
ES 作为一个分布式搜索引擎,从扩展能力和搜索特性上而言无出其右,然而它有自身的弱势存在,其作为近实时存储系统,由于其分片和复制的设计原理,也使其在数据延迟和一致性方面都是无法和 OLTP(Online Transaction Processing)系统相媲美的。
也正因如此,通常它的数据都来源于其他存储系统同步而来,做二次过滤和分析的。这就引入了一个关键节点,即 ES 数据的同步写入方式,本文介绍的则是 MySQL 同步 ES 方式。
将 MySQL 数据写入 ES,首先想到的一定是消费 Binlog 直连 ES 写入,这种方式简单明了,然而如果稍微考量维度多一点,就会发现该方式的一些弊端。因此还有另外一个方式,即【RocketMQ+Flink Consumer+ES Bulk】集成生态,我们将从同步延迟、消费特性,ES 写入性能、系统容灾能力四****个方面评估这两种接入方式,希望给到大家灵感并选择适合业务的同步方式。
ES 基础写入原理
ES 写入属于追加式写入,先形成特定大小的 Segment,然后定时 Merge 小数据段为大数据段以减少内存碎片,提升查询效率的过程。一个 Index 由 N 个 Shard 及其副本构成,存储了同一种 Type 类型的 Documents,由 Mapping 定义了其索引方式,每一个 Shard 由 N 个 Segment 组成,每个 Shard 都是一个全功能且完整的 Lucene 索引,它是 ES 的最小处理单元;Segment 是 ES 最小的数据处理单位,每个 Segment 都是一个独立的倒排索引。
ES 写入其实是不断将数据写入到同一个 Segment(内存),然后触发 Refresh 刷新,将 Segment 刷新到 OS Cache(默认 1s),此时数据就可以查询到了,OS Cache 会由操作系统触发 Flush 操作持久化到磁盘。
引发思考:ES 是如何保证数据不丢失的呢?追加式写入的优劣点是什么?追加式写入是如何处理数据更新问题的?MySQL 是属于哪种写入方式呢?本文重点不在此处,大家可以另行查阅文章。

ES 基本概念
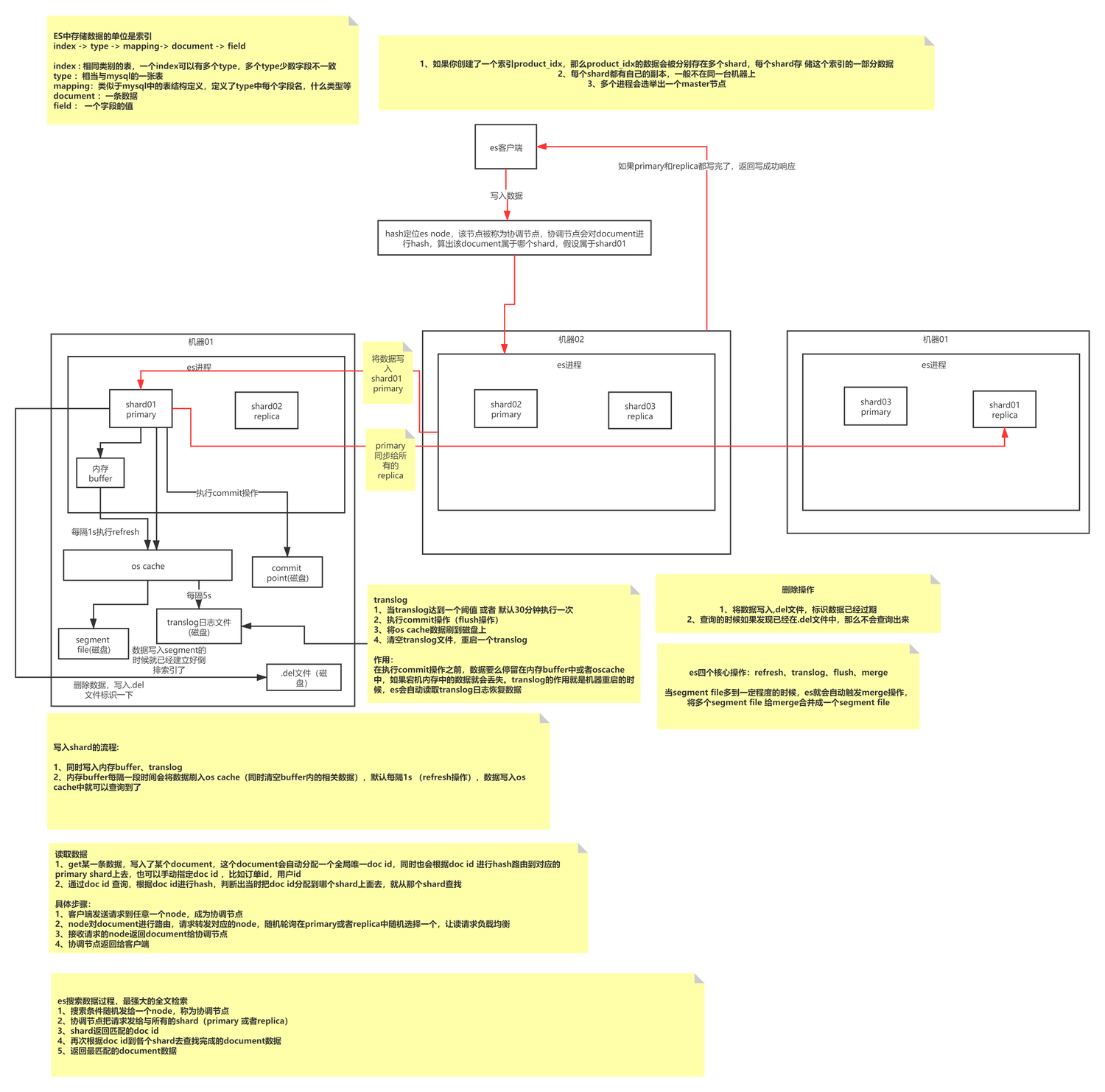
ES 写入过程
ES 直连写入

采用 ES 直连写入的优点是因为路径短,依赖组件少,加上 Dsyncer(异构存储转换系统)通常已经提供了完善的限流重试机制,所以消费延迟和消费的数据完整性都是可以保证的。
缺点:
- 不易于接入多机房容灾部署,目前 ES 容灾机房都属于独立部署,独立读写模式,所以如果采用该方式,则难以同时对多机房写入分别做管控,达不到容灾效果。Binlog-->Dsyncer 通常一个 MySQL Table 对应一个转换任务,如果为了写多机房起多个重复的转换任务,则显得有些愚笨。
- 如果自身业务场景有对同一条记录并发写场景,但写不一定全部来源于 Binlog 的情况下,那全局考虑直写 ES 则更容易遇到写入冲突问题,因为缺乏有序队列的保障。
通过 Flink 搭建 ES 集成系统

Flink 搭建 ES 集成系统,则指的是所有的 ES 写入都由 Flink 任务完成,Flink 监听 RocketMQ 实时数据流,既保证了数据的分区有序性,又充分利用了 ES 的批量写入能力,ES 的批量写入能力比单条写入性能高出多倍。同时由于 Flink 本身的容错性,即使在异常场景下,也能保证数据的最终一致性。
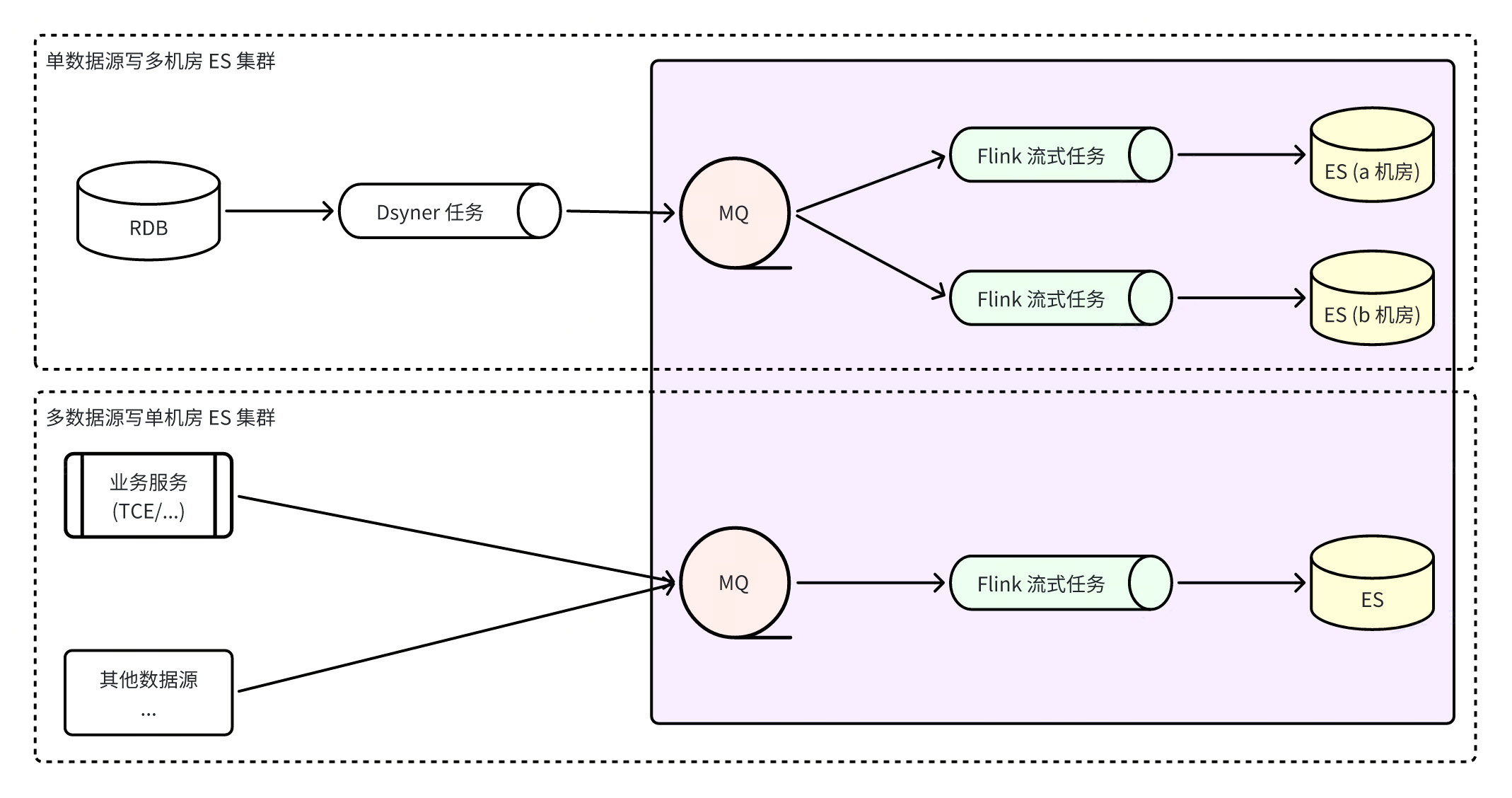
优点:
- 通过 MQ 可以更快捷的接入多机房 ES 集群,写入解耦,三机房分别起消费者写入数据,彼此独立,当出现单机房故障时,只要有可用机房,直接处理读流量切流即可,容灾方案简单清晰;
- 网络抖动等问题会导致 ES 暂时性写入失败时,不影响其他集群写入的情况下,RocketMQ 会暂存消息,Flink 会保存消费快照,不断重试直至成功,更好的保障了数据最终一致性;
- 多数据源写入能保证全局分区一致性。
缺点:
- 依赖了更多组件,会增加全链路数据同步延迟,而 ES 默认的 Refresh 频率是每秒一次,经测试该链路正常情况下数据延迟都是秒级的,不是完全不可接受;
- 依赖了更多组件,对基础组件的稳定性有更高的要求,RocketMQ 异常,或者 Flink 任务异常都会导致同步链路出现问题,增加一定的业务异常风险。
在这里需要注意的一个问题是有人可能会考虑接入多机房 ES 集群,是怎么保证多机房同时成功的、以及怎么保证写入成功后就可以查询得到?目前这两点暂时无法做到,因为多个机房都是独立写入的,互不影响,且 ES 集群属于弱数据一致性集群,无法保证写入成功立刻就能查到。
搭建并运行一个ES Flink消费程序****的必备条件:
- Flink****运行环境:首先需要有 Flink 任务的运行环境,通常企业级的 Flink 任务会作为一个 YARN 作业在分布式系统中被调度并分配资源执行,但同时 Flink 也可作为单机进程,亦或搭建一个独立集群运行。
- ES****消息格式:需要约定一种 ES 消息传输格式和序列化方式,一套范式解决所有同步场景,目前流行的序列化方式是 pb 格式或 json 格式,目前我们都是推荐使用 pb 格式的,数据格式 Schema 定义:
字段名
值类型
必需/可选
描述
_index
string
必需
文档要写入索引的名称或别名
_type
string
必需/可选
文档的类型
_op_type
string
必需
文档写入操作类型,取值范围: index, create, update, upsert, delete
_id
string
可选
文档 ID,不指定时写入 ES 会自动生成,但同一条数据被重复消费写入 ES 会生成多个文档
_routing
string
可选
文档****路由,不指定时默认使用 _id 字段值路由
_version
int64
可选
文档版本,指定时大于 0 且仅操作为 index/delete 有效,默认使用 external_gte版本类型
_source
object
必需/可选
文档内容,操作类型为 delete 时可不指定
_script
object
可选
文档脚本,操作类型为 update/upsert 时有效,但和 _source 不能同时存在
syntax = "proto3";
message ESIndexInfo {
string Name = 1; // 文档要写入索引的名称或别名
}
enum ESOPType { // 文档写入操作类型
DELETE = 0; // 删除文档
INDEX = 1; // 创建新文档或更新老文档,只能全量更新 (替换老文档)
UPDATE = 2; // 更新老文档,支持部分更新 (合并老文档)
UPSERT = 3; // 创建新文档或更新老文档,支持部分更新 (合并老文档)
CREATE = 4; // 创建新文档,存在时报错丢弃
}
message ESDocAction {
ESIndexInfo IndexInfo = 1; // 索引信息 (必需)
ESOPType OPType = 2; // 操作类型 (必需)
string ID = 3; // 文档 ID (可选)
string Doc = 4; // 文档内容 (JSON 格式, 删除操作时不需要)
int64 Version = 5; // 文档版本 (可选, 大于 0 且操作为 index/create/delete 有效)
string Routing = 6; // 文档路由 (可选, 非空有效)
string Script = 7; // 文档脚本 (JSON 格式, 操作类型为 update/upsert 有效,但和 Doc 不能同时存在)
}
- Flink****任务必要配置:监听的 RocketMQ Topic 信息,写 ES 集群信息;
- Flink****执行函数:Flink 处理流式消息有流式 SQL 和自定义应用程序两种方式,流式 SQL 约束于本身的一些限制,比如不支持同一个 MQ 有多个索引消息,而自定义编程更加灵活,比如添加各种打点,日志,错误码处理等,推荐该方式;
- Flink****资源配置:JobManager 资源配置,TaskManager 资源配置等等;
- Flink****自定义参数配置:可以自定义一些与应用程序紧密相关的动态配置,方便动态调节 Flink 消费能力,比如:
参数名
用途
默认值
job.writer.connector.bulk-flush.max-actions
单次 bulk 最大文档数,超过进行一次 flush (即执行一次 es 的 bulk 请求)
默认 300
job.writer.connector.bulk-flush.max-size
单次 bulk 最大字节数,超过进行一次 flush (即执行一次 es 的 bulk 请求)
默认 10MB
job.writer.connector.bulk-flush.interval
两次 bulk 最大间隔,超过进行一次 flush (即执行一次 es 的 bulk 请求)
默认 1000ms
job.writer.connector.global-rate-limit
全局写入限速值
默认 -1,不限速
job.writer.connector.failure-handler
指定自定义失败处理器,比如处理4xx错误,5xx错误的方式不同,429总是无限重试等;
global_parallelism_num
flink 任务全局并发度
rmq 是 queue/4,bmq/kafka 是 partition/3
max_parallelism_num
flink 任务最大并发度
mq 的 queue/partition 的个数
checkpoint_interval
创建 Checkpoint 的间隔,单位 ms (5min=300000)
默认 15min
checkpoint_timeout
创建 Checkpoint 的超时时间,单位 ms (5min=300000)
默认 10min
rebalance_enable
开启乱序消费
默认 false
对比建议
写入方式
同步延迟
写入特性
ES写入性能
消费者
容灾能力
直连
依赖组件少,延迟低
Binlog 单 key 有序
bulk写入
FaaS
较差
RocketMQ+Flink+ES
依赖组件多,延迟较高/秒级
全局单 key 有序
bulk写入
Flink
好
经过以上介绍如果业务在都可接受秒级延迟的条件下,使用 RocketMQ+Flink 的方式能够更好的实现有序性和容灾能力,Flink 在流式任务处理能力上也远优 FaaS,但是直连方式明显链路更加简洁,架构更加轻量,系统集成和维护成本较低,所以还是需要依照业务特性选择最适合的才是最好的。
版权归原作者 字节跳动云原生计算 所有, 如有侵权,请联系我们删除。