
这个文章是记录
org.apache.spark.sql.catalyst.optimizer.RewriteDistinctAggregates
如何重写count distinct
针对场景:
select
count(distinct id),
count(distinct age),
sum(age)
from student
group by grade

expand: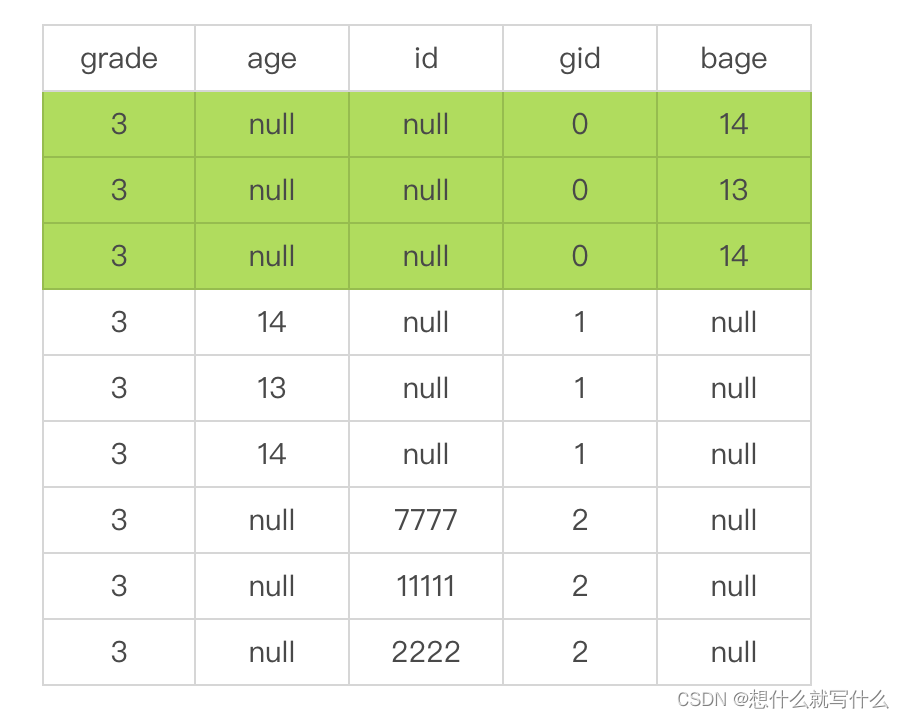
说明gid的数据内容就是上图expand显示的样子
因为存在count(distinct age) 和sum(age) ,所以在projection 中,会有针对age 有两列。
这个bage 就是sum(age),因为在底层是 sum(CAST((age) AS BIGINT)) 所以这个就写成了bage
session.sql(
“”"
| select
| id,
| age,
| gid,
| grade,
| sum(CAST((bage) AS BIGINT)) AS col1
| from gid
| group by
| id,age,gid,grade
| order by gid
|“”".stripMargin).show()
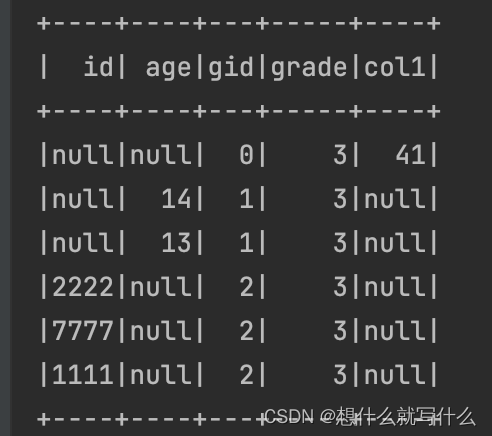
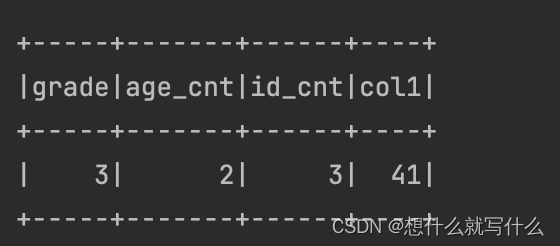
session.sql(
“”"
|select
| grade,
| count(if(gid = 1 ,age ,null)) as age_cnt,
| count(if(gid = 2 ,id ,null)) as id_cnt,
| first(if(gid = 0 ,col1,null),true) as col1
|from
|(
| select
| id,
| age,
| gid,
| grade,
| sum(CAST((bage) AS BIGINT)) AS col1
| from gid
| group by
| id,age,gid,grade
| order by gid
| )foo
| group by grade
|“”".stripMargin).show()
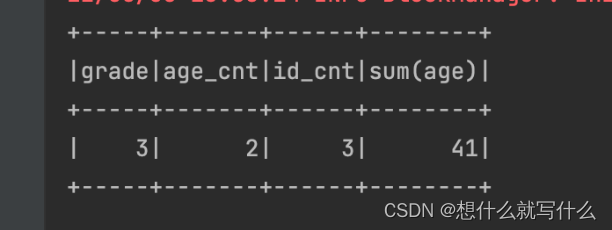
原始计算
session.sql(
“”"
|
|select
| grade,
| count(distinct age) as age_cnt,
| count(distinct id) as id_cnt,sum(age)
|from student
|group by grade
|“”".stripMargin).show
expand的规则: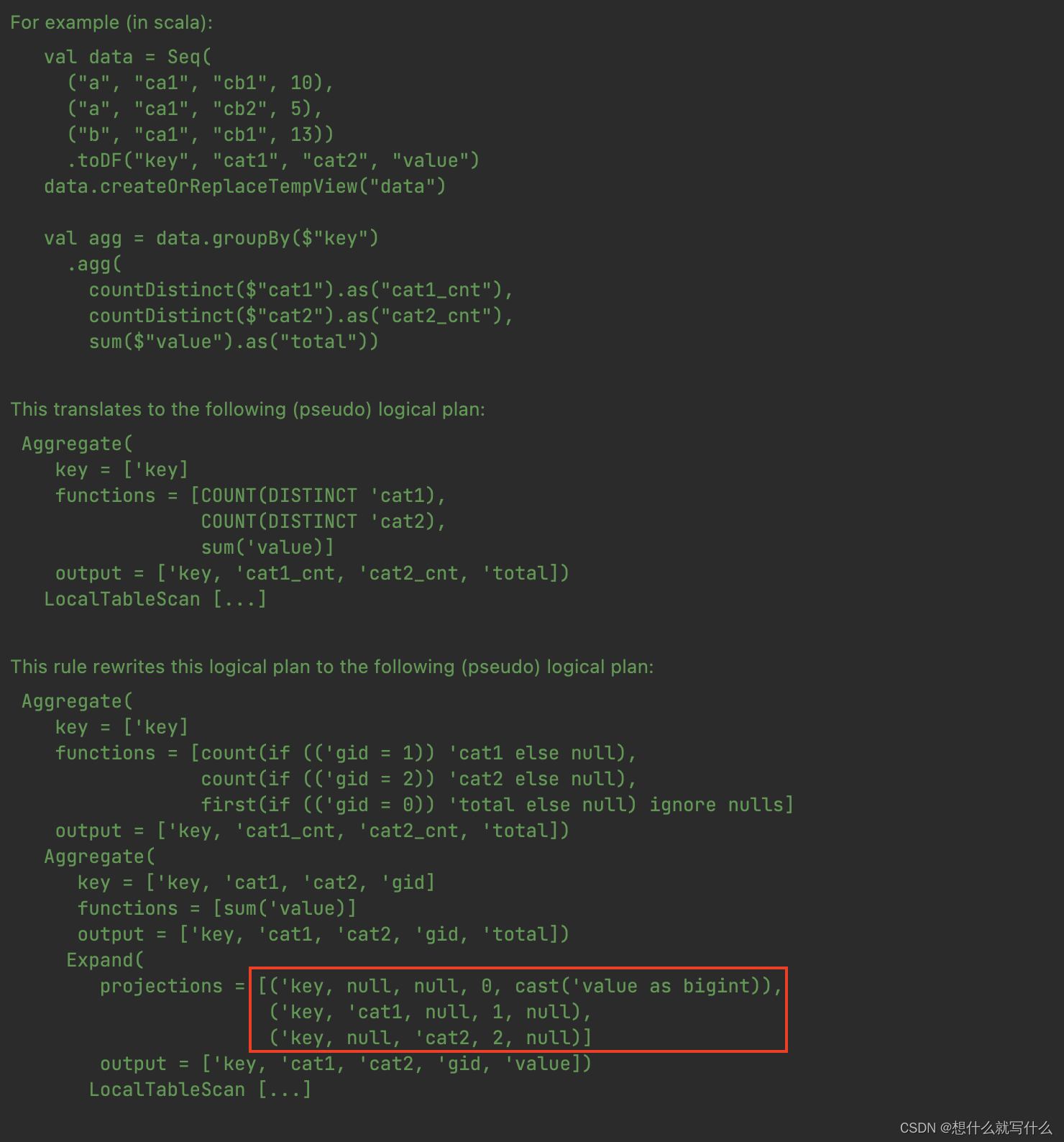
版权归原作者 想什么就写什么 所有, 如有侵权,请联系我们删除。