
Flink(八)CEP
1.概述
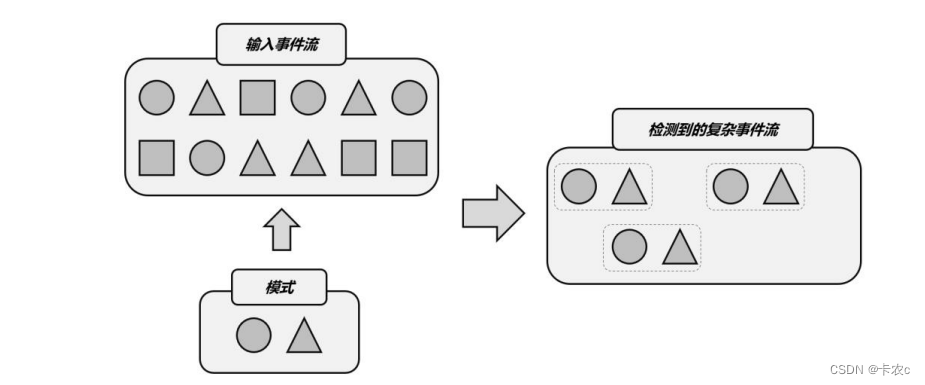
所谓 CEP,其实就是“复杂事件处理(Complex Event Processing)”的缩写;而 Flink CEP,就是 Flink 实现的一个用于复杂事件处理的库(library)。那到底什么是“复杂事件处理”呢?就是可以在事件流里,检测到特定的事件组合并进行处理,比如说“连续登录失败”,或者“订单支付超时”等等
具体的处理过程是,把事件流中的一个个简单事件,通过一定的规则匹配组合起来,这就是“复杂事件”;然后基于这些满足规则的一组组复杂事件进行转换处理,得到想要的结果进行输出
总结起来,复杂事件处理(CEP)的流程可以分成三个步骤:
(1)定义一个匹配规则,匹配规则就是
模式,主要由两部分组成,每个简单事件的特征 和 简单事件之间的组合关系
(2)将匹配规则应用到事件流上,检测满足规则的复杂事件
(3)对检测到的复杂事件进行处理,得到结果进行输出
CEP 主要用于实时流数据的分析处理。CEP 可以帮助在复杂的、看似不相关的事件流中找出那些有意义的事件组合,进而可以接近实时地进行分析判断、输出通知信息或报警。这在企业项目的风控管理、用户画像和运维监控中,都有非常重要的应用
- 风险控制 当一个用户行为符合了异常行为模式,比如短时间内频繁登录并失败、大量下单却不支付(刷单),就可以向用户发送通知信息,或是进行报警提示、由人工进一步判定用户是否有违规操作的嫌疑。这样就可以有效地控制用户个人和平台的风险
- 用户画像 利用 CEP 可以用预先定义好的规则,对用户的行为轨迹进行实时跟踪,从而检测出具有特定行为习惯的一些用户,做出相应的用户画像。基于用户画像可以进行精准营销,即对行为匹配预定义规则的用户实时发送相应的营销推广;这与目前很多企业所做的精准推荐原理是一样的
- 运维监控 对于企业服务的运维管理,可以利用 CEP 灵活配置多指标、多依赖来实现更复杂的监控模式 CEP 的应用场景非常丰富。很多大数据框架,如 Spark、Samza、Beam 等都提供了不同的CEP 解决方案,但没有专门的库(library)。而 Flink 提供了专门的 CEP 库用于复杂事件处理,可以说是目前 CEP 的最佳解决方案
2.快速入门
需要引入的依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-cep_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency>
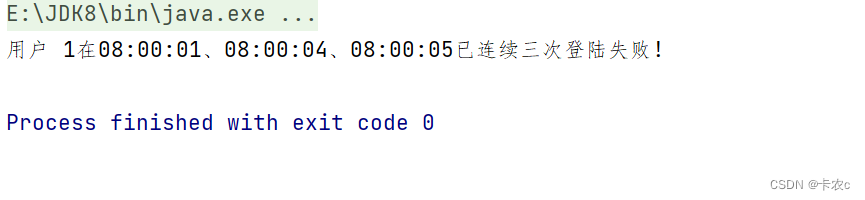
接下来我们考虑一个具体的需求:检测用户行为,如果连续三次登录失败,就输出报警信息。很显然,这是一个复杂事件的检测处理,我们可以使用 Flink CEP 来实现。我们首先定义数据的类型。这里的用户行为不再是之前的访问事件 Event 了,所以应该单独定义一个登录事件 POJO 类。具体实现如下:
publicclassLoginEvent{// 用户idpublicString userId;// 用户ip地址publicString ipAddress;// 用户登录成功与否publicBoolean eventType;// 登录时间戳publicLong timestamp;publicLoginEvent(){}// 省略toString 有参构造}
publicclassLoginDetectExample{publicstaticvoidmain(String[] args)throwsException{// 创建一个表执行环境StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tableEnv =StreamTableEnvironment.create(env);
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100);// 100毫秒生成一次水位线// 1.用户登录事件SingleOutputStreamOperator<LoginEvent> streamOperator = env.fromElements(newLoginEvent("1","192.168.10.1",false,1000L),newLoginEvent("2","192.168.10.6",true,2000L),newLoginEvent("1","192.168.10.1",false,5000L),newLoginEvent("2","192.168.10.6",false,5000L),newLoginEvent("1","192.168.10.1",false,4000L)).assignTimestampsAndWatermarks(WatermarkStrategy.<LoginEvent>forBoundedOutOfOrderness(Duration.ofSeconds(2))// 延迟2秒保证数据正确.withTimestampAssigner(newSerializableTimestampAssigner<LoginEvent>(){@Override// 时间戳的提取器publiclongextractTimestamp(LoginEvent event,long l){return event.timestamp;}}));// 2.定义模式// 2.1 模式的第一个事件是用户登陆失败Pattern<LoginEvent,LoginEvent> loginEventPattern =Pattern.<LoginEvent>begin("first-false").where(newSimpleCondition<LoginEvent>(){@Overridepublicbooleanfilter(LoginEvent loginEvent)throwsException{return!loginEvent.eventType;// 类型为false的则代表登陆失败}})// next衔接模式的第二个事件.next("second-false").where(newSimpleCondition<LoginEvent>(){@Overridepublicbooleanfilter(LoginEvent loginEvent)throwsException{return!loginEvent.eventType;}})// 以后的每个事件都用next衔接即可.next("third-false").where(newSimpleCondition<LoginEvent>(){@Overridepublicbooleanfilter(LoginEvent loginEvent)throwsException{return!loginEvent.eventType;}});// 3.将模式应用到数据流,检测复杂事件PatternStream<LoginEvent> patternStream = CEP.pattern(streamOperator.keyBy(event -> event.userId), loginEventPattern);// 4.提取复杂事件,进行处理 select类似于map 只不过我们处理的是一组事件SingleOutputStreamOperator<String> warningOut = patternStream.select(newPatternSelectFunction<LoginEvent,String>(){@Override// 这里是一个map map的key就是我们定义的事件名称,value对应的事件列表,我们这里列表里只有一个事件,为什么是列表,因为我们定义的一个事件,它可能会重复发生publicStringselect(Map<String,List<LoginEvent>> map)throwsException{// 提取三次事件LoginEvent firstFailEvent = map.get("first-false").get(0);LoginEvent secondFailEvent = map.get("second-false").get(0);LoginEvent thirdFailEvent = map.get("third-false").get(0);return"用户 "+ firstFailEvent.userId +"在"+newTime(firstFailEvent.timestamp)+"、"+newTime(secondFailEvent.timestamp)+"、"+newTime(thirdFailEvent.timestamp)+"已连续三次登陆失败!";}});// 5.打印输出
warningOut.print();
env.execute();}}
3.模式API
3.1 个体模式
模式(Pattern)其实就是将一组简单事件组合成复杂事件的“匹配规则”。由于流中事件的匹配是有先后顺序的,因此一个匹配规则就可以表达成先后发生的一个个简单事件,按顺序串联组合在一起
这里的每一个简单事件并不是任意选取的,也需要有一定的条件规则;
所以我们就把每个简单事件的匹配规则,叫作“个体模式”(Individual Pattern),例如上面的例子,需要匹配三次连续失败的用户,实际上就是三个个体模式
量词
个体模式后面可以跟一个“量词”,用来指定循环的次数,在上面例子中,可以在begin或者next之后接量词,注意量词的使用位置
为了更好的理解量词的含义,我们这里假设输入的4个事件为 a a a b
在 Flink CEP 中,可以使用不同的方法指定循环模式,主要有:
- .oneOrMore()
匹配事件出现一次或多次,假设 a 是一个个体模式,a.oneOrMore()表示可以匹配 1 个或多个 a 的事件组合,匹配结果有三个 [a,a,a]、[a,a]、[a],
也是说oneOrMore会以每一个匹配的事件为开头,返回最大的匹配项
,第一个a,它可以匹配三个a,结束,轮到第二个a,它可以匹配两个a(第二个a本身和第三个a),结束,轮到最后一个a,只有它自己了,结束
- .times(times)
匹配事件发生特定次数(times),例如 a.times(3)表示 aaa
- .times(fromTimes,toTimes)
指定匹配事件出现的次数范围,最小次数为fromTimes,最大次数为toTimes。例如a.times(2, 3)可以匹配 aa,aaa
- .greedy()
只能用在循环模式后
,使当前循环模式变得“贪心”(greedy),也就是总是尽可能多地去匹配。例如 a.times(2, 4).greedy(),如果出现了连续 4 个 a,那么会直接把 aaaa 检测出来进行处理,其他任意 2 个 a 是不算匹配事件的
- .optional()
使当前模式成为可选的,也就是说可以满足这个匹配条件,也可以不满足。对于一个个体模式 pattern 来说,后面所有可以添加的量词如下:
// 匹配事件出现 4 次
pattern.times(4);// 匹配事件出现 4 次,或者不出现
pattern.times(4).optional();// 匹配事件出现 2, 3 或者 4 次
pattern.times(2,4);// 匹配事件出现 2, 3 或者 4 次,并且尽可能多地匹配,有4次匹配4次
pattern.times(2,4).greedy();// 匹配事件出现 2, 3, 4 次,或者不出现
pattern.times(2,4).optional();// 匹配事件出现 2, 3, 4 次,或者不出现;并且尽可能多地匹配
pattern.times(2,4).optional().greedy();// 匹配事件出现 1 次或多次
pattern.oneOrMore();// 匹配事件出现 1 次或多次,并且尽可能多地匹配
pattern.oneOrMore().greedy();// 匹配事件出现 1 次或多次,或者不出现
pattern.oneOrMore().optional();// 匹配事件出现 1 次或多次,或者不出现;并且尽可能多地匹配
pattern.oneOrMore().optional().greedy();// 匹配事件出现 2 次或多次
pattern.timesOrMore(2);// 匹配事件出现 2 次或多次,并且尽可能多地匹配
pattern.timesOrMore(2).greedy();// 匹配事件出现 2 次或多次,或者不出现
pattern.timesOrMore(2).optional()// 匹配事件出现 2 次或多次,或者不出现;并且尽可能多地匹配
pattern.timesOrMore(2).optional().greedy();
正是因为个体模式可以通过量词定义为循环模式,一个模式能够匹配到多个事件,所以之前代码中事件的检测接收才会用 Map 中的一个列表(List)来保存。而之前代码中没有定义量词,都是单例模式,所以只会匹配一个事件,每个 List 中也只有一个元素:
LoginEvent first = map.get("first").get(0);
条件 where
对于每个个体模式,匹配事件的核心在于定义匹配条件,也就是选取事件的规则。FlinkCEP 会按照这个规则对流中的事件进行筛选,判断是否接受当前的事件
- 限定子类型
调用.subtype()方法可以为当前模式增加子类型限制条件。例如:
pattern.subtype(SubEvent.class);
这里 SubEvent 是流中数据类型 Event 的子类型。这时,只有当事件是 SubEvent 类型时,才可以满足当前模式 pattern 的匹配条件
- 简单条件(Simple Conditions)
简单条件是最简单的匹配规则,只根据当前事件的特征来决定是否接受它。这在本质上其实就是一个 filter 操作
代码中我们为.where()方法传入一个
SimpleCondition 的实例作为参数
。SimpleCondition 是表示“简单条件”的抽象类,内部有一个.filter()方法,唯一的参数就是当前事件。所以它可以当作 FilterFunction 来使用
- 迭代条件(Iterative Conditions)
在 Flink CEP 中,提供了
IterativeCondition 抽象类
。这其实是更加通用的条件表达,查看源码可以发现, .where()方法本身要求的参数类型就是 IterativeCondition;而之前 的SimpleCondition 是它的一个子类
在 IterativeCondition 中同样需要实现一个 filter()方法,不过与 SimpleCondition 中不同的是,这个方法有两个参数:除了当前事件之外,还有一个上下文 Context。调用这个上下文的.getEventsForPattern()方法,传入一个模式名称,
就可以拿到这个模式中已匹配到的所有数据了
@PublicEvolvingpublicabstractclassIterativeCondition<T>implementsFunction,Serializable{privatestaticfinallong serialVersionUID =7067817235759351255L;publicIterativeCondition(){}publicabstractbooleanfilter(T var1,Context<T> var2)throwsException;publicinterfaceContext<T>extendsTimeContext{Iterable<T>getEventsForPattern(String var1)throwsException;}}
下面是一个具体示例:
Pattern<LoginEvent,LoginEvent> loginEventPattern =Pattern.<LoginEvent>begin("first-false").where(newSimpleCondition<LoginEvent>(){@Overridepublicbooleanfilter(LoginEvent loginEvent)throwsException{return!loginEvent.eventType;// 类型为false的则代表登陆失败}})// next衔接模式的第二个事件.next("second-false").where(newSimpleCondition<LoginEvent>(){@Overridepublicbooleanfilter(LoginEvent loginEvent)throwsException{return!loginEvent.eventType;}})// 以后的每个事件都用next衔接即可.next("third-false").where(newIterativeCondition<LoginEvent>(){@Overridepublicbooleanfilter(LoginEvent loginEvent,Context<LoginEvent> context)throwsException{Iterable<LoginEvent> eventsForPattern = context.getEventsForPattern("second-false");System.out.println(newTime(eventsForPattern.iterator().next().timestamp));return!loginEvent.eventType;}});
上面代码中,在第三个模式中,我们传入的是一个迭代条件,它调用了getEventsForPattern(“second-false”),于是获取了第二个模式中已经捕获的数据

- 组合条件(Combining Conditions)
独立定义多个条件,然后在外部把它们连接起来,构成一个“组合条件”(Combining Condition)
最简单的组合条件,就是.where()后面再接一个.where()。因为前面提到过,一个条件就像是一个 filter 操作,所以每次调用.where()方法都相当于做了一次过滤,连续多次调用就表示多重过滤,最终匹配的事件自然就会同时满足所有条件。这相当于就是多个条件的
“逻辑与”(AND)
而多个条件的
逻辑或(OR
),则可以通过.where()后加一个.or()来实现。这里的.or()方法与.where()一样,传入一个 IterativeCondition 作为参数,定义一个独立的条件;它和之前.where()定义的条件只要满足一个,当前事件就可以成功匹配
当然,子类型限定条件(subtype)也可以和其他条件结合起来,成为组合条件,如下所示:
pattern.subtype(SubEvent.class).where(newSimpleCondition<SubEvent>(){@Overridepublicbooleanfilter(SubEvent value){return...// some condition}});
这里可以看到,SimpleCondition 的泛型参数也变成了 SubEvent,所以匹配出的事件就既满足子类型限制,又符合过滤筛选的简单条件;这也是一个逻辑与的关系
- 终止条件(Stop Conditions)
对于循环模式而言,还可以指定一个“终止条件”(Stop Condition),表示
遇到某个特定事件时当前模式就不再继续循环匹配了
终 止 条 件 的 定 义 是 通 过
调 用 模 式 对 象 的 .until() 方 法
来 实 现 的 , 同 样 传 入 一 个IterativeCondition 作为参数。需要注意的是,终止条件只与 oneOrMore() 或 者oneOrMore().optional()结合使用。因为在这种循环模式下,我们不知道后面还有没有事件可以匹配,只好把之前匹配的事件作为状态缓存起来继续等待,这等待无穷无尽;如果一直等下去,缓存的状态越来越多,最终会耗尽内存。所以这种循环模式必须有个终点,当.until()指定的条件满足时,循环终止,这样就可以清空状态释放内存了
3.2 组合模式
有了定义好的个体模式,就可以尝试按一定的顺序把它们连接起来,定义一个完整的复杂事件匹配规则了。这种将多个个体模式组合起来的完整模式,就叫作“组合模式”(Combining Pattern),
为了跟个体模式区分有时也叫作“模式序列”(Pattern Sequence)
组合模式就是一个“模式序列”
,是用诸如 begin、next、followedBy 等表示先后顺序的“连接词”将个体模式串连起来得到的。在这样的语法调用中,每个事件匹配的条件是什么、各个事件之间谁先谁后、近邻关系如何都定义得一目了然。每一个“连接词”方法调用之后,得到的都仍然是一个 Pattern 的对象;所以从 Java 对象的角度看,组合模式与个体模式是一样的,都是 Pattern
1. 初始模式(Initial Pattern)
所有的组合模式,都必须以一个“初始模式”开头;而初始模式必须通过调用 Pattern 的静态方法.begin()来创建。如下所示:
Pattern<Event,?> start =Pattern.<Event>begin("start");
这里我们调用 Pattern 的.begin()方法创建了一个初始模式。传入的 String 类型的参数就是模式的名称;而 begin 方法需要传入一个类型参数,这就是模式要检测流中事件的基本类型,这里我们定义为 Event。调用的结果返回一个 Pattern 的对象实例。Pattern 有两个泛型参数,第一个就是检测事件的基本类型 Event,跟 begin 指定的类型一致;第二个则是当前模式里事件的子类型,由子类型限制条件指定。我们这里用类型通配符(?)代替,就可以从上下文直接推断了
2. 近邻条件(Contiguity Conditions)
在初始模式之后,我们就可以按照复杂事件的顺序追加模式,组合成模式序列了。模式之间的组合是通过一些“连接词”方法实现的,这些连接词指明了先后事件之间有着怎样的近邻关系,这就是所谓的“近邻条件”(Contiguity Conditions,也叫“连续性条件”)
Flink CEP 中提供了三种近邻关系:
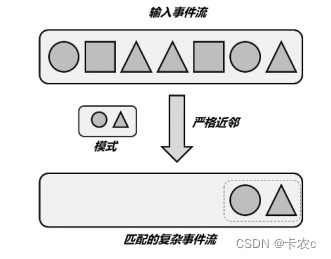
- 严格近邻(Strict Contiguity)
匹配的事件严格地按顺序一个接一个出现,中间不会有任何其他事件
代码中对应的就
是 Pattern 的.next()方法
,名称上就能看出来,“下一个”自然就是紧挨着的
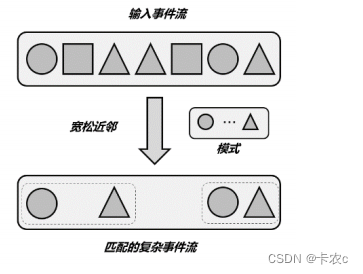
- 宽松近邻(Relaxed Contiguity)
宽松近邻只关心事件发生的顺序,而放宽了对匹配事件的“距离”要求,也就是说两个匹配的事件之间可以有其他不匹配的事件出现。
代码中对应.followedBy()方法
,很明显这表示“跟在后面”就可以,不需要紧紧相邻
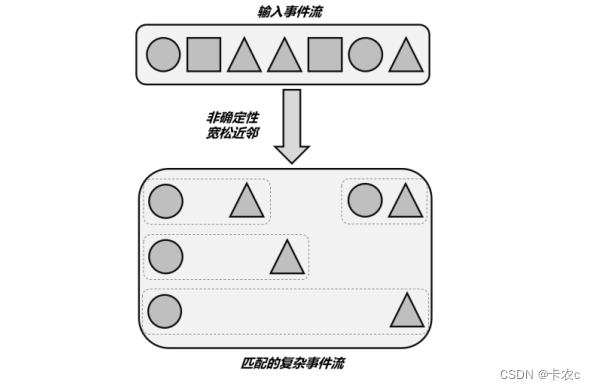
- 非确定性宽松近邻(Non-Deterministic Relaxed Contiguity)
也就是从全局找所有符合匹配模式的事件队列,下图我们找圆 + 三角,
代码中对应.followedByAny()方法
3. 其他限制条件
除了上面提到的 next()、followedBy()、followedByAny()可以分别表示三种近邻条件,我们还可以用否定的“连接词”来组合个体模式。主要包括:
- .notNext()
表示前一个模式匹配到的事件后面,不能紧跟着某种事件
- .notFollowedBy()
表示前一个模式匹配到的事件后面,不会出现某种事件
这里需要注意,由于notFollowedBy()是没有严格限定的;流数据不停地到来,我们永远不能保证之后“不会出现某种事件”。所以一个模式序列不能以 notFollowedBy()结尾,这个限定条件主要用来表示“两个事件中间不会出现某种事件”
- .within()
方法传入一个时间参数,这是模式序列中第一个事件到最后一个事件之间的最大时间间隔,只有在这期间成功匹配的复杂事件才是有效的。一个模式序列中只能有一个时间限制,调用.within()的位置不限;如果多次调用则会以最小的那个时间间隔为准
下面是模式序列中所有限制条件在代码中的定义:
// 严格近邻条件Pattern<Event,?> strict = start.next("middle").where(...);// 宽松近邻条件Pattern<Event,?> relaxed = start.followedBy("middle").where(...);// 非确定性宽松近邻条件Pattern<Event,?> nonDetermin =
start.followedByAny("middle").where(...);// 不能严格近邻条件Pattern<Event,?> strictNot = start.notNext("not").where(...);// 不能宽松近邻条件Pattern<Event,?> relaxedNot = start.notFollowedBy("not").where(...);// 时间限制条件
middle.within(Time.seconds(10));
4. 循环模式中的近邻条件
在循环模式中,近邻关系同样有三种:严格近邻、宽松近邻以及非确定性宽松近邻。对于定义了量词(如 oneOrMore()、times())的循环模式,默认内部采用的是宽松近邻。也就是说,当循环匹配多个事件时,它们中间是可以有其他不匹配事件的;相当于用单例模式分别定义、再用 followedBy()连接起来
- .consecutive()
循环模式中的匹配事件增加严格的近邻条件,保证所有匹配事件是严格连续的。也就是说,一旦中间出现了不匹配的事件,当前循环检测就会终止。这起到的效果跟模式序列中的next()一样,需要与循环量词 times()、oneOrMore()配合使用
- .allowCombinations()
除严格近邻外,也可以为循环模式中的事件指定非确定性宽松近邻条件,表示可以重复使用 已 经 匹 配 的 事 件。 这 需 要 调 用 .allowCombinations() 方 法 来 实 现 , 实 现 的 效 果与.followedByAny()相同
3.3 匹配后跳过策略
在 Flink CEP 中,由于有循环模式和非确定性宽松近邻的存在,同一个事件有可能会重复利用,被分配到不同的匹配结果中。这样会导致匹配结果规模增大,有时会显得非常冗余。当然,非确定性宽松近邻条件,本来就是为了放宽限制、扩充匹配结果而设计的;我们主要是针对循环模式来考虑匹配结果的精简
之前已经讲过,如果对循环模式增加了.greedy()的限制,那么就会“尽可能多地”匹配事件,这样就可以砍掉那些子集上的匹配了。不过这种方式还是略显简单粗暴,如果我们想要精确控制事件的匹配应该跳过哪些情况,那就需要制定另外的策略了
在 Flink CEP 中,提供了模式的“匹配后跳过策略”(After Match Skip Strategy),专门用来精准控制循环模式的匹配结果。这个策略可以在 Pattern 的初始模式定义中,作为 begin()的第二个参数传入:
Pattern.begin("start",AfterMatchSkipStrategy.noSkip()).where(...)

具体的跳过策略有5种
publicabstractclassAfterMatchSkipStrategyimplementsSerializable{privatestaticfinallong serialVersionUID =-4048930333619068531L;publicstaticSkipToFirstStrategyskipToFirst(String patternName){returnnewSkipToFirstStrategy(patternName,false);}publicstaticSkipToLastStrategyskipToLast(String patternName){returnnewSkipToLastStrategy(patternName,false);}publicstaticSkipPastLastStrategyskipPastLastEvent(){returnSkipPastLastStrategy.INSTANCE;}publicstaticAfterMatchSkipStrategyskipToNext(){returnSkipToNextStrategy.INSTANCE;}publicstaticNoSkipStrategynoSkip(){returnNoSkipStrategy.INSTANCE;}}
案例
输入为 a a a b b
Pattern<Word,Word> wordPattern =Pattern.<Word>begin("first").oneOrMore().where(newSimpleCondition<Word>(){@Overridepublicbooleanfilter(Word word)throwsException{return word.ch.equals('a');}}).next("second").oneOrMore().where(newSimpleCondition<Word>(){@Overridepublicbooleanfilter(Word word)throwsException{return word.ch.equals('b');}});
- 不跳过(NO_SKIP)
代码调用 AfterMatchSkipStrategy.noSkip()。这是默认策略,所有可能的匹配都会输出
返回 [a,a,a,b] 、[a,a,b] 、[a,b]、 [a,a,a,b,b] 、 [a,a,b,b] 、[a,b,b]
- 跳至下一个(SKIP_TO_NEXT)
代码调用 AfterMatchSkipStrategy.skipToNext(),找到一个匹配项,跳至下一个元素
返回 [a,a,a,b] 、[a,a,b] 、[a,b]
- 跳过所有子匹配(SKIP_PAST_LAST_EVENT)
代码调用 AfterMatchSkipStrategy.skipPastLastEvent(),只返回第一个匹配也即跳过所有子匹配,这是最为精简的跳过策略
返回[a,a,a,b]
- 跳至第一个(SKIP_TO_FIRST[])
代码调用 AfterMatchSkipStrategy.skipToFirst(“second”),这里传入一个参数,指明跳至哪个模式的第一个匹配事件
返回 [a,a,a,b] 、[a,a,b] 、[a,b] ,second的一个匹配为b
- 跳至最后一个(SKIP_TO_LAST[])
代码调用 AfterMatchSkipStrategy.skipToLast(“second”),同样传入一个参数,指明跳至哪个模式的最后一个匹配事件
4.模式的检测处理
4.1 模式应用到数据流
将模式应用到事件流上的代码非常简单,只要调用 CEP 类的静态方法.pattern(),将数据流(DataStream)和模式(Pattern)作为两个参数传入就可以了。最终得到的是一个 PatternStream:
DataStream<Event> inputStream =...Pattern<Event,?> pattern =...PatternStream<Event> patternStream = CEP.pattern(inputStream, pattern);
这里的 DataStream,也可以通过 keyBy 进行按键分区得到 KeyedStream,接下来对复杂事件的检测就会针对不同的 key 单独进行了
模式中定义的复杂事件,发生是有先后顺序的,这里“先后”的判断标准取决于具体的时间语义。默认情况下采用事件时间语义,那么事件会以各自的时间戳进行排序;如果是处理时间语义,那么所谓先后就是数据到达的顺序。对于时间戳相同或是同时到达的事件,我们还可以在 CEP.pattern()中传入一个比较器作为第三个参数,用来进行更精确的排序:
// 可选的事件比较器EventComparator<Event> comparator =...PatternStream<Event> patternStream = CEP.pattern(input, pattern, comparator);
得到 PatternStream 后,接下来要做的就是对匹配事件的检测处理了
4.2 处理匹配事件
基于 PatternStream 可以调用一些转换方法,对匹配的复杂事件进行检测和处理,并最终得到一个正常的 DataStream。这个转换的过程与窗口的处理类似:将模式应用到流上得到PatternStream,就像在流上添加窗口分配器得到 WindowedStream;而之后的转换操作,就像定义具体处理操作的窗口函数,对收集到的数据进行分析计算,得到结果进行输出,最后回到DataStream 的类型来
PatternStream 的转换操作主要可以分成两种:简单便捷的选择提取(select)操作,和更加通用、更加强大的处理(process)操作。与 DataStream 的转换类似,具体实现也是在调用API 时传入一个函数类:选择操作传入的是一个 PatternSelectFunction,处理操作传入的则是一个 PatternProcessFunction
1. 匹配事件的选择提取(select)

处理匹配事件最简单的方式,就是从 PatternStream 中直接把匹配的复杂事件提取出来,包装成想要的信息输出,这个操作就是“选择”(select)
- PatternSelectFunction
代码中基于 PatternStream 直接调用.select()方法,传入一个 PatternSelectFunction 作为参数
publicinterfacePatternSelectFunction<IN, OUT>extendsFunction,Serializable{OUTselect(Map<String,List<IN>> var1)throwsException;}
它会将检测到的匹配事件保存在一个 Map 里,对应的 key 就是这些事件的名称。这里的“事件名称”就对应着在模式中定义的每个个体模式的名称;而个体模式可以是循环模式,一个名称会对应多个事件,所以最终保存
在 Map 里的 value 就是一个事件的列表(List)
2.flatSelect

- PatternFlatSelectFunction
PatternStream 还有一个类似的方法是.flatSelect(),传入的参数是一个PatternFlatSelectFunction。从名字上就能看出,这是 PatternSelectFunction 的“扁平化”版本;内部需要实现一个 flatSelect()方法,它与之前 select()的不同就在于没有返回值,而是多了一个收集器(Collector)参数 out,通过调用 out.collet()方法就可以实现多次发送输出数据了
publicinterfacePatternFlatSelectFunction<IN, OUT>extendsFunction,Serializable{voidflatSelect(Map<String,List<IN>> var1,Collector<OUT> var2)throwsException;}
3.process

@PublicEvolvingpublicabstractclassPatternProcessFunction<IN, OUT>extendsAbstractRichFunction{publicPatternProcessFunction(){}publicabstractvoidprocessMatch(Map<String,List<IN>> var1,Context var2,Collector<OUT> var3)throwsException;publicinterfaceContextextendsTimeContext{<X>voidoutput(OutputTag<X> var1,X var2);}}
4.3 处理超时事件
复杂事件的检测结果一般只有两种:要么匹配,要么不匹配。检测处理的过程具体如下:
(1)如果当前事件符合模式匹配的条件,就接受该事件,保存到对应的 Map 中
(2)如果在模式序列定义中,当前事件后面还应该有其他事件,就继续读取事件流进行检测;如果模式序列的定义已经全部满足,那么就成功检测到了一组匹配的复杂事件,调用PatternProcessFunction 的 processMatch()方法进行处理
(3)如果当前事件不符合模式匹配的条件,就丢弃该事件
(4)如果当前事件破坏了模式序列中定义的限制条件,比如不满足严格近邻要求,那么当前已检测的一组部分匹配事件都被丢弃,重新开始检测
不过在有时间限制的情况下,需要考虑的问题会有一点特别。比如我们用.within()指定了模式检测的时间间隔,超出这个时间当前这组检测就应该失败了。然而这种“超时失败”跟真正的“匹配失败”不同,它其实是一种“部分成功匹配”;因为只有在开头能够正常匹配的前提下,没有等到后续的匹配事件才会超时。所以往往不应该直接丢弃,而是要输出一个提示或报警信息。这就要求我们有能力捕获并处理超时事件
使用 PatternProcessFunction 的侧输出流
在 Flink CEP 中 , 提 供 了 一 个 专 门 捕 捉 超 时 的 部 分 匹 配 事 件 的 接 口 , 叫 作TimedOutPartialMatchHandler。这个接口需要实现一个 processTimedOutMatch()方法,可以将超时的、已检测到的部分匹配事件放在一个 Map 中,作为方法的第一个参数;方法的第二个参数则是 PatternProcessFunction 的上下文 Context。所以这个接口必须与 PatternProcessFunction结合使用,对处理结果的输出则需要利用侧输出流来进行。代码中的调用方式如下:
classMyPatternProcessFunctionextendsPatternProcessFunction<Event,String>implementsTimedOutPartialMatchHandler<Event>{// 正常匹配事件的处理@OverridepublicvoidprocessMatch(Map<String,List<Event>> match,Context ctx,Collector<String> out)throwsException{...}// 超时部分匹配事件的处理@OverridepublicvoidprocessTimedOutMatch(Map<String,List<Event>> match,Context ctx)throwsException{Event startEvent = match.get("start").get(0);OutputTag<Event> outputTag =newOutputTag<Event>("time-out"){};
ctx.output(outputTag, startEvent);}}
我们在 processTimedOutMatch()方法中定义了一个输出标签(OutputTag)。调用 ctx.output()方法,就可以将超时的部分匹配事件输出到标签所标识的侧输出流了
案例,检测用户订单是否超时
publicclassTimeOutTest{publicstaticvoidmain(String[] args)throwsException{// 创建一个表执行环境StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tableEnv =StreamTableEnvironment.create(env);
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100);// 100毫秒生成一次水位线// 1.用户行为事件 检测用户订单是否超时 我们假设订单从创建到支付只有20分钟,并且可以中途修改,但是修改后不会重新计时SingleOutputStreamOperator<OrderEvent> streamOperator = env.fromElements(newOrderEvent("1","101","create",1000L),newOrderEvent("2","102","create",20000L),newOrderEvent("1","101","update",10*60*1000L),newOrderEvent("1","101","pay",15*60*1000L)).assignTimestampsAndWatermarks(WatermarkStrategy.<OrderEvent>forBoundedOutOfOrderness(Duration.ofSeconds(2))// 延迟2秒保证数据正确.withTimestampAssigner(newSerializableTimestampAssigner<OrderEvent>(){@Override// 时间戳的提取器publiclongextractTimestamp(OrderEvent event,long l){return event.timestamp;}}));// 2.定义模式Pattern<OrderEvent,OrderEvent> pattern =Pattern.<OrderEvent>begin("first").where(newSimpleCondition<OrderEvent>(){@Overridepublicbooleanfilter(OrderEvent orderEvent)throwsException{return orderEvent.action.equals("create");}}).followedBy("pay")// 因为中途可以修改订单,所以是非严格近邻.where(newSimpleCondition<OrderEvent>(){@Overridepublicbooleanfilter(OrderEvent orderEvent)throwsException{return orderEvent.action.equals("pay");}}).within(Time.minutes(15));// 3.将模式应用到数据流上PatternStream<OrderEvent> patternStream = CEP.pattern(streamOperator.keyBy(event -> event.orderId), pattern);// 4侧输出流 定义侧输出流标签OutputTag<String> outputTag =newOutputTag<String>("timeout"){};// 5.处理匹配到的数据SingleOutputStreamOperator<String> res = patternStream.process(newMyPatternProcessFunction(outputTag));
res.print("payed: =>");
res.getSideOutput(outputTag).print("timeout: =>");
env.execute();}publicstaticclassMyPatternProcessFunctionextendsPatternProcessFunction<OrderEvent,String>implementsTimedOutPartialMatchHandler<OrderEvent>{publicOutputTag<String> outputTag;publicMyPatternProcessFunction(OutputTag<String> outputTag){this.outputTag = outputTag;}// 获取正常的匹配事件@OverridepublicvoidprocessMatch(Map<String,List<OrderEvent>> map,Context context,Collector<String> collector)throwsException{OrderEvent orderEvent = map.get("pay").get(0);
collector.collect("用户 "+ orderEvent.userId +"的订单=>"+ orderEvent.orderId +"正常支付!");}// 处理超时的事件@OverridepublicvoidprocessTimedOutMatch(Map<String,List<OrderEvent>> map,Context context)throwsException{OrderEvent orderEvent = map.get("first").get(0);
context.output(outputTag,"用户 "+ orderEvent.userId +"的订单=>"+ orderEvent.orderId +"超时!");}}}

版权归原作者 Jumanji_ 所有, 如有侵权,请联系我们删除。