
一、常用查询
(增、删、改、查)
对MySQL数据库的查询,除了基本的查询外,有时候需要对查询的结果集进行处理。例如只取几条数据、对查询结果进行排序或分组等等。
1.按关键字排序
类比于windows任务管理器
使用SELECT语句可以将需要的数据从MySQL数据库中查询出来,如果对查询的结果进行排序,可以使用ORDER BY语句来对语句实现排序,并最终将排序后的结果返回给用户。这个语句的排序不光可以针对某一个字段,也可以针对多个字段。
语法
select column1, column2, ... FROM table_name order by colunn1, column2, ...
ASC|DESC;
ASC是按照升序进行排序的,是默认的排序方式,即ASC可以省略。select语句中如果没有指定具体的排序方式,则默认按ASC方式进行排序。 DESC是按降序方式进行排列。当然order by前面也可以使用where子句对查询结果进一步过滤。
例:
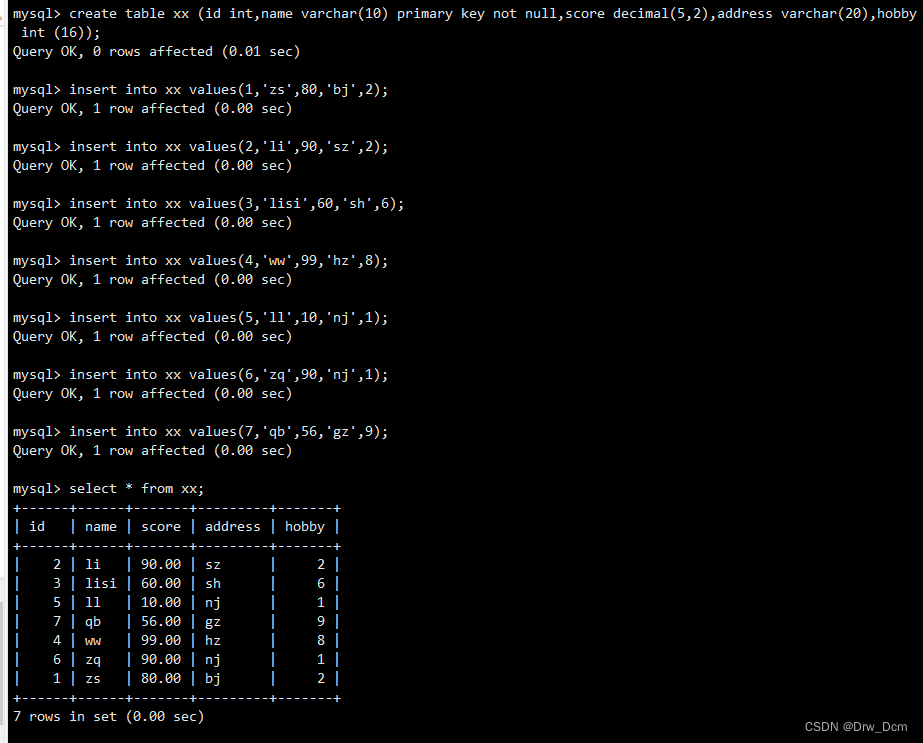
数据库有一张表,记录了id,姓名,分数,地址和爱好
create table 表名 (id int, name varchar(10) primary key not null,score decimal(5,2),address varchar (20), hobbid int(5));
insert into info values(1,'liuyi',80, 'beijing',2);
insert into info values (2,'wangwu',90,'shengzheng',2);
insert into info values(3,'lisi',60,'shanghai',4);
insert into info values(4,'tianqi',99,'hangzhou',5);
insert into info values(5,'j iaoshou',98,'laowo',3);
insert into info values (6,'hanmeimei',10,'nanjing,3);
insert into info values(7,'lilei',11,'nanjing',5);
select * from 表名;
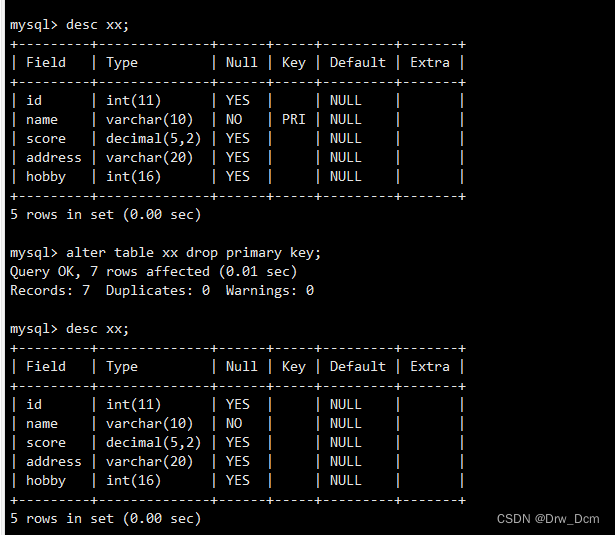
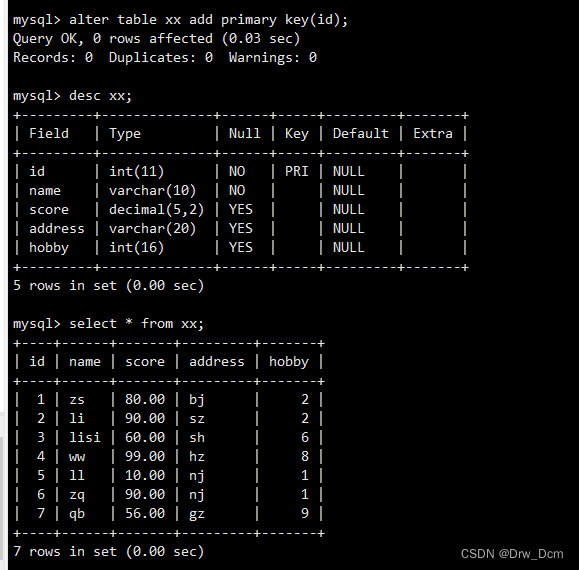
按分数排序,默认不指定是升序排列
select id, name, score from 表名 order by score;
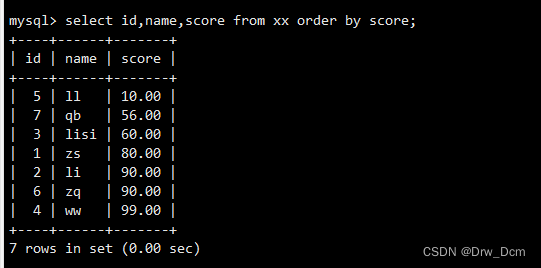
分数按降序排列
select id, name, score from 表名 order by score desc;
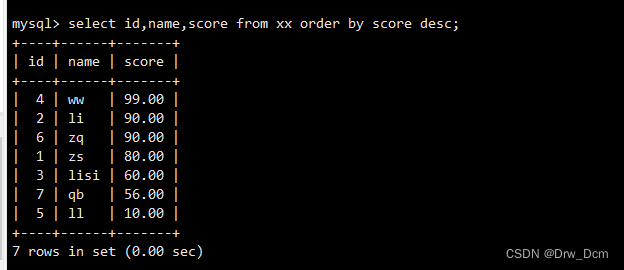
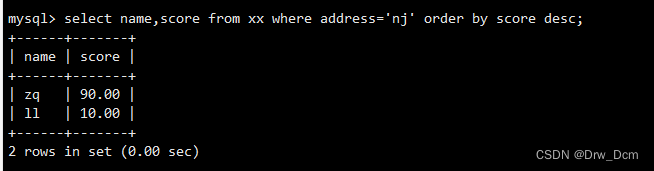
order by还可以结合where进行条件过滤,筛选某个地址的学生按分数降序排列
select name, score from 表名 where address-'address' order by score desc;
order by
语句也可以使用多个字段来进行排序,当排序的第--个字段相同的记录有多条的情况下,这些多条的记录再按照第二个字段进行排序,order by后面跟多个字段时,字段之间使用英文逗号隔开,优先级是按先后顺序而定。
但order by之后的第一个参数只有在出现相同值时,第二个字段才有意义
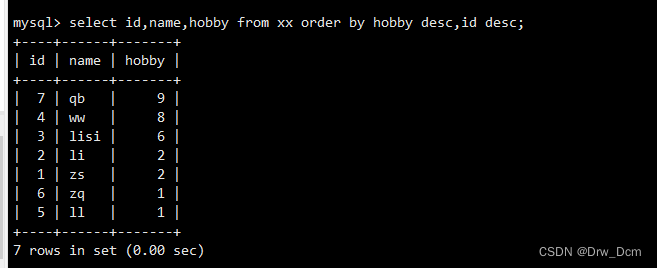
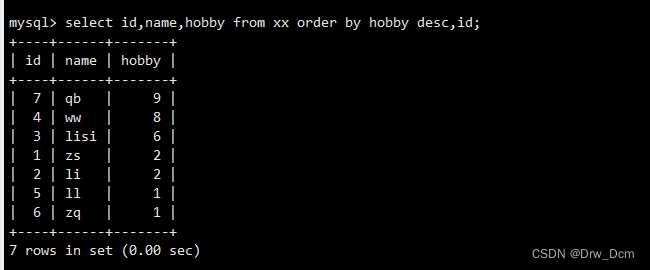
①查询学生信息先按兴趣id降序排列,相同分数的,id也按降序排列。select id, name, hobbid from 表名 order by hobbid desc, id desc;②查询学生信息先按兴趣id降序排列,相同分数的,id按升序排列
select id, name, hobbid from 表名 order by hobbid desc, id;
2.区间判断及查询不重复记录
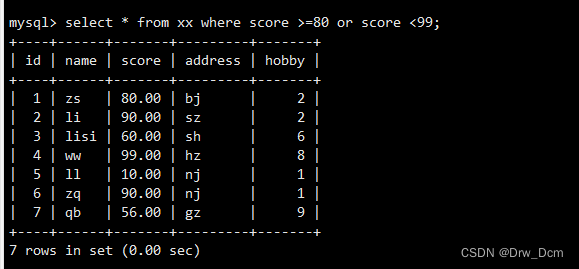
①and/or一且/或
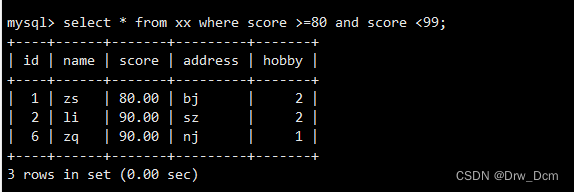
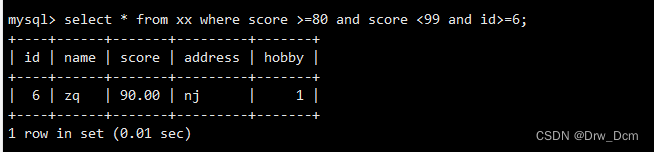
select * from 表名 where score >80 and score <=99; select * from 表名 where score >80 or score <=99;嵌套/多条件
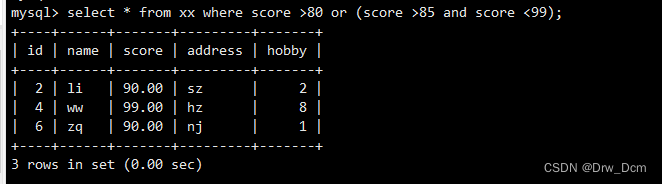
select * from 表名 where score >80 or (score >85 and score <99);添加:
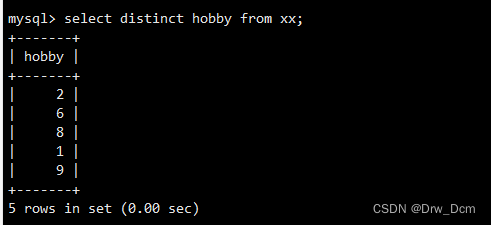
②distinct 查询不重复记录
语法:select distinct 字段 from 表名; select distinct hobbid from 表名;
3.对结果进行分组
通过SQL查询出来的结果,还可以对其进行分组,使用group by语句来实现,group by通常都是结合聚合函数一起使用的,常用的聚合函数包括:计数(COUNT)、求和(SUM)、求平均数(AVG) 、最大值(MAX) 、最小值(MIN),group by分组的时候可以按一个或多个字段对结果进行分组处理。
(1) 语法
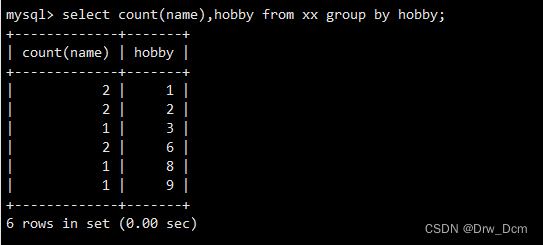
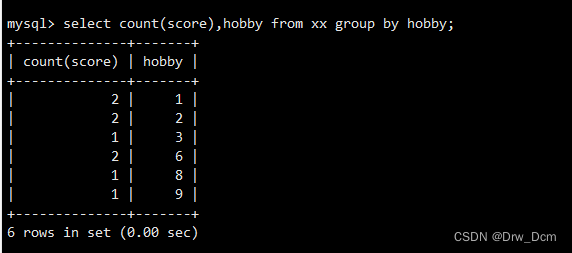
select column_name, aggregate_function (column_name) from table_name where column_name operator value group by column_name;按hobbid相同的 分组,计算相同分数的学生个数( 基于name个数进行计数)
select count (name),hobby from 表名 group by hobby;结合where语句, 筛选分数大于等于80的分组,计算学生个数
select count (name) ,hobby from 表名 where score>=80 group by hobby;结合order by 把计算出的学生个数按升序排列
select count (name) , score,hobby from 表名 where score>=80 group by hobby order by count (name) asc;
4.限制结果条目(limit)
limit限制输出的结果记录
在使用MySQLSELECT语句进行查询时,结果集返回的是所有匹配的记录(行)。有时候仅需要返回第一行或者前几行,这时候就需要用到limit子句。(1)语法
select column1, column2, ... from table_name limit [offset, ] numberlimit 的第一个参数是位置偏移量(可选参数),是设置MySQL从哪一行开始显示。
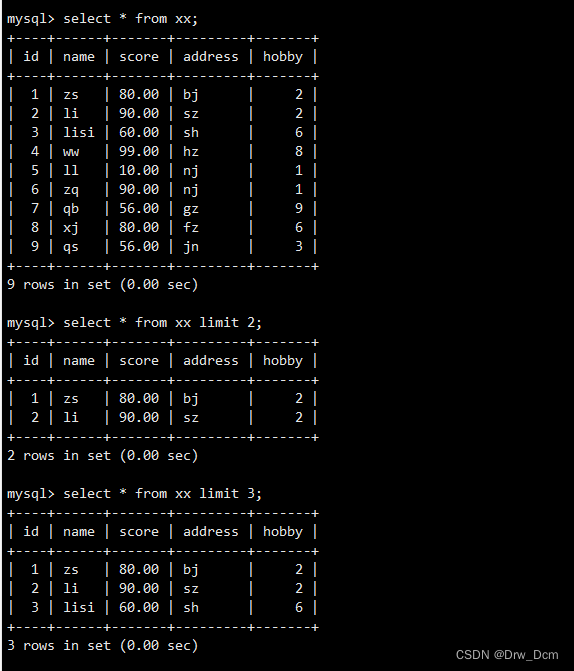
如果不设定第一个参数,将会从表中的第一条记录开始显示。需要注意的是,第一条记录的位置偏移量是0, 第二条是1,以此类推。第二个參数是设置返回记录行的最大数目。查询所有信息显示前4行记录
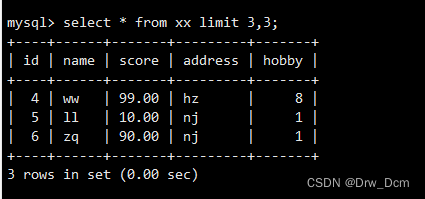
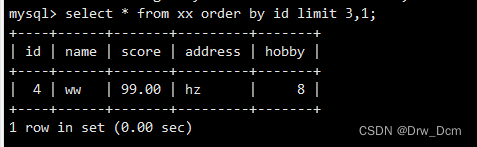
select * from 表名 limit 3;从第4行开始,往后显示3行内容
select * from 表名 limit 3,3;结合order by语句,按id的大小升序排列显示前三行
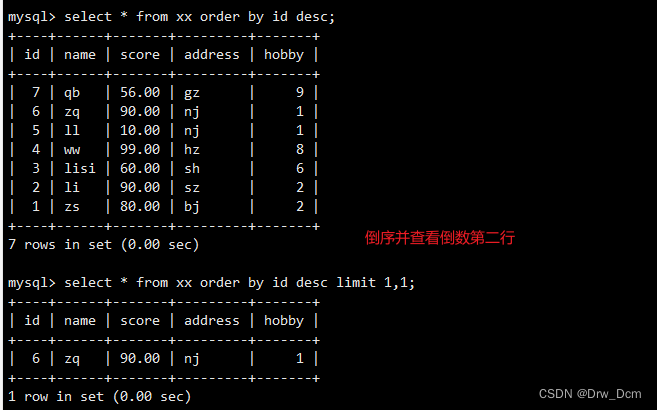
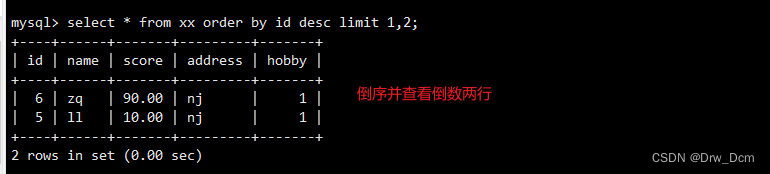
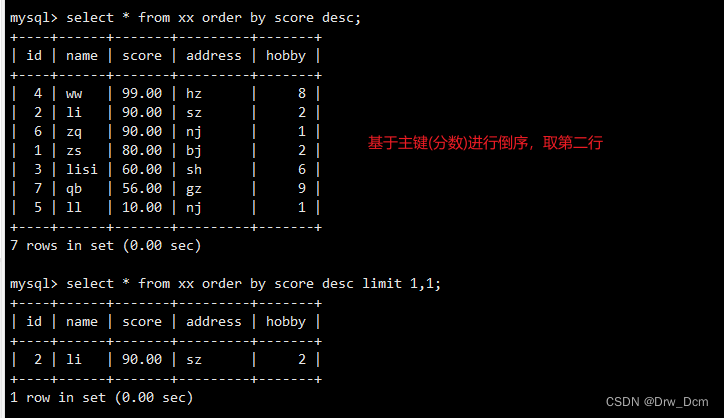
select id,name from 表名 order by id limit 3.输出最后三行
select id, name from 表名 order by id desc limit 3;select * from 表名 order by 主键字段 desc limit ;
5.设置别名(alias→as)
在MySQL查询时,当表的名字比较长或者表内某些字段比较长时,为了方便书写或者多次使用相同的表,可以给字段列或表设置别名。使用的时候直接使用别名,简洁明了,增强可读性。语法
对于列的别名select column_name as alias_name from table_name;对于表的别名
select column_name(s) from table_name as alias_name;在使用as后,可以用alias_name 代替table_name, 其中as语句是可选的。as之后的别名,主要是为表内的列或者表提供临时的名称,在查询过程中使用,库内实际的表名或字段名是不会被改变的。列别名设置示例:
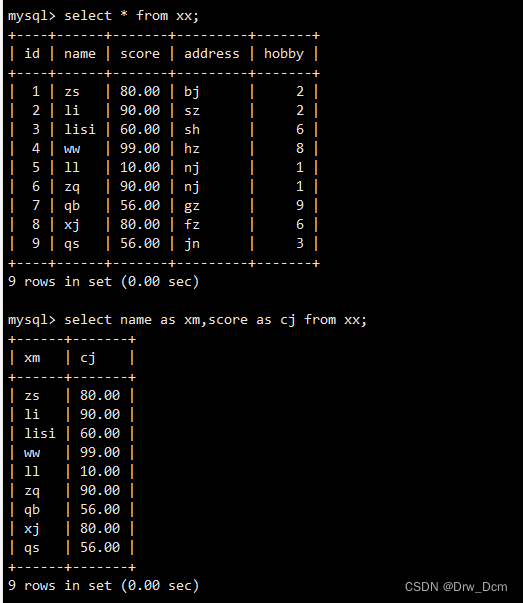
select name as 姓名,score as成绩 from info;如果表的长度比较长,可以使用as给表设置别名,在查询的过程中直接使用别名。
临时设置数据表的别名为i
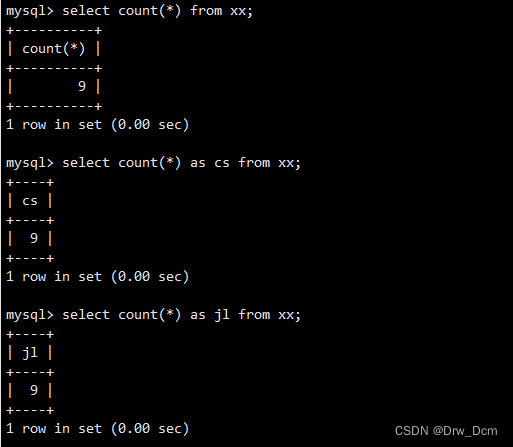
select name as 姓名,score as 成绩 from 表名 as i;查询数据表的字段数量,以number 显示
select count (*) as number from 表名;不用as也可以,一样显示
select count(*) number from 表名;使用场景:
(1)对复杂的表进行查询的时候,别名可以缩短查询语句的长度。
(2)多表相连查询的时候(通俗易懂、减短sql语句)此外,as还可以作为连接语句的操作符。
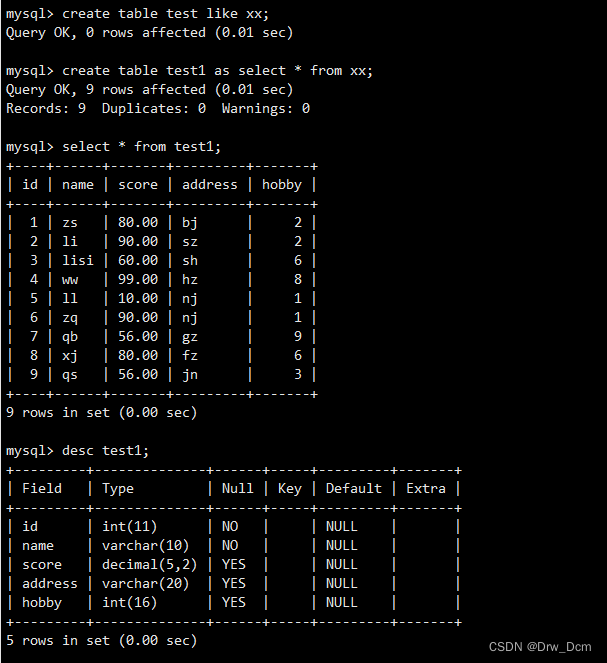
创建t1表,将数据表的查询记录全部插入t1表create table test1 like info; create table t1 as select * from 表名; select * from t1;此处as起到的作用:
(1)创建了一个新表t1并定义表结构,插入表数据(与info表相同)
(2)但是"约束“没有被完全”复制“过来#但是如果原表设置了主键,那么附表的: default字段会默认设置一个0
相似:
克隆、复制表结构create table t1 (select * from 表名) ;也可以加入where语句判断
create table test1 as select * from 表名 where score >=60;在为表设置别名时,要保证别名不能与数据库中的其他表的名称冲突。
列的别名是在结果中有显示的,而表的别名在结果中没有显示,只在执行查询时使用。
6.通配符
通配符主要用于替换字符串中的部分字符,通过部分字符的匹配将相关结果查询出来。
通常通配符都是跟like一起使用的,并协同WHERE 子句共同来完成查询任务。常用的通配符有两个,分别是:
%:百分号衣示零个、一个或多个字符。 * (通配符)
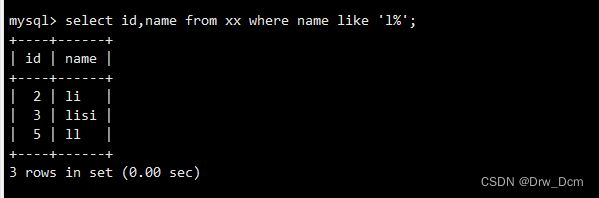
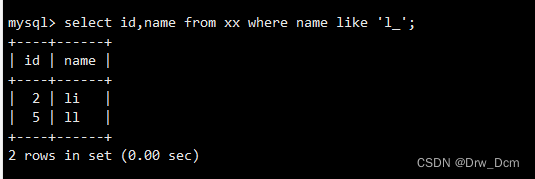
_ :下划线表示单个字符。 . (单个字符)查询名字是c开头的记录
select id, name from 表名 where name like 'c%' ;查询名字里是c和i中间有一个字符的记录
select id,name from 表名 where name like 'c_ic_i';查询名字中间有g的记录
select id, name from 表名 where name like '%g%' ;查询指定内容后面3个字符的名字记录
select id, name from 表名 where name like '指定内容__';通配符“%”和“ "不仅可以单独使用,也可以组合使用
查询名字以s开头的记录select id, name from 表名 where name like 's%_';
7.子查询
子查询也被称作内查询或者嵌套查询,是指在一个查询语句里面还嵌套着另一个查询语句。子查询语句是先于主查询语句被执行的,其结果作为外层的条件返回给主查询进行下一步的查询过滤。PS:子语句可以与主语句所查询的表相同,也可以是不同表。
相同表示例:
select name, score from 表名 where id in (select id from 表名 where score >80);以上主语句
select name,score from info where id子语句(集合):
select id from info where score >80;PS:子语句中的sq1语句是为了,最后过滤出-一个结果集,用于主语句的判断条件
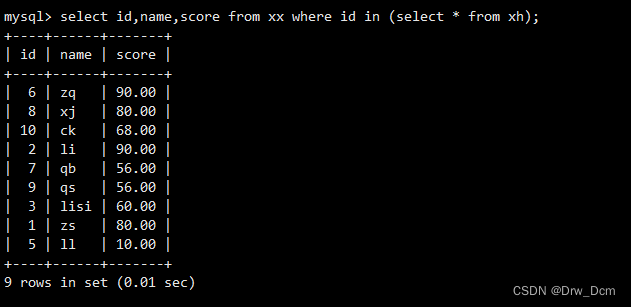
in: 将主表和子表关联/连接的语法不同表/多表示例:
create table 表名 (id int); insert into 表名 values(1),(2),(3);多表查询
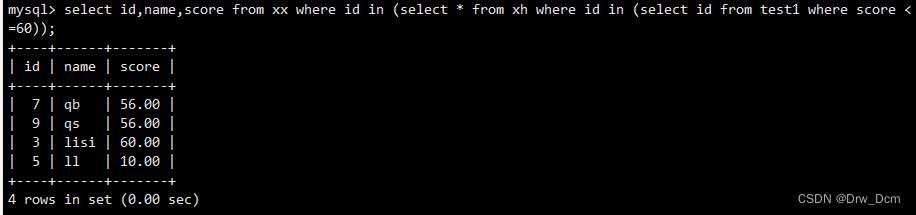
select id,name,score from 表名 where id in (select * from 表名);子查询不仅可以在select 语句中使用,在insert、update、delete中也同样适用。在嵌套的时候,子查询内部还可以再次嵌套新的子查询,也就是说可以多层嵌套。语法
in 用来判断某个值是否在给定的结果集中,通常结合子查询来使用语法:
<表达式> [not] in <子查询>
当表达式与 子查询返回的结果集中的某个值相等时,返回true,否则返回 false。若启用了not关键字,则返回值相反。需要注意的是,子查询只能返回一列数据,如果需求比较复杂,一列解决不了问题,可以使用多层嵌套的方式来应对。多数情况下,子查询都是与select语句一起使用的。查询分数大于80的记录
select name,score from 表名 where id in (select id from 表名 where score>80);子查询还可以用在insert语句中。子查询的结果集可以通过insert语句插入到其他的表中
将t1里的记录全部删除, 重新插入数据表的记录。insert into t1 select * from 表名 where id in (select id from 表名) ; select * from t1;update语句也可以使用子查询。update内的子查询,在set更新内容时,可以是单独的一列, 也可以是多列。
将分数改为50
update info set score=50 where id in (select * from 表名 where id=2); select * from info; update info set score=100 where id not in (select * from 表名 where id >1);表示先匹配出数据表内的id字段为基础匹配的结果集(2,3)
然后再执行主语句,以主语句的id为基础进行where 条件判断/过滤delete 也适用于子查询
删除分数大于80的记录
delete from 表名 where id in (select id where score>80); select id, name, score from t1;在in前面还可以添加not,其作用与in相反,表示否定(即不在子查询的结果集里面)
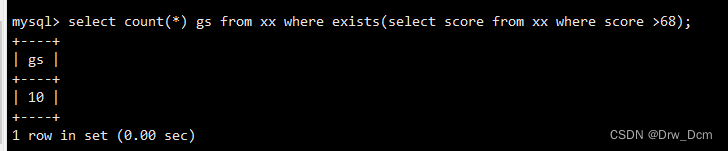
删除分数不是大于等于80的记录delete from t1 where id not in (select id where score>=80); select id,name,score from t1;exists 这个关键字在子查询时,主要用于判断子查询的结果集是否为空。如果不为空, 则返回true: 反之,则返回false。 查询如果存在分数等于80的记录则计算info的字段数select count(*) from 表名 where exists(select id from 表名 where score=80);人员信息统计,只有当所有人全部签到之后,在人员信息统计表录入完成侯,才需要进行统计)
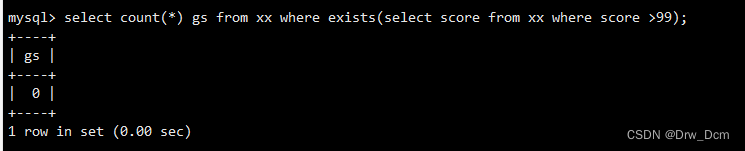
查询如果存在分数小于50的记录则计算info的字段数, info表没有小于50的,所以返回0select count(*) from 表名 where exists (select id from 表名 where score<50);子查询,别名as
查询数据表id, name字段select id, name from 表名;以上命令可以查看到数据表的内容
将结果集做为一张表进行查询的时候,也需要用到别名,示例:
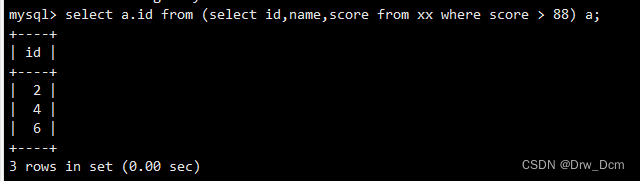
从数据表中的id和name字段的内容做为"内容"输出id的部分select id from (select id,name from 表名);此时会报错,原因为: .
select * from 表名此为标准格式,而以上的查询语句,"表名"的位置其实是一个完整结果集,mysql并不能直接识别,而此时给与结果集设置一个别名,以"select a.id from a“的方式查询将此结果集视为一 张"表", 就可以正常查询数据了,如下:
select a.id from (select id,name from 表名) a相当于
select info.id, name from 表名; select 表.字段,字段 from 表:


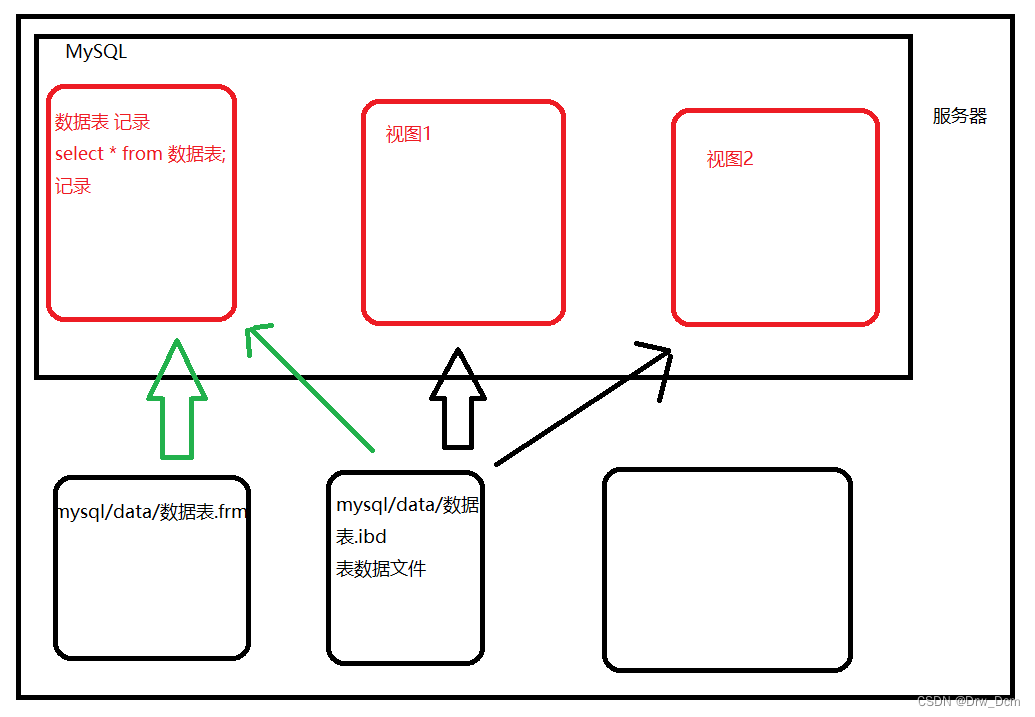
二、MySQL视图
视图:优化操作+安全方案
数据库中的虚拟表, 这张虚拟表中不包含真实数据,只是做了真实数据的映射。
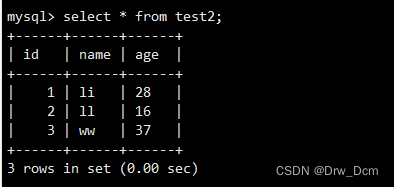
视图可以理解为镜花水月/倒影,动态保存结果集( 数据)。基础数据表
(记录)→映射(投影) --视图作用场景[图]
针对不同的人(权限身份),提供不同结果集的“表”(以表格的形式展示)。作用范围:
select * from info; 展示的部分是info表 select * from view_name; 展示的一张或多张表功能:
(1)简化查询结果集、灵活查询、可以针对不同用户呈现不同结果集、相对有更高的安全性
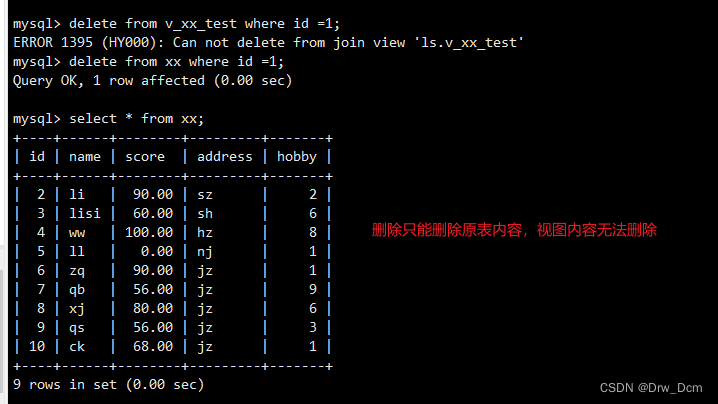
(2)本质而言视图是一种select(结果集的呈现)。PS:视图适合于多表连接浏览时使用!不适合增、删、改
而存储过程适合于使用较频繁的SQL语句,这样可以提高执行效率。视图和表的区别和联系
区别:
(1)视图是已经编译好的sql语句。而表不是。
(2)视图没有实际的物理记录。而表有。show table status\G(3)表只用物理空间而视图不占用物理空间,视图只是逻辑概念的存在,表可以及时对它进行修改,但视图只能有创建的语句来修改。
(4)视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全的角度说,视图可以不给用户接触数据表,从而不知道表结构。
(5)表属于全局模式中的表,是实表:视图属于局部模式的表,是虚表。
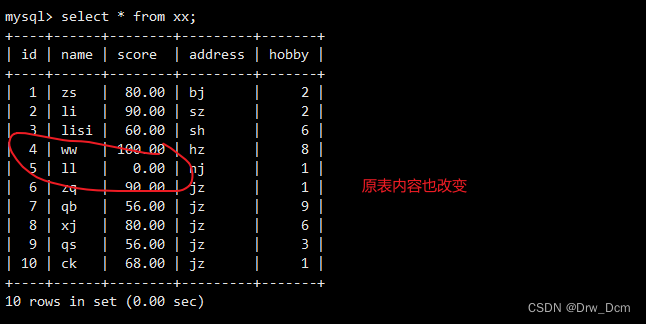
(6)视图的建立和删除只影响视图本身,会影响对应的基本表。(但是更新视图数据,是会影响到基本表的)。联系:
(1)视图(view)是在基本表之上建立的表,它的结构(即所定义的列)和内容(即所有数据行)都来自基本表,它依据基本表存在而存在。一个视图可以对应一个基本表,也可以对应多个基本表。视图是基本表的抽象和在逻辑意义上建立的新关系。示例:
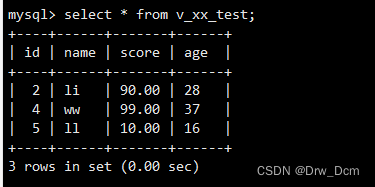
满足80分的展示在视图中。
PS:这个结果会动态变化,同时可以给不同的人群(例如权限范围)展示不同的视图。创建视图(单表)
create view v_score as select * from 表名 where score>=80;查看表状态
show table status\G查看视图
select * from v_score;查看视图与源表结构
desc v_score; desc info;多表创建视图
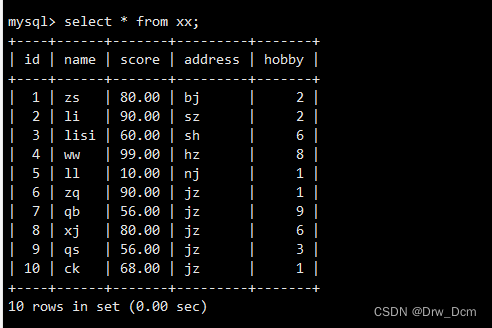
创建test01表
create table test01 (id int, name varchar(10) ,age char(10)) ; insert into test01 values(1, ' zhangsan',20) ; insert into test01 values(2, 'lisi',30) ; insert into test01 values (3, 'wangwu',29) ;创建一个 视图,需要输出id、姓名、分数以及年龄
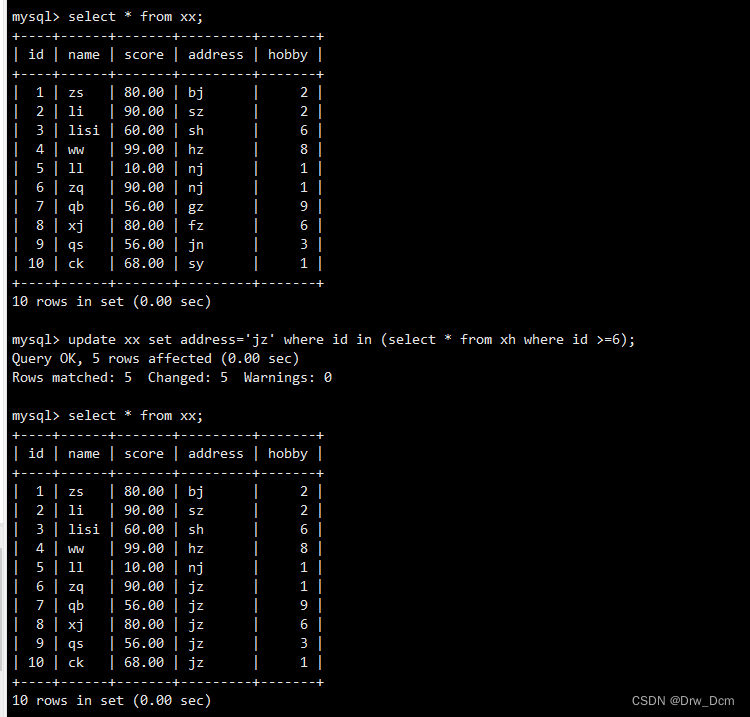
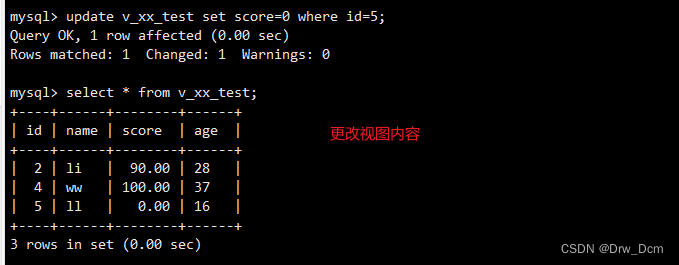
create view v_表名(id, name, score,age) as select 表名.id, 表名.name, 表名.score, test01.age from 表名, test01 where 表名.name-test01.name; select * from v_info;修改原表数据
update 表名 set score='60' where name='liuyi';查看视图
select * from v_score; select * from 表名;修改表不能修改以函数、复合函数方式计算出来的字段
查询方便、安全性
查询方便:索引速度快、同时可以多表查询更为迅速(视图不保存真实数据,视图本质类似select)。
安全性:我们实现登陆的账户是root→所拥有权限,视图无法显示完整的约束。NULL值
在SQL语句使用过程中,经常会碰到NULL这几个字符。通常使用NULL来表示缺失的值,也就是在表巾该字段是没有值的。如果在创建表时,限制某些字段不为空,则可以使用NOT NULL。
关键字不使用则默认可以为空。在向表内插入记录或者更新记录时,如果该字段没有NOT NULL 并且没有值,这时候新记录的该字段将被保存为NULL。 需要注意的是,NULL 值与数字0或者空白(spaces) 的字段是不同的,值为NULL的字段是没有值的。在SQL语句中,使用IS NULL 可以判断表内的某个字段是不是NULL 值,相反的用 IS NOT NULL 可以判断不是 NULL值。查询数据表结构,name字段是不允许空值的。
null值与空值的区别(空气与真空)。
空值长度为0,不占空间,NULL值的长度为null,占用空间。
is null无法判断空值。
空值使用"=“或者"<>"来处理(! =)。count ()计算时,NULL会忽略,空值会加入计算。
desc 表名;
插入一条记录,分数字段输入null,显示出来就是null。验 证:
alter table 表名 add column addr varchar(50); update info set addr-'nj' where score >=70;统计数量:检测null是否会加入统计中。
update info set addr='nj' where score >=70;统计数量:检测null是否会加入统计中。
select count (addr) from info;将info表中其中一条数据修改为空值''
update info set addr=''where name-'wangwu';统计数量,检测空值是不会被添加到统计中
select count (addr) from info;查询null值
select * from 表名 where addr is NULL;查询不为空的值
select * from 表名 where addr is not null;
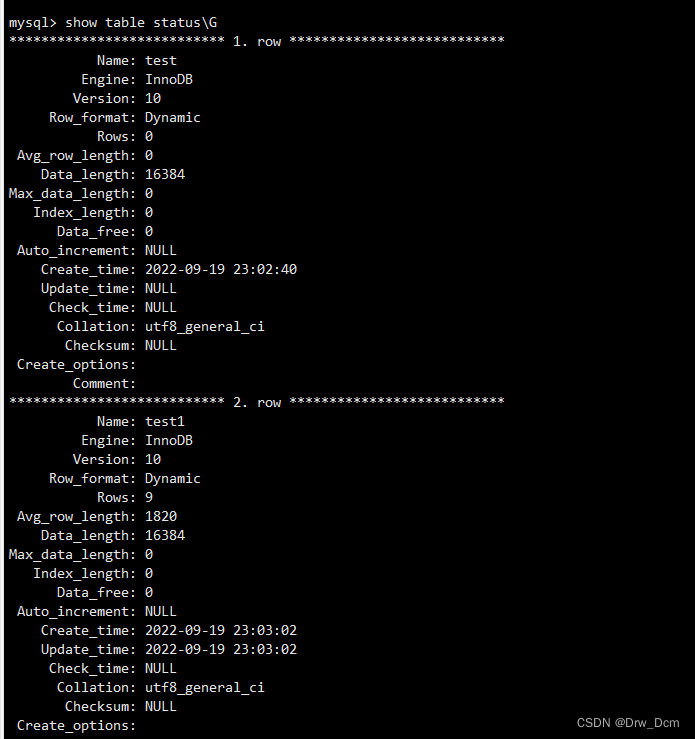
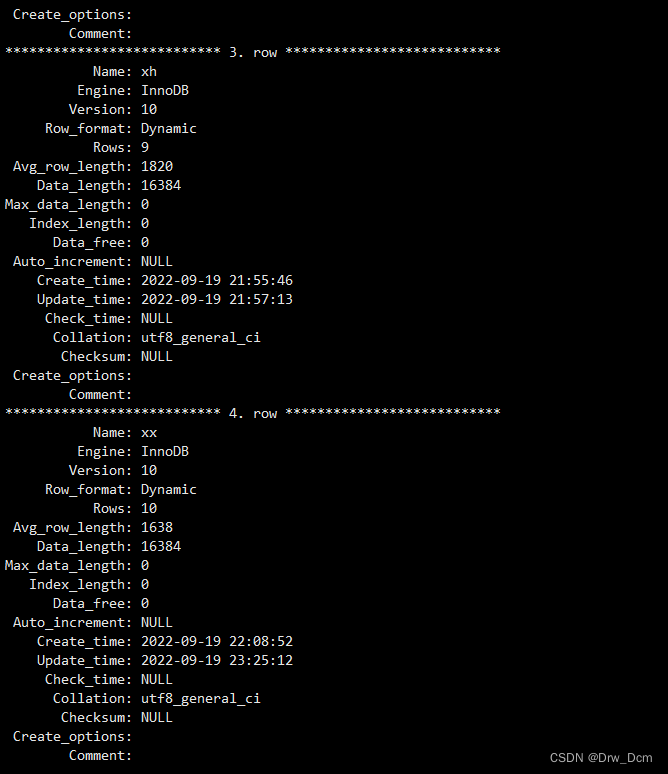
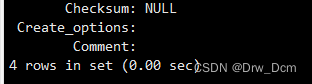
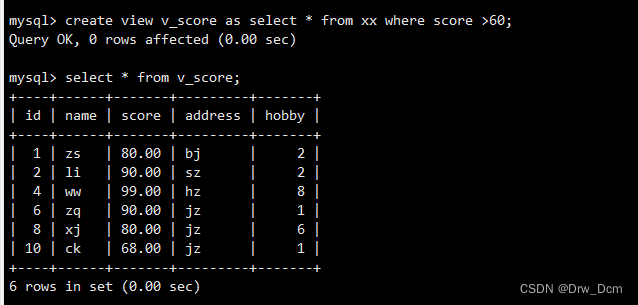

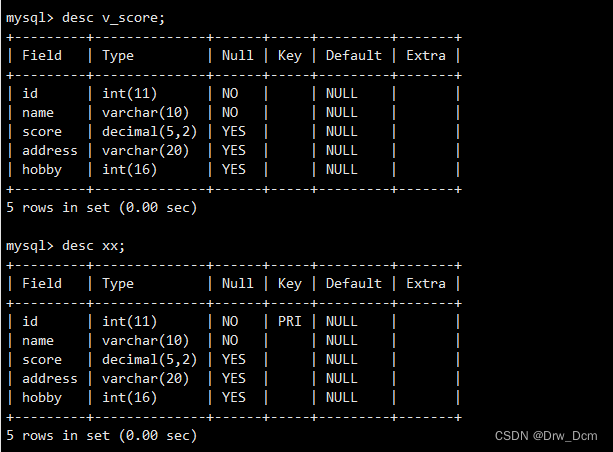

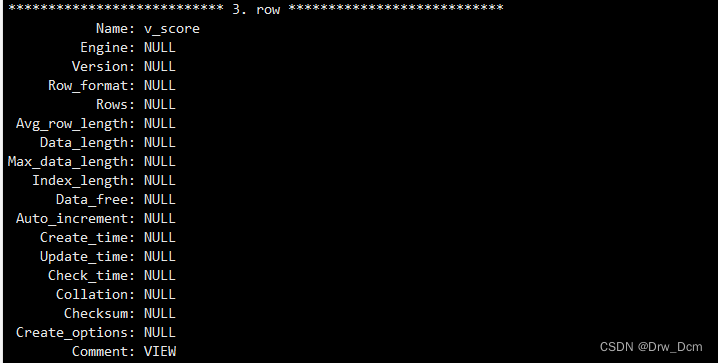

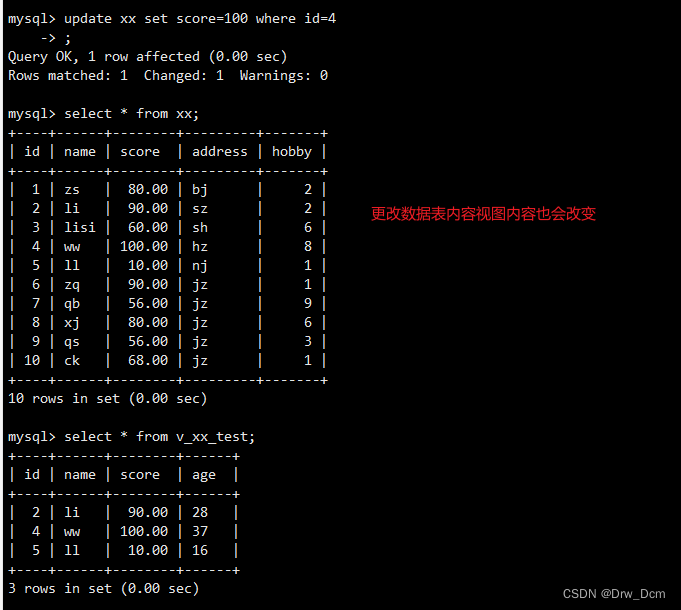
视图没有数据,存储引擎,只是一种映射
版权归原作者 Drw_Dcm 所有, 如有侵权,请联系我们删除。