
文章目录
1.大数据生态技术
数据存储处理: 清洗, 关联, 规范化, 组织建模, 通过数据质量的检测, 数据分析然后提供相应的数据服务
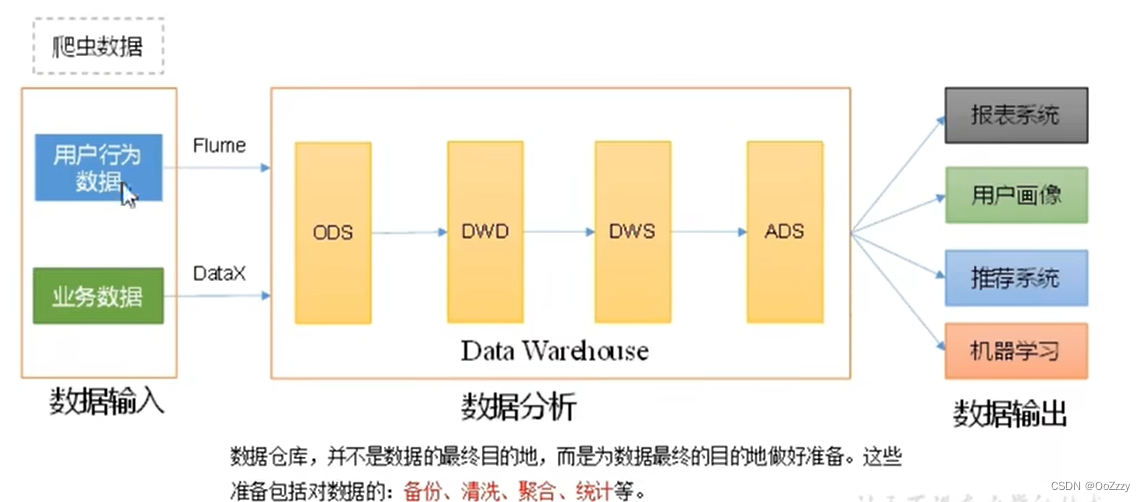
离线数仓: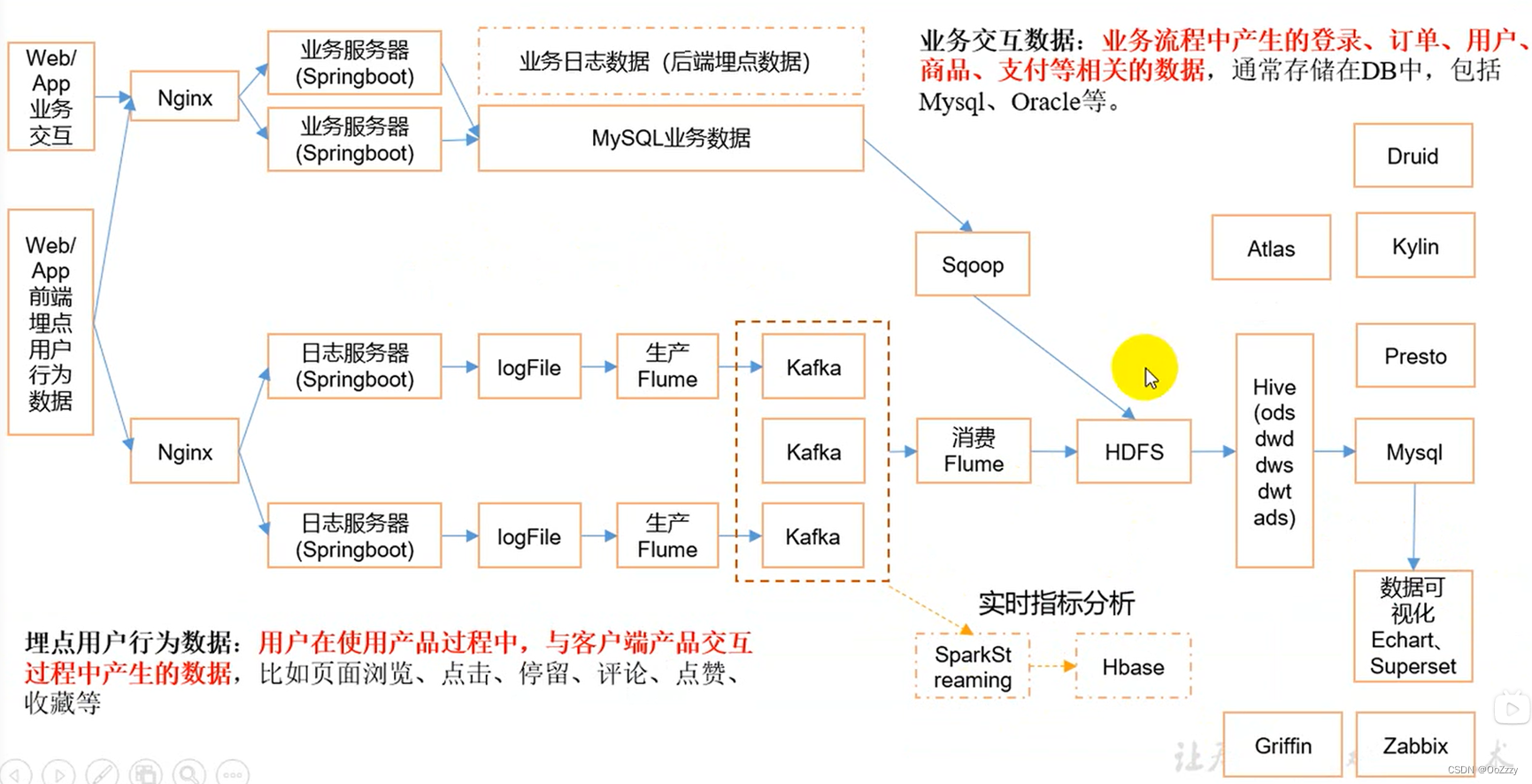
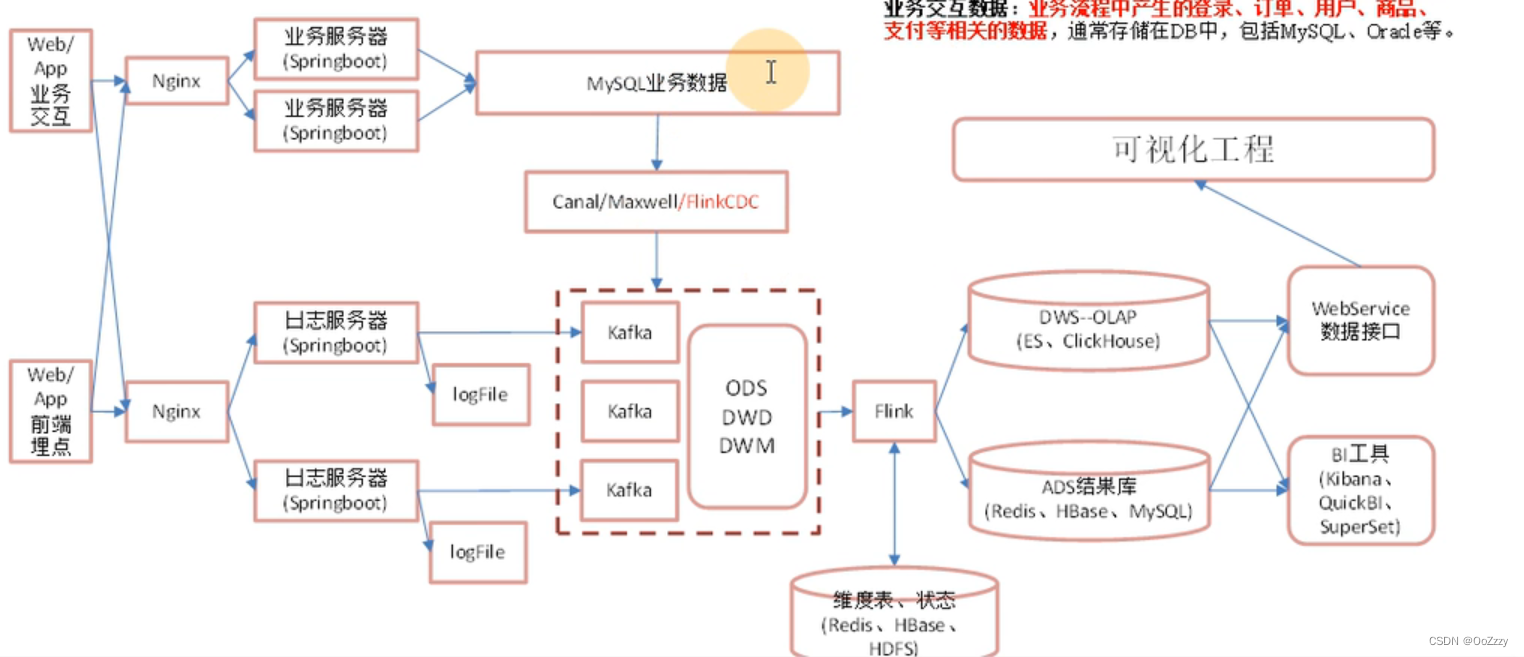
实时数仓:
以Kafka, cancal/Maxwell/FlinkCdc为区分, 离线数仓为Hive, Sqoop
实时数仓:分层: Ods, Dwd, Dim, Dwm, Dws, Ads
离线数仓分层: Ods. Dwd, Dws, Dwt, Ads
实时数仓分层分析:

数据存储: Mysql. HDFS. HBase, KUDU, TiDB
数据计算: Spark, Flink, MapReduce, Tez, Hive, Storm
交互式查询: Impala, Presto
在线实时分析: ClickHouse, Kylin, Doris, Druid, kudu
资源调度: Yarn, k8s, Mesos
任务调度: Oozie, Azakaban, AirFlow, DolphinScheduler(离线)
数据监控: Zabbix(离线), Prometheus(实时)
数据治理, 元数据管理: Atlas
数据地图, 数据可视化: DataV, QuickBI, Echarts, Superset(离线), Hue, Sugar(实时)
数据采集传输: Flume, Kafka, Sqoop, Logstash, DataX
服务协调: Zookeeper
数据同步: Maxwall, Canal, FlinkCDC, Debezium
数据迁移, 数据收集: Flume, Canal, Sqoop, DataX, Waterdrop
部署运维: Ambari, Saltstack
安全框架: Range, Kerberos, Sentry
大数据平台: HDP, CDH, CDP
数据湖: Hudi, Icebery
数据血缘: Spark
数据资产, 数据中台

2.数据存储
在整个大数据生态圈里,数据存储可以分为两大类:
1、是直接以文件形式存放在
分布式文件系统
上,处理工具可以直接读写 (Hive 和SparkSQL 都是这类)。
2、通过kafak存储
实时数据
,经过实时计算框架最后把指标数据利用NoSQL数据库来存储和管理数据(NOSQL数据库Hbase之类)。
3.数据存储的发展
数据库 -> 数据仓库 -> 数据湖
- 数据仓库存储结构化数据(先处理后存储)。
- 数据湖存储原始数据(先存储后处理)。
3.1 数据仓库
数据仓库是在企业管理和决策中面向主题的、集成的、与时间相关的,不可修改的数据集合。
1、所谓主题:要把不同业务系统的数据同步到一个统一的数据仓库中,然后按照主题域方式组织数据。主题可以把它理解为数据仓库的一个目录。
2、所谓集成:是指数据仓库中的信息不是从各个业务系统中简单抽取出来的,而是经过一系列加工、整理和汇总的过程,因此数据仓库中的信息是关于整个企业的一致的全局信息。
3、所谓随时间变化:是指数据仓库内的信息并不只是反映企业当前的状态,而是记录了从过去某一时点到当前各个阶段的信息。通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
简而言之,它综合多个业务系统数据,主要用于历史性、综合性和深层次数据分析。
在了解数据仓库之后,不得不提下经典的两个
数仓建模技术
。
恩门
提出的建模方法
自顶向下
(这里的顶是指数据的来源,在传统数据仓库中,就是各个业务数据库),基于业务中各个实体以及实体之间的关系,构建数据仓库。
金博尔
建模与恩门正好相反,是一种
自底向上
的模型设计方法,从数据分析的需求出发,拆分维度和事实。那么用户、商品就是维度,库存、用户账户余额是事实。
这两种方法各有优劣,恩门建模因为是从数据源开始构建,构建成本比较高,适用于应用场景比较固定的业务,比如金融领域,冗余数据少是它的优势。金博尔建模由于是从分析场景出发,适用于变化速度比较快的业务,比如互联网业务。
3.2 数据湖
数据湖(Data Lake)是一个以原始格式存储数据的存储库或系统。
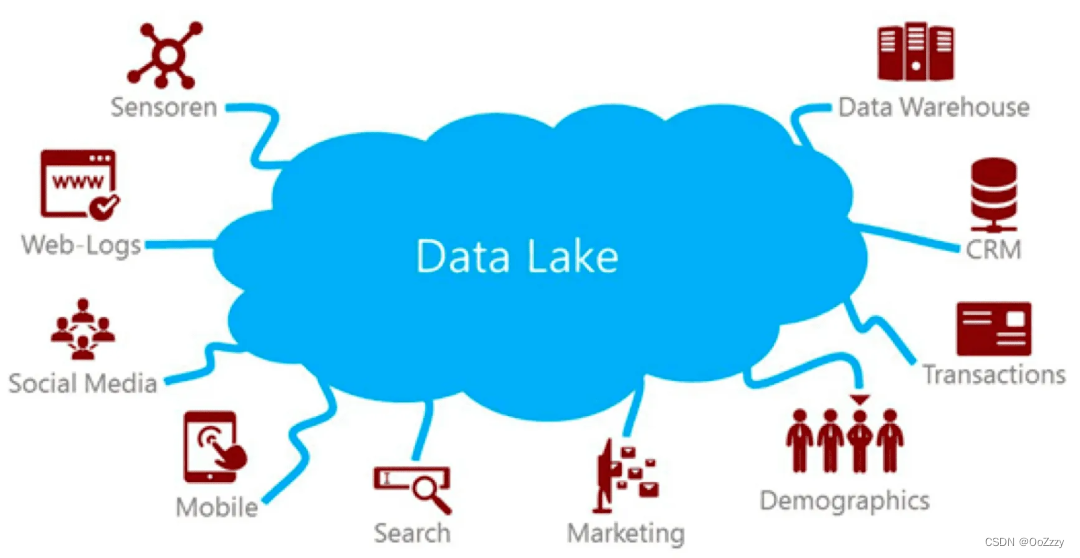
其构建组件基于Hadoop进行存储。
简而言之,数据湖原始数据统一存放在HDFS系统上,引擎以Hadoop和Spark,Flink开源生态为主,存储和计算一体。
4.数据存储的方式
4.1 批处理的数据存储
HDFS分布式文件系统
HDFS提供了一个高容错性和高吞吐量的海量数据存储解决方案。
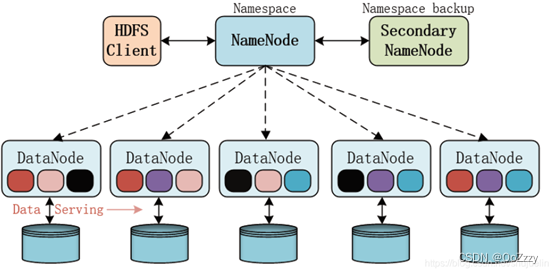
离线数据一般基于HDFS分布式文件系统作为数据仓库。
4.2 实时处理的数据存储
实时处理的数据为无界流数据,因此分为原数据存储和数据处理后的存储。
原始数据: 用户行为数据, 日志数据, 爬虫数据(ADS)
数据处理后数据: Hbase, Redis, ES, Mysql(用户行为数据) -> 报表系统, 用户画像, 机器学习, 推荐系统, 数据可视化
版权归原作者 959y 所有, 如有侵权,请联系我们删除。