
文章目录
物理执行图
JobManager根据ExecutionGraph对作业进行调度,并在各个TaskManager上部署任务。这些任务在TaskManager上的实际执行过程就形成了物理执行图。物理执行图并不是一个具体的数据结构,而是描述了流处理任务在集群中的实际执行情况。
它包含的主要抽象概念有:Task、ResultPartition、ResultSubpartition、InputGate、InputChannel。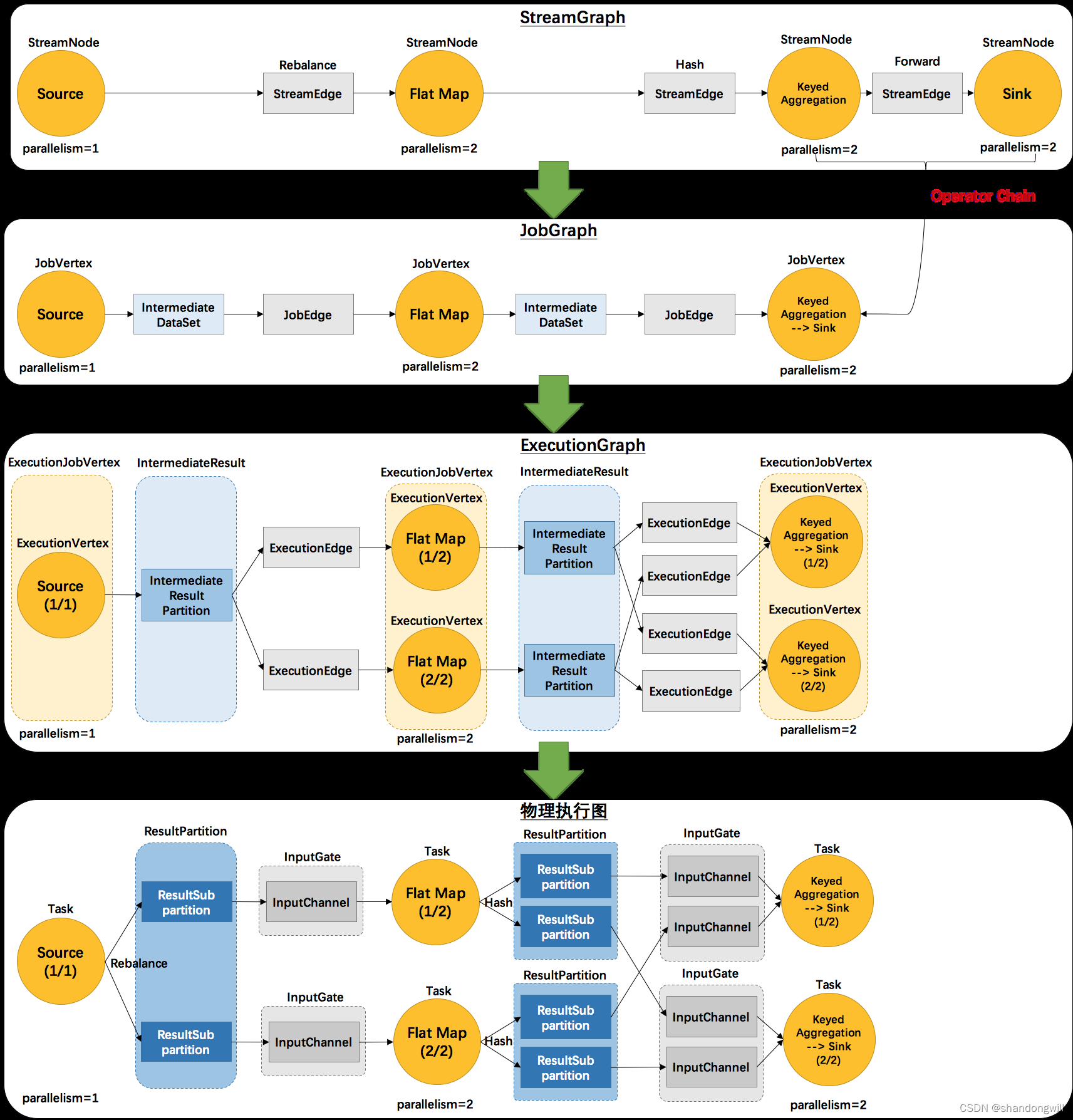
一、Task
Execution被调度后在分配的 TaskManager 中启动对应的 Task。Task 包裹了具有用户执行逻辑的 operator。
一个作业可以被划分为多个Task,并在不同的Task上并行执行。每个Task由一个或多个子任务(Subtask)组成,每个子任务在一个TaskSlot中运行。Task主要负责接收输入数据,执行数据转换和计算,并将结果发送到下游的算子中。
在Flink中,Task的执行由TaskExecutor来负责。Task.doRun()方法是引导Task初始化并执行其相关代码的核心方法。它会构造并实例化Task的可执行对象,即AbstractInvokable。AbstractInvokable.invoke()方法的执行过程中,如果正常执行完毕,会输出ResultPartition缓冲区数据,关闭缓冲区,并标记Task为Finished;如果因为取消操作导致退出,会标记Task为CANCELED,并关闭用户代码;如果执行过程中抛出异常,会标记Task为FAILED,关闭用户代码,并记录异常;如果执行过程中JVM抛出错误,会强制终止虚拟机,并退出当前进程。
二、ResultPartition
ResultPartition代表由一个Task生成的数据,并与ExecutionGraph中的IntermediateResultPartition一一对应。它实际上是一个缓存池,里面保存的是经过序列化之后的节点计算结果。每个ResultPartition包含多个ResultSubPartition,其数目由下游消费Task的数量和DistributionPattern来决定。ResultSubPartition是ResultPartition的一个子分区,真正持有缓冲区Buffer。
写入ResultPartition的操作由ResultPartition的add方法实现。此外,在shuffle阶段,ResultPartition的选择由ChannelSelector负责,它决定了序列化后的record应该写入哪个ResultSubPartition。
ResultPartition在Flink的物理执行图中扮演着重要角色,它确保了数据在Task之间的正确流动和传输,是构建高效、可靠数据流处理应用的关键组件之一。
三、ResultSubpartition
ResultSubpartition是ResultPartition的一个子分区,用于存储和传输数据。每个ResultPartition包含多个ResultSubpartition,其数量由下游消费Task的数量和DistributionPattern决定。这种设计有助于并行处理数据,提高处理效率。
ResultSubpartition负责接收上游Task生成的数据,并将其缓存起来,以便下游Task消费。同时,ResultSubpartition还负责数据的序列化、反序列化和传输,确保数据在不同Task之间的正确流动。
根据数据类型和传输需求,Flink提供了不同类型的ResultSubpartition实现。例如,PipelinedSubpartition是基于内存的管道模式的结果子分区,适用于低延迟的数据传输场景;BoundedBlockingSubpartition中是以阻塞的方式传输的,即数据先被写入,然后再被消费。这种机制确保了数据的有序性和一致性,避免了数据在传输过程中的丢失或乱序问题。
在Flink的物理执行图中,ResultSubpartition与InputGate和InputChannel紧密相关。每个InputGate消费一个或多个ResultPartition,而每个InputGate又包含一个或多个InputChannel。InputChannel与ResultSubpartition一对一地相连,即一个InputChannel接收一个ResultSubpartition的输出。这种设计使得数据能够按照预定的路径在Task之间流动,实现分布式数据流处理。
总的来说,ResultSubpartition是Flink数据流处理中的关键组件,它负责数据的存储、传输和消费,确保数据在不同Task之间的正确流动和高效处理。
创建ResultPartition、ResultSubpartition的相关源码
publicResultPartitioncreate(String taskNameWithSubtaskAndId,int partitionIndex,ResultPartitionID id,ResultPartitionType type,int numberOfSubpartitions,int maxParallelism,SupplierWithException<BufferPool,IOException> bufferPoolFactory){BufferCompressor bufferCompressor =null;if(type.supportCompression()&& batchShuffleCompressionEnabled){
bufferCompressor =newBufferCompressor(networkBufferSize, compressionCodec);}ResultSubpartition[] subpartitions =newResultSubpartition[numberOfSubpartitions];finalResultPartition partition;if(type ==ResultPartitionType.PIPELINED|| type ==ResultPartitionType.PIPELINED_BOUNDED|| type ==ResultPartitionType.PIPELINED_APPROXIMATE){finalPipelinedResultPartition pipelinedPartition =newPipelinedResultPartition(
taskNameWithSubtaskAndId,
partitionIndex,
id,
type,
subpartitions,
maxParallelism,
partitionManager,
bufferCompressor,
bufferPoolFactory);for(int i =0; i < subpartitions.length; i++){if(type ==ResultPartitionType.PIPELINED_APPROXIMATE){
subpartitions[i]=newPipelinedApproximateSubpartition(
i, configuredNetworkBuffersPerChannel, pipelinedPartition);}else{
subpartitions[i]=newPipelinedSubpartition(
i, configuredNetworkBuffersPerChannel, pipelinedPartition);}}
partition = pipelinedPartition;}elseif(type ==ResultPartitionType.BLOCKING|| type ==ResultPartitionType.BLOCKING_PERSISTENT){if(numberOfSubpartitions >= sortShuffleMinParallelism){
partition =newSortMergeResultPartition(
taskNameWithSubtaskAndId,
partitionIndex,
id,
type,
subpartitions.length,
maxParallelism,
batchShuffleReadBufferPool,
batchShuffleReadIOExecutor,
partitionManager,
channelManager.createChannel().getPath(),
bufferCompressor,
bufferPoolFactory);}else{finalBoundedBlockingResultPartition blockingPartition =newBoundedBlockingResultPartition(
taskNameWithSubtaskAndId,
partitionIndex,
id,
type,
subpartitions,
maxParallelism,
partitionManager,
bufferCompressor,
bufferPoolFactory);initializeBoundedBlockingPartitions(
subpartitions,
blockingPartition,
blockingSubpartitionType,
networkBufferSize,
channelManager,
sslEnabled);
partition = blockingPartition;}}elseif(type ==ResultPartitionType.HYBRID_FULL|| type ==ResultPartitionType.HYBRID_SELECTIVE){
partition =newHsResultPartition(
taskNameWithSubtaskAndId,
partitionIndex,
id,
type,
subpartitions.length,
maxParallelism,
batchShuffleReadBufferPool,
batchShuffleReadIOExecutor,
partitionManager,
channelManager.createChannel().getPath(),
networkBufferSize,HybridShuffleConfiguration.builder(
numberOfSubpartitions,
batchShuffleReadBufferPool.getNumBuffersPerRequest()).setSpillingStrategyType(
type ==ResultPartitionType.HYBRID_FULL?HybridShuffleConfiguration
.SpillingStrategyType.FULL:HybridShuffleConfiguration
.SpillingStrategyType.SELECTIVE).build(),
bufferCompressor,
bufferPoolFactory);}return partition;}
四、InputGate
InputGate是对数据输入的封装,与JobGraph中的JobEdge一一对应。每个InputGate消费一个或多个ResultPartition,这些ResultPartition代表上游Task生成的数据。InputGate的主要作用是管理和控制数据的流入,确保数据能够按照正确的顺序和方式被Task所消费。
InputGate由多个InputChannel构成,每个InputChannel与ExecutionGraph中的ExecutionEdge以及ResultSubpartition一一对应。这意味着每个InputChannel负责接收一个ResultSubpartition的输出,从而实现了数据的精确传递和接收。
在Flink的物理执行过程中,InputGate和InputChannel起着至关重要的作用。它们不仅负责数据的接收和传递,还参与了数据的序列化和反序列化过程,确保数据在不同Task之间的正确流动。此外,InputGate和InputChannel还提供了对数据传输的控制和优化功能,可以根据实际需求调整数据传输的策略和方式。
总的来说,Flink的InputGate通过对数据输入的封装和管理,实现了数据的精确传递和高效处理。
五、InputChannel
InputChannel是数据输入通道的关键组件,它位于InputGate之下,与ExecutionGraph中的ExecutionEdge以及ResultSubpartition一对一地相连。每个InputChannel负责接收一个ResultSubpartition的输出,确保数据从上游Task正确地流向下游Task。
根据消费的ResultPartition的位置,InputChannel有两种不同的实现:LocalInputChannel和RemoteInputChannel。LocalInputChannel用于处理本地数据交换,即数据在同一TaskManager的不同Task之间传输;而RemoteInputChannel则负责远程数据交换,即数据在不同TaskManager的Task之间传输。这种设计使得Flink能够灵活地处理分布式环境中的数据流动。
此外,还有一个名为UnknownInputChannel的实现类,它作为尚未确定ResultPartition位置的情况下的占位符。在实际执行过程中,UnknownInputChannel最终会被更新为LocalInputChannel或RemoteInputChannel,以反映实际的数据传输路径。
InputChannel在Flink的数据流处理中扮演着重要角色。它不仅是数据传输的通道,还参与数据的序列化和反序列化过程,确保数据在传输过程中的完整性和一致性。同时,InputChannel与InputGate和ResultSubpartition的紧密协作,使得Flink能够高效地处理大规模、高吞吐量的数据流。
总结来说,Flink InputChannel负责数据的接收、传输和序列化,确保数据在不同Task之间的正确流动。通过LocalInputChannel和RemoteInputChannel的不同实现,Flink能够处理各种分布式场景下的数据交换需求。
版权归原作者 shandongwill 所有, 如有侵权,请联系我们删除。