
一、基于命令行使用Kafka
**** 类似scala,mysql等,命令行是初学者操作Kafka的基本方式,kafka的模式是生产者消费者模式,他们之间通讯是通过,一个公共频道完成****
二、创建一个名为“itcasttopic”的主题
****kafka-topics.sh --create --topic itcasttopic --partitions 3 --replication-factor 2 --zookeeper master:2181,slave1:2181,slave2:2181 ****
--create --topic itcasttopic: 创建主题名称是 itcasttopic
--partitions 3 : 分区数是3
--replication-factor 2:副本数是 2
--zookeeper master:2181,slave1:2181,slave2:2181 : zookeeper:服务的IP地址和端口

****#********#删除主题##****
$**** bin/kafka-topics.sh --delete -zookeeper master:2181,slave1:2181,slave2:2181 --topic itcasttopic****
①、创建生产者
****kafka-console-producer.sh ****** --broker-list master:9092,slave1:9092,slave2:9092 ******--topic itcasttopic****

(上面是等待输入光标在闪烁)
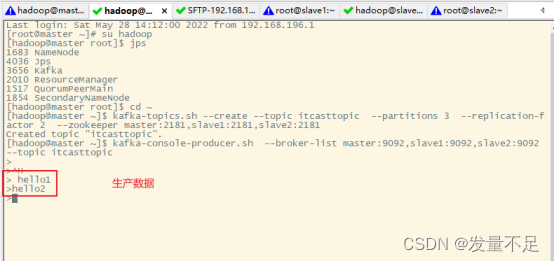
转换到slave****1
②、创建消费者****
****kafka-console-consumer.sh ****** --from-beginning --topic itcasttopic ******--bootstrap-server master:90****
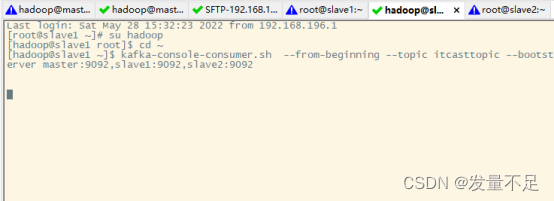
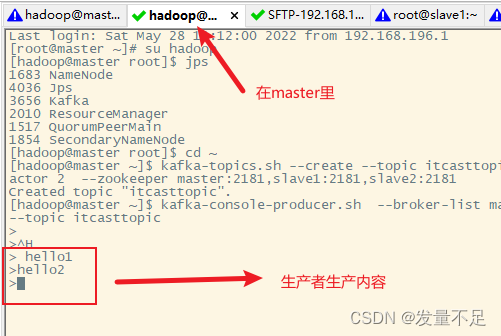
③、测试发送数据
生产发送数据
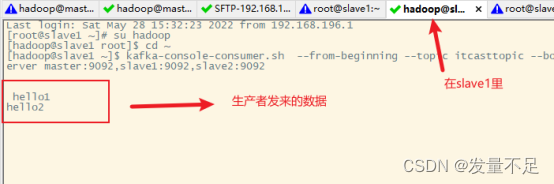
消费接收数据
三、基于Java API方式使用Kafka

修改配置:
①、创建工程添加依赖
在工程里面的pom.xml文件添加Kafka依赖
(Kafka依赖需要与虚拟机安装的Kafka版本保持一致)
<properties>
<scala.version>2.11.8</scala.version>
<hadoop.version>2.7.4</hadoop.version>
<spark.version>2.3.2</spark.version>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<!--kafka-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.0.0</version>
</dependency>
②、编写生产者客户端
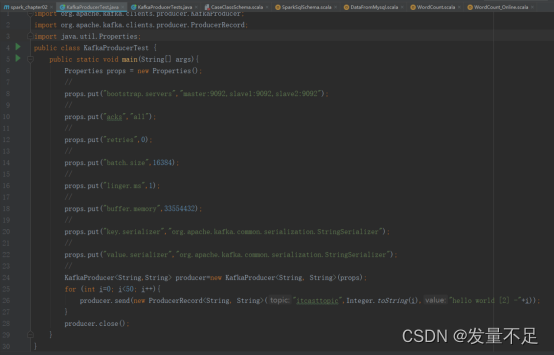
在工程的java目录下创建KafkaProducerTest文件
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class KafkaProducerTest {
public static void main(String[] args){
Properties props = new Properties();
//
props.put("bootstrap.servers","master:9092,slave1:9092,slave2:9092");
//
props.put("acks","all");
//
props.put("retries",0);
//
props.put("batch.size",16384);
//
props.put("linger.ms",1);
//
props.put("buffer.memory",33554432);
//
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
//
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
//
KafkaProducer<String,String> producer=new KafkaProducer<String, String>(props);
for (int i=0; i<50; i++){
producer.send(new ProducerRecord<String, String>("itcasttopic",Integer.toString(i),"hello world [2] -"+i));
}
producer.close();
}
}
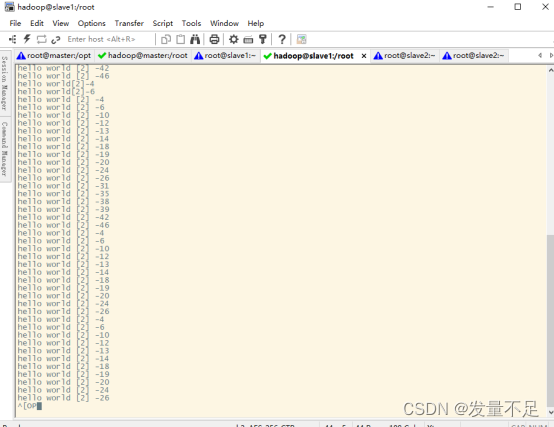
Slave1****上出现的结果
③ 、配置环境
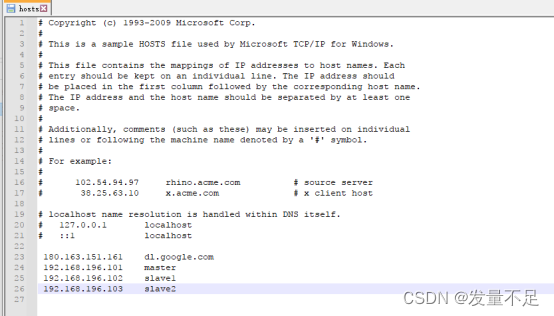
④、编写消费者客户端
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Arrays;
import java.util.Properties;
public class KafkaConsumerTest {
public static void main(String[] args) {
// 1、准备配置文件
Properties props = new Properties();
// 2、指定Kafka集群主机名和端口号
props.put("bootstrap.servers", "master:9092,slave1:9092,slave2:9092");
// 3、指定消费者组ID,在同一时刻同一消费组中只有一个线程可以去消费一个分区数据,不同的消费组可以去消费同一个分区的数据。
props.put("group.id", "itcasttopic");
// 4、自动提交偏移量
props.put("enable.auto.commit", "true");
// 5、自动提交时间间隔,每秒提交一次
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(props);
// 6、订阅数据,这里的topic可以是多个
kafkaConsumer.subscribe(Arrays.asList("itcasttopic"));
// 7、获取数据
while (true) {
//每隔100ms就拉去一次
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("topic = %s,offset = %d, key = %s, value = %s%n", record.topic(), record.offset(), record.key(), record.value());
}
}
}
}
运行KafkaP roducerTest程序
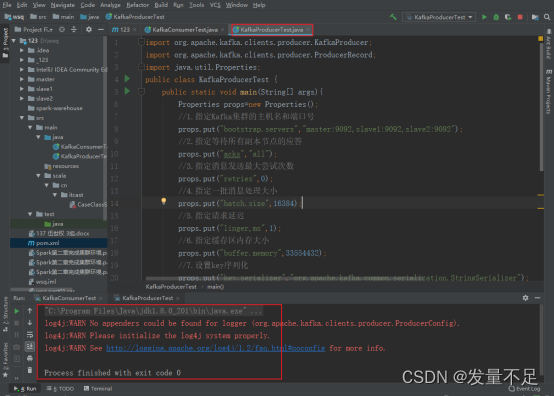
⑤、再运行KafkaConsumerTest******程序 ******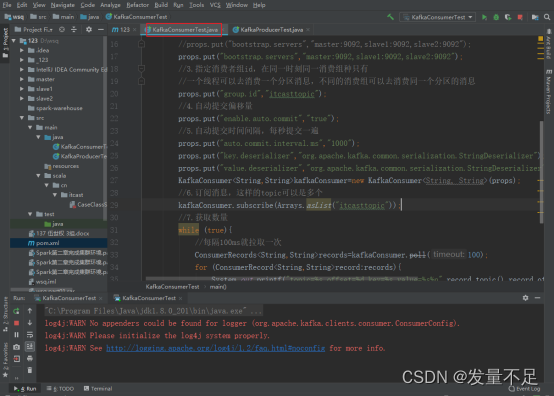
⑥、再回到KafkaProducerTest.java运行该程序****
(查看KafkaConsumerTest的运行框)由以下图可以看出生产者生产消息成功被终端消费
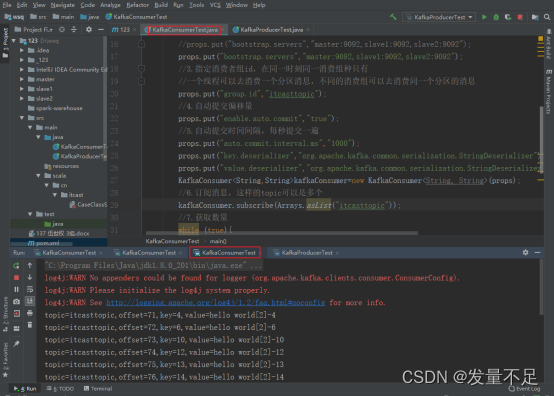
版权归原作者 发量不足 所有, 如有侵权,请联系我们删除。