
文章目录

简介
Selenium 是最广泛使用的开源 Web UI(用户界面)自动化测试套件之一。Selenium 支持的语言包括C#,Java,Perl,PHP,Python 和 Ruby。目前,Selenium Web 驱动程序最受 Python 和 C#欢迎。 Selenium 测试脚本可以使用任何支持的编程语言进行编码,并且可以直接在大多数现代 Web 浏览器中运行。在爬虫领域 selenium 同样是一把利器,能够解决大部分的网页的反爬问题。下面就进入正式的 study 阶段。
selenium安装
打开 cmd,输入下面命令进行安装。
pip install -i https://pypi.douban.com/simple selenium
执行后,使用
pip show selenium
查看是否安装成功。
安装浏览器驱动
针对不同的浏览器,需要安装不同的驱动。下面列举了常见的浏览器与对应的驱动程序下载链接,部分网址需要 “科学上网” 才能打开哦(dddd)。
- Firefox 浏览器驱动:Firefox
- Chrome 浏览器驱动:Chrome
- IE 浏览器驱动:IE
- Edge 浏览器驱动:Edge
- PhantomJS 浏览器驱动:PhantomJS
- Opera 浏览器驱动:Opera
这里以安装
Chrome
驱动作为演示。但
Chrome
在用
selenium
进行自动化测试时还是有部分
bug
,常规使用没什么问题,但如果出现一些很少见的报错,可以使用
Firefox
进行尝试,毕竟是
selenium
官方推荐使用的。
确定浏览器版本
在新标签页输入
chrome://settings/
进入设置界面,然后选择 【关于 Chrome】
查看自己的版本信息。这里我的版本是94,这样在下载对应版本的
Chrome
驱动即可。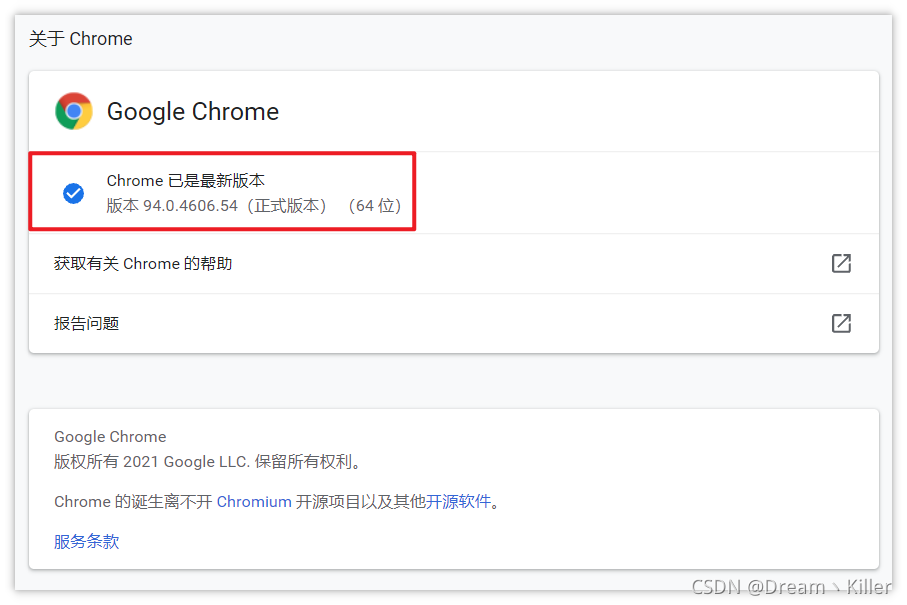
下载驱动
打开 Chrome驱动 。单击对应的版本。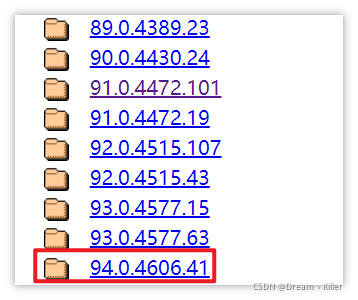
根据自己的操作系统,选择下载。
下载完成后,压缩包内只有一个
exe
文件。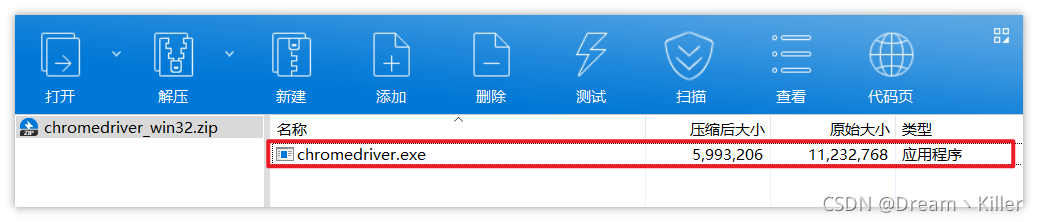
将
chromedriver.exe
保存到任意位置,并把当前路径保存到环境变量中(我的电脑>>右键属性>>高级系统设置>>高级>>环境变量>>系统变量>>Path),添加的时候要注意不要把 path 变量给覆盖了,如果覆盖了千万别关机,然后百度。添加成功后使用下面代码进行测试。
from selenium import webdriver
# Chrome浏览器
driver = webdriver.Chrome()
定位页面元素
打开指定页面
使用
selenium
定位页面元素的前提是你已经了解基本的页面布局及各种标签含义,当然如果之前没有接触过,现在我也可以带你简单的了解一下。
以我们熟知的 CSDN 为例,我们进入首页,按 【F12】 进入开发者工具。红框中显示的就是页面的代码,我们要做的就是从代码中定位获取我们需要的元素。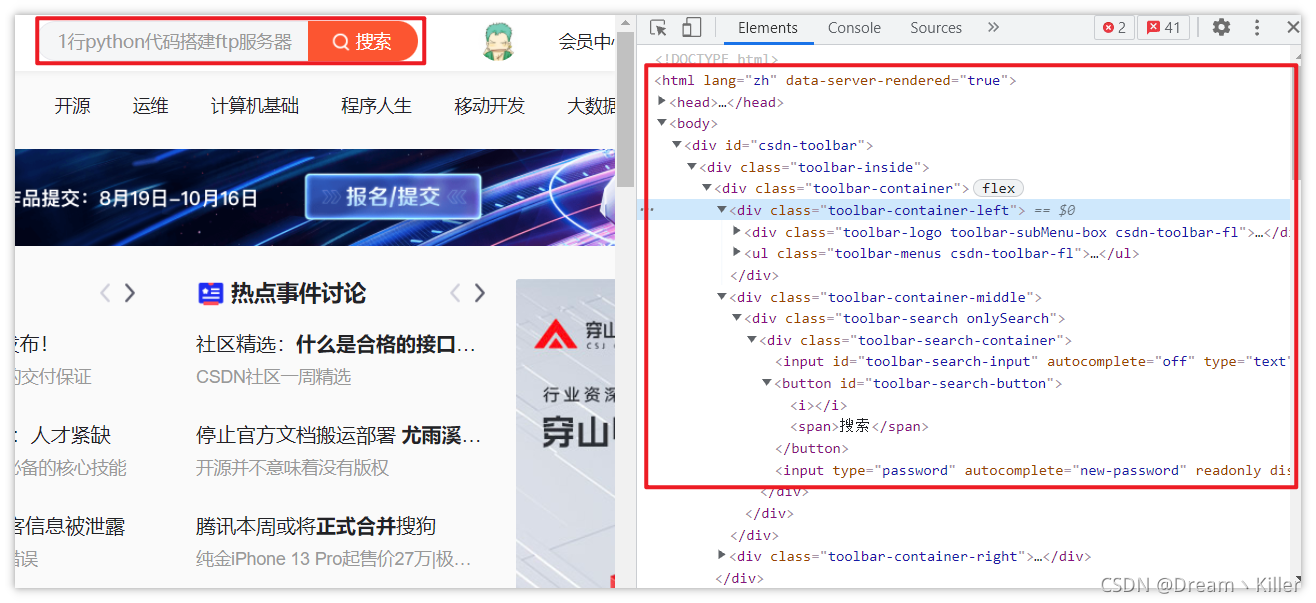
想要定位并获取页面中的信息,首先要使用
webdriver
打开指定页面,再去定位。
from selenium import webdriver
# Chrome浏览器
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/')
执行上面语句后会发现,浏览器打开 CSDN 主页后会马上关闭,想要防止浏览器自动关闭,可以添加下面代码。
# 不自动关闭浏览器
option = webdriver.ChromeOptions()
option.add_experimental_option("detach",True)# 将option作为参数添加到Chrome中
driver = webdriver.Chrome(chrome_options=option)
这样将上面的代码组合再打开浏览器就不会自动关闭了。
from selenium import webdriver
# 不自动关闭浏览器
option = webdriver.ChromeOptions()
option.add_experimental_option("detach",True)# 注意此处添加了chrome_options参数
driver = webdriver.Chrome(chrome_options=option)
driver.get('https://www.csdn.net/')
下面我们再来看看几种常见的页面元素定位方式。
id 定位
标签的
id
具有唯一性,就像人的身份证,假设有个
input
标签如下。
<inputid="toolbar-search-input"autocomplete="off"type="text"value=""placeholder="C++难在哪里?">
我们可以通过
id
定位到它,由于
id
的唯一性,我们可以不用管其他的标签的内容。
driver.find_element_by_id("toolbar-search-input")
name 定位
name
指定标签的名称,在页面中可以不唯一。假设有个
meta
标签如下
<metaname="keywords"content="CSDN博客,CSDN学院,CSDN论坛,CSDN直播">
我们可以使用
find_element_by_name
定位到
meta
标签。
driver.find_element_by_name("keywords")
class 定位
class
指定标签的类名,在页面中可以不唯一。假设有个
div
标签如下
<divclass="toolbar-search-container">
我们可以使用
find_element_by_class_name
定位到
div
标签。
driver.find_element_by_class_name("toolbar-search-container")
tag 定位
每个
tag
往往用来定义一类功能,所以通过
tag
来识别某个元素的成功率很低,每个页面一般都用很多相同的
tag
,比如:
\<div\>
、
\<input\>
等。这里还是用上面的
div
作为例子。
<divclass="toolbar-search-container">
我们可以使用
find_element_by_class_name
定位到
div
标签。
driver.find_element_by_tag_name("div")
xpath 定位
xpath
是一种在
XML
文档中定位元素的语言,它拥有多种定位方式,下面通过实例我们看一下它的几种使用方式。
<html><head>...<head/><body><divid="csdn-toolbar"><divclass="toolbar-inside"><divclass="toolbar-container"><divclass="toolbar-container-left">...</div><divclass="toolbar-container-middle"><divclass="toolbar-search onlySearch"><divclass="toolbar-search-container"><inputid="toolbar-search-input"autocomplete="off"type="text"value=""placeholder="C++难在哪里?">
根据上面的标签需要定位 最后一行
input
标签,以下列出了四种方式,
xpath
定位的方式多样并不唯一,使用时根据情况进行解析即可。
# 绝对路径(层级关系)定位
driver.find_element_by_xpath("/html/body/div/div/div/div[2]/div/div/input[1]")# 利用元素属性定位
driver.find_element_by_xpath("//*[@id='toolbar-search-input']"))# 层级+元素属性定位
driver.find_element_by_xpath("//div[@id='csdn-toolbar']/div/div/div[2]/div/div/input[1]")# 逻辑运算符定位
driver.find_element_by_xpath("//*[@id='toolbar-search-input' and @autocomplete='off']")
css 定位
CSS
使用选择器来为页面元素绑定属性,它可以较为灵活的选择控件的任意属性,一般定位速度比
xpath
要快,但使用起来略有难度。
CSS
选择器常见语法:
方法例子描述**.class**
.toolbar-search-container
选择
class = 'toolbar-search-container'
的所有元素**#id**
#toolbar-search-input
选择
id = 'toolbar-search-input'
的元素*****
*
选择所有元素element
input
选择所有
<input\>
元素element>element
div>input
选择父元素为
<div\>
的所有
<input\>
元素element+element
div+input
选择同一级中在
<div\>
之后的所有
<input\>
元素**[attribute=value]**
type='text'
选择
type = 'text'
的所有元素
举个简单的例子,同样定位上面实例中的
input
标签。
driver.find_element_by_css_selector('#toolbar-search-input')
driver.find_element_by_css_selector('html>body>div>div>div>div>div>div>input')
link 定位
link
专门用来定位文本链接,假如要定位下面这一标签。
<divclass="practice-box"data-v-04f46969="">加入!每日一练</div>
我们使用
find_element_by_link_text
并指明标签内全部文本即可定位。
driver.find_element_by_link_text("加入!每日一练")
partial_link 定位
partial_link
翻译过来就是“部分链接”,对于有些文本很长,这时候就可以只指定部分文本即可定位,同样使用刚才的例子。
<divclass="practice-box"data-v-04f46969="">加入!每日一练</div>
我们使用
find_element_by_partial_link_text
并指明标签内部分文本进行定位。
driver.find_element_by_partial_link_text("加入")
浏览器控制
修改浏览器窗口大小
webdriver
提供
set_window_size()
方法来修改浏览器窗口的大小。
from selenium import webdriver
# Chrome浏览器
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/')# 设置浏览器浏览器的宽高为:600x800
driver.set_window_size(600,800)
也可以使用
maximize_window()
方法可以实现浏览器全屏显示。
from selenium import webdriver
# Chrome浏览器
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/')# 设置浏览器浏览器的宽高为:600x800
driver.maximize_window()
浏览器前进&后退
webdriver
提供
back
和
forward
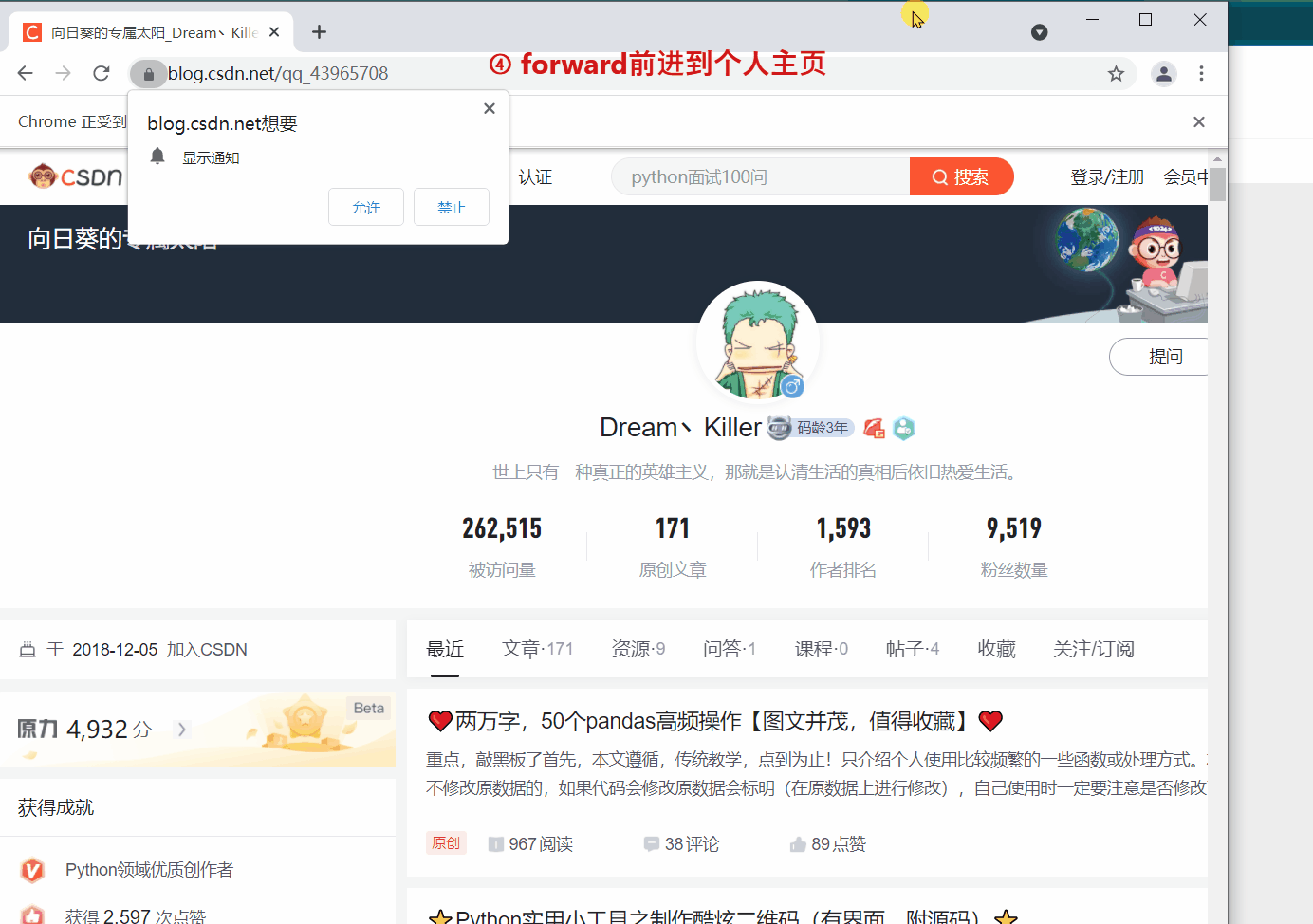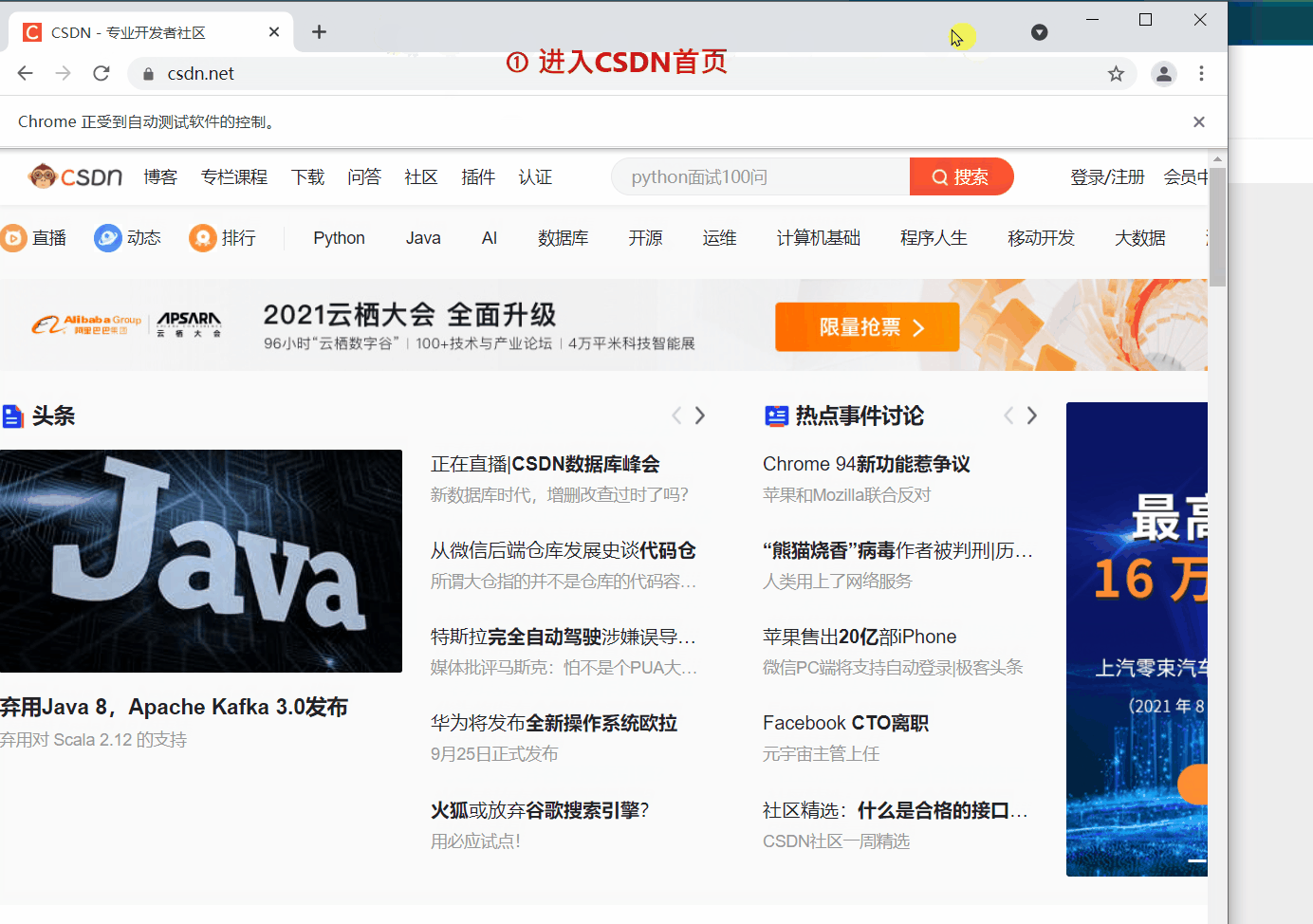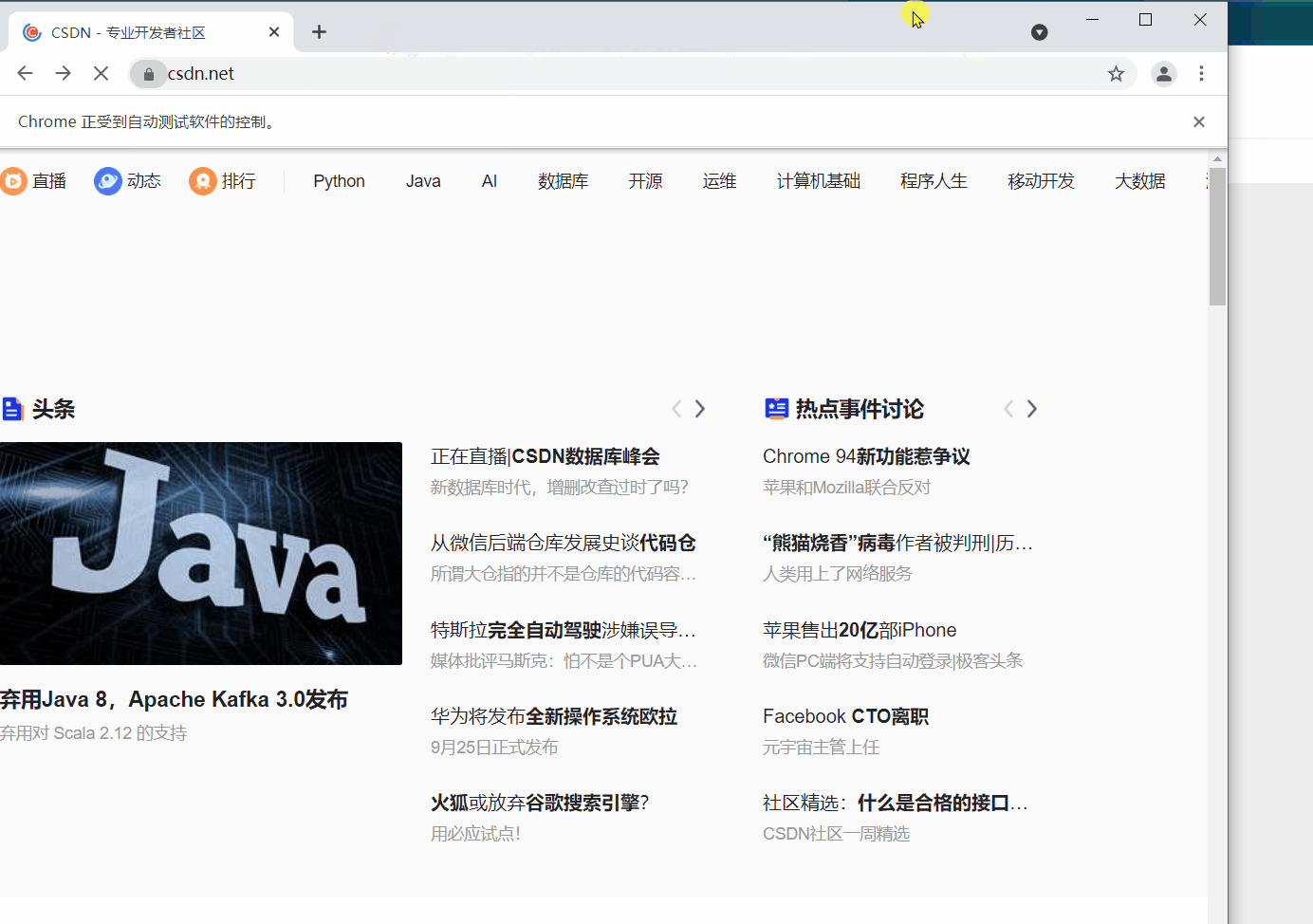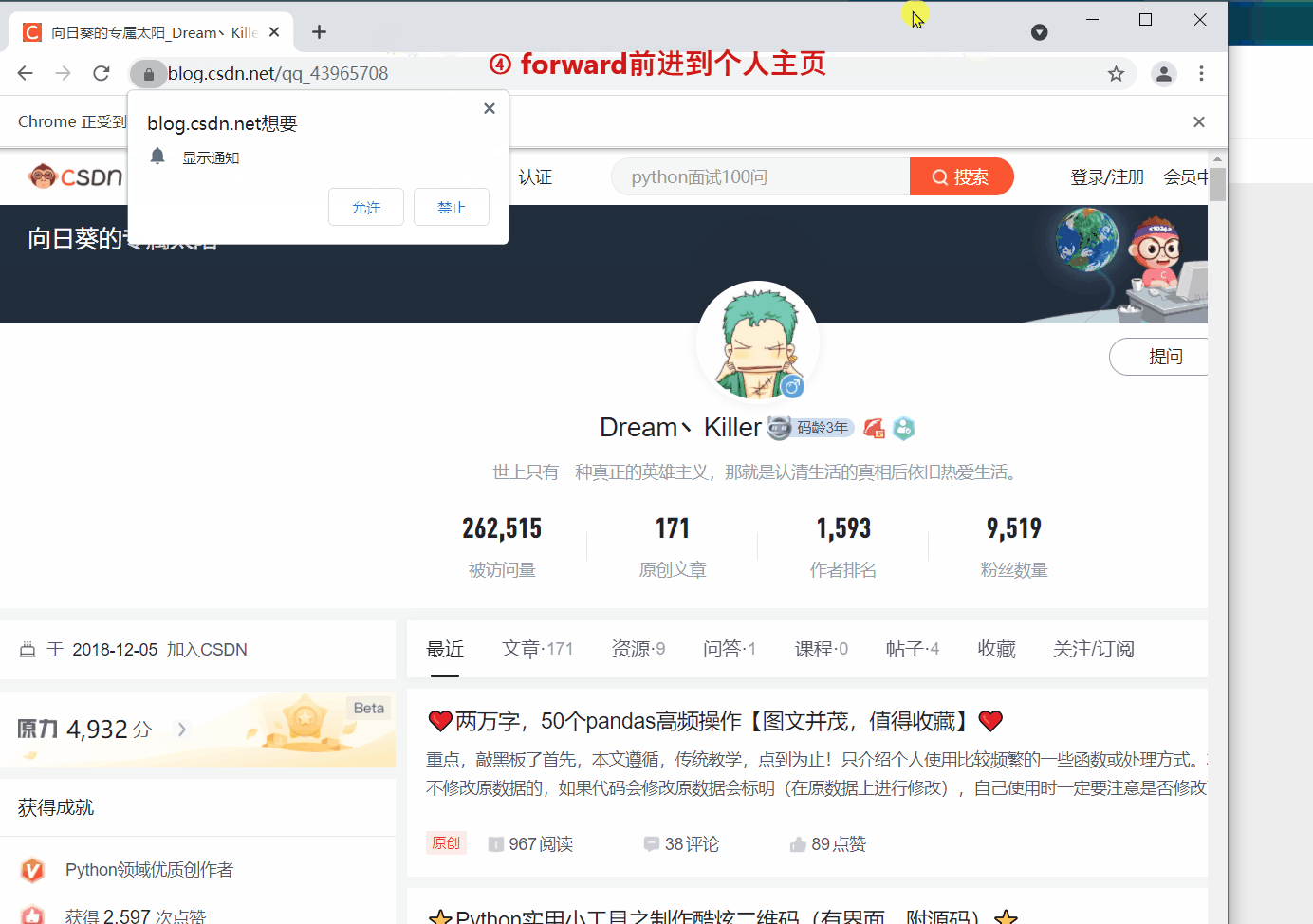
方法来实现页面的后退与前进。下面我们 ①进入CSDN首页,②打开CSDN个人主页,③
back
返回到CSDN首页,④
forward
前进到个人主页。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()# 访问CSDN首页
driver.get('https://www.csdn.net/')
sleep(2)#访问CSDN个人主页
driver.get('https://blog.csdn.net/qq_43965708')
sleep(2)#返回(后退)到CSDN首页
driver.back()
sleep(2)#前进到个人主页
driver.forward()
细心的读者会发现第二次
get()
打开新页面时,会在原来的页面打开,而不是在新标签中打开。如果想的话也可以在新的标签页中打开新的链接,但需要更改一下代码,执行
js
语句来打开新的标签。
# 在原页面打开
driver.get('https://blog.csdn.net/qq_43965708')# 新标签中打开
js ="window.open('https://blog.csdn.net/qq_43965708')"
driver.execute_script(js)
浏览器刷新
在一些特殊情况下我们可能需要刷新页面来获取最新的页面数据,这时我们可以使用
refresh()
来刷新当前页面。
# 刷新页面
driver.refresh()
浏览器窗口切换
在很多时候我们都需要用到窗口切换,比如:当我们点击注册按钮时,它一般会打开一个新的标签页,但实际上代码并没有切换到最新页面中,这时你如果要定位注册页面的标签就会发现定位不到,这时就需要将实际窗口切换到最新打开的那个窗口。我们先获取当前各个窗口的句柄,这些信息的保存顺序是按照时间来的,最新打开的窗口放在数组的末尾,这时我们就可以定位到最新打开的那个窗口了。
# 获取打开的多个窗口句柄
windows = driver.window_handles
# 切换到当前最新打开的窗口
driver.switch_to.window(windows[-1])
常见操作
webdriver中的常见操作有:
方法描述
send_keys()
模拟输入指定内容
clear()
清除文本内容
is_displayed()
判断该元素是否可见
get_attribute()
获取标签属性值
size
返回元素的尺寸
text
返回元素文本
接下来还是用 CSDN 首页为例,需要用到的就是搜素框和搜索按钮。通过下面的例子就可以气息的了解各个操作的用法了。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/')
sleep(2)# 定位搜索输入框
text_label = driver.find_element_by_xpath('//*[@id="toolbar-search-input"]')# 在搜索框中输入 Dream丶Killer
text_label.send_keys('Dream丶Killer')
sleep(2)# 清除搜索框中的内容
text_label.clear()# 输出搜索框元素是否可见print(text_label.is_displayed())# 输出placeholder的值print(text_label.get_attribute('placeholder'))# 定位搜索按钮
button = driver.find_element_by_xpath('//*[@id="toolbar-search-button"]/span')# 输出按钮的大小print(button.size)# 输出按钮上的文本print(button.text)'''输出内容
True
python面试100问
{'height': 32, 'width': 28}
搜索
'''
鼠标控制
在webdriver 中,鼠标操作都封装在ActionChains类中,常见方法如下:
方法描述
click()
单击左键
context_click()
单击右键
double_click()
双击
drag_and_drop()
拖动
move_to_element()
鼠标悬停
perform()
执行所有ActionChains中存储的动作
单击左键
模拟完成单击鼠标左键的操作,一般点击进入子页面等会用到,左键不需要用到
ActionChains
。
# 定位搜索按钮
button = driver.find_element_by_xpath('//*[@id="toolbar-search-button"]/span')# 执行单击操作
button.click()
单击右键
鼠标右击的操作与左击有很大不同,需要使用
ActionChains
。
from selenium.webdriver.common.action_chains import ActionChains
# 定位搜索按钮
button = driver.find_element_by_xpath('//*[@id="toolbar-search-button"]/span')# 右键搜索按钮
ActionChains(driver).context_click(button).perform()
双击
模拟鼠标双击操作。
# 定位搜索按钮
button = driver.find_element_by_xpath('//*[@id="toolbar-search-button"]/span')# 执行双击动作
ActionChains(driver).double_click(button).perform()
拖动
模拟鼠标拖动操作,该操作有两个必要参数,
- source:鼠标拖动的元素
- target:鼠标拖至并释放的目标元素
# 定位要拖动的元素
source = driver.find_element_by_xpath('xxx')# 定位目标元素
target = driver.find_element_by_xpath('xxx')# 执行拖动动作
ActionChains(driver).drag_and_drop(source, target).perform()
鼠标悬停
模拟悬停的作用一般是为了显示隐藏的下拉框,比如 CSDN 主页的收藏栏,我们看一下效果。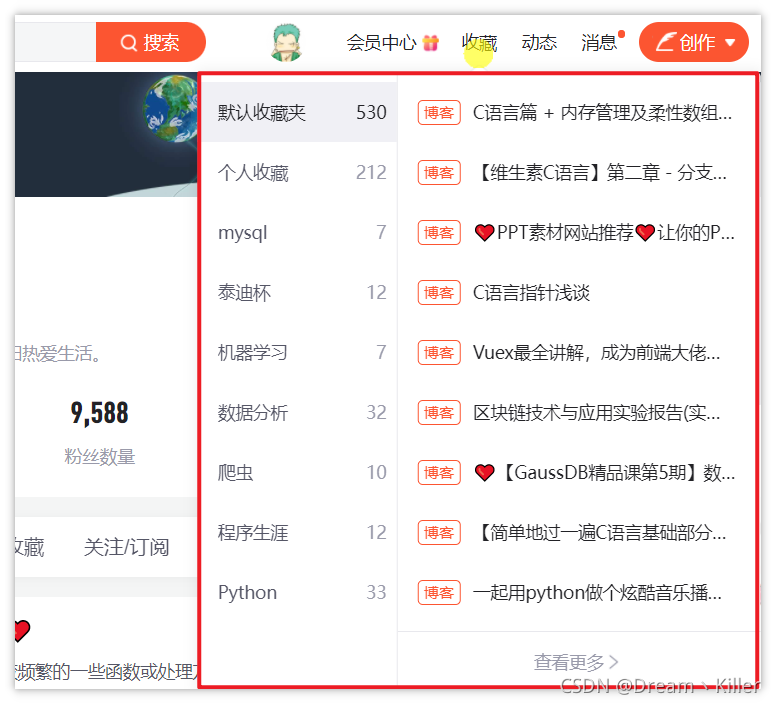
# 定位收藏栏
collect = driver.find_element_by_xpath('//*[@id="csdn-toolbar"]/div/div/div[3]/div/div[3]/a')# 悬停至收藏标签处
ActionChains(driver).move_to_element(collect).perform()
键盘控制
webdriver
中
Keys
类几乎提供了键盘上的所有按键方法,我们可以使用
send_keys + Keys
实现输出键盘上的组合按键如 “Ctrl + C”、“Ctrl + V” 等。
from selenium.webdriver.common.keys import Keys
# 定位输入框并输入文本
driver.find_element_by_id('xxx').send_keys('Dream丶killer')# 模拟回车键进行跳转(输入内容后)
driver.find_element_by_id('xxx').send_keys(Keys.ENTER)# 使用 Backspace 来删除一个字符
driver.find_element_by_id('xxx').send_keys(Keys.BACK_SPACE)# Ctrl + A 全选输入框中内容
driver.find_element_by_id('xxx').send_keys(Keys.CONTROL,'a')# Ctrl + C 复制输入框中内容
driver.find_element_by_id('xxx').send_keys(Keys.CONTROL,'c')# Ctrl + V 粘贴输入框中内容
driver.find_element_by_id('xxx').send_keys(Keys.CONTROL,'v')
其他常见键盘操作:
操作描述
Keys.F1
F1键
Keys.SPACE
空格
Keys.TAB
Tab键
Keys.ESCAPE
ESC键
Keys.ALT
Alt键
Keys.SHIFT
Shift键
Keys.ARROW_DOWN
向下箭头
Keys.ARROW_LEFT
向左箭头
Keys.ARROW_RIGHT
向右箭头
Keys.ARROW_UP
向上箭头
设置元素等待
很多页面都使用
ajax
技术,页面的元素不是同时被加载出来的,为了防止定位这些尚在加载的元素报错,可以设置元素等来增加脚本的稳定性。
webdriver
中的等待分为 显式等待 和 隐式等待。
显式等待
显式等待:设置一个超时时间,每个一段时间就去检测一次该元素是否存在,如果存在则执行后续内容,如果超过最大时间(超时时间)则抛出超时异常(
TimeoutException
)。显示等待需要使用
WebDriverWait
,同时配合
until
或
not until
。下面详细讲解一下。
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
driver:浏览器驱动timeout:超时时间,单位秒poll_frequency:每次检测的间隔时间,默认为0.5秒ignored_exceptions:指定忽略的异常,如果在调用until或until_not的过程中抛出指定忽略的异常,则不中断代码,默认忽略的只有NoSuchElementException。
until(method, message=’ ‘)
until_not(method, message=’ ')
method:指定预期条件的判断方法,在等待期间,每隔一段时间调用该方法,判断元素是否存在,直到元素出现。until_not正好相反,当元素消失或指定条件不成立,则继续执行后续代码message: 如果超时,抛出TimeoutException,并显示message中的内容
method
中的预期条件判断方法是由
expected_conditions
提供,下面列举常用方法。
先定义一个定位器
from selenium.webdriver.common.by import By
from selenium import webdriver
driver = webdriver.Chrome()
locator =(By.ID,'kw')
element = driver.find_element_by_id('kw')
方法描述title_is(‘百度一下’)判断当前页面的 title 是否等于预期title_contains(‘百度’)判断当前页面的 title 是否包含预期字符串presence_of_element_located(locator)判断元素是否被加到了 dom 树里,并不代表该元素一定可见visibility_of_element_located(locator)判断元素是否可见,可见代表元素非隐藏,并且元素的宽和高都不等于0visibility_of(element)跟上一个方法作用相同,但传入参数为 elementtext_to_be_present_in_element(locator , ‘百度’)判断元素中的 text 是否包含了预期的字符串text_to_be_present_in_element_value(locator , ‘某值’)判断元素中的 value 属性是否包含了预期的字符串frame_to_be_available_and_switch_to_it(locator)判断该 frame 是否可以 switch 进去,True 则 switch 进去,反之 Falseinvisibility_of_element_located(locator)判断元素中是否不存在于 dom 树或不可见element_to_be_clickable(locator)判断元素中是否可见并且是可点击的staleness_of(element)等待元素从 dom 树中移除element_to_be_selected(element)判断元素是否被选中,一般用在下拉列表element_selection_state_to_be(element, True)判断元素的选中状态是否符合预期,参数 element,第二个参数为 True/Falseelement_located_selection_state_to_be(locator, True)跟上一个方法作用相同,但传入参数为 locatoralert_is_present()判断页面上是否存在 alert
下面写一个简单的例子,这里定位一个页面不存在的元素,抛出的异常信息正是我们指定的内容。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
element = WebDriverWait(driver,5,0.5).until(
EC.presence_of_element_located((By.ID,'kw')),
message='超时啦!')

隐式等待
隐式等待也是指定一个超时时间,如果超出这个时间指定元素还没有被加载出来,就会抛出
NoSuchElementException
异常。
除了抛出的异常不同外,还有一点,隐式等待是全局性的,即运行过程中,如果元素可以定位到,它不会影响代码运行,但如果定位不到,则它会以轮询的方式不断地访问元素直到元素被找到,若超过指定时间,则抛出异常。
使用
implicitly_wait()
来实现隐式等待,使用难度相对于显式等待要简单很多。
示例:打开个人主页,设置一个隐式等待时间 5s,通过
id
定位一个不存在的元素,最后打印 抛出的异常 与 运行时间。
from selenium import webdriver
from time import time
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/qq_43965708')
start = time()
driver.implicitly_wait(5)try:
driver.find_element_by_id('kw')except Exception as e:print(e)print(f'耗时:{time()-start}')

代码运行到
driver.find_element_by_id('kw')
这句之后触发隐式等待,在轮询检查 5s 后仍然没有定位到元素,抛出异常。
强制等待
使用
time.sleep()
强制等待,设置固定的休眠时间,对于代码的运行效率会有影响。以上面的例子作为参照,将 隐式等待 改为 强制等待。
from selenium import webdriver
from time import time, sleep
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/qq_43965708')
start = time()
sleep(5)try:
driver.find_element_by_id('kw')except Exception as e:print(e)print(f'耗时:{time()-start}')

值得一提的是,对于定位不到元素的时候,从耗时方面隐式等待和强制等待没什么区别。但如果元素经过 2s 后被加载出来,这时隐式等待就会继续执行下面的代码,但 sleep还要继续等待 3s。
定位一组元素
上篇讲述了定位一个元素的 8 种方法,定位一组元素使用的方法只需要将
element
改为
elements
即可,它的使用场景一般是为了批量操作元素。
find_elements_by_id()find_elements_by_name()find_elements_by_class_name()find_elements_by_tag_name()find_elements_by_xpath()find_elements_by_css_selector()find_elements_by_link_text()find_elements_by_partial_link_text()
这里以 CSDN 首页的一个 博客专家栏 为例。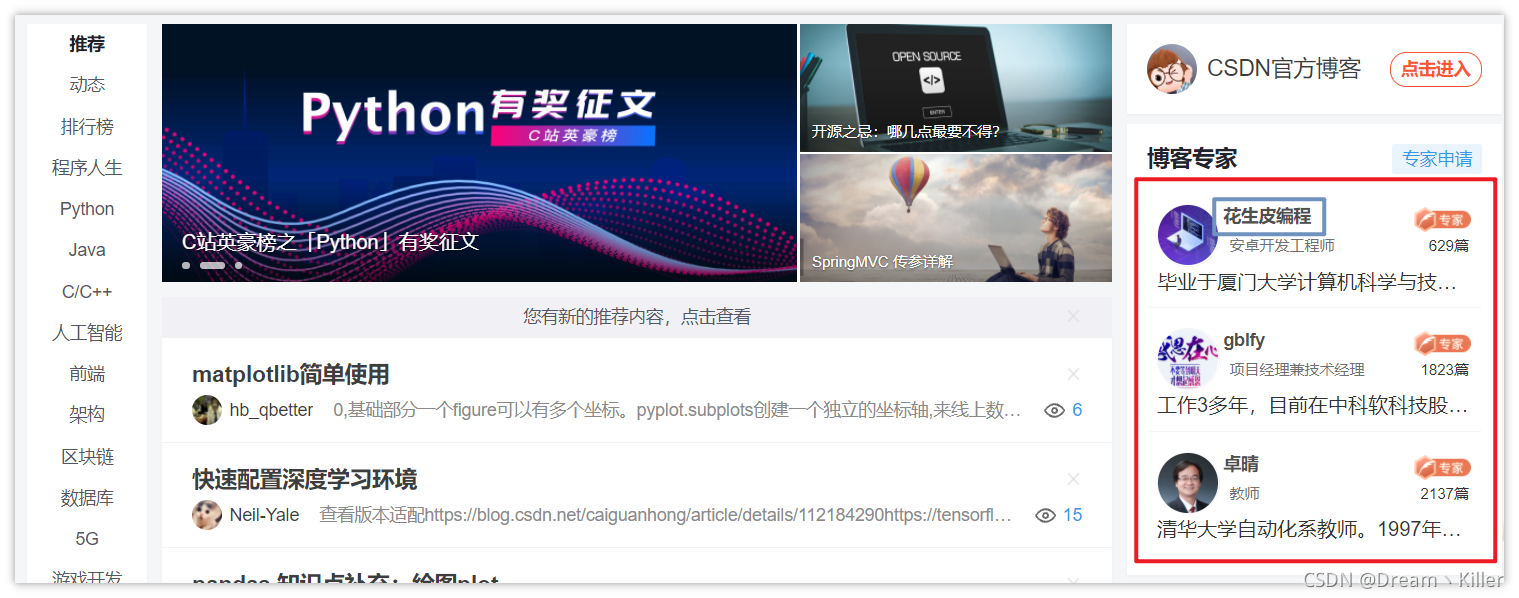
下面使用
find_elements_by_xpath
来定位三位专家的名称。
这是专家名称部分的页面代码,不知各位有没有想到如何通过
xpath
定位这一组专家的名称呢?
from selenium import webdriver
# 设置无头浏览器
option = webdriver.ChromeOptions()
option.add_argument('--headless')
driver = webdriver.Chrome(options=option)
driver.get('https://blog.csdn.net/')
p_list = driver.find_elements_by_xpath("//p[@class='name']")
name =[p.text for p in p_list]
name

切换操作
窗口切换
在
selenium
操作页面的时候,可能会因为点击某个链接而跳转到一个新的页面(打开了一个新标签页),这时候
selenium
实际还是处于上一个页面的,需要我们进行切换才能够定位最新页面上的元素。
窗口切换需要使用
switch_to.windows()
方法。
首先我们先看看下面的代码。
代码流程:先进入 【CSDN首页】,保存当前页面的句柄,然后再点击左侧 【CSDN官方博客】跳转进入新的标签页,再次保存页面的句柄,我们验证一下
selenium
会不会自动定位到新打开的窗口。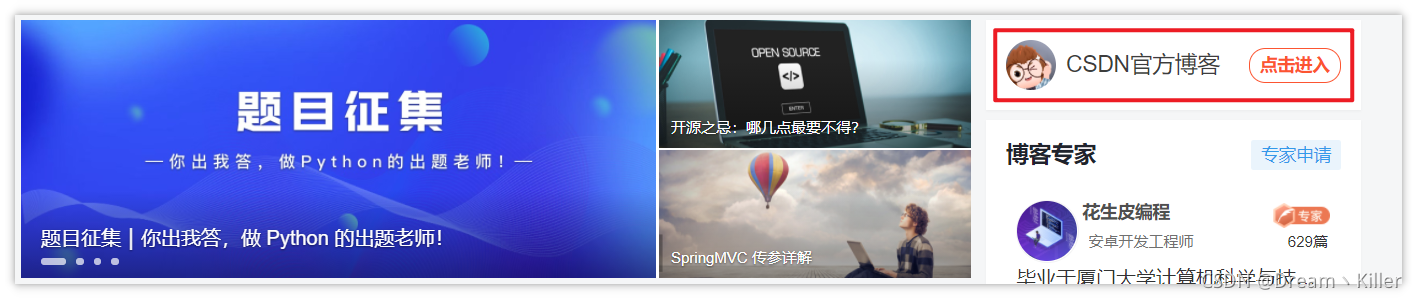
from selenium import webdriver
handles =[]
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/')# 设置隐式等待
driver.implicitly_wait(3)# 获取当前窗口的句柄
handles.append(driver.current_window_handle)# 点击 python,进入分类页面
driver.find_element_by_xpath('//*[@id="mainContent"]/aside/div[1]/div').click()# 获取当前窗口的句柄
handles.append(driver.current_window_handle)print(handles)# 获取当前所有窗口的句柄print(driver.window_handles)

可以看到第一个列表
handle
是相同的,说明
selenium
实际操作的还是 CSDN首页 ,并未切换到新页面。
下面使用
switch_to.windows()
进行切换。
from selenium import webdriver
handles =[]
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/')# 设置隐式等待
driver.implicitly_wait(3)# 获取当前窗口的句柄
handles.append(driver.current_window_handle)# 点击 python,进入分类页面
driver.find_element_by_xpath('//*[@id="mainContent"]/aside/div[1]/div').click()# 切换窗口
driver.switch_to.window(driver.window_handles[-1])# 获取当前窗口的句柄
handles.append(driver.current_window_handle)print(handles)print(driver.window_handles)

上面代码在点击跳转后,使用
switch_to
切换窗口,**
window_handles
返回的
handle
列表是按照页面出现时间进行排序的**,最新打开的页面肯定是最后一个,这样用
driver.window_handles[-1]
+
switch_to
即可跳转到最新打开的页面了。
那如果打开的窗口有多个,如何跳转到之前打开的窗口,如果确实有这个需求,那么打开窗口是就需要记录每一个窗口的
key
(别名) 与
value
(
handle
),保存到字典中,后续根据
key
来取
handle
。
表单切换
很多页面也会用带
frame/iframe
表单嵌套,对于这种内嵌的页面
selenium
是无法直接定位的,需要使用
switch_to.frame()
方法将当前操作的对象切换成
frame/iframe
内嵌的页面。
switch_to.frame()
默认可以用的
id
或
name
属性直接定位,但如果
iframe
没有
id
或
name
,这时就需要使用
xpath
进行定位。下面先写一个包含
iframe
的页面做测试用。
<!DOCTYPE html><htmllang="en"><head><metacharset="UTF-8"><metahttp-equiv="X-UA-Compatible"content="IE=edge"><metaname="viewport"content="width=device-width, initial-scale=1.0"><title>Document</title><style>div p{color: #red;animation: change 2s infinite;}@keyframes change{from{color: red;}to{color: blue;}}</style></head><body><div><p>公众号:Python新视野</p><p>CSDN:Dream丶Killer</p><p>微信:python-sun</p></div><iframesrc="https://blog.csdn.net/qq_43965708"width="400"height="200"></iframe><!-- <iframe id="CSDN_info" name="Dream丶Killer" src="https://blog.csdn.net/qq_43965708" width="400" height="200"></iframe> --></body></html>
现在我们定位红框中的 CSDN 按钮,可以跳转到 CSDN 首页。
from selenium import webdriver
from pathlib import Path
driver = webdriver.Chrome()# 读取本地html文件
driver.get('file:///'+str(Path(Path.cwd(),'iframe测试.html')))# 1.通过id定位
driver.switch_to.frame('CSDN_info')# 2.通过name定位# driver.switch_to.frame('Dream丶Killer')# 通过xpath定位# 3.iframe_label = driver.find_element_by_xpath('/html/body/iframe')# driver.switch_to.frame(iframe_label)
driver.find_element_by_xpath('//*[@id="csdn-toolbar"]/div/div/div[1]/div/a/img').click()
这里列举了三种定位方式,都可以定位
iframe
。
弹窗处理
JavaScript
有三种弹窗
alert
(确认)、
confirm
(确认、取消)、
prompt
(文本框、确认、取消)。
处理方式:先定位(
switch_to.alert
自动获取当前弹窗),再使用
text
、
accept
、
dismiss
、
send_keys
等方法进行操作
方法描述
text
获取弹窗中的文字
accept
接受(确认)弹窗内容
dismiss
解除(取消)弹窗
send_keys
发送文本至警告框
这里写一个简单的测试页面,其中包含三个按钮,分别对应三个弹窗。
<!DOCTYPE html><htmllang="en"><head></head><body><buttonid="alert">alert</button><buttonid="confirm">confirm</button><buttonid="prompt">prompt</button><scripttype="text/javascript">const dom1 = document.getElementById("alert")
dom1.addEventListener('click',function(){alert("alert hello")})const dom2 = document.getElementById("confirm")
dom2.addEventListener('click',function(){confirm("confirm hello")})const dom3 = document.getElementById("prompt")
dom3.addEventListener('click',function(){prompt("prompt hello")})</script></body></html>

下面使用上面的方法进行测试。为了防止弹窗操作过快,每次操作弹窗,都使用
sleep
强制等待一段时间。
from selenium import webdriver
from pathlib import Path
from time import sleep
driver = webdriver.Firefox()
driver.get('file:///'+str(Path(Path.cwd(),'弹窗.html')))
sleep(2)# 点击alert按钮
driver.find_element_by_xpath('//*[@id="alert"]').click()
sleep(1)
alert = driver.switch_to.alert
# 打印alert弹窗的文本print(alert.text)# 确认
alert.accept()
sleep(2)# 点击confirm按钮
driver.find_element_by_xpath('//*[@id="confirm"]').click()
sleep(1)
confirm = driver.switch_to.alert
print(confirm.text)# 取消
confirm.dismiss()
sleep(2)# 点击confirm按钮
driver.find_element_by_xpath('//*[@id="prompt"]').click()
sleep(1)
prompt = driver.switch_to.alert
print(prompt.text)# 向prompt的输入框中传入文本
prompt.send_keys("Dream丶Killer")
sleep(2)
prompt.accept()'''输出
alert hello
confirm hello
prompt hello
'''

注:细心地读者应该会发现这次操作的浏览器是
Firefox,为什么不用
Chrome呢?原因是测试时发现执行
prompt的
send_keys时,不能将文本填入输入框。尝试了各种方法并查看源码后确认不是代码的问题,之后通过其他渠道得知原因可能是
Chrome的版本与
selenium版本的问题,但也没有很方便的解决方案,因此没有继续深究,改用
Firefox可成功运行。这里记录一下我的
Chrome版本,如果有大佬懂得如何在
Chrome上解决这个问题,请在评论区指导一下,提前感谢!
selenium:3.141.0
Chrome:94.0.4606.71

上传 & 下载文件
上传文件
常见的 web 页面的上传,一般使用
input
标签或是插件(
JavaScript
、
Ajax
),对于
input
标签的上传,可以直接使用
send_keys(路径)
来进行上传。
先写一个测试用的页面。
<!DOCTYPE html><htmllang="en"><head><metacharset="UTF-8"><metahttp-equiv="X-UA-Compatible"content="IE=edge"><metaname="viewport"content="width=device-width, initial-scale=1.0"><title>Document</title></head><body><inputtype="file"name=""></body></html>

下面通过
xpath
定位
input
标签,然后使用
send_keys(str(file_path)
上传文件。
from selenium import webdriver
from pathlib import Path
from time import sleep
driver = webdriver.Chrome()
file_path = Path(Path.cwd(),'上传下载.html')
driver.get('file:///'+str(file_path))
driver.find_element_by_xpath('//*[@name="upload"]').send_keys(str(file_path))

下载文件
Chrome浏览器
Firefox
浏览器要想实现文件下载,需要通过
add_experimental_option
添加
prefs
参数。
download.default_directory:设置下载路径。profile.default_content_settings.popups:0 禁止弹出窗口。
下面测试下载搜狗图片。指定保存路径为代码所在路径。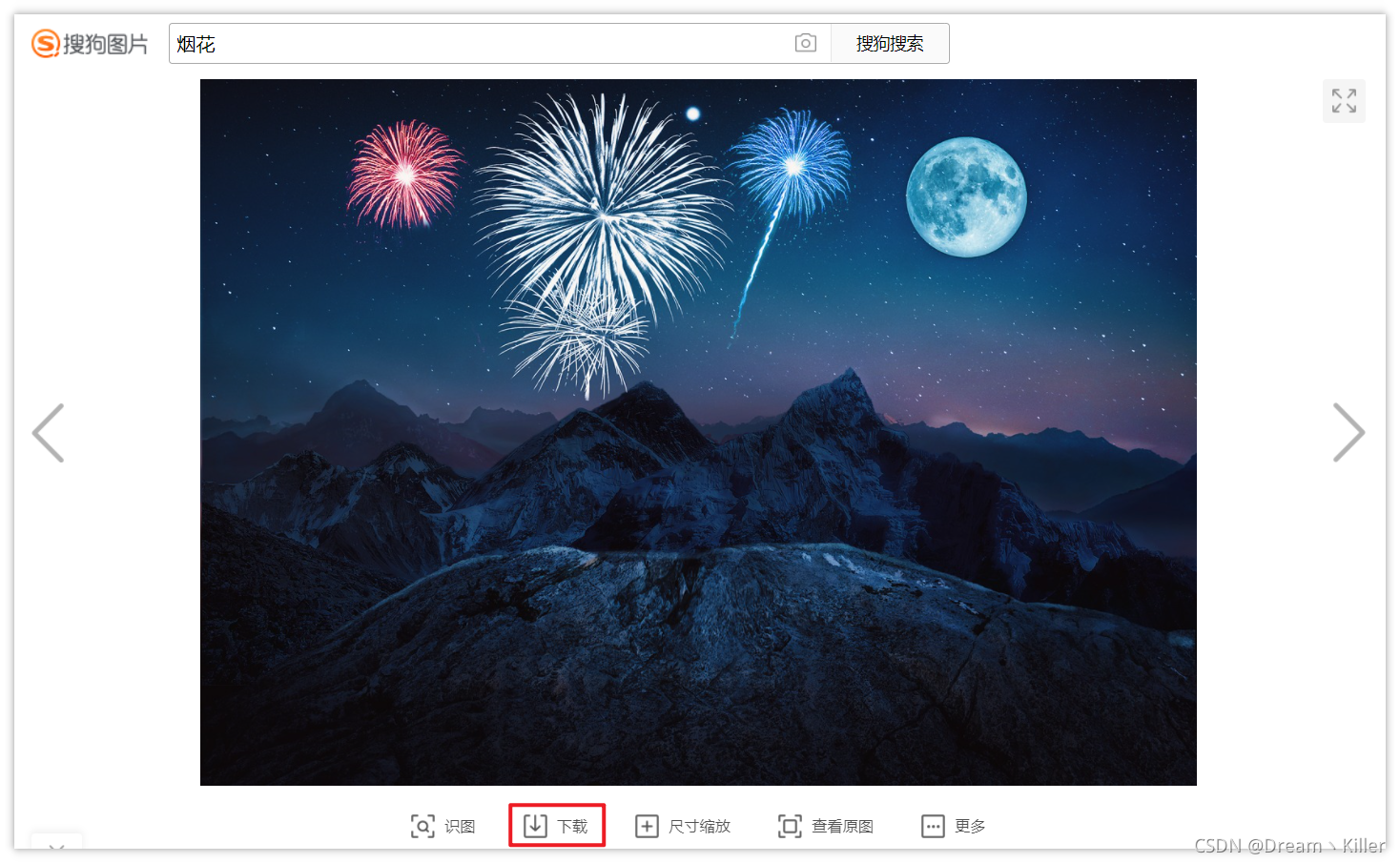
from selenium import webdriver
prefs ={'profile.default_content_settings.popups':0,'download.default_directory':str(Path.cwd())}
option = webdriver.ChromeOptions()
option.add_experimental_option('prefs', prefs)
driver = webdriver.Chrome(options=option)
driver.get("https://pic.sogou.com/d?query=%E7%83%9F%E8%8A%B1&did=4&category_from=copyright")
driver.find_element_by_xpath('/html/body/div/div/div/div[2]/div[1]/div[2]/div[1]/div[2]/a').click()
driver.switch_to.window(driver.window_handles[-1])
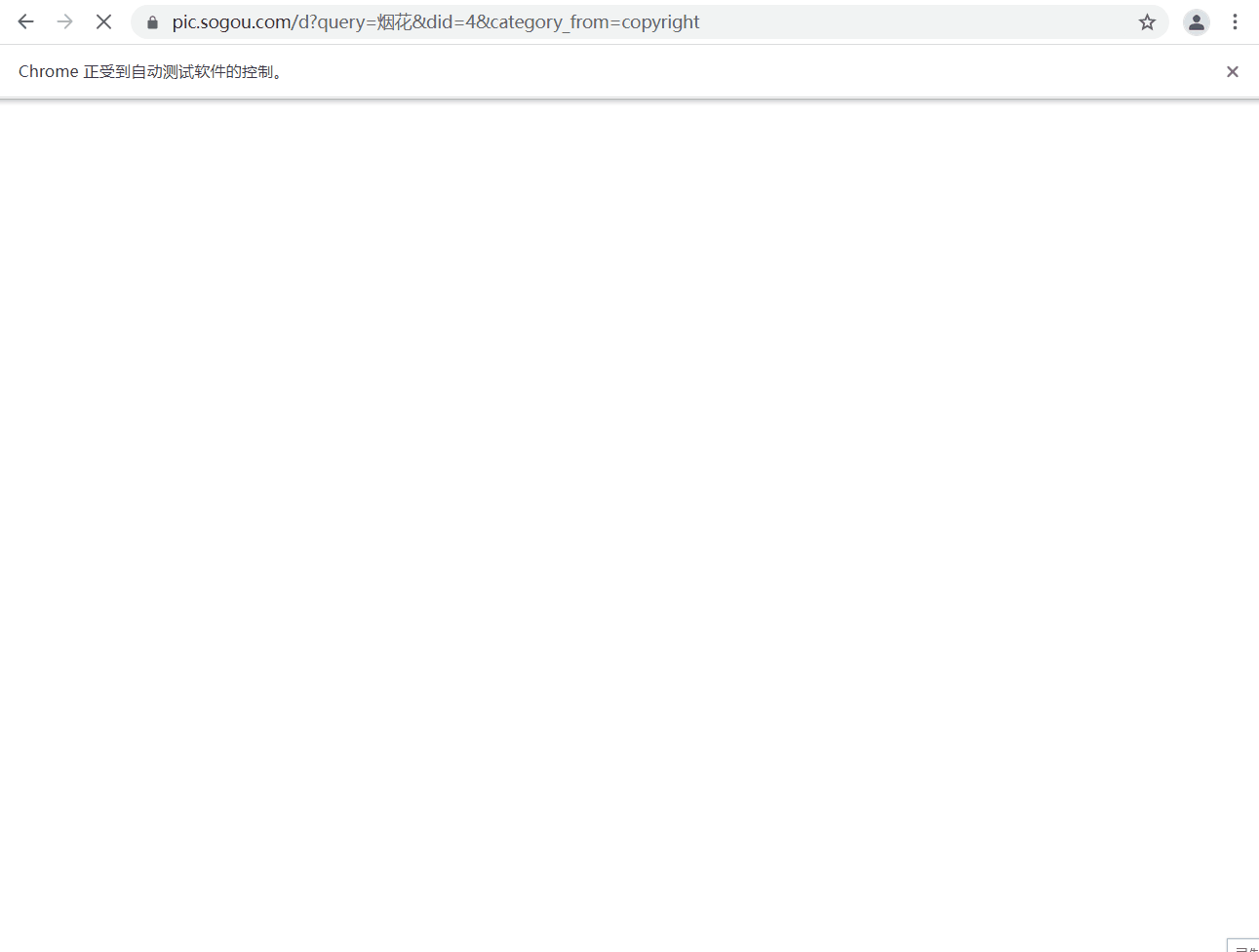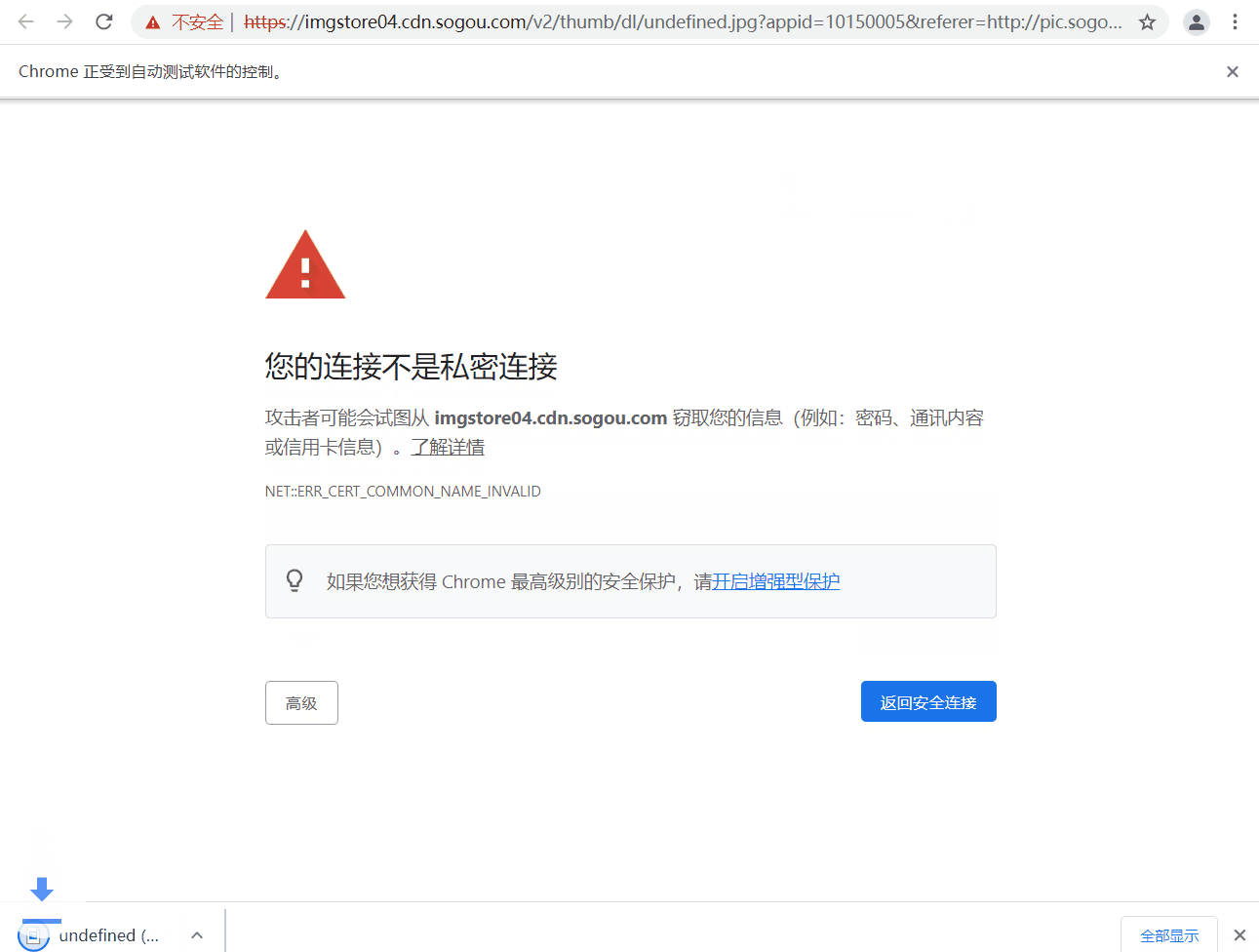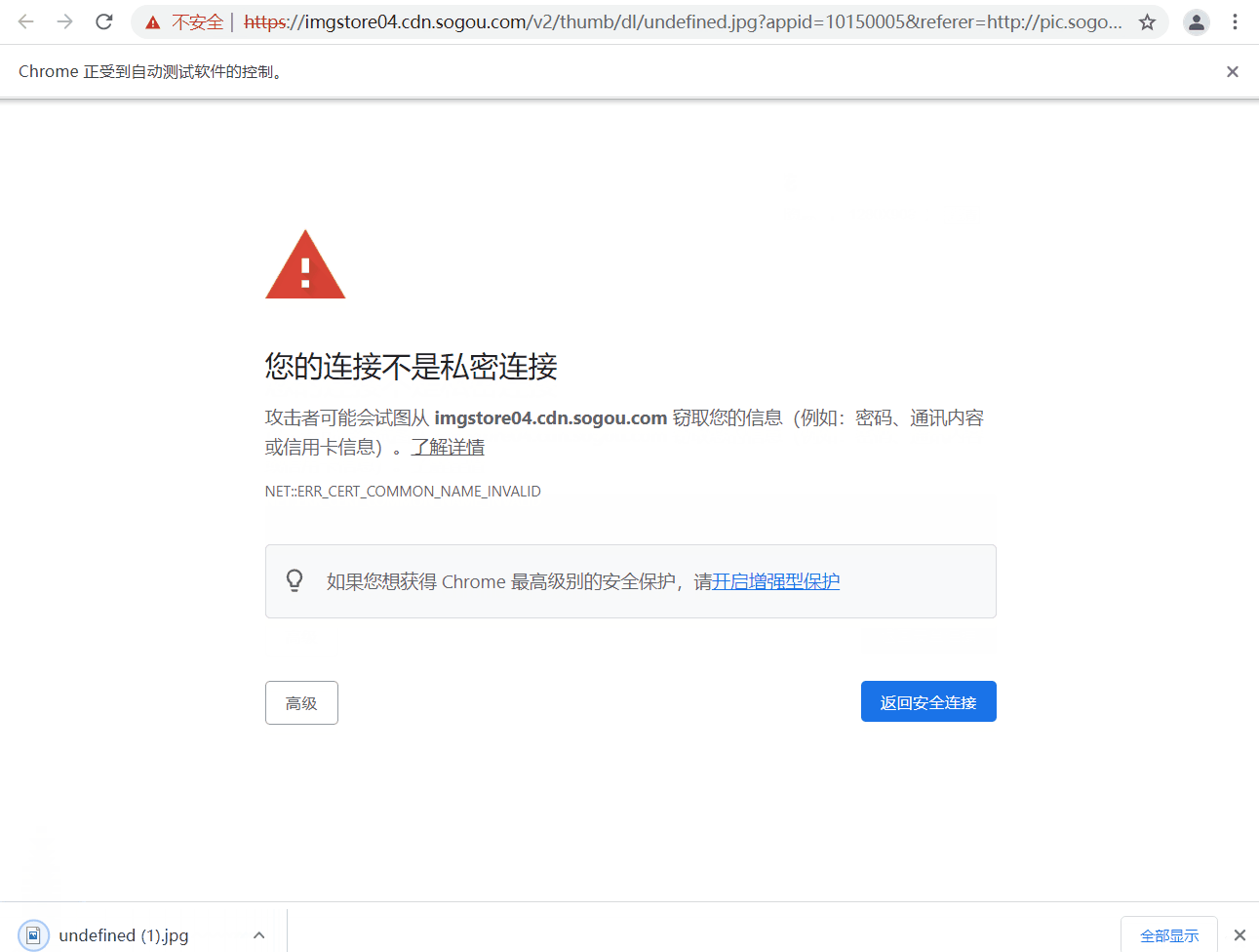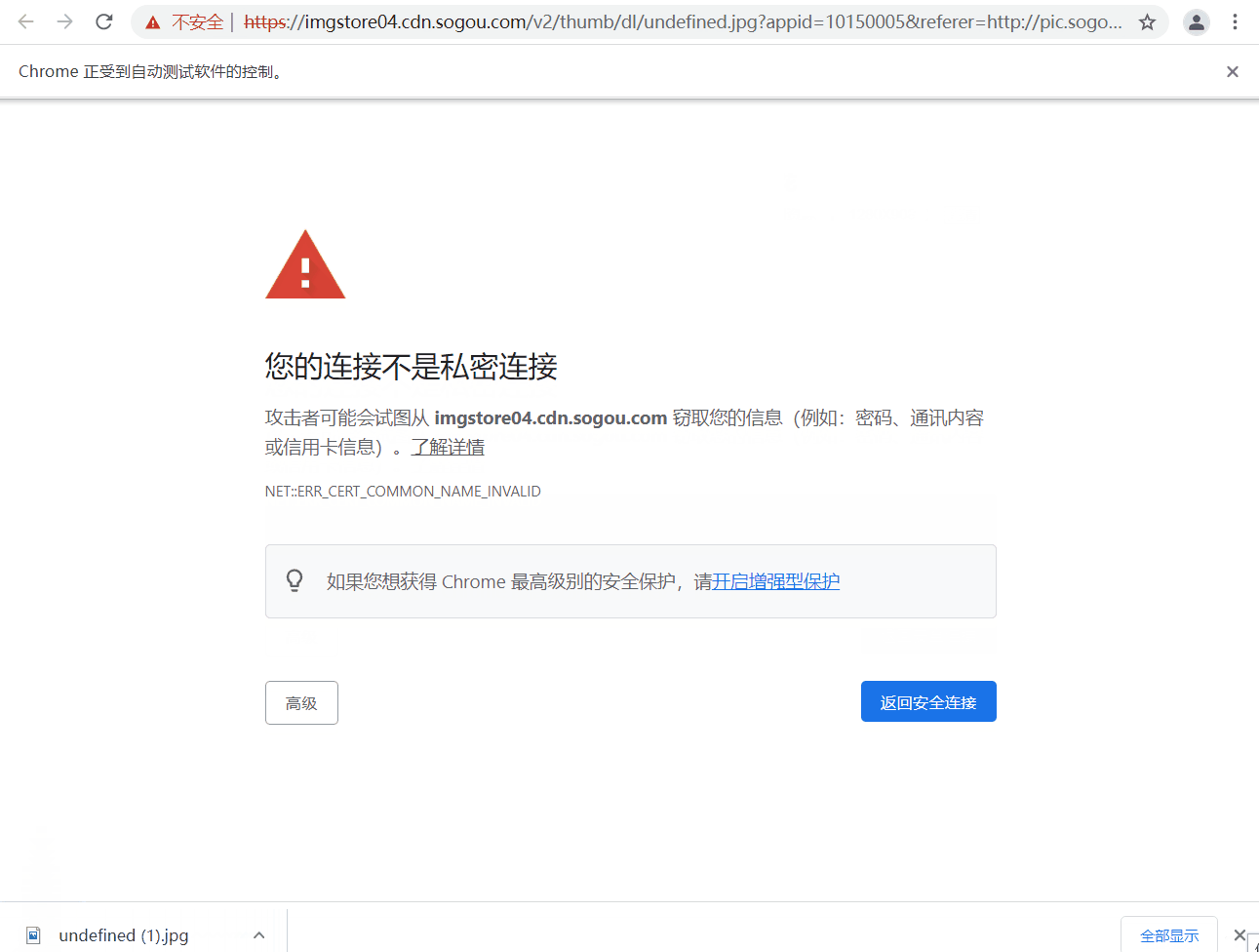
driver.find_element_by_xpath('./html').send_keys('thisisunsafe')
代码最后两句猜测有理解什么意思的吗~,哈哈,实际作用是当你弹出像下面的页面 “您的连接不是私密连接” 时,可以直接键盘输入 “thisisunsafe” 直接访问链接。那么这个键盘输入字符串的操作就是之间讲到的
send_keys,但由于该标签页是新打开的,所以要通过
switch_to.window()将窗口切换到最新的标签页。
Firefox浏览器
Firefox
浏览器要想实现文件下载,需要通过
set_preference
设置
FirefoxProfile()
的一些属性。
browser.download.foladerList:0 代表按浏览器默认下载路径;2 保存到指定的目录。browser.download.dir:指定下载目录。browser.download.manager.showWhenStarting:是否显示开始,boolean类型。browser.helperApps.neverAsk.saveToDisk:对指定文件类型不再弹出框进行询问。- HTTP Content-type对照表:https://www.runoob.com/http/http-content-type.html
from selenium import webdriver
import os
fp = webdriver.FirefoxProfile()
fp.set_preference("browser.download.dir",os.getcwd())
fp.set_preference("browser.download.folderList",2)
fp.set_preference("browser.download.manager.showhenStarting",True)
fp.set_preference("browser.helperApps.neverAsk.saveToDisk","application/octet-stream")
driver = webdriver.Firefox(firefox_profile = fp)
driver.get("https://pic.sogou.com/d?query=%E7%83%9F%E8%8A%B1&did=4&category_from=copyright")
driver.find_element_by_xpath('/html/body/div/div/div/div[2]/div[1]/div[2]/div[1]/div[2]/a').click()
运行效果与
Chrome
基本一致,这里就不再展示了。
cookies操作
cookies
是识别用户登录与否的关键,爬虫中常常使用
selenium + requests
实现
cookie
持久化,即先用
selenium
模拟登陆获取
cookie
,再通过
requests
携带
cookie
进行请求。
webdriver
提供
cookies
的几种操作:读取、添加删除。
get_cookies:以字典的形式返回当前会话中可见的cookie信息。get_cookie(name):返回cookie字典中key == name的cookie信息。add_cookie(cookie_dict):将cookie添加到当前会话中delete_cookie(name):删除指定名称的单个cookie。delete_all_cookies():删除会话范围内的所有cookie。
下面看一下简单的示例,演示了它们的用法。
from selenium import webdriver
driver = webdriver.Chrome()
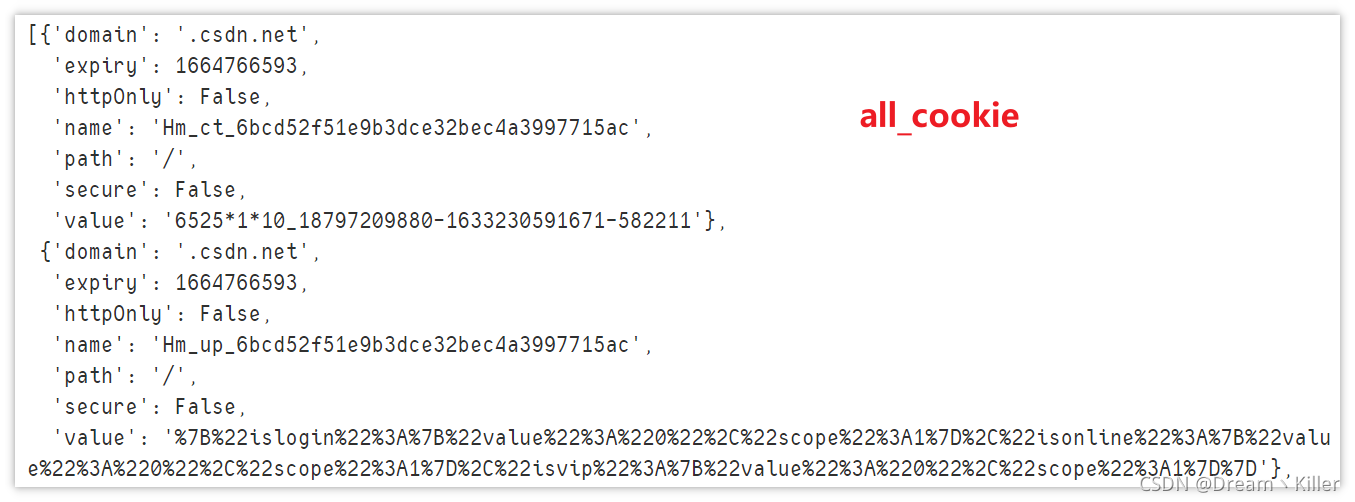
driver.get("https://blog.csdn.net/")# 输出所有cookie信息print(driver.get_cookies())
cookie_dict ={'domain':'.csdn.net','expiry':1664765502,'httpOnly':False,'name':'test','path':'/','secure':True,'value':'null'}# 添加cookie
driver.add_cookie(cookie_dict)# 显示 name = 'test' 的cookie信息print(driver.get_cookie('test'))# 删除 name = 'test' 的cookie信息
driver.delete_cookie('test')# 删除当前会话中的所有cookie
driver.delete_all_cookies()

调用JavaScript
webdriver
对于滚动条的处理需要用到
JavaScript
,同时也可以向
textarea
文本框中输入文本(
webdriver
只能定位,不能输入文本),
webdriver
中使用execute_script方法实现
JavaScript
的执行。
滑动滚动条
通过 x ,y 坐标滑动
对于这种通过坐标滑动的方法,我们需要知道做表的起始位置在页面左上角(0,0),下面看一下示例,滑动 CSDN 首页。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("https://blog.csdn.net/")
sleep(1)
js ="window.scrollTo(0,500);"
driver.execute_script(js)
通过参照标签滑动
这种方式需要先找一个参照标签,然后将滚动条滑动至该标签的位置。下面还是用 CSDN 首页做示例,我们用循环来实现重复滑动。该
li
标签实际是一种懒加载,当用户滑动至最后标签时,才会加载后面的数据。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("https://blog.csdn.net/")
sleep(1)
driver.implicitly_wait(3)for i inrange(31,102,10):
sleep(1)
target = driver.find_element_by_xpath(f'//*[@id="feedlist_id"]/li[{i}]')
driver.execute_script("arguments[0].scrollIntoView();", target)
其他操作
关闭所有页面
使用
quit()
方法可以关闭所有窗口并退出驱动程序。
driver.quit()
关闭当前页面
使用
close()
方法可以关闭当前页面,使用时要注意 “当前页面” 这四个字,当你关闭新打开的页面时,需要切换窗口才能操作新窗口并将它关闭。,下面看一个简单的例子,这里不切换窗口,看一下是否能够关闭新打开的页面。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/')
driver.implicitly_wait(3)# 点击进入新页面
driver.find_element_by_xpath('//*[@id="mainContent"]/aside/div[1]/div').click()# 切换窗口# driver.switch_to.window(driver.window_handles[-1])
sleep(3)
driver.close()
可以看到,在不切换窗口时,
driver
对象还是操作最开始的页面。
对当前页面进行截图
wendriver
中使用
get_screenshot_as_file()
对 “当前页面” 进行截图,这里和上面的
close()
方法一样,对于新窗口的操作,一定要切换窗口,不然截的还是原页面的图。对页面截图这一功能,主要用在我们测试时记录报错页面的,我们可以将
try except
结合
get_screenshot_as_file()
一起使用来实现这一效果。
try:
driver.find_element_by_xpath('//*[@id="mainContent"]/aside/div[1]/div').click()except:
driver.get_screenshot_as_file(r'C:\Users\pc\Desktop\screenshot.png')
常用方法总结
# 获取当前页面url
driver.current_url
# 获取当前html源码
driver.page_source
# 获取当前页面标题
driver.title
# 获取浏览器名称(chrome)
driver.name
# 对页面进行截图,返回二进制数据
driver.get_screenshot_as_png()# 设置浏览器尺寸
driver.get_window_size()# 获取浏览器尺寸,位置
driver.get_window_rect()# 获取浏览器位置(左上角)
driver.get_window_position()# 设置浏览器尺寸
driver.set_window_size(width=1000, height=600)# 设置浏览器位置(左上角)
driver.set_window_position(x=500, y=600)# 设置浏览器的尺寸,位置
driver.set_window_rect(x=200, y=400, width=1000, height=600)
selenium进阶
selenium隐藏指纹特征
selenium
对于部分网站来说十分强大,但它也不是万能的,实际上,
selenium
启动的浏览器,有几十个特征可以被网站检测到,轻松的识别出你是爬虫。
不相信?接着往下看,首先你手动打开浏览器输入https://bot.sannysoft.com/,在网络无异常的情况下,显示应该如下: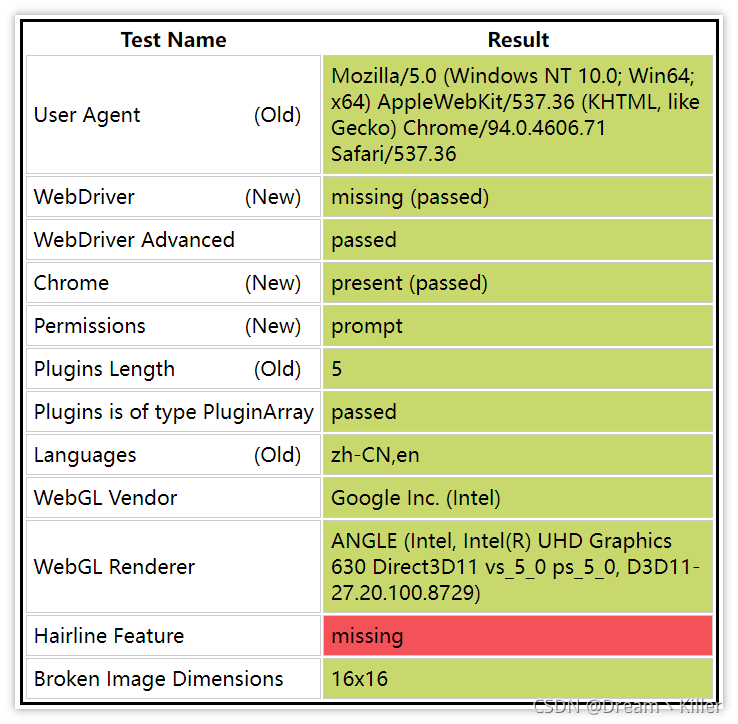
下面通过
selenium
来打开浏览器。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://bot.sannysoft.com/')
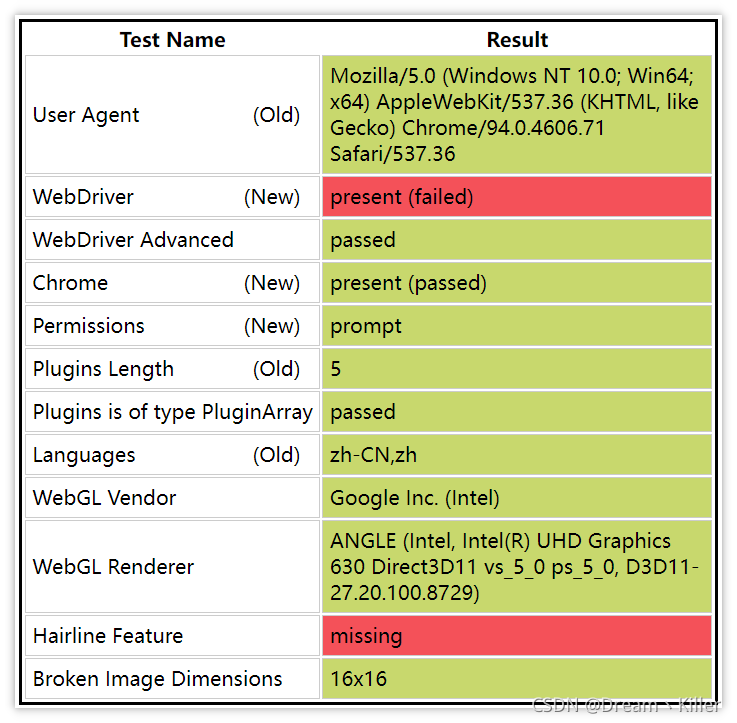
通过
webdriver:present
可以看到浏览器已经识别出了你是爬虫,我们再试一下无头浏览器。
from selenium import webdriver
# 设置无头浏览器
option = webdriver.ChromeOptions()
option.add_argument('--headless')
driver = webdriver.Chrome()
driver.get('https://bot.sannysoft.com/')# 对当前页面进行截图
driver.save_screenshot('page.png')

没错,就是这么真实,对于常规网站可能没什么反爬,但真正想要抓你还是一抓一个准的。
说了这么多,是不是
selenium
真的不行?别着急,实际还是解决方法的。关键点在于如何在浏览器检测之前将这些特征进行隐藏,事实上,前人已经为我们铺好了路,解决这个问题的关键,实际就是一个
stealth.min.js
文件,这个文件是给
puppeteer
用的,在
Python
中使用的话需要单独执行这个文件,该文件获取方式需要安装
node.js
,如果已安装的读者可以直接运行如下命令即可在当前目录生成该文件。
npx extract-stealth-evasions
这里我已经成功获取了
stealth.min.js
文件。
链接:https://pan.baidu.com/s/1O6co1Exa8eks6QmKAst91g
提取码:关注文末小卡片回复“隐藏指纹特征”获取
下面我们在网站检测之前先执行该js文件隐藏特征,同样使用无头浏览器,看是否有效。
import time
from selenium.webdriver import Chrome
option = webdriver.ChromeOptions()
option.add_argument("--headless")# 无头浏览器需要添加user-agent来隐藏特征
option.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36')
driver = Chrome(options=option)
driver.implicitly_wait(5)withopen('stealth.min.js')as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument",{"source": js
})
driver.get('https://bot.sannysoft.com/')
driver.save_screenshot('hidden_features.png')
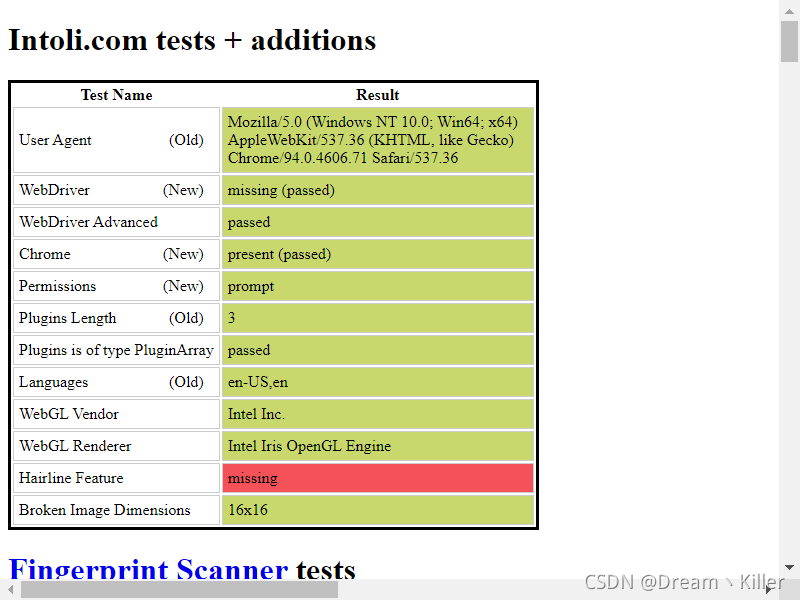
通过
stealth.min.js
的隐藏,可以看到这次使用无头浏览器特征基本都以隐藏,已经十分接近人工打开浏览器了。
实战:selenium模拟登录B站
登录验证码处理
selenium
中的难点验证码破解在上文中并没有提及,因为确实没有很好的方式,一般都需要通过第三方平台实现破解,本案例中使用的是超级鹰平台(收费,大概1元30次,测试用冲个1元就足够)。下面实战开始!
分析登录界面结构
B站登录界面如下。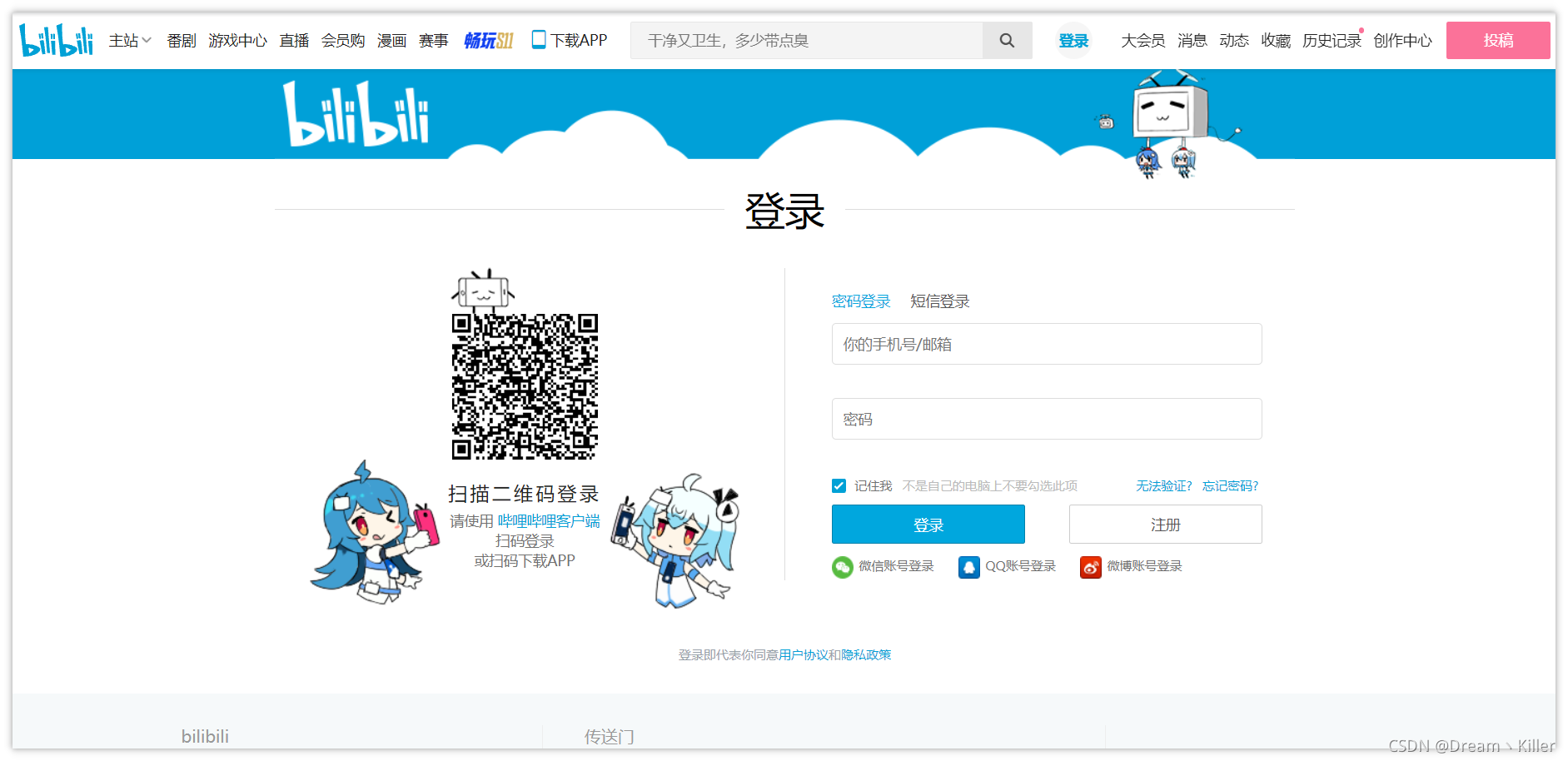
首先明确我们的目标,打开登陆界面,定位用户名和密码对应的标签,输入相关数据后,点击登录,此时页面会弹出文字验证码。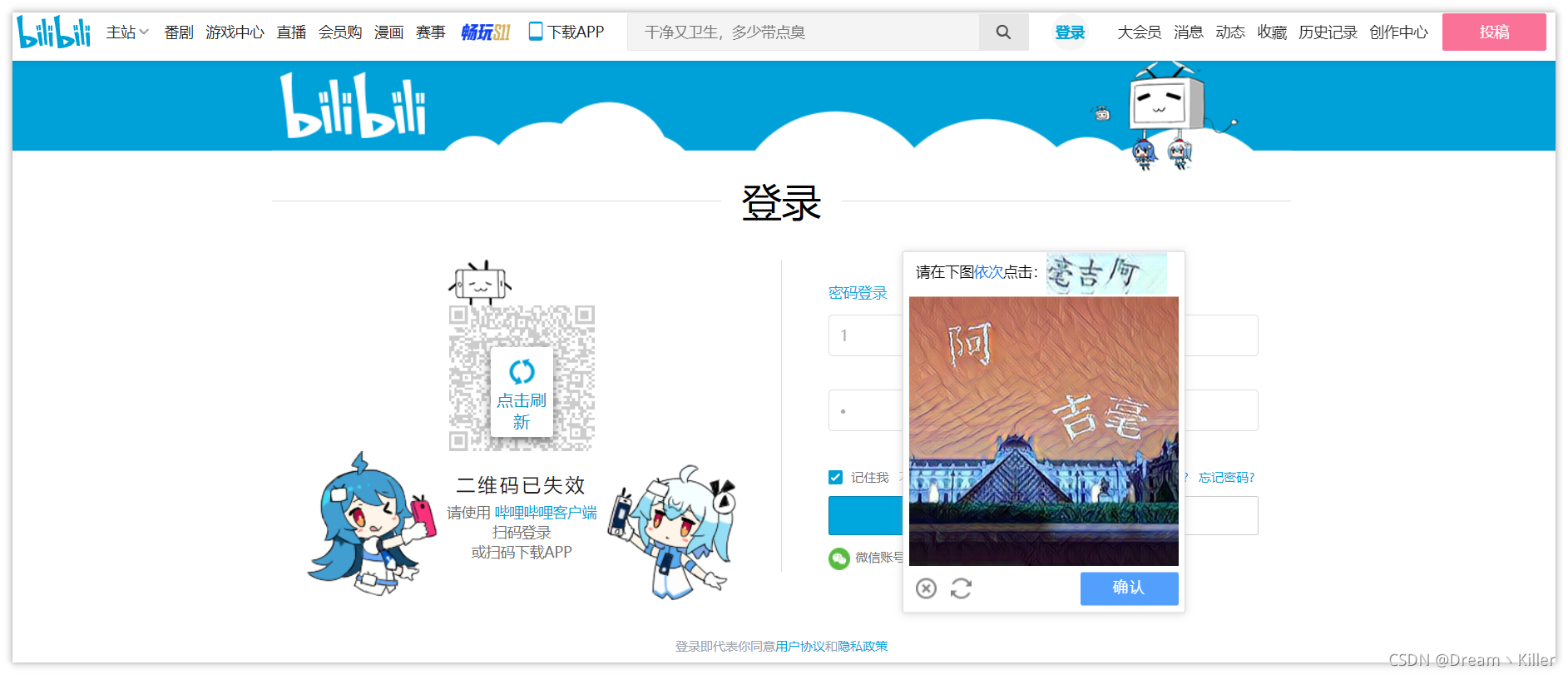
下文会用两种方法进行验证码图片的获取,并提交给超级鹰进行识别,接收到汉字的坐标后,处理坐标数据,然后用动作链点击对应坐标操作,完成登录。
下面使用
selenium
打开登录页面。
driver.get('https://passport.bilibili.com/login')# 定位用户名,密码输入框
username = driver.find_element_by_id('login-username')
password = driver.find_element_by_id('login-passwd')# 将自己的用户名密码替换xxxxxx
username.send_keys('xxxxxx')
password.send_keys('xxxxxx')# 定位登录按钮并点击
driver.find_element_by_xpath('//*[@id="geetest-wrap"]/div/div[5]/a[1]').click()
获取页面当前验证码图片
方法一、页面截图,将验证码区域进行裁剪保存
使用此方法时,注意我们截取验证码图片时需要截取完整,不要只截图片部分,上面文字也需要。完整验证码截图如下:
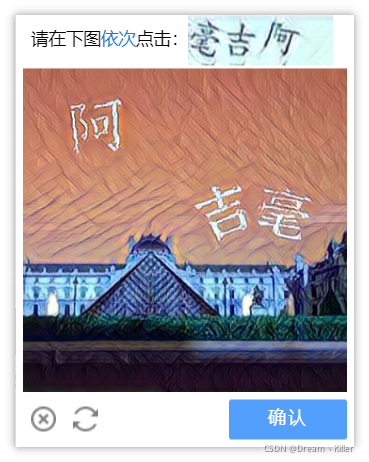
首先将点击登录后的页面进行截图,然后定位到验证码的位置,通过location()方法获取验证码左上角的坐标, size() 获取验证码的宽和高,左上角坐标加上宽和高就是验证码右下角的坐标。获取坐标后就可以用**crop()**方法来进行裁剪,然后将裁剪到的验证码图片保存。
此时虽然获取了验证码图片,但是还不能直接提交给超级鹰。
因为超级鹰识别的验证码图片的宽和高有限制,最好不超过
460px,310px
。
但是截取到的验证码图片宽高为
338px,432px
,这时就要先将图片缩小一倍再提交即可,等到收到坐标数据再将坐标乘2。
defsave_img():# 对当前页面进行截图保存
driver.save_screenshot('page.png')# 定位验证码图片的位置
code_img_ele = driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[6]/div/div')# 获取验证码左上角的坐标x,y
location = code_img_ele.location
# 获取验证码图片对应的长和宽
size = code_img_ele.size
# 左上角和右下角的坐标
rangle =(int(location['x']*1.25),int(location['y']*1.25),int((location['x']+ size['width'])*1.25),int((location['y']+ size['height'])*1.25))
i = Image.open('./page.png')
code_img_name ='./code.png'# crop根据rangle元组内的坐标进行裁剪
frame = i.crop(rangle)
frame.save(code_img_name)return code_img_ele
defnarrow_img():# 缩小图片
code = Image.open('./code.png')
small_img = code.resize((169,216))
small_img.save('./small_img.png')print(code.size, small_img.size)
方法二、通过网页获取图片地址,并保存
这种方法比上一种更加方便,分析网页源码获取图片地址,对该地址发送请求,接收返回的二进制文件,进行保存。首先打开网页源码找到图片地址。
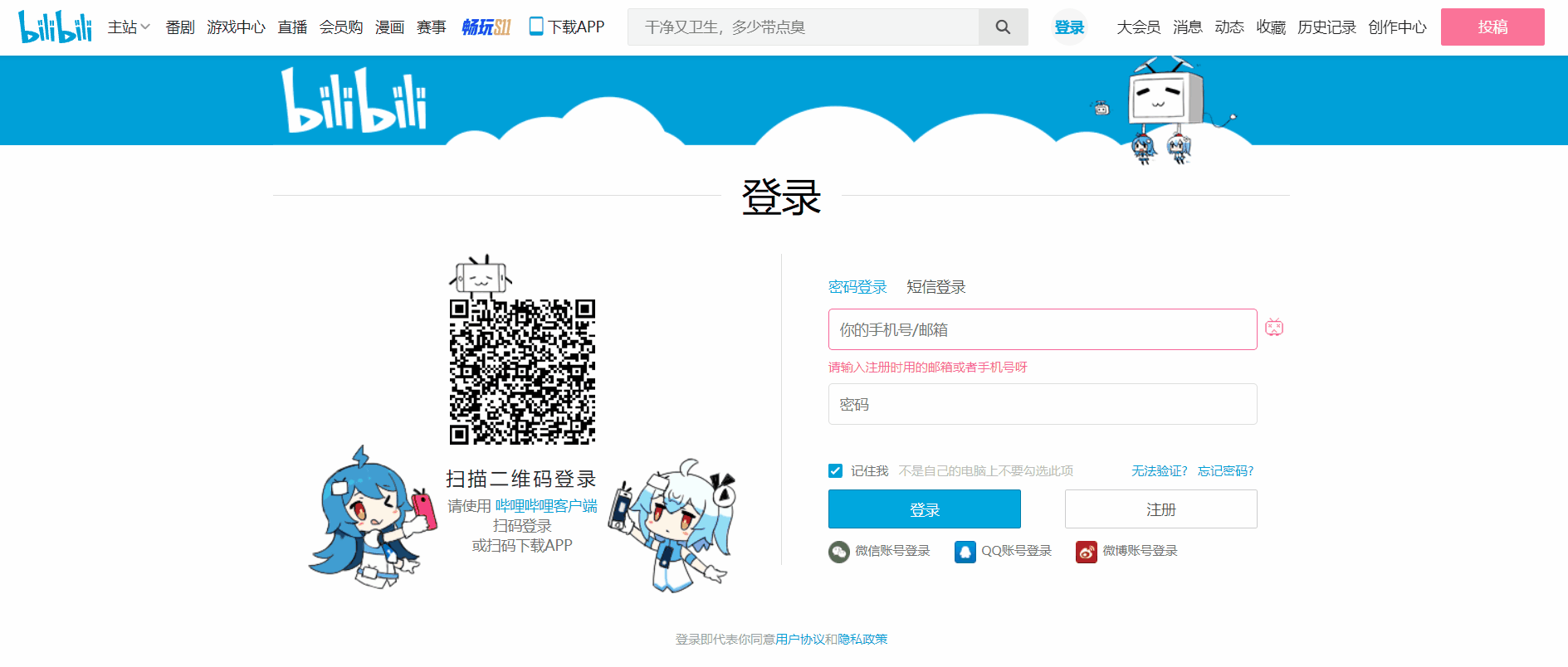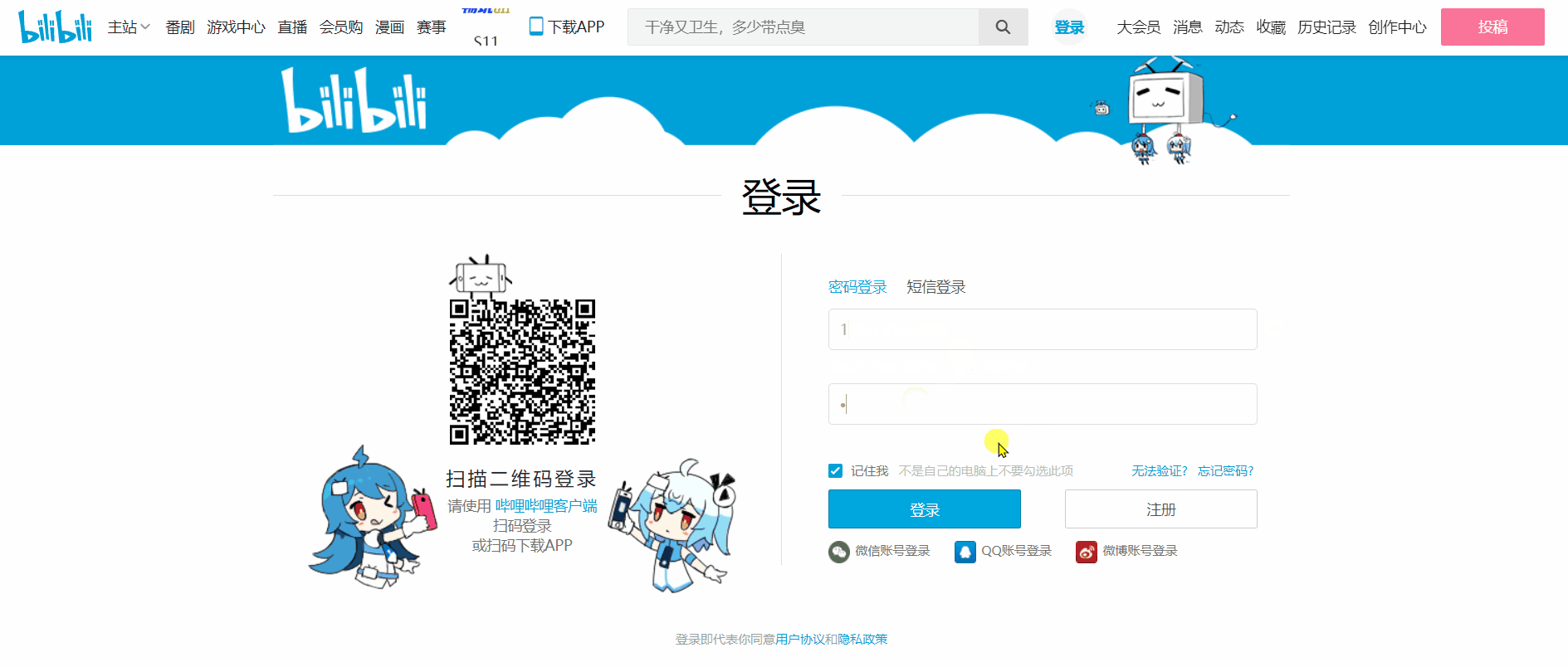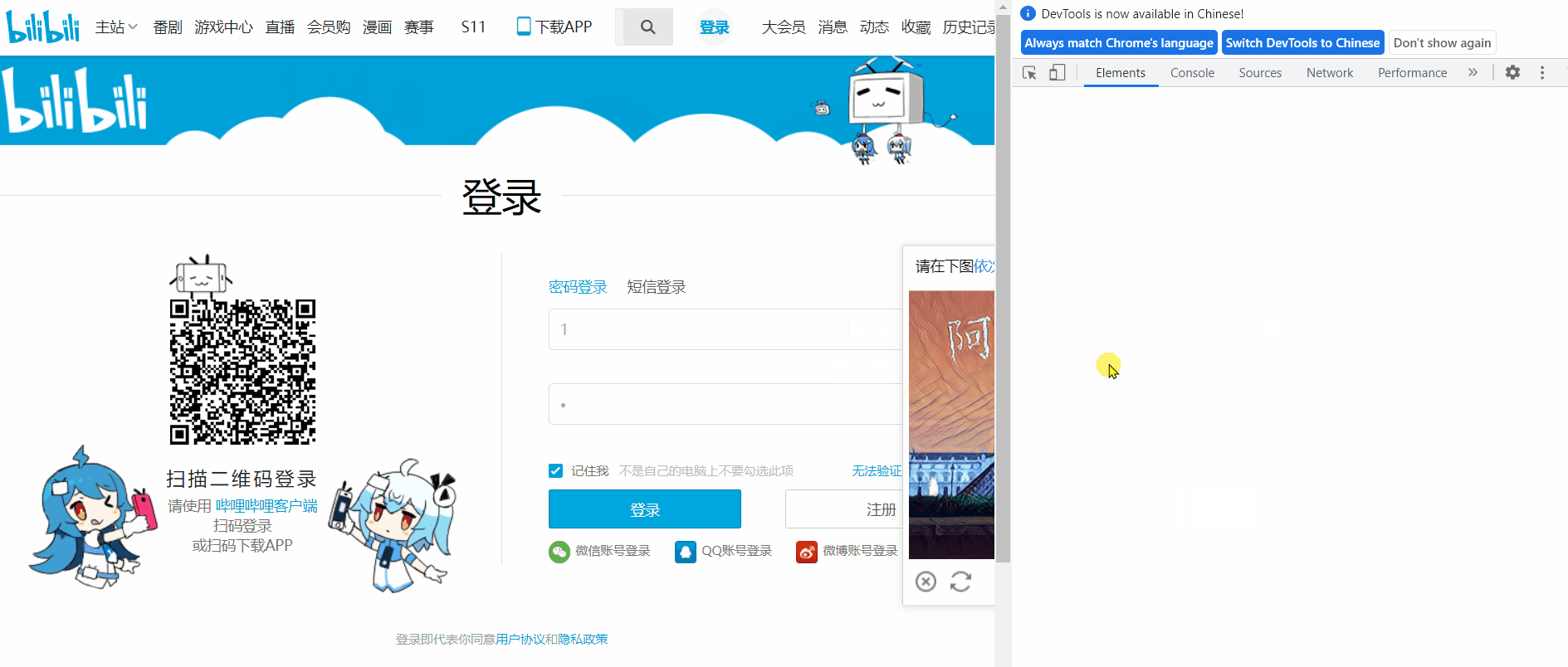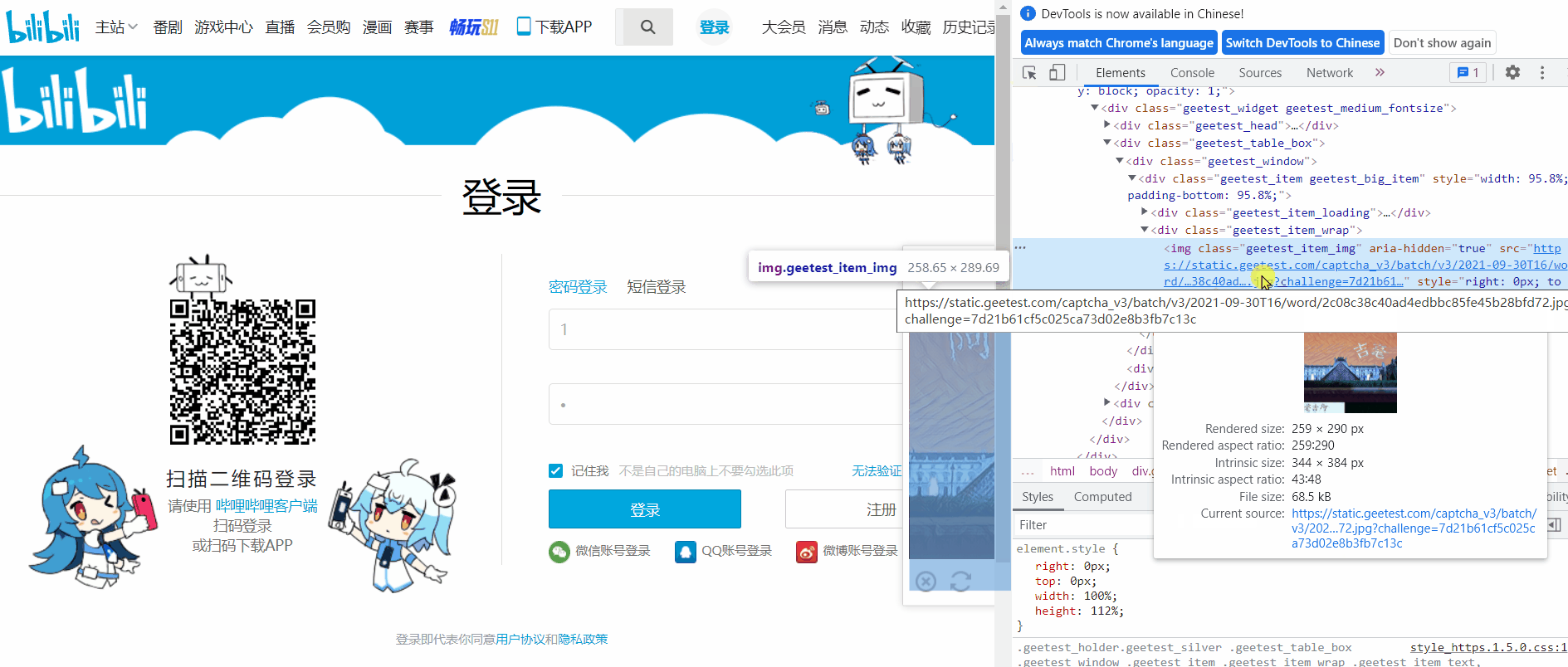
图片地址是
img
标签的
src
属性值,通过
xpath
得到地址,直接对此
url
发送请求,接收数据并保存即可。
注意:由于获取的图片的高度仍然大于超级鹰标准格式,所以也需要将图片缩小。
# 获取img标签的src属性值
img_url = driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[6]/div/div/div[2]/div[1]/div/div[2]/img').get_attribute('src')
headers ={'Users-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'}# 获取图片二进制数据
img_data = requests.get(url=img_url, headers=headers).content
withopen('./node1.png','wb')as fp:
fp.write(img_data)
i = Image.open('./node1.png')# 将图片缩小并保存,设置宽为172,高为192
small_img = i.resize((172,192))
small_img.save('./small_img1.png')
使用超级鹰识别验证码
这部分没什么说的,直接调用就行。
# 将验证码提交给超级鹰进行识别
chaojiying = Chaojiying_Client('用户名','密码','96001')# 用户中心>>软件ID 生成一个替换 96001
im =open('small_img.png','rb').read()# 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//# 9004是验证码类型print(chaojiying.PostPic(im,9004)['pic_str'])
result = chaojiying.PostPic(im,9004)['pic_str']
提取坐标数据,动作链点击
超级鹰识别返回的数据格式是:
123,12 | 234,21
。我们可以将数据以
' | '
进行分割,保存到列表中,再以逗号分割将
x,y
的坐标保存,得到
[ [123,12],[234,21] ]
这一格式,然后遍历这一列表,使用动作链对每一个列表元素对应的
x,y
指定的位置进行点击操作,最后定位并点击确认,登录成功。
all_list =[]# 要存储即将被点击的点的坐标 [[x1,y1],[x2,y2]]if'|'in result:
list_1 = result.split('|')
count_1 =len(list_1)for i inrange(count_1):
xy_list =[]
x =int(list_1[i].split(',')[0])
y =int(list_1[i].split(',')[1])
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)else:
x =int(result.split(',')[0])
y =int(result.split(',')[1])
xy_list =[]
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)# 遍历列表,使用动作链对每一个列表元素对应的x,y指定的位置进行点击操作# x,y坐标乘2和0.8,是由于之前图片缩放过,所以*2,0.8是因为本人电脑桌面缩放比例为125%,需要还原成1for l in all_list:
x = l[0]*2*0.8
y = l[1]*2*0.8# 将点击操作的参照物移动到指定的模块,# 若用方法二获取的验证码图片,要添加下面代码对code_img_ele赋值# code_img_ele = bro.find_element_by_xpath('/html/body/div[2]/div[2]/div[6]/div/div/div[2]/div[1]/div/div[2]/img')
ActionChains(driver).move_to_element_with_offset(code_img_ele, x, y).click().perform()print('点击已完成')# 完成动作链点击操作后,定位确认按钮并点击
driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[6]/div/div/div[3]/a').click()
运行效果
由于验证码处理需要用到第三方平台,外加设置了强制等待,整体运行速度较慢。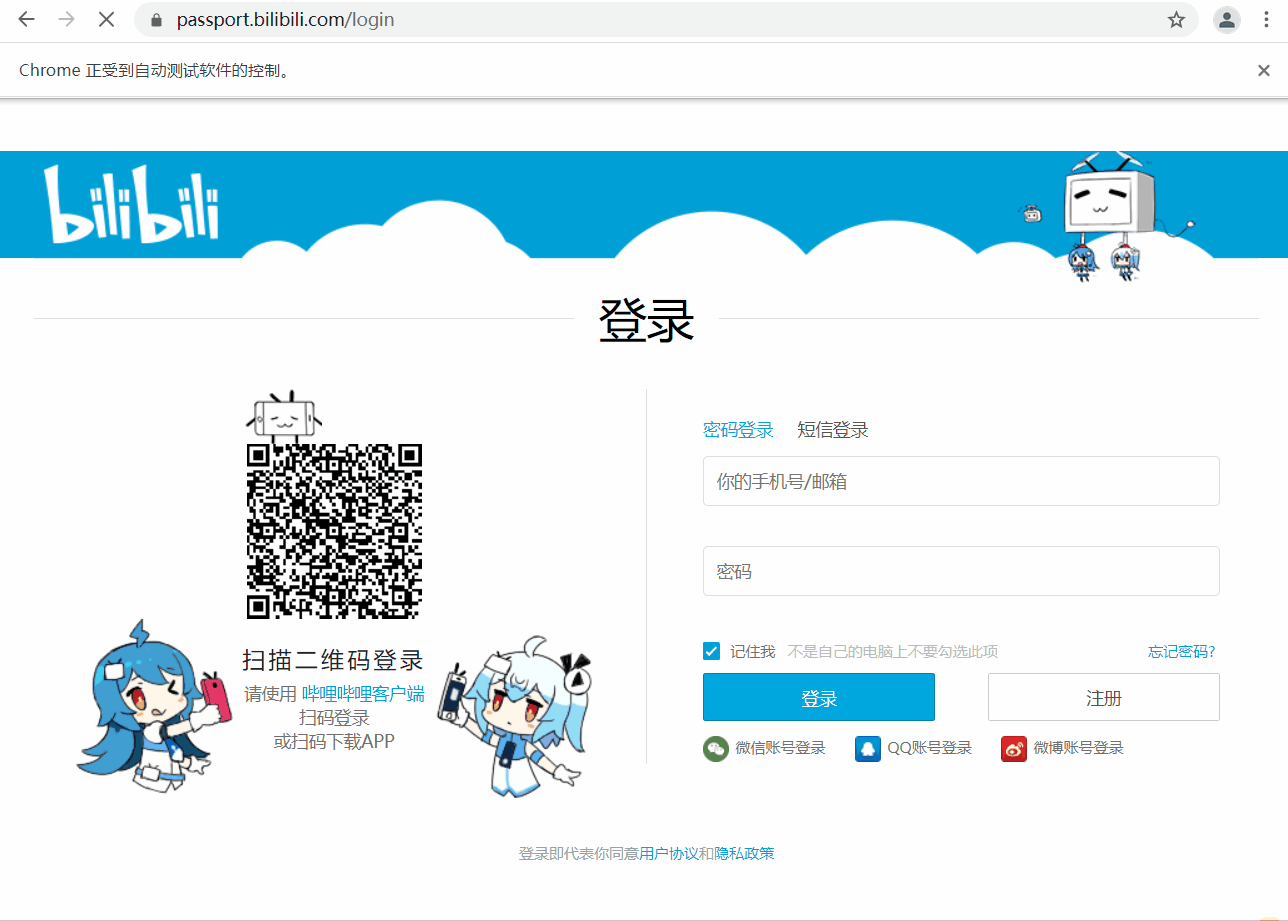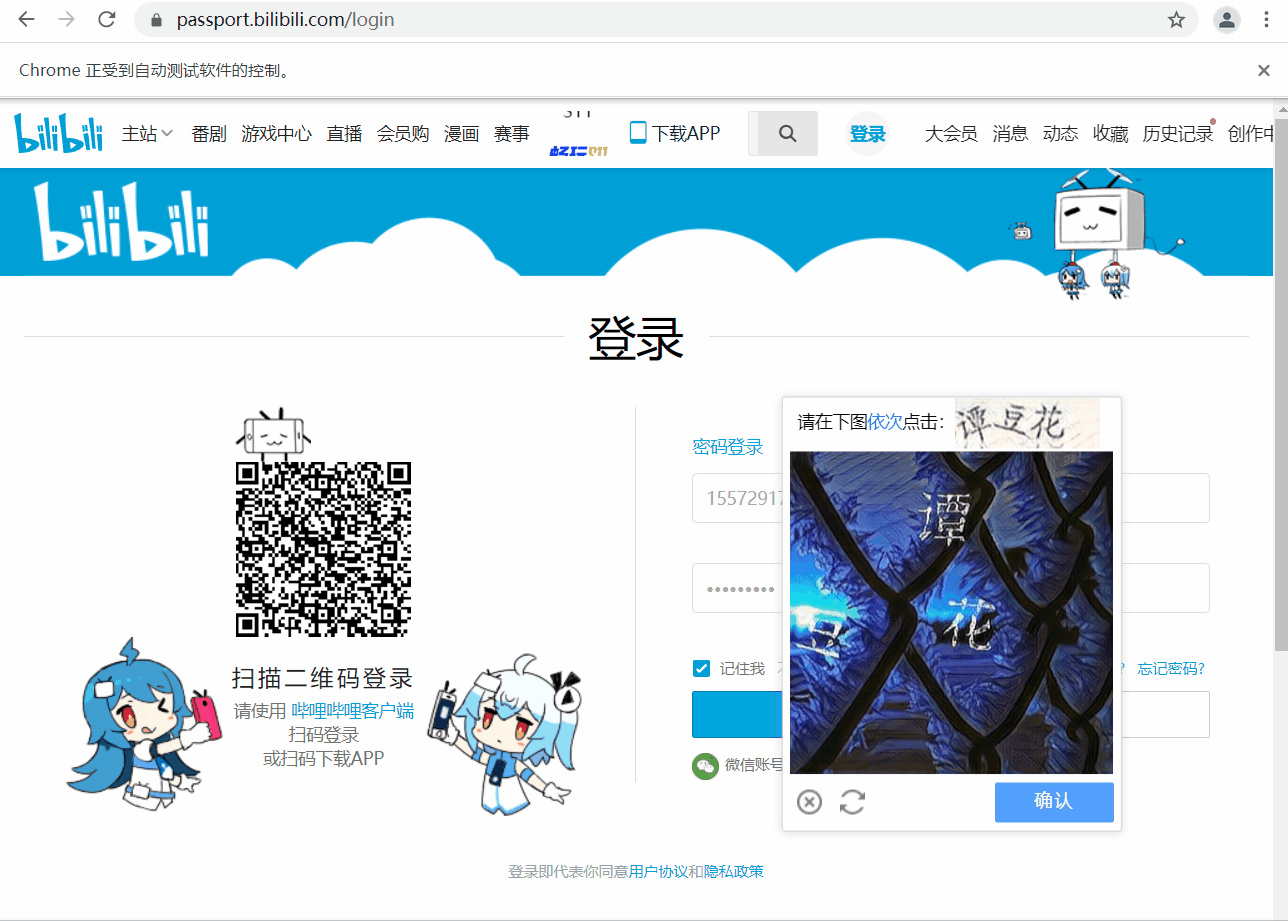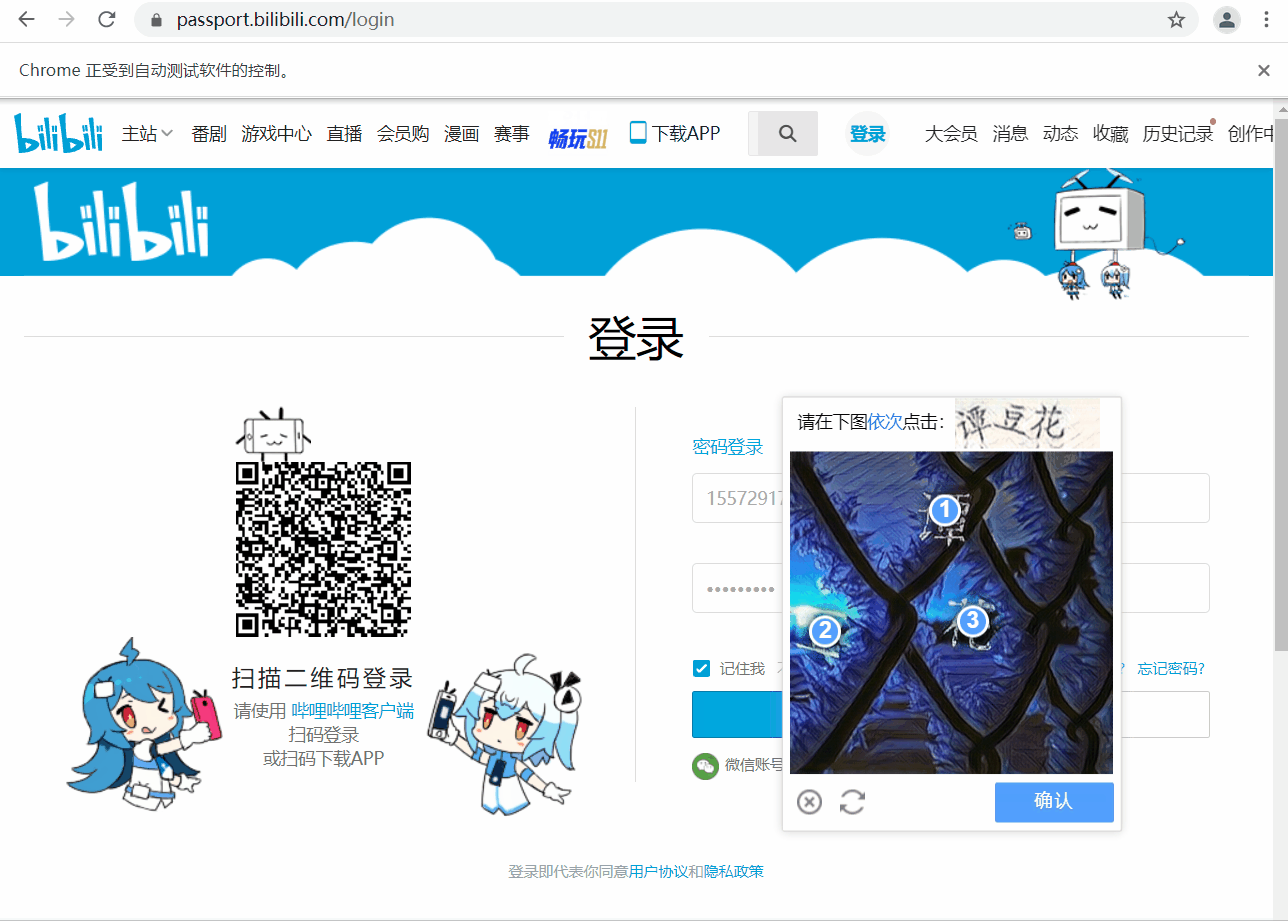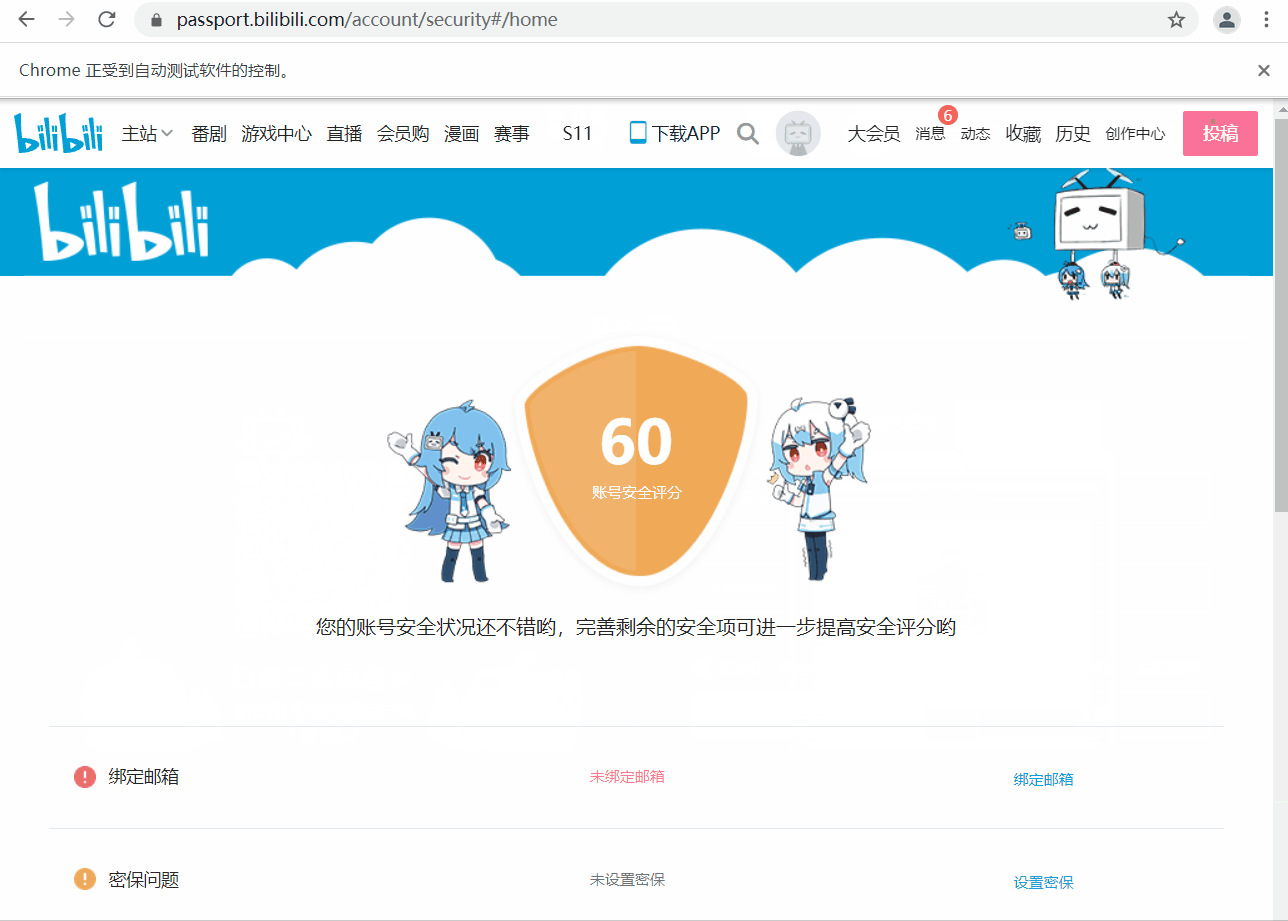
❤️源码获取❤️
对于刚入门
Python
或是想要入门
Python
的小伙伴,可以通过下方公众号联系作者 进入交流群,一起交流学习,都是从新手走过来的,有时候一个简单的问题卡很久,但可能别人的一点拨就会恍然大悟,由衷的希望大家能够共同进步。另有整理的近千套简历模板,几百册电子书等你来领取哦!
也可以直接加本人微信,备注:【交流群】,我拉你进Python交流群👇🏻
👇🏻
实战源码 可关注最下方
公众号卡片 回复
模拟登录B站 获取,回复“666”入群👇🏻
版权归原作者 Dream丶Killer 所有, 如有侵权,请联系我们删除。