
分析&回答
Flink双流JOIN主要分为两大类
- 一类是基于原生State的Connect算子操作
- 另一类是基于窗口的JOIN操作。其中基于窗口的JOIN可细分为window join和interval join两种。
基于原生State的Connect算子操作
实现原理:底层原理依赖Flink的State状态存储,通过将数据存储到State中进行关联join, 最终输出结果。

基于窗口的JOIN操作
基于Window Join的双流JOIN实现机制
顾名思义,此类方式利用Flink的窗口机制实现双流join。通俗理解,将两条实时流中元素分配到同一个时间窗口中完成Join。
底层原理: 两条实时流数据缓存在Window State中,当窗口触发计算时,执行join操作。
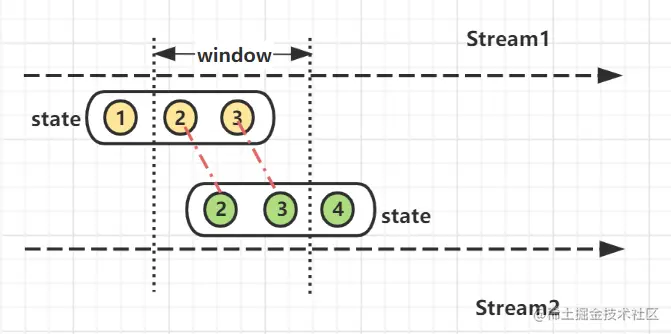
- join算子 先看看Window join实现方式之一的join算子。这里涉及到Flink中的窗口(window)概念,因此Window Joinan按照窗口类型区分的话某种程度来说可以细分出3种:
- Tumbling Window Join (滚动窗口)
- Sliding Window Join (滑动窗口)
- Session Widnow Join(会话窗口)
- coGroup算子 coGroup算子也是基于window窗口机制,不过coGroup算子比Join算子更加灵活,可以按照用户指定的逻辑匹配左流或右流数据并输出。换句话说,我们通过自己指定双流的输出来达到left join和right join的目的。
基于Interval Join的双流JOIN实现机制
Interval Join根据右流相对左流偏移的时间区间(interval)作为关联窗口,在偏移区间窗口中完成join操作。
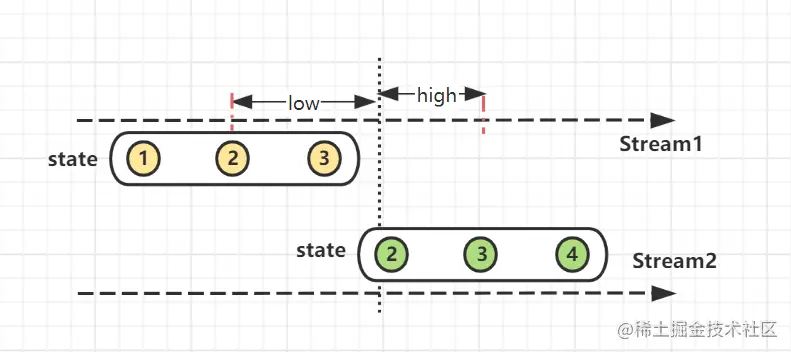
stream2.time ∈ (stream1.time +low, stream1.time +high)
满足数据流stream2在数据流stream1的 interval(low, high)偏移区间内关联join。
interval越大,关联上的数据就越多,超出interval的数据不再关联。
复制代码
实现原理:interval join也是利用Flink的state存储数据,不过此时存在state失效机制ttl,触发数据清理操作。
反思&扩展
- 为什么我的双流join时间到了却不触发,一直没有输出 检查一下watermark的设置是否合理,数据时间是否远远大于watermark和窗口时间,导致窗口数据经常为空
- state数据保存多久,会内存爆炸吗 state自带有ttl机制,可以设置ttl过期策略,触发Flink清理过期state数据。建议程序中的state数据结构用完后手动clear掉。
- 我的双流join倾斜怎么办 join倾斜三板斧: 过滤异常key、拆分表减少数据、打散key分布。当然可以加内存。
- 想实现多流join怎么办 目前无法一次实现,可以考虑先union然后再二次处理;或者先进行connnect操作再进行join操作,仅建议~
- join过程延迟、没关联上的数据会丢失吗 这个一般来说不会,join过程可以使用侧输出流存储延迟流;如果出现节点网络等异常,Flink checkpoint也可以保证数据不丢失。
喵呜面试助手:一站式解决面试问题,你可以搜索微信小程序 [喵呜面试助手] 或关注 [喵呜刷题] -> 面试助手 免费刷题。如有好的面试知识或技巧期待您的共享!
本文转载自: https://blog.csdn.net/jjclove/article/details/127406693
版权归原作者 学一次 所有, 如有侵权,请联系我们删除。
版权归原作者 学一次 所有, 如有侵权,请联系我们删除。