
大文件分片下载
解决大文件上传超时问题,使用Range支持,对文件进行分片下载
步骤:
一、首先通过发送0-1长度去后端获取文件大小、名称等信息返回给前端
二、前端通过文件大小、分片大小计算出分片数据量,循环请求后端,分片获取文件数据,前端组合Blob数组数据,记录当前请求的索引和数据进行组合
三、全部异步请求完毕之后,对所有数据进行从大到小排序,从新生成一个新的Blob,一定要保证数组的顺序正确,不然打开文件会有异常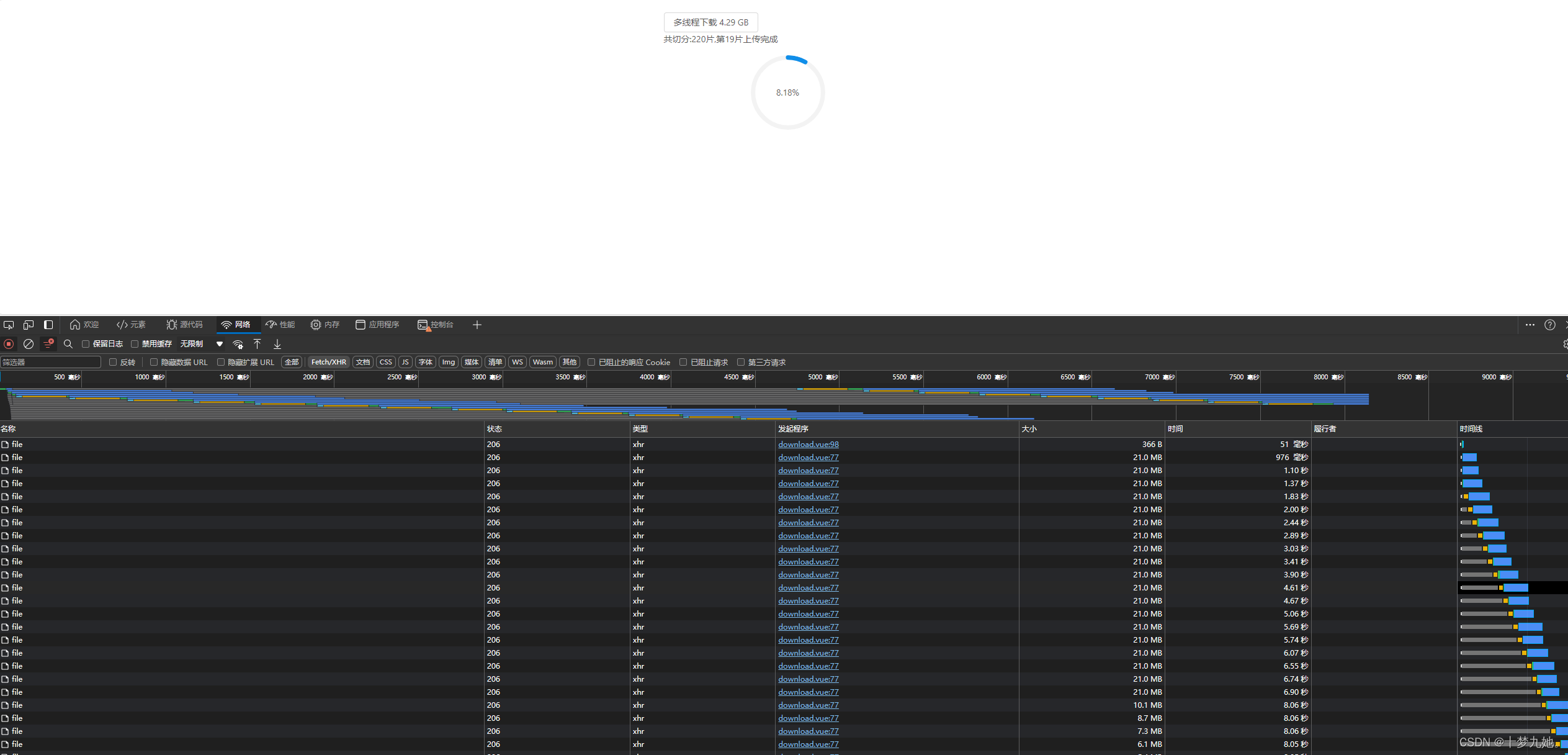
多线程异步下载
<template>
<div style="width: 400px;margin: 0 auto;margin-top: 20px">
<div style="display: flex;gap: 10px">
<a-button @click="downloadBatch" id="download">多线程下载 {{ (fileSize/1073741824).toFixed(2) }} GB</a-button>
</div>
<div>
{{ downloadText }}
</div>
<div style="margin-top: 16px;text-align: center">
<a-progress type="circle" :percent="percentage" />
</div>
</div>
</template>
<script>
import axios from 'axios'
import to from '@/utils/to'
export default {
name: 'Download',
data () {
return {
percentage: 0,
currentBlob: null,
url: '/download/file',
chunkSize: 1024 * 1024 * 20, // 单个分段大小 10M
totalChunk: 1, // 总共分几段下载
fileSize: 0, // 文件大小
downloadText: ''
}
},
methods: {
// 初始化一个空的 Blob 对象
initializeBlob () {
this.currentBlob = new Blob([])
},
// 向 Blob 对象添加新内容
appendContentToBlob (content) {
if (!this.currentBlob) {
this.initializeBlob()
}
const newBlob = new Blob([this.currentBlob, content])
this.currentBlob = newBlob
},
// 下载 Blob 对象
downloadBlob (fileName) {
if (!this.currentBlob) {
console.error('Blob 对象为空')
return
}
const downloadLink = document.createElement('a')
const fileUrl = URL.createObjectURL(this.currentBlob)
downloadLink.href = fileUrl
downloadLink.download = fileName // 设置下载的文件名
downloadLink.click()
// 释放临时URL对象
URL.revokeObjectURL(fileUrl)
this.percentage = 100
},
// 下载 Blob 对象
downloadBlobs (fileName, blobs) {
if (!blobs) {
console.error('Blob 对象为空')
return
}
const downloadLink = document.createElement('a')
const fileUrl = URL.createObjectURL(new Blob(blobs))
downloadLink.href = fileUrl
downloadLink.download = fileName // 设置下载的文件名
downloadLink.click()
// 释放临时URL对象
URL.revokeObjectURL(fileUrl)
this.percentage = 100
},
// 批量下载组合数据
downloadRange (url, start, end, i) {
return new Promise(async (resolve, reject) => {
const [err, res] = await to(axios({
method: 'get',
url: url,
data: {},
headers: { range: `bytes=${start}-${end}` },
responseType: 'blob',
timeout: 6000000 // 请求超时时间
}))
if (err) {
reject(err)
}
// 计算下载百分比 当前下载的片数/总片数
this.percentage = Number.parseFloat(Number((i / this.totalChunk) * 100).toFixed(2))
this.downloadText = `共切分:${this.totalChunk}片,第${i + 1}片上传完成`
resolve({
i,
buffer: res.data
})
})
},
async downloadBatch () {
// 发送第一次请求,从后端获取下载文件的大小等信息
const [err, res] = await to(axios({
method: 'get',
url: this.url,
async: true,
data: {},
headers: { range: `bytes=0-1` },
responseType: 'blob',
timeout: 6000000 // 请求超时时间
}))
if (err) return false
if (res.status === 200 || res.status === 206) {
// 文件名称
const fileName = decodeURIComponent(res.headers['fname'])
// 截取文件总长度和最后偏移量
const result = res.headers['content-range'].split('/')
// 获取文件总大小,方便计算下载百分比
this.fileSize = parseInt(result[1], 10) // 转为整数
// 计算总共分片数,向上取整
this.totalChunk = Math.ceil(this.fileSize / this.chunkSize)
const arr = []
for (let i = 0; i < this.totalChunk; i++) {
const start = i * this.chunkSize
let end
if (i === this.totalChunk - 1) {
end = this.fileSize - 1 // 最后一片的结束位置
} else {
end = (i + 1) * this.chunkSize - 1
}
console.log(`Chunk ${i + 1}: Start: ${start}, End: ${end}, FileSize:${this.fileSize}`)
arr.push(this.downloadRange(this.url, start, end, i))
}
Promise.all(arr).then(res => {
const blobs = res.sort(item => item.i - item.i).map(item => (item.buffer))
this.downloadText = `结果集长度为:${blobs.length}`
this.downloadBlobs(fileName, blobs)
})
}
}
}
}
</script>
<style scoped lang="less">
</style>
to 工具类
/**
* 捕获异常是使用try/catch的方式来处理,因为await后面跟着的是Promise对象,当有异常的情况下会被Promise对象的内部
* catch捕获,而await就是一个then的语法糖,并不会捕获异常, 那就需要使用try/catch来捕获异常,并进行相应的逻辑处理。
* @param promise
* @returns {Promise<T | *[]>}
*/exportdefaultfunctionto(promise){if(!promise ||!Promise.prototype.isPrototypeOf(promise)){returnnewPromise((resolve, reject)=>{reject(newError(`${promise}\r\n requires promises as the param"`))}).catch((err)=>{return[err,null]})}return promise.then(data=>{return[null, data]}).catch(err=>[err])}
Java后端代码
importio.swagger.annotations.Api;importlombok.extern.slf4j.Slf4j;importorg.springframework.web.bind.annotation.GetMapping;importorg.springframework.web.bind.annotation.RequestMapping;importorg.springframework.web.bind.annotation.RestController;importjavax.servlet.http.HttpServletRequest;importjavax.servlet.http.HttpServletResponse;importjava.io.*;importjava.net.URLEncoder;importjava.util.Optional;/**
* @version V1.0
* @Title:
* @ClassName: DownLoadController
* @Description:
*/@RequestMapping("/download")@RestController@Api(tags ="文件下载")@Slf4jpublicclassDownLoadController{privatefinalstaticString utf8 ="utf-8";@GetMapping("/file")publicvoiddownLoadFile(HttpServletRequest request,HttpServletResponse response)throwsIOException{// 设置编码格式
response.setCharacterEncoding(utf8);//获取文件路径String drive ="F";String fileName ="AdobeAcrobatProDC_setup.zip";//参数校验
log.info(fileName, drive);//完整路径(路径拼接待优化-前端传输优化-后端从新格式化 )String pathAll = drive +":\\"+ fileName;
log.info("pathAll{}", pathAll);Optional<String> pathFlag =Optional.ofNullable(pathAll);File file =null;if(pathFlag.isPresent()){//根据文件名,读取file流
file =newFile(pathAll);
log.info("文件路径是{}", pathAll);if(!file.exists()){
log.warn("文件不存在");return;}}else{//请输入文件名
log.warn("请输入文件名!");return;}InputStream is =null;OutputStream os =null;try{//获取长度long fSize = file.length();
response.setContentType("application/x-download");String file_Name =URLEncoder.encode(file.getName(),"UTF-8");
response.addHeader("Content-Disposition","attachment;filename="+ fileName);//根据前端传来的Range 判断支不支持分片下载
response.setHeader("Accept-Range","bytes");// response.setHeader("fSize",String.valueOf(fSize))
response.setHeader("fName", file_Name);//定义断点long pos =0, last = fSize -1, sum =0;//判断前端需不需要分片下载if(null!= request.getHeader("Range")){
response.setStatus(HttpServletResponse.SC_PARTIAL_CONTENT);String numRange = request.getHeader("Range").replaceAll("bytes=","");String[] strRange = numRange.split("-");if(strRange.length ==2){
pos =Long.parseLong(strRange[0].trim());
last =Long.parseLong(strRange[1].trim());//若结束字节超出文件大小 取文件大小if(last > fSize -1){
last = fSize -1;}}else{//若只给一个长度 开始位置一直到结束
pos =Long.parseLong(numRange.replaceAll("-","").trim());}}long rangeLenght = last - pos +1;String contentRange =newStringBuffer("bytes").append(pos).append("-").append(last).append("/").append(fSize).toString();
response.setHeader("Content-Range", contentRange);
os =newBufferedOutputStream(response.getOutputStream());
is =newBufferedInputStream(newFileInputStream(file));//跳过已读的文件(重点,跳过之前已经读过的文件)
is.skip(pos);byte[] buffer =newbyte[1024];int lenght =0;//相等证明读完while(sum < rangeLenght){
lenght = is.read(buffer,0,(rangeLenght - sum)<= buffer.length ?(int)(rangeLenght - sum): buffer.length);
sum = sum + lenght;
os.write(buffer,0, lenght);}
log.info("下载完成");}finally{if(is !=null){
is.close();}if(os !=null){
os.close();}}}}
本文转载自: https://blog.csdn.net/dip_chao/article/details/138345818
版权归原作者 十梦九她。 所有, 如有侵权,请联系我们删除。
版权归原作者 十梦九她。 所有, 如有侵权,请联系我们删除。