
🌇🌆🌃本文已收录至:C语言——梦想系列
更多知识尽在此专栏中!
🌳前言
C语言中的数据类型可以分为两种:简单数据类型和复杂数据类型,简单数据类型就是我们经常用到的整型(int)、实型(float)、字符型(char)等,复杂数据类型中有结构体(struct)、位段(struct)、枚举(enum)和联合体(union)这几种。
** 简单数据类型负责存储简单的数据;而复杂数据类型则适用于复杂对象的描述,比如我们学生的信息、图书的信息等。使用复杂数据类型(即自定义类型)能很好的进行数据存储与访问,所以还在等什么呢?让我们一起进入更深层次的数据世界吧!**

小小精灵球中蕴含的复杂类型
🌳正文
在本篇文章中,我将会给大家介绍几种自定义类型:结构体、位段、枚举、联合体。其中结构体的内容最为丰富,也比较难。剩下几个用的都比较少,但也都很有趣,值得学习一下。
🌲一、结构体
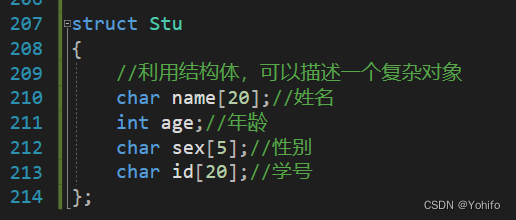
🌱1.定义
** 结构体是一种特殊数据类型,可以用来描述复杂对象,用户可以自定义其中的变量类型,比如定义一个用来储存学生信息的结构体 stu**,其中的成员变量就包含有姓名、性别、年龄、学号等信息,且信息类型可以不一样,这就打破了单一数组存储类型固定的限制。
🌱2.声明
** 结构体由必要的三部分组成:类型关键字 struct、结构体标签 tag、主体 { }; 即struct tag { }; 当然结构体标签可以省略,此时称为匿名结构体**(后面会介绍)

此时一个结构体数据就声明完成了,可以对其进行使用(初始化、调用等)
- 注意:
- 1.结构体定义时,关键字 struct 和结构体 { }; 不能少
- 2.结构体标签 tag 可以省略,但使用起来不方便
- 3.切记最后的分号 ; 不能丢
🌱3.特殊声明
** 特殊声明相较于普通说明少了标签部分,即结构体标签 tag,此时的结构体就是上面提到的匿名结构体,匿名结构体使用场景有限,并且只能创建全局性的结构体变量**。

*** 匿名结构体只能使用已经创建好的结构体全局变量,当同时出现两个匿名结构体时,编译器会认为这是两个类型不同匿名结构体*,对它们进行操作会引发警告。
//匿名结构体1
struct
{
//此时省略了结构体标签,为匿名结构体
char a;//成员变量1
int b;//成员变量2
float c;//成员变量3
}test1;//只能创建分号前的全局结构体变量
//匿名结构体2
struct
{
//此时省略了结构体标签,为匿名结构体
char a;//成员变量1
int b;//成员变量2
float c;//成员变量3
}test2 = {'A',98,9.8f},*p2;//只能在这里进行初始化
int main()
{
p2 = &test1;//引发了报错
return 0;
}

- 注意:
- 1.匿名结构体只能创建全局性的结构体变量
- 2.全局性的结构体变量创建好后,只能紧接着对其初始化,无法在调用环境中初始化
- 3.当出现多个匿名结构体时,编译器会认为是不同的类型,强行使用会引发警告
🌱4.自引用
** 自引用是指在结构体中能找到一个和自己类型相同的成员,有点像递归,但两者本质上不是一个东西。结构体自引用出现于链表中,比如单链表中有一个 data 数据域和一个 next 指针域,其中的成员变量 next 的类型是结构体指针,此行为就是自引用**。

//结构体自引用
//链表中用到了自引用
struct SList
{
int data[10];//数据域
struct SList* next;//指针域
};
int main()
{
struct SList s2 = { {6,7,8,9,10},NULL };
struct SList s1 = { {1,2,3,4,5},&s2 };
printf("%d %d\n", s1.data[0], s1.next->data[0]);//模拟实现链表
return 0;
}
结构体自引用是链表实现的必须项,理解透彻了,链表学起来就会很容易
- 注意:
- 1.自引用时,其中的某个成员变量名必须和结构体类型相同,关键字、标签名、指针一样都不能少
- 2.使用自引用时,各变量首尾链接关系要理清
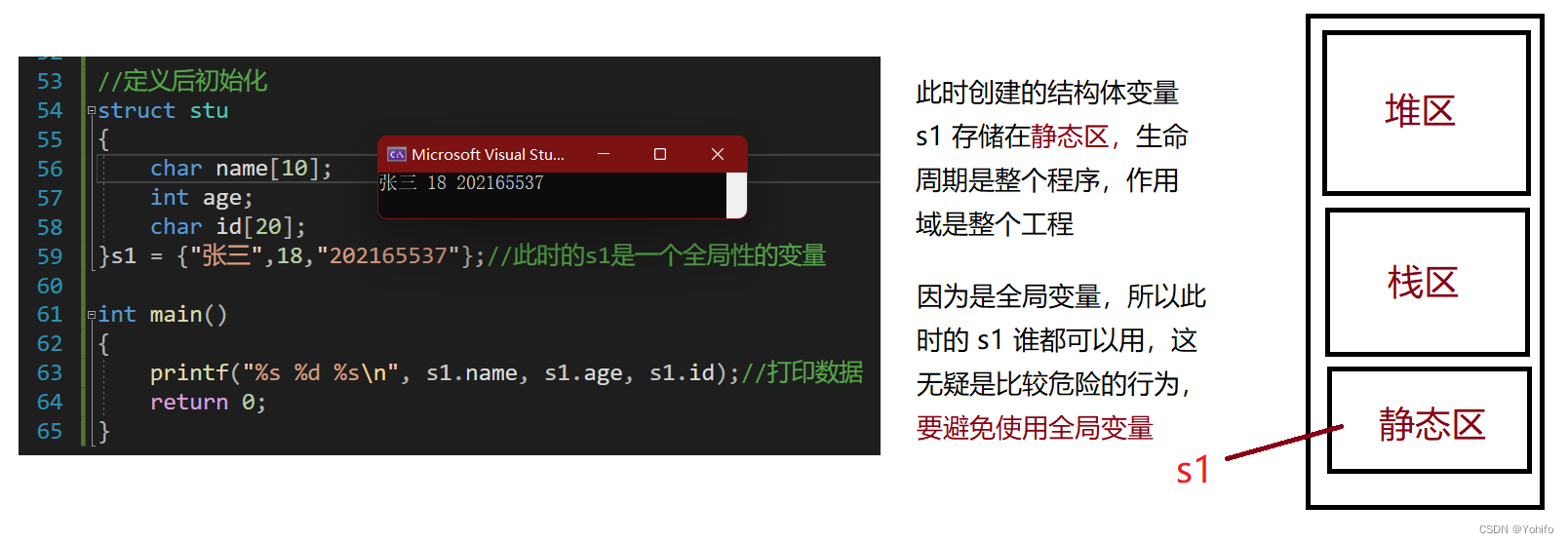
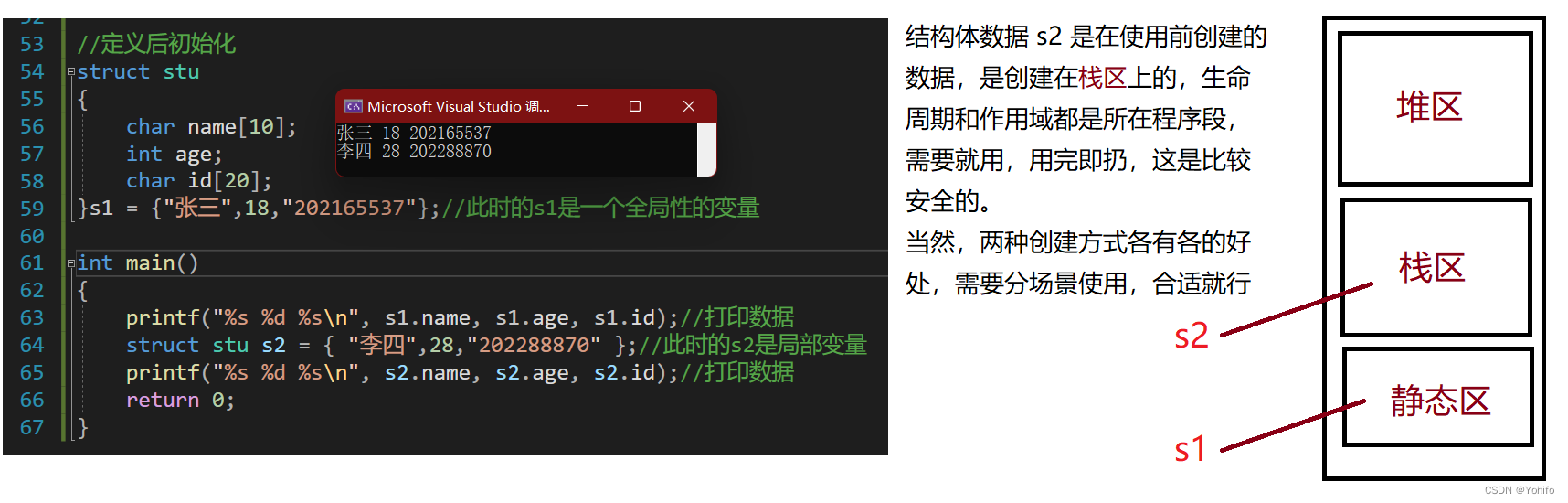
🌱5.变量的定义和初始化
定义和初始化有两种方式,在结构体声明后和使用前,前者所创建的结构体变量具有全局属性,后者就只是一个普通的局部变量,结构体支持嵌套定义和指定元素初始化。
🪴声明后初始化:
🪴使用前初始化:
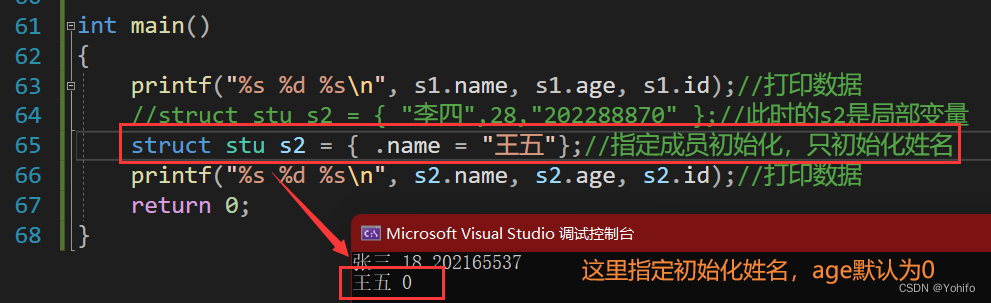
当然结构体初始化还有更多玩法,比如下面的指定成员初始化:
🪴嵌套定义:
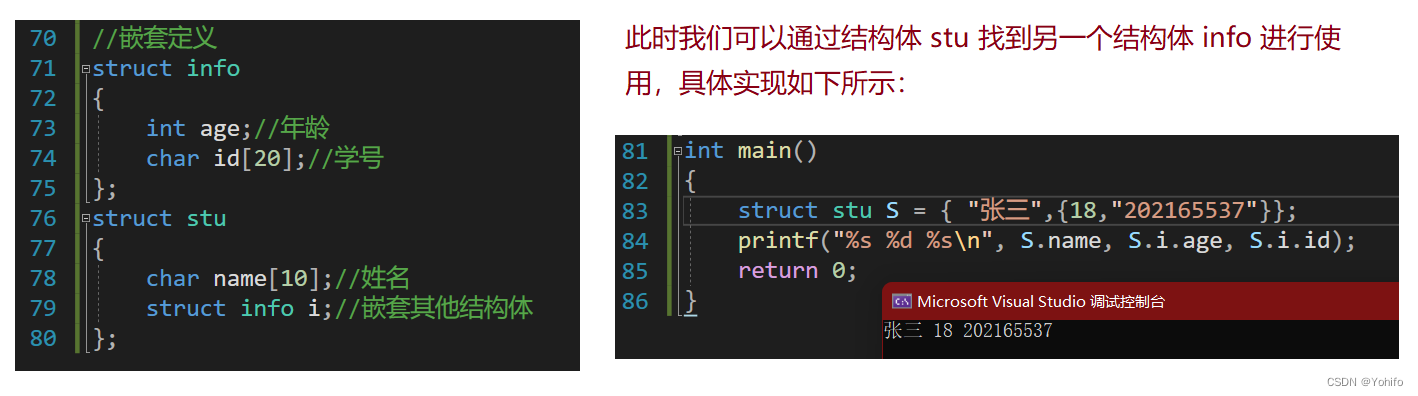
- 注意:
- 1.全局变量默认初始化为0,局部变量为随机值
- 2.当对局部变量进行指定成员初始化时,其他成员会初始化为0
- **3.结构体嵌套定义时,初始化子字符串需要再次进行访问 **
🌱6.内存对齐
** 内存对齐是个很有意思的东西,为了方便数据读取,设计出了这么个东西。内存对齐规则很多,但好处也很多,是近年热门的考点**,所以内存对齐值得我们花时间去学习。
图片来源:百度百科
简言之,内存对齐就是使结构体中的数据在内存中的存储更有规律,方便读取数据。下面是一个关于内存对齐的实际例子,按照常理来说,此结构体所占空间应为13字节,但事实真如此吗?
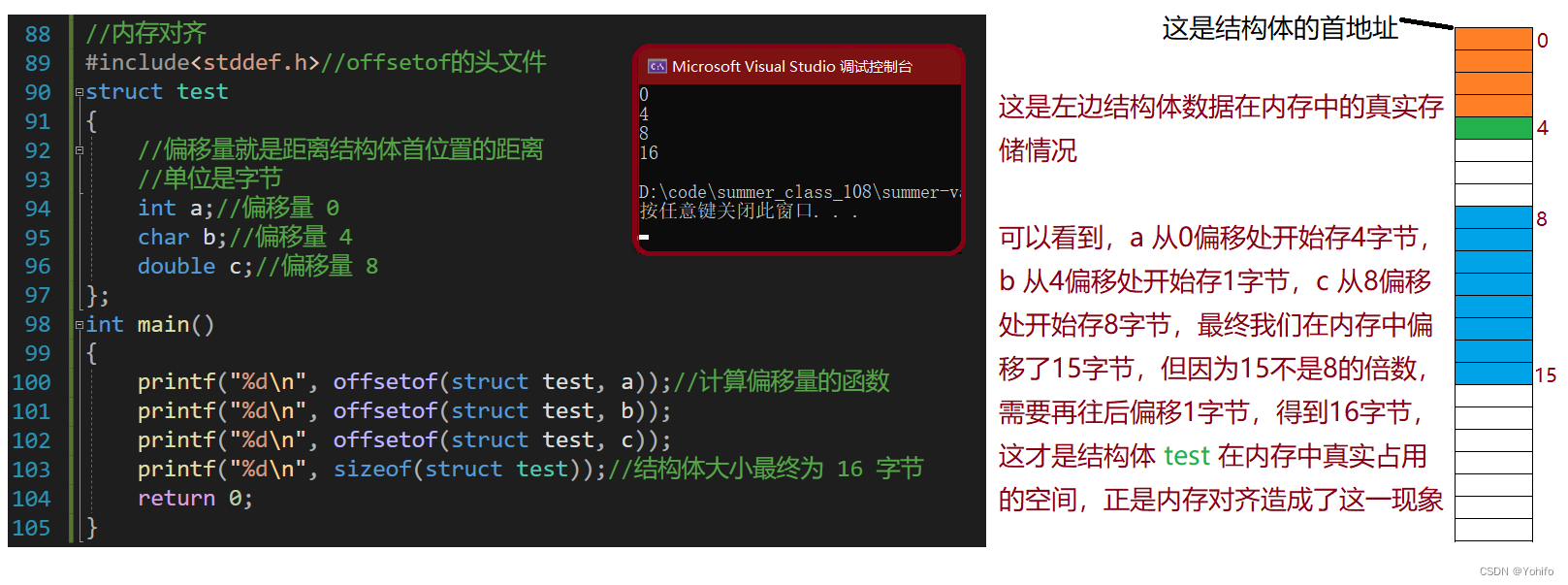
//内存对齐
#include<stddef.h>//offsetof的头文件
struct test
{
//偏移量就是距离结构体首位置的距离
//单位是字节
int a;//偏移量 0
char b;//偏移量 4
double c;//偏移量 8
};
int main()
{
//offsetof 是一个宏,可以用来计算偏移量
printf("%d\n", offsetof(struct test, a));//计算偏移量的函数
printf("%d\n", offsetof(struct test, b));
printf("%d\n", offsetof(struct test, c));
printf("%d\n", sizeof(struct test));//结构体大小最终为 16 字节
return 0;
}
显然,最终结果不是我们预想的13字节,而是更大的16字节,编译器为什么会有这种浪费空间的行为呢?还是那句话,为了方便数据的读取。
比如在有对齐环境下,先存入一个char型数据,偏移量0,再存入一个int型数据,偏移量为4,当程序读取数据,只需要读取两次,第一次完全读取char,第二次完全读取int,只需要两次就能清楚的读到数据,且不会有额外的操作。
如果没有内存对齐,那么第一个char偏移量为0,第二个int偏移量为1,当第一次读取char时,会误读到int的部分数据,此时会进行额外操作,同样的第二次读取int也需要进行额外读取,这样是非常浪费时间的。
所以诞生了内存对齐这种奇妙规则:用空间换时间,提高程序运行效率。
图片来源:百度百科
- 内存对齐的规则:
- 1.结构体中的第一个成员,对齐至结构体起始位置的0偏移处
- 2.从第二个成员开始,要对齐至某个对齐数整数倍的偏移处(对齐数:结构体成员自身大小和默认对齐数的较小值,VS中默认对齐数为8字节,Linux中没有设置默认对齐数)
- 3.结构体的总大小必须是最大对齐数的整数倍,最大对齐数就是结构体成员中对齐数的最大值
- 4.如果是结构体嵌套的情况,则嵌套的结构体要对齐到自己的最大对齐数整数倍处,此时结构体的整体大小就是所有对齐数(包括嵌套的结构体)中最大对齐数的整数倍
内存优化方案:创建成员变量时,尽量把占用空间小的成员集中在一起。
🌱7.修改默认对齐数
VS中的默认对齐数是8字节,Linux中没有规定默认对齐数,当然我们可以通过特殊手段修改默认对齐数,让数据在内存中不对齐,结构体大小计算更简单(不推荐这样玩)。
** 内存对齐这个规则并不是定死的,我们可以通过 pragma 来修改默认对齐数,如果把对齐数修改为1,这样相当于直接没有对齐,空间是省下来了,但效率却下降了。**
我们借用上一题举例,修改默认对齐数为1字节。
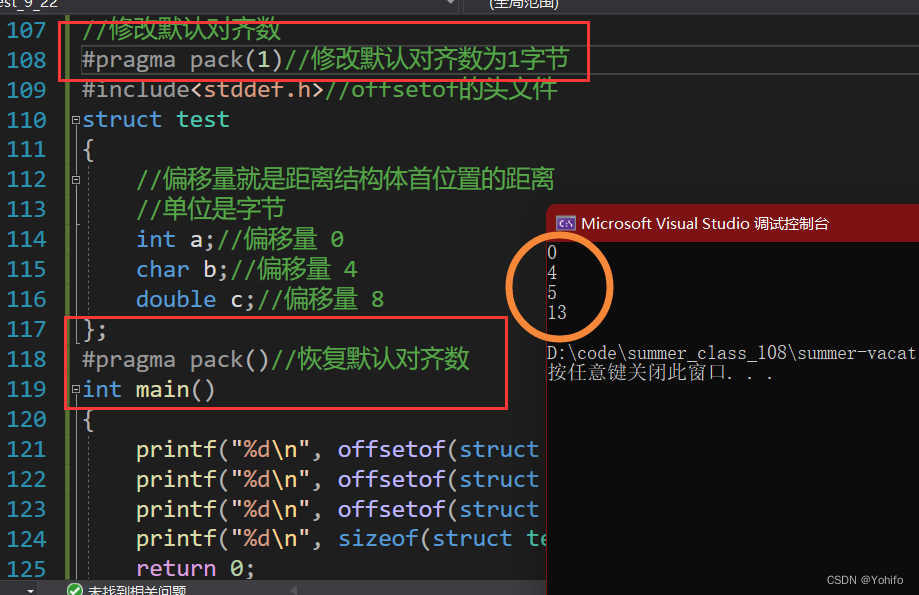
//修改默认对齐数
#pragma pack(1)//修改默认对齐数为1字节
#include<stddef.h>//offsetof的头文件
struct test
{
//偏移量就是距离结构体首位置的距离
//单位是字节
int a;//偏移量 0
char b;//偏移量 4
double c;//偏移量 8
};
#pragma pack()//恢复默认对齐数
int main()
{
printf("%d\n", offsetof(struct test, a));//计算偏移量的函数
printf("%d\n", offsetof(struct test, b));
printf("%d\n", offsetof(struct test, c));
printf("%d\n", sizeof(struct test));//结构体大小最终为 16 字节
return 0;
}
可以看到,结果为我们预想中的13字节,从侧面说明内存对齐是真实存在的。
- 注意:
- 1.一般情况下不要修改默认对齐数,避免破坏代码的可移植性
- 2.当结构在对齐方式不合适的时候,我么可以自己更改默认对齐数。
- 3.修改完默认对齐数后,记得改回来
🌱8.结构体传参
** 结构体传参有两种方式:传值与传址,传值不会对原数据造成影响,但会申请一块同样大的空间;传址能间接修改原数据,且只占一个指针大小的空间。虽说结构体名是结构体首元素地址,但在接收时是以一级指针接收的,相当于接收了个变量值,因此最好是传递 &结构体名 (即传递结构体指针变量),指针毕竟只需要 4/8 字节空间,拥有传值的功效,且不像传值那样临时拷贝所有数据,造成空间的浪费。

//结构体传参
struct test
{
int arr[1000];//大小为1000,比较大
int num;//成员变量2
};
void print1(struct test T1)
{
printf("%d\n", T1.num);//打印第二个成员变量的值
}
void print2(struct test* T1)
{
printf("%d\n", T1->num);//打印第二个成员变量的值
}
int main()
{
struct test t1 = { .num = 1000 };//指定成员初始化
print1(t1);//传值,会产生一份临时拷贝赋给T1
print2(&t1);//传址,直接把结构体地址赋给T1
return 0;
}
注意:
1.结构体传参,首选址传递,节省空间、简洁高效
2.如果执意选择值传地址,参数压栈的开销会比较大,导致性能下降
🌲二、位段
🌱1.定义
** 位段这个概念比较少见,因为位段这个东西本身不确定性就很多:比如可移植性差,最大位数不确定等,因此用的比较少,但如果是在固定环境下频繁使用的代码,位段就是一个非常厉害的工具,它能控制变量所占字节数,最大限度的节省空间。**
🌱2.声明
** 位段**的基本形式 struct tag { }; 与结构体一致,区别在于:
- **1.位段中的成员必须是整型家族(int、char),因为位段按4字节或1字节进行空间开辟 **
- 2.位段成员后面要有冒号 : 和数字,冒号表示这是一个位段成员,数字表示此成员占用的空间(单位是比特)
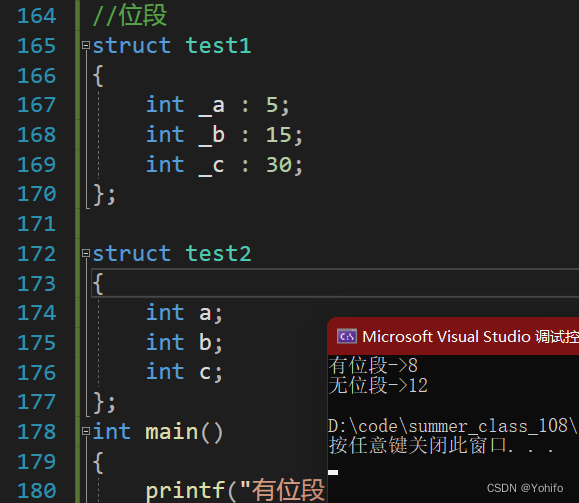
//位段
struct test1
{
int _a : 5;
int _b : 15;
int _c : 30;
};
struct test2
{
int a;
int b;
int c;
};
int main()
{
printf("有位段->%d\n", sizeof(struct test1));
printf("无位段->%d\n", sizeof(struct test2));
return 0;
}
🌱3.内存分配
当我们了解完位段的基本结构后是否好奇它在内存中的存储方式呢?


位段的内存分配
🌱4.实际运用
** 位段的使用场景比较有限,但如果用好了就是一件利器,能很好的节省空间,使数据传输更高效,没错,在网络数据传输中就用到了位段**。

如图所示,前五行每行占4字节大小的空间,不同的地方需要存入不同的数据,此时利用位段最大化利用空间,只需要使用区区20字节的空间就能装下关键信息,大大提高了数据传输的效率。
🌱5.注意
- 注意(位段的跨平台问题):
- 1.关于 int 是否带符号是不确定的
- 2.位段中能存放的最大字节数是不确定的
- 3.位段中的空间内存分配给成员时,是从左向右分配还是从右向左分配是不确定的
- 4.当位段存储数据时,剩余空间是否利用是不确定的
- 5.位段中也存在内存对齐,但仅仅是针对整体的对齐,即位段大小要为其中最大对齐数的整数倍
🌲三、枚举
🌱1.定义
** 枚举即一一列举,枚举一般称为枚举常量,枚举的形式跟结构体类似,即 enum tag { }; 值得一提的是,枚举中的成员变量定义时,不是以分号 ; 结尾的,而是以逗号 , 区分,并且最后一个枚举成员不用加任何符号,关于枚举常量的大小(标准未定义),在VS中是4字节。**
🌱2.声明
下面是枚举类型的声明,其中的成员变量可以自由定义,当然也可以赋初值

🌱3.实际运用
枚举常量可以和 switch 配合使用,用来优化部分逻辑,比如下面这个逻辑菜单:
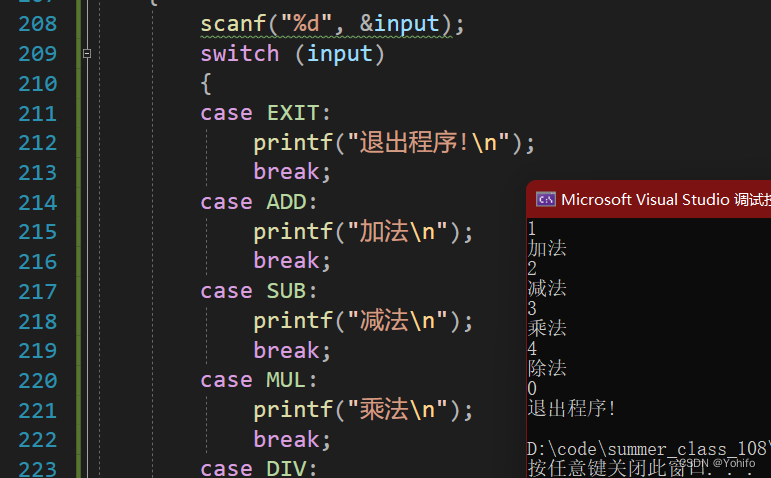
//枚举运用
enum test
{
//利用枚举定义五个通道
EXIT,
ADD,
SUB,
MUL,
DIV
}s;
int main()
{
int input = 1;
while (input)
{
scanf("%d", &input);
//利用枚举常量配合case通道
switch (input)
{
case EXIT:
printf("退出程序!\n");
break;
case ADD:
printf("加法\n");
break;
case SUB:
printf("减法\n");
break;
case MUL:
printf("乘法\n");
break;
case DIV:
printf("除法\n");
break;
default:
break;
}
}
return 0;
}
当然这只是枚举的基本用法,关于枚举的高阶用法需要代码量的积累,也就是靠自己悟。
🌱4.注意
- 枚举的优点:
- 1.提高程序的可读性和可维护性
- 2.有类型检查,比较严谨
- 3.防止命名污染,因为枚举常量已封装
- 4.便于调试(#define定义的标识符常量在预编译阶段会被替换)
- 5.使用方便,可以自由定义多个变量
🌲四、联合体
🌱1.定义
** 联合体有点像结构体的对立面,为什么这么说呢?因为结构体会追求成员变量的对齐,而联合体不会;结构体可以同时使用多个成员变量,联合体一次只能用一个。由此可知,联合体中的成员变量共用一块内存空间,比如其中定义了一个字符型和一个整型,最终联合体的大小为4字节(一个整型大小),联合体中也有内存对齐,不过不像结构体那样严格,联合体在进行内存对齐时,会判断此时所占字节数是否为其中最大对齐数的倍数**,如果不是,就会自动对齐。
🌱2.声明
老样子,形式跟结构体差不多,为union tag { }; 内部的成员变量会共用一块空间

🌱**3.妙用解题 **
数据在内存有两种存储方式:小端字节序储存和大端字节序存储,小端看着是反的,大端看着是正的,这也就是为什么有时候通过内存调试,发现数据与预想不一样的原因(因为是按小端字节序储存的),我们可以自己程序来判断当前机器的大小端,普通的解法以前已经介绍过了,如今我们可以利用联合体巧妙判断大小端。
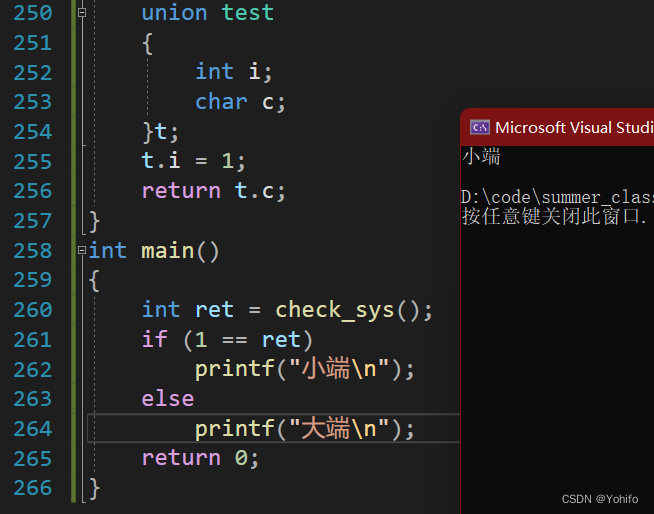

这种解法是非常妙的,揉合了各种知识点,是一段高级的代码。
//联合体判断大小端
int check_sys(void)
{
union test
{
int i;
char c;
}t;
t.i = 1;
return t.c;
}
int main()
{
int ret = check_sys();
if (1 == ret)
printf("小端\n");
else
printf("大端\n");
return 0;
}
🌱4.注意
- 1.联合体的大小至少是最大成员的大小。
- 2.联合体中也存在内存对齐,同样是只针对整个联合体的内存对齐,要使整个联合体所占字节数为最大成员对齐数的倍数。
🌳总结
** 以上就是自定义类型的全部内容了,除了结构体其他几个都比较少见,因此我们对结构体的多个方面都进行了剖析;但正因为其他的少见,属于偏底层的知识,所以我们才需要去学习,增加内功,拉开与其他人之间的距离。 总之,自定义类型可以用来描述复杂对象,实现更高级的数据存储以及较复杂的程序实现,比如我们耳熟能详的C语言课设系列(通讯录、职工工资管理系统等),其中就必须使得自定义类型,其实都不难,只要好好学习就能乘风破浪!**
** 如果你觉得本文写的还不错的话,期待留下一个小小的赞👍,你的支持是我分享的最大动力!**
** 如果本文有不足或错误的地方,随时欢迎指出,我会在第一时间改正**

临渊羡鱼,不如退而结网
相关文章推荐
C语言初阶——结构体_Yohifo的博客-CSDN博客
C语言进阶——数据在内存中的存储_Yohifo的博客-CSDN博客
C语言进阶——指针进阶_Yohifo的博客-CSDN博客
版权归原作者 Yohifo 所有, 如有侵权,请联系我们删除。