
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
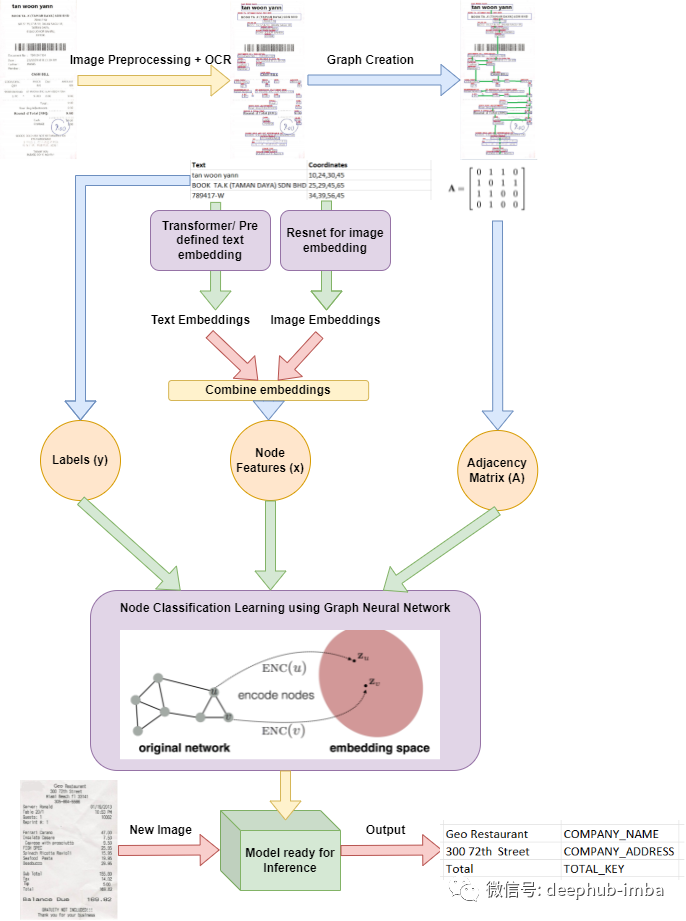
在这篇文章中,我们将介绍票据数字化的问题,即从纸制收据(如医疗发票、门票等)中以标签的形式提取必要和重要的信息。这些类型的模型在现实生活中非常有用,可以帮助用户, 为了更好地理解数据,我们日常工作的很大一部分仍然是处理纸制收据(扫描件)。在自然语言处理领域,这项任务称为序列标记,因为我们以某种形式的预定义类标记每个输入实体,例如杂货店购物的正常收据,标签可以是 TOTAL_KEY、SUBTOTAL_KEY、COMPANY_NAME、COMPANY_ADDRESS、DATE、 下图描述了这些工作的一般流程,将在接下来的部分中一一描述。
为什么要使用GNN/GCN ?
需要识别图中的局部模式,类似于 CNN 通过小窗口扫描输入数据的方式,识别窗口内节点之间的局部关系,GCN 可以从捕获图中相邻节点之间的局部模式开始 [7] 。GCNs可以良好的识别模式和层次结构。
流程介绍
让我们尝试了解这些项目的基本流程:
- 输入以图像形式或视频的形式进行捕获,这些图像进入图像预处理步骤,例如从图像中裁剪收据、直方图调整、亮度调整等。OpenCV 是此类任务的行业标准。了解图像分割,可以从[1] 中裁剪图像收据开始,还可以从[2] 了解一些常见的预处理。
- 图像被相应地裁剪和处理,我们将此图像提供给 OCR [3] 系统。这里可以根据自己的预算、需求和系统准确性使用 Google 的Cloud API [4]、Tesseract [5] 或任何你喜欢的的 OCR 系统。
- 在 OCR 过程之后,我们有一个表格,其中包含文本及其在输入图像中的位置。通常 OCR 系统会为每个检测到的文本提供左上点和右下点的坐标。
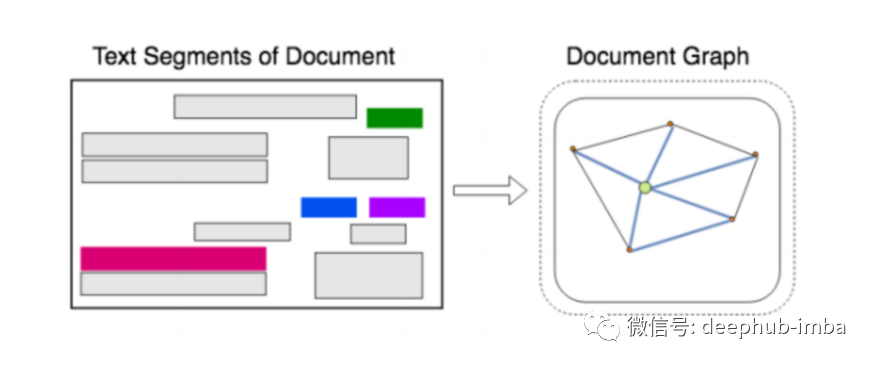
- 图神经网络将使用OCR 的输出,即收据上的边界框用于创建输入图。每个文本/边界框都被认为是一个节点,边缘连接的创建可以有多种方式。其中一种技术 [6] 为每个节点创建最多四个边,这些边将每个文本区域与每个方向(上、下、左和右)上最近的四个相邻文本区域连接起来 [7]。[8]将介绍如何进行编码。
- OCR 的输出也用于创建嵌入。要创建词嵌入,我们可以使用glove,或可以使用 预训练的Transformer 对文本段进行编码以获得文本嵌入。为每个检测到的文本创建嵌入并存储在节点特征矩阵中。使用图像的嵌入是可选的,但它们在 PICK [9] 等模型中显示出很有效的提升,因为它们可以携带有用的信息,如文本字体、大小、曲率等。比如它的字体很大可以预测文本属于 STORE_NAME 类别, 因为通常商店名称字体比收据上的其他文本大。
- 这两种类型的嵌入结合起来创建一个新的融合嵌入以更好地理解数据,并用作图神经网络的节点输入。为了更好地理解嵌入的使用,建议阅读 [9] 及其实现 [10]。
- 对于每个输出文本,我们已经为其分配了用于学习的输出类,有一些基于收据的数据集可以作为参考,例如 [11]。
- 我们有邻接矩阵(A),使用单词和图像嵌入的组合为每个节点创建的特征矩阵(x),最后是标签(y)。现在我们可以把它当作一个正常的机器学习问题,其中 A 和 x 是独立的特征,而 y 是目标,需要学习和预测。
- A、x 和 y 将用于训练基于图的神经网络模型,该模型将学习在可能的类别中对每个节点进行分类。GCN(Graph Convolution Neural Network)通过生成将输入节点表示为N维空间中的一个点的实数向量来学习嵌入节点特征向量(词嵌入和与其他节点的连接结构的组合),类似节点将被映射到嵌入空间中的相邻点,从而允许训练一个能够对节点进行分类的模型 [7]。[15]对与节点分类相关的理论进行了研究。
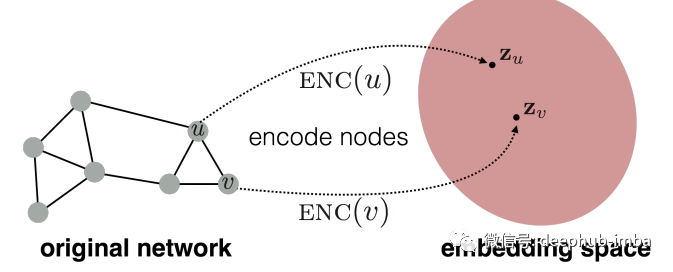
该模型在准确性、F1 分数等方面从测试集提供了令人满意的结果。它可用于现实世界数据,从收据扫描件中提取信息,使用提取文本预测其可能的类别。
总结
本文只是关于这些系统如何工作的概述,我可以推荐从 [7]、[12]、[13]、[16] 中学习更多,也许这可以使用基于开源图学习的库来实现,例如 Spektral [14] 或你喜欢的任何其他库。
引用
- Image segmentation by OpenCV : https://www.kaggle.com/dmitryyemelyanov/receipt-ocr-part-1-image-segmentation-by-opencv
- Pre-Processing from OCR!!! : https://towardsdatascience.com/pre-processing-in-ocr-fc231c6035a7
- Optical Character Recognization : https://en.wikipedia.org/wiki/Optical_character_recognition
- Google Vision API : https://cloud.google.com/vision/docs/ocr
- Tesseract : https://github.com/tesseract-ocr/tesseract
- Effecient, Lexicon free OCR using deep learning : https://arxiv.org/abs/1906.01969
- Information Extraction from Receipts with Graph Convolutional Networks : https://nanonets.com/blog/information-extraction-graph-convolutional-networks/
- Graph Convolution on Structured Document : https://github.com/dhavalpotdar/Graph-Convolution-on-Structured-Documents/blob/master/grapher.py
- PICK : https://arxiv.org/abs/2004.07464
- PICK-pytorch : https://github.com/wenwenyu/PICK-pytorch
- CORD : https://github.com/clovaai/cord
- Automizing Receipt Digitization with OCR and Deep Learning : https://nanonets.com/blog/receipt-ocr/
- Graph Convolution for Multimodel Information Extraction for Visually Rich Documents : https://arxiv.org/abs/1903.11279
- Spektral : https://graphneural.network/
- Understanding GCN for Node Classifcation : https://towardsdatascience.com/understanding-graph-convolutional-networks-for-node-classification-a2bfdb7aba7b
- Extracting Structred Data from Invoices : https://medium.com/analytics-vidhya/extracting-structured-data-from-invoice-96cf5e548e40
作者:Prakhar Gurawa
喜欢就关注一下吧:
点个 在看 你最好看!********** **********