
文章目录
前言
Apache Flink是一个框架和分布式处理引擎,用于对无边界和有边界的数据流进行有状态的计算。Flink被设计为可以在所有常见集群环境中运行,并能以内存速度和任意规模执行计算。目前市场上主流的流式计算框架有Apache Storm、Spark Streaming、Apache Flink等,但能够同时支持低延迟、高吞吐、Exactly-Once(收到的消息仅处理一次)的框架只有Apache Flink。
Flink是原生的流处理系统,但也提供了批处理API,拥有基于流式计算引擎处理批量数据的计算能力,真正实现了批流统一。与Spark批处理不同的是,Flink把批处理当作流处理中的一种特殊情况。在Flink中,所有的数据都看作流,是一种很好的抽象,因为这更接近于现实世界。
一、部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink为各种场景提供了不同的部署模式,主要有以下三种:会话模式(Session Mode)、单作业模式(Per-Job Mode)、应用模式(Application Mode)。
它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的main方法到底在哪里执行——客户端(Client)还是JobManager。
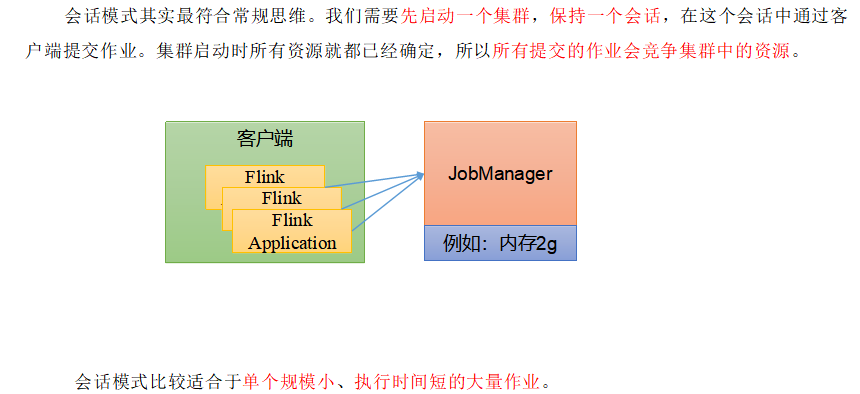
1.会话模式(Session Mode)
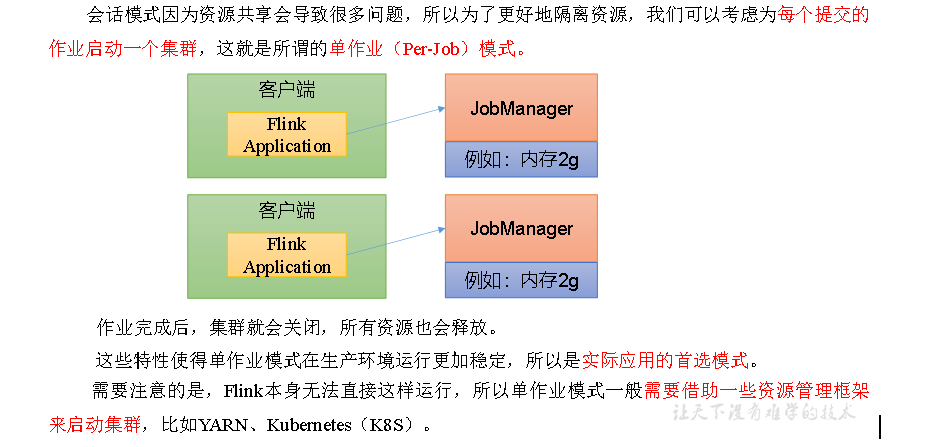
2.单作业模式(Per-Job Mode)
3.应用模式(Application Mode)

应用模式后续会替代单作业模式
二、运行模式
1.Standalone运行模式
独立模式是独立运行的,不依赖任何外部的资源管理平台;当然独立也是有代价的:如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理。所以独立模式一般只用在开发测试或作业非常少的场景下。
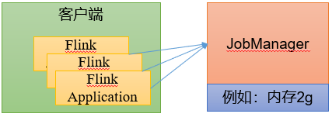
1.1 会话模式部署(本文采用此方式部署)
提前启动集群,并通过Web页面客户端提交任务(可以多个任务,但是集群资源固定)。
1.2 单作业模式部署
Flink的Standalone集群并不支持单作业模式部署。因为单作业模式需要借助一些资源管理平台。
1.3 应用模式部署
应用模式下不会提前创建集群,所以不能调用start-cluster.sh脚本。我们可以使用同样在bin目录下的standalone-job.sh来创建一个JobManager。
2.YARN运行模式
YARN上部署的过程是:客户端把Flink应用提交给Yarn的ResourceManager,Yarn的ResourceManager会向Yarn的NodeManager申请容器。在这些容器上,Flink会部署JobManager和TaskManager的实例,从而启动集群。Flink会根据运行在JobManger上的作业所需要的Slot数量动态分配TaskManager资源。
2.1 会话模式部署
YARN的会话模式与独立集群略有不同,需要首先申请一个YARN会话(YARN Session)来启动Flink集群。(yarn-session.sh)
2.2 单作业模式部署
在YARN环境中,由于有了外部平台做资源调度,所以我们也可以直接向YARN提交一个单独的作业,从而启动一个Flink集群
2.3 应用模式部署
应用模式同样非常简单,与单作业模式类似,直接执行flink run-application命令即可
3.K8S 运行模式
容器化部署是如今业界流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(k8s),而Flink也在最近的版本中支持了k8s部署模式。基本原理与YARN是类似的,具体配置可以参见官网说明,这里我们就不做过多讲解了
三、安装部署flink
1.下载flink
https://www.apache.org/dyn/closer.lua/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgz
2.配置flink
配置环境变量
vim /etc/profile
exportFLINK_HOME=/opt/flink-1.17.1
exportPATH=$FLINK_HOME/bin:$PATHsource /etc/profile
#修改配置文件vim conf/flink-conf.yaml
新增或修改如下配置
taskmanager.numberOfTaskSlots: 8#远程访问需要设置成0.0.0.0
rest.bind-address: 0.0.0.0
#自定义IP可设置
rest.port: 31992
state.savepoints.dir: file:///opt/flink/savepoints
#解决oracle驱动无法加载问题
classloader.resolve-order: parent-first
3.启动flink(采用Standalone session模式)
#启动
./bin/start-cluster.sh
web页面地址 :http://localhost:8081/
4.运行job
4.1命令行
运行jar
./bin/flink run -d-c com.cdc.demo.TestOracle_Doris_API_Single_JdbcIncrementalSource lib/flink-demo-1.0-SNAPSHOT.jar
取消任务并保存savepoint
flink cancel -s jobid
以savepoint启动
./bin/flink run -d-c com.cdc.demo.TestOracle_Doris_API_Single_JdbcIncrementalSource -s file:///opt/flink-1.17.1/savepoints/savepoint-aa8205-b86f87af185e lib/flink-demo-1.0-SNAPSHOT.jar
结尾
- 感谢大家的耐心阅读,如有建议请私信或评论留言。
- 如有收获,劳烦支持,关注、点赞、评论、收藏均可,博主会经常更新,与大家共同进步
版权归原作者 Xd聊架构 所有, 如有侵权,请联系我们删除。