
1. HTTP协议与WEB开发
1. 什么是请求头请求体,响应头响应体
2. URL地址包括什么
3. get请求和post请求到底是什么
4. Content-Type是什么
1.1 简介
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于万维网(WWW:World Wide Web )服务器与本地浏览器之间传输超文本的传送协议。HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
1.2 请求协议与响应协议
URL:
1、URL:协议://IP:端口/路径/.../.../.../...?查询参数
https://www.lagou.com/wn/jobs?labelWords=&fromSearch=true&suginput=&kd=python
协议:HTTP
IP:每一台服务器的网络标识:www.lagou.com
端口:进程:默认80
路径:/wn/jobs
查询参数:labelWords=&fromSearch=true&suginput=&kd=python
2、网络三要素:协议、IP、端口
3、状态码:
404:找不到资源
101:进行中
202:请求成功
303:重定向
404:资源不存在、访问限制
505:服务器错误
http协议包含由浏览器发送数据到服务器需要遵循的请求协议与服务器发送数据到浏览器需要遵循的请求协议。用于HTTP协议交互的信被为HTTP报文。请求端(客户端)的HTTP报文 做请求报文,响应端(服务器端)的 做响应报文。HTTP报文本身是由多行数据构成的字文本。
请求方式: get与post请求
- GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditBook?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的请求体中.
- GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制
响应状态码:状态码的职 是当客户端向服务器端发送请求时, 返回的请求 结果。借助状态码,用户可以知道服务器端是正常 理了请求,还是出 现了 。状态码如200 OK,以3位数字和原因组成。
2. requests&反爬破解
2.1 User-Agent反爬

import requests
headers ={"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",}
res = requests.get("https://www.baidu.com/",
headers=headers
)# 解析数据withopen("baidu.html","w")as f:
f.write(res.text)
2.2 Refer反爬

# 选电影:喜剧import requests
headers ={"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'' Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',"Referer":"https://movie.douban.com/explore",}
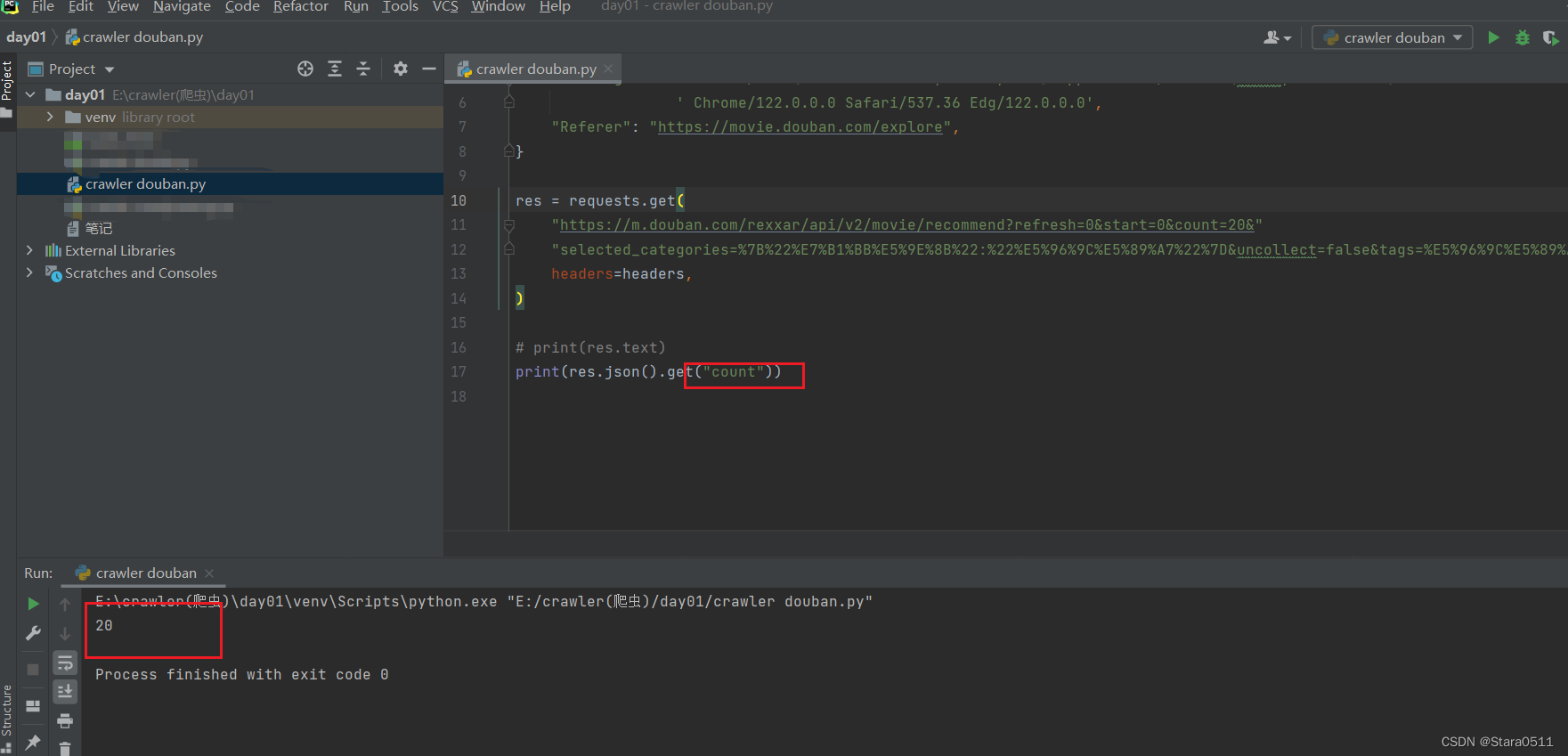
res = requests.get("https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=20&""selected_categories=%7B%22%E7%B1%BB%E5%9E%8B%22:%22%E5%96%9C%E5%89%A7%22%7D&uncollect=false&tags=%E5%96%9C%E5%89%A7",
headers=headers,)# print(res.text)print(res.json().get("count"))
2.3 cookie反爬

# -*- coding utf-8 -*-import requests
cookie="xq_a_token=edbee4e5d1e92f98548629214a6e17fe06486a8f; xqat=edbee4e5d1e92f98548629214a6e17fe06486a8f; xq_r_token=1bd9fe2188768570022d1a3f9e12934cdaa1dc53; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTcwODQ3NjMzNiwiY3RtIjoxNzA2MTk1NzQ0NzM1LCJjaWQiOiJkOWQwbjRBWnVwIn0.Dajzah-CDQ8ER2qN9cHnYH_TPjSiYoXzl7Ht1J_CE4TxQRbH8qEzrXe4LcT4KDd815rQOZ6DF4SORJbA1qltAQ-EmD1NiD0YX0FV-Ub-5ok2FDoLcD4_9dS3iNkpIyAQE8DNJZEMBUv4TuLl8tGh7g5l9PpcOlV-_rC5OYXTckDCklU5WNkvPRsSis2nIohnkz4up2STWsB1IowmYgAN3cTXABy5wFmpEY-KUsGYi49UGH5QSYzfAYdbOxVFO5YWOiKrzXV_GIJNRvL2G0N3wQBzMew-fpB0fopKO6BbzzdbKbY2hccxx3p27a_6b7hqED0PoMO34fUKH8z6p5yqvA; cookiesu=851706195765148; u=851706195765148; device_id=11c12c1015a4baf7b0208768b7589c02; Hm_lvt_1db88642e346389874251b5a1eded6e3=1706195767; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1706196050"
headers ={"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'' Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',"Referer":"https://xueqiu.com/",# "Cookie": "xq_a_token=edbee4e5d1e92f98548629214a6e17fe06486a8f; "# "xqat=edbee4e5d1e92f98548629214a6e17fe06486a8f; "# "xq_r_token=1bd9fe2188768570022d1a3f9e12934cdaa1dc53; "# "xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9."# "eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTcwODQ3NjMzNiwiY3RtIjoxNzA2"# "MTk1NzQ0NzM1LCJjaWQiOiJkOWQwbjRBWnVwIn0.Dajzah-CDQ8ER2qN9cHnYH_"# "TPjSiYoXzl7Ht1J_CE4TxQRbH8qEzrXe4LcT4KDd815rQOZ6DF4SORJbA1qltAQ-"# "EmD1NiD0YX0FV-Ub-5ok2FDoLcD4_9dS3iNkpIyAQE8DNJZEMBUv4TuLl8tGh7g5"# "l9PpcOlV-_rC5OYXTckDCklU5WNkvPRsSis2nIohnkz4up2STWsB1IowmYgAN3cTXAB"# "y5wFmpEY-KUsGYi49UGH5QSYzfAYdbOxVFO5YWOiKrzXV_GIJNRvL2G0N3wQBzMew-f"# "pB0fopKO6BbzzdbKbY2hccxx3p27a_6b7hqED0PoMO34fUKH8z6p5yqvA; "# "cookiesu=851706195765148; u=851706195765148; "# "device_id=11c12c1015a4baf7b0208768b7589c02; "# "Hm_lvt_1db88642e346389874251b5a1eded6e3=1706195767; "# "Hm_lpvt_1db88642e346389874251b5a1eded6e3=1706196050","Cookie": cookie
}
res = requests.get("https://stock.xueqiu.com/v5/stock/chart/minute.json?symbol=SZ399001&period=1d",
headers=headers
)print(res.text)
3.请求参数
requests里面的两个参数:data、params
3.1 post请求以及请求体参数
data参数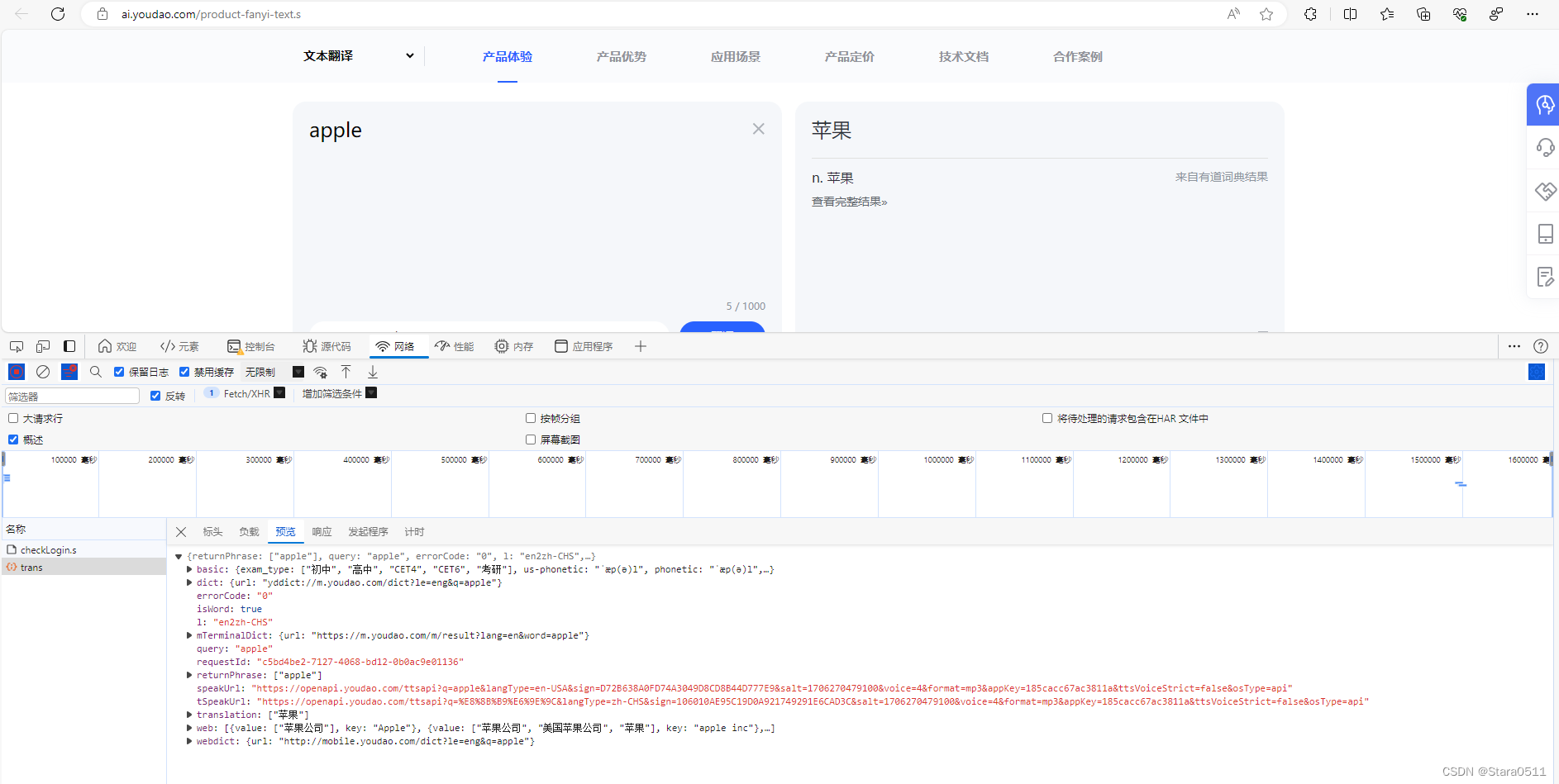
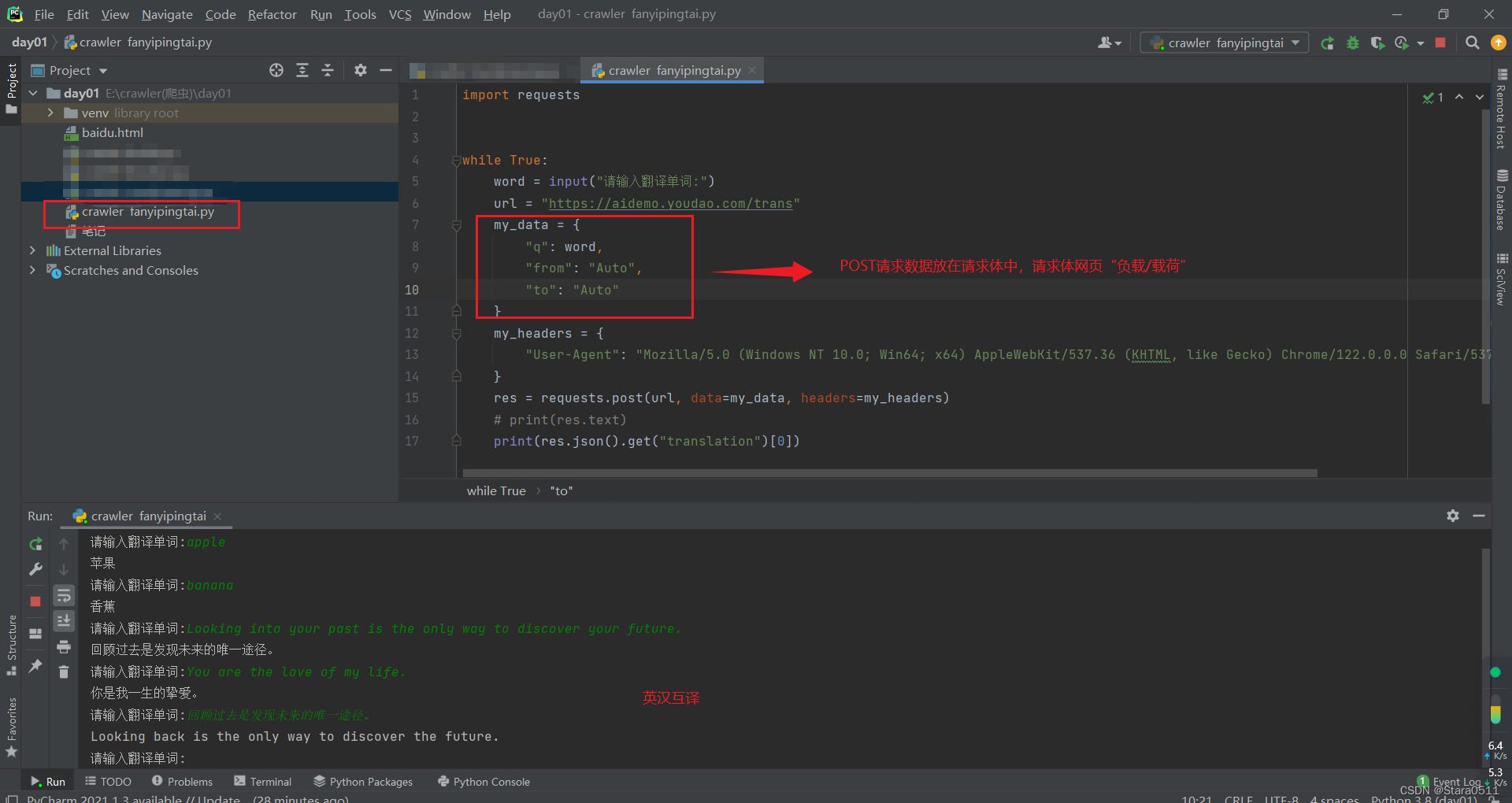
import requests
whileTrue:
word =input("请输入翻译单词:")
url ="https://aidemo.youdao.com/trans"
my_data ={"q": word,"from":"Auto","to":"Auto"}
my_headers ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"}
res = requests.post(url, data=my_data, headers=my_headers)# print(res.text)print(res.json().get("translation")[0])
3.2 get请求以及查询参数
params参数
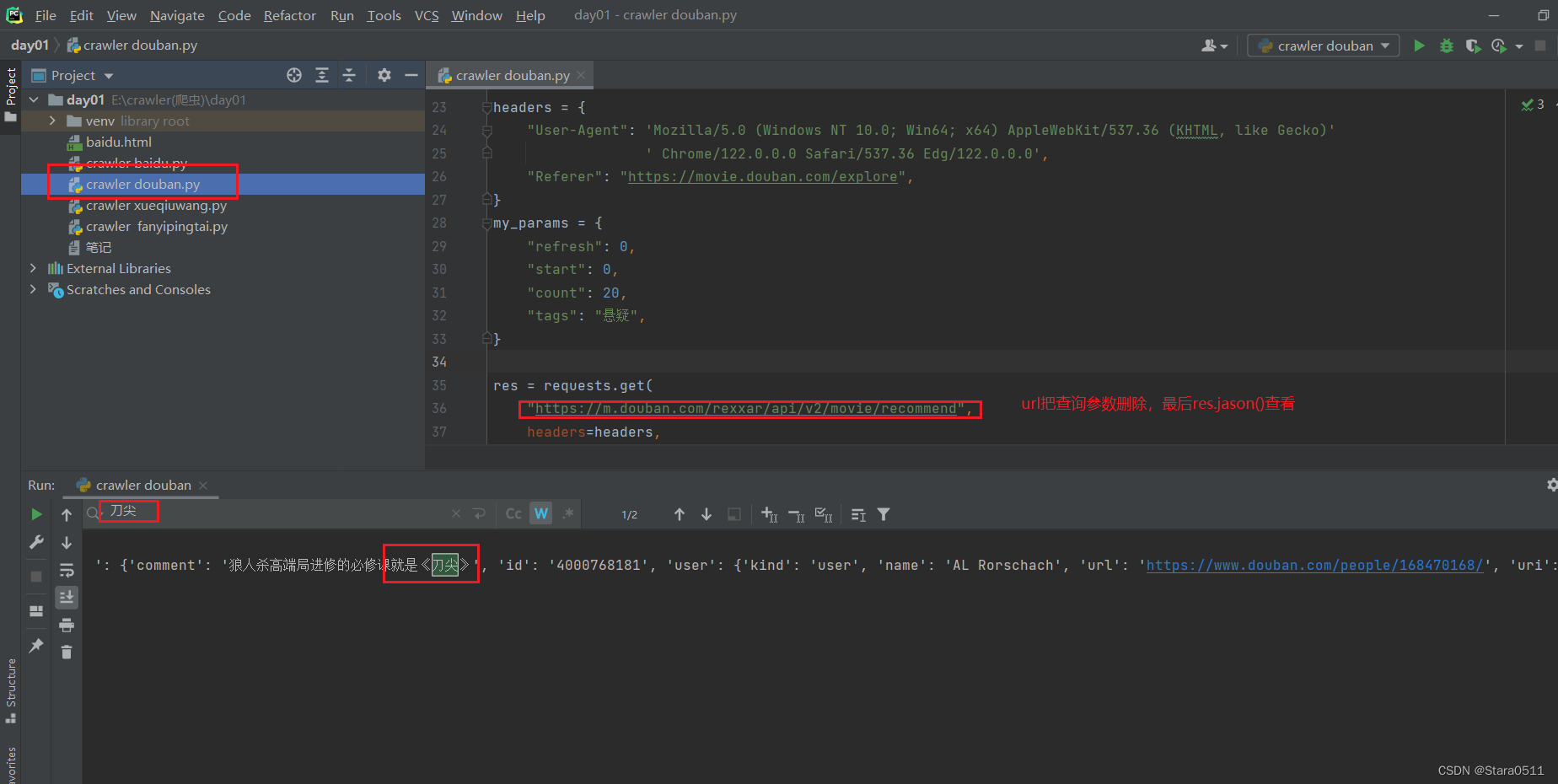
# 2.get请求以及查询参数import requests
headers ={"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'' Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',"Referer":"https://movie.douban.com/explore",}
my_params ={"refresh":0,"start":0,"count":20,"tags":"悬疑",}
res = requests.get("https://m.douban.com/rexxar/api/v2/movie/recommend",
headers=headers,
params=my_params,)# print(res.text)print(res.json())
4. 爬虫图片和视频
4.1 直接爬取媒体数据流
图片:
# -*- coding utf-8 -*-import requests
url ="https://pic.netbian.com/uploads/allimg/231213/233751-17024818714f51.jpg"
res = requests.get(url)# print(res.content)# 文件操作withopen("美女.jpg","wb")as f:
f.write(res.content)
视频
# -*- coding utf-8 -*-import requests
url ="https://apd-vlive.apdcdn.tc.qq.com/om.tc.qq.com/A2cOGJ1ZAYQyB_mkjQd9WD_pAtroyonOY92ENqLuwa9Q/B_JxNyiJmktHRgresXhfyMeiXZqnwHhIz_hST7i-68laByiTwQm8_qdRWZhBbcMHif/svp_50001/szg_1179_50001_0bf2kyaawaaafaal3yaoijqfcvwdbnlaac2a.f632.mp4?sdtfrom=v1010&guid=e765b9e5b625f662&vkey=38DF885CE72372B324B47541285404A230F61C9E12FC69B72EC8A2CF6F6809E00461165C635758EB7E7B49738D9DB608A7C855DB4E7A0B9A082A399875D82022567E1690D97ABE2A3C002ADD06D4AD5EAD4F028688C35E6D73D29DBF2D596F63C6722B78DA1EA3707EB5A7DD2F60781A45B31B693974432F649E523C08D797BA7907BFDB2562BF44E1483A3981FAAC70BEF8BD92611EF365A183621BDE70F55B2224394DB78CD7F5"
res = requests.get(url)# 解析数据withopen("相声.mp4","wb")as f:
f.write(res.content)
4.2 批量爬取数据
"""1.先爬取整个页面
2.然后做数据解析找到想要的"""import re
import os
import requests
headers ={"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',}
res = requests.get("https://pic.netbian.com/4kqiche/",
headers=headers
)# print(res.text)# 数据解析url,例如:正则,xpath,bs4都是页面中解数据# ret = re.findall(pattern:"", string:"")
img_url_list = re.findall("uploads/allimg/.*?.jpg", res.text)print(img_url_list)for img_url in img_url_list:
res = requests.get("https://pic.netbian.com/"+img_url)# print(res.content)# 文件操作
img_name = os.path.basename(img_url)withopen("./imgs/"+ img_name,"wb")as f:
f.write(res.content)
本文转载自: https://blog.csdn.net/m0_69402477/article/details/135853498
版权归原作者 Stara0511 所有, 如有侵权,请联系我们删除。
版权归原作者 Stara0511 所有, 如有侵权,请联系我们删除。