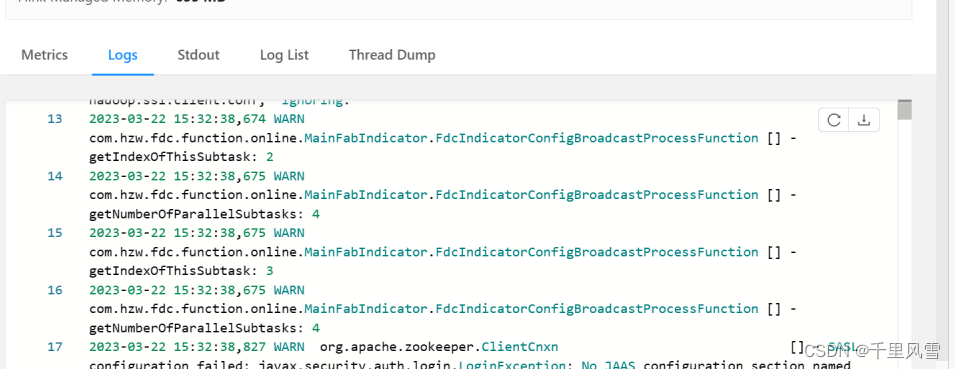
taskmanager2; open的时候打印信息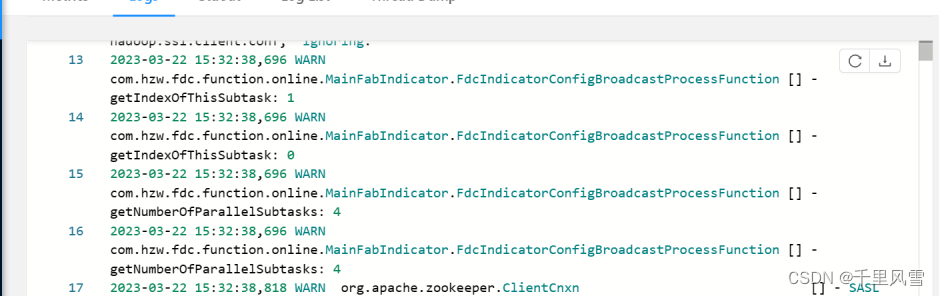
当数据流来时, processElement中的打印信息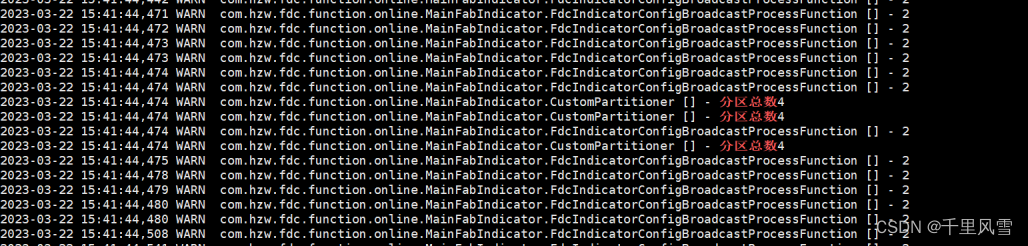
参考:
https://blog.csdn.net/weixin_44904816/article/details/104305824
https://codeantenna.com/a/IcVVHYGUVi
https://www.jianshu.com/p/66b014dd2e36
https://blog.csdn.net/cloudbigdata/article/details/125013545
版权归原作者 千里风雪 所有, 如有侵权,请联系我们删除。