
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于大数据的股票预测系统
课题背景和意义
随着股票市场的不断发展,产生了大量的股票数据。但这 些历史数据往往被人们所忽略它们的价值或者在对历史数据 进行分析的过程中,难以深层次的挖掘出真正的对人们有用的 价值,信息的利用率较低。并且股票市场向来“阴晴不定”,股价 的高低起伏很大,而股票的价格变化又与每一位股票投资者 的切身利益有着密切的联系。因此,要充分利用好大数据技术 所带来的优势,结合神经网络算法,对股票的历史数据进行分 析,尽可能有效地挖掘出隐藏在股票大量数据中的规律,找出 股票的价格走势。
实现技术思路
BP神经网络基本介绍
股票市场自身具有高噪声、非线性的特点,而BP神经网络可 以较好的克服这些缺陷来对个股股票进行分析。BP神经网络, 是一种按照误差逆向传播算法训练的多层前馈神经网络,也称 之为误差反向传播神经网络,其构造的基本思路是:由信号的 正向和反向传播两部分构成了一个完整的学习过程。信号样本 值先从输入层输入,经过隐含层时按照制定的规则进行处理,再 从输出层将信号输出,若输出的样本值与期望值存在较大差异, 则进行反向传播,通过调节各个参数的权重重新进行训练学习, 如此循环往复,直到满足预期的标准为止。
收集数据
首先要收集有关股票的数据,比如股票价格、交易量、财务报表等。
确定股票数据的来源,例如股票交易所、第三方财务公司或者金融网站。
确定要收集的股票数据类型,例如价格、成交量、市值等。
创建一个程序,从股票数据来源中提取所需的数据,并存储到数据库中。
将收集的股票数据进行分析,以获得有用的信息。
数据预处理
将收集到的数据进行清洗、标准化等处理,以便用于模型训练。
1、数据清洗:检查数据中是否有缺失值,有则替换为有意义的值或者删除;
2、数据标准化:通过减去均值,再除以标准差,将数据标准化到均值为0,方差为1,使得不同特征数据之间具有可比性;
3、数据归一化:将数据的值按比例缩放至[0,1]之间,使得数据的比例变化不太大;
4、特征选择:根据建模任务,选择相关性较大的特征,以便于模型训练。
模型建立
根据所收集的数据建立合适的机器学习模型,比如KNN、SVM等。
收集股票数据:从一定时期内的历史股价、交易量及投资者活跃度等收集股票数据;
数据预处理:清洗数据,去除噪声,缩放数据;
选取模型:根据股票数据的特点选取合适的模型;
模型训练:对模型进行训练,训练参数,调整参数;
模型检验:对模型进行检验,检查模型在不同情况下的表现;
模型应用:将模型应用到实际情况,进行预测和估计。
模型训练
训练机器学习模型,以最大化预测准确性。
1、数据获取:从股票市场获取历史数据,如股价、成交量等,并将其转换为特征向量;
2、特征选择:根据股票市场的特性,从历史数据中选择合适的特征,如价格、成交量、市盈率等;
3、模型训练:选择合适的机器学习模型,使用训练数据训练模型,并调整超参数;
4、评估:使用测试数据对模型进行评估,计算准确率和召回率等指标,以确定模型的效果;
5、模型部署:将训练好的模型部署到系统,实时监控股票市场,并及时发出报警和提示。
模型验证
使用一定的评价指标,如RMSE、MAE等,来评估模型的预测准确性。
首先,要根据股票模型的特征进行分析,确定模型的参数,对股票模型进行定义和确定;
其次,要收集一定时期内的历史股票数据,收集可能影响股票模型的外部因素,比如经济形势、政治环境等;
然后,要使用历史股票数据和外部因素,对模型进行拟合,以确定模型的参数;
接着,对模型的参数进行校验,以确定模型的准确性和有效性;
最后,使用模型对未来股票行情进行预测,并对预测结果进行检验,以确认模型的可靠性。
模型部署
将训练好的模型部署到相应的环境中,以便获得实时预测结果。
(1)首先,对模型进行分析,了解模型的特点,并分析模型的输入输出,确定模型的参数。 (2)其次,准备好测试数据,要求测试数据与训练数据是一致的,以确保模型可以正确处理数据。
(3)然后,使用对应的模型部署技术,将模型部署到生产环境中,并根据需求实现模型的API接口。
(4)最后,使用测试数据对模型进行验证,检查模型的表现,以及模型部署后的效果。
一、建立股票模型思路
1. 收集股票数据:从一定时期内的历史股价、交易量及投资者活跃度等收集股票数据;
2. 数据预处理:清洗数据,去除噪声,缩放数据;
3. 选取模型:根据股票数据的特点选取合适的模型;
4. 模型训练:对模型进行训练,训练参数,调整参数;
5. 模型检验:对模型进行检验,检查模型在不同情况下的表现;
6. 模型应用:将模型应用到实际情况,进行预测和估计。
二、股票模型代码
下面是基于Python的股票模型代码:
# 导入数据
import pandas as pd
import numpy as np
# 读取数据
df = pd.read_csv('stock_data.csv')
# 清洗数据
df.dropna(inplace=True)
# 缩放数据
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(df)
df = scaler.transform(df)
# 选择模型
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
# 训练模型
model.fit(df[:,:-1], df[:,-1])
# 模型检验
from sklearn.metrics import mean_squared_error
predicted = model.predict(df[:,:-1])
mse = mean_squared_error(df[:,-1], predicted)
# 模型应用
predicted_stock_price = model.predict(new_data)
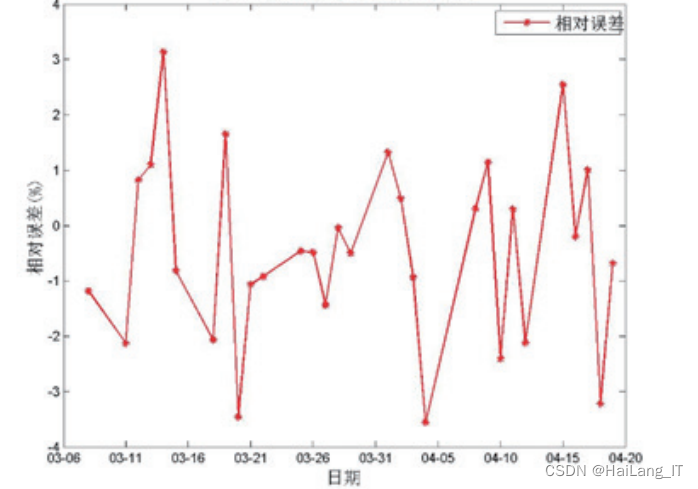
实现效果图样例
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
最后
版权归原作者 HaiLang_IT 所有, 如有侵权,请联系我们删除。