
云上大数据
1.Hadoop 生态圈组件介绍
2.重点介绍mapreduce概述
3.重点介绍spark技术特点和概述
4.对比mapreduce和spark的区别
5.结构化数据与非结构化数据是什么?
6.Linux简单操作命令实训练习。
Hadoop生态圈组建介绍
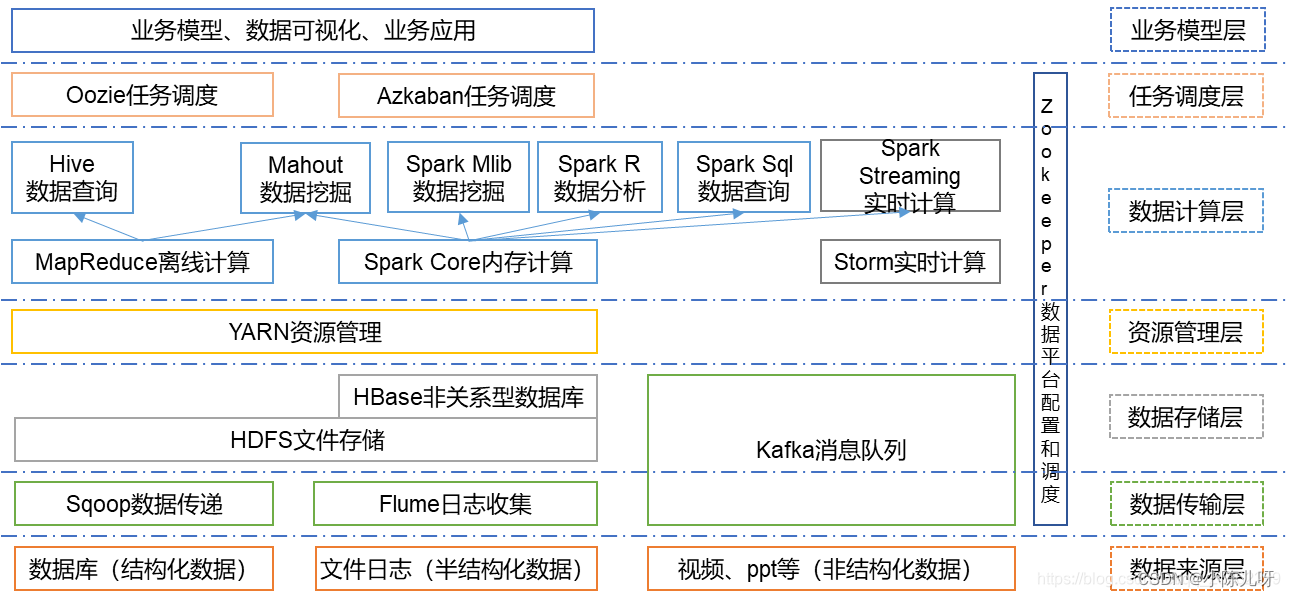
Hadoop是一种大数据框架结构,我们可以把它比作一个大型的工厂。
划重点:是个框架,MapReduce就是里面的核心组件
首先,Hadoop的主要组成部分分有两个:HDFS和MapReduce.
HDPS提供存储,MapReduce提供计算,YARN用于管理和调度
- HDPS(Hadoop Distributed File System)是Hadoop的文件系统,它是Hadoop生态系统中的核心项目之一,是分布式计算中数据存储管理基础。
- MapReduce分布式计算框架:是一种计算模型,用于大规模数据集(大于1TB)的并行运算
- Yarn资源管理框架:是Hadoop中的资源管理器,它可为上层应用提供统一的资源管理和调度。
** 介绍mapreduce**
** mapreduce是Hadoop的计算模型,是一个分布式运算程序的编程框架,使用户开发“给予 Hadoop的数据分析应用”的核心框架,用于解决海量数据计算。**
** MapReduce将复杂的分布式计算过程分解为两个主要阶段:映射(map)和归约(Reduce)**
MapReduce优点
1)MapReduce易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序就可以分布到大量的 PC机器上运行。
2)良好的扩展性
当你的计算资源不能的到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
3)高容错性
MapReduce设计的初衷就是使程序能够部署在PC机器上,这就要求它具有很高的容错性。 比如其中的一台机器挂掉了,它可以把上面的计算任务转移到另一台节点上运行,且不需要 人工干预,由Hadoop内部完成的。
** MapReduce缺点**
1)不擅长实时计算
MapReduce无法在毫秒或者秒级内返回结果
2)不擅长流失计算
流试计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。
3)不擅长DAG(有向无环图)计算
不擅长DAG(有向图)计算 — 不建议使用,会导致MR一直写入到磁盘造成大量磁盘IO,影响性能
spark技术特点和概述
Spark 是当今大数据领域最活跃、最热门、最高效的大数据通用计算平台之一。
spark拥有Hadoop MapReduce所具有的优点,spark中间输出结果可以保存在内存中,从而不需要读写HDFS,因此spark性能以及运算速度高于MapReduce。

优点:
1)快速
spark在内存中的运行速度是Hadoopuce MapReduce运行速度的100多倍,spark在磁盘上的运行速度是Hadoop MapReduce运行速度的10多倍。
2)提供了大量的库
spark core、sparkSQL、spark streaming、MLilb、graphx.
3)支持多种资源管理器
支持Hadoop yarn,及其自带额独立集群管理器
4)操作简单
支持Scala,Python等语言编写代码。
对比mapreduce和spark的区别
1)实用性方面:MapReduce不容易编程、不实用,而Spark有良好的API接口,方便对接编程,很实用;
2)特点方面:MapReduce初始实现分布式计算,而Spark实现分布式内存计算;
3)迭代运算方面:MapReduce几乎不能实现迭代运算,每次MR都要进行数据的重新读入和加载,而Spark可以将迭代数据集直接加载到内存处理,实现内存环境下的直接迭代运算;
5)容错性方面:MapReduce由HDFS分布式存储框架实现,而Spark内存数据集直接实现;
6)执行模型方面:MapReduce只能进行批处理,而Spark批处理、迭代处理、流处理均可;
7)支持的编程语言类型方面:MapReduce主要是Java,而Spark Java、Scala、Python、R等。
结构化数据与非结构化数据是什么?
结构化数据是指以关系型数据库表形式管理的数据。一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。比如:Excel,mysql
非结构化数据,是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据,更难被计算机所理解。也是大家通常说的文件数据,比如:视频、音频、图片、图像、文档、文本
Linux简单操作命令实训练习。
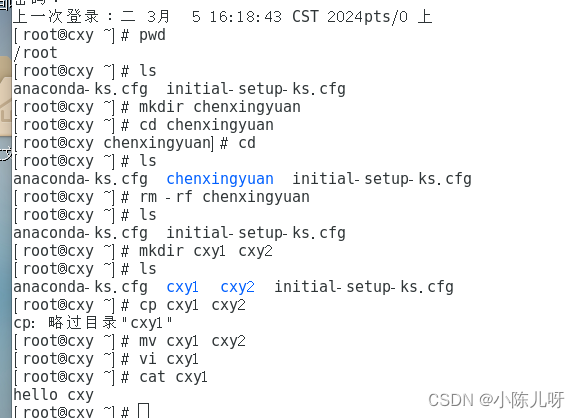
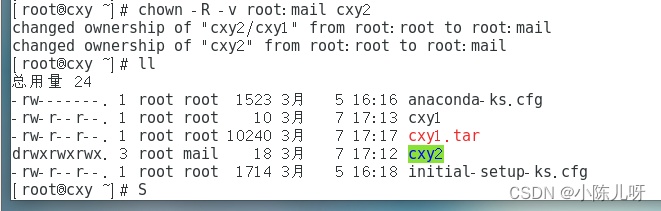
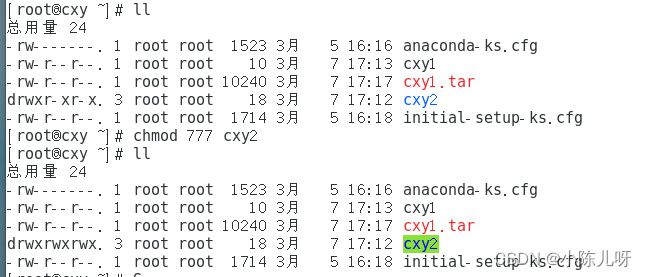
** **

版权归原作者 小陈儿呀 所有, 如有侵权,请联系我们删除。