
写在前面
本系列文章索引以及一些默认好的条件在 传送门
所有节点均需要安装并配置Hadoop
一共设置了两个节点,分别是master && slave1
step1. Hadoop下载
博主使用的是Hadoop3.1.1,可以去Hadoop官网下载
step2. Hadoop解压安装
将下载后的Hadoop包放置在
/usr/local
之下,然后使用如下命令:
cd /usr/local
tar -zxvf /usr/local/hadoop-3.1.1.tar.gz -C /usr/local
cd /usr/local
mv ./hadoop-3.1.1 ./hadoop
具体版本名称根据自己的实际情况来确定
切勿盲目CV
step3. 配置环境变量
使用vim打开文件命令是:
vim ~/.bashrc
然后键入
i
后输入:
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_HOME=$HADOOP_INSTALL
然后保存编辑的内容,按下esc,然后输入
:wq!
保存并退出
具体版本名称根据自己的实际情况来确定
切勿盲目CV
step4. 查看时候配置成功
命令行输入:
source ~/.bashrc
然后输入
hdfs
查看结果
出现下图所示则为成功: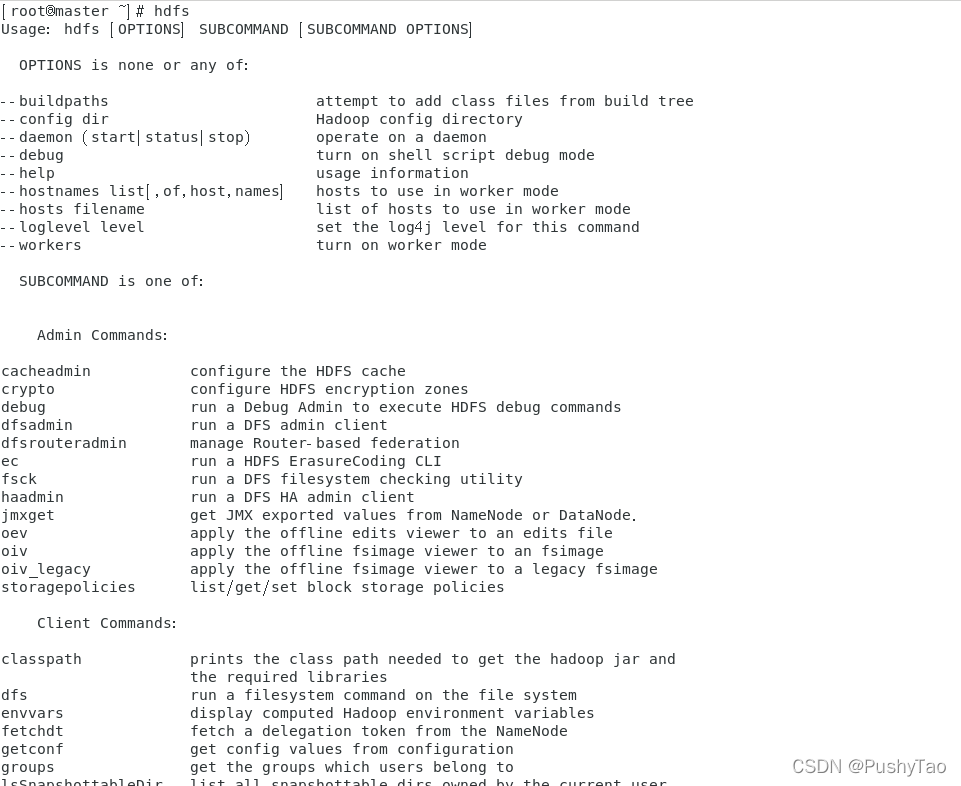
step5. 其他节点的配置
在其他的节点均操作step1-4
step6. 修改六个配置文件
6.1 hadoop-env.sh修改 | master节点
cd /usr/local/hadoop/etc/hadoop/
vim hadoop-env.sh
然后键入:
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64
export HADOOP_HOME=/usr/local/hadoop
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
具体版本名称根据自己的实际情况来确定
切勿盲目CV
后保存
6.2 core-site.xml修改 | master节点
该文件在与6.1同级目录下
需要键入:
<property>
<name>hadoop.tmp.dir</name><value>/usr/hadoop/tmp</value>
</property>
<property>
<name>fs.default.name</name><value>hdfs://master:9000</value>
</property>
<property><name>io.file.buffer.size</name><value>131072</value>
</property>
需要夹在
<
c
o
n
f
i
g
u
r
a
t
i
o
n
>
<
/
c
o
n
f
i
g
u
r
a
t
i
o
n
>
<configuration></configuration>
<configuration></configuration>之间
6.3 hdfs-site.xml修改 | master节点
同样在同级目录下使用vim编辑该文件,同样放在
<
c
o
n
f
i
g
u
r
a
t
i
o
n
>
<
/
c
o
n
f
i
g
u
r
a
t
i
o
n
>
<configuration></configuration>
<configuration></configuration>之间
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hdfs/name/</value>
</property>
<property><name>dfs.blocksize</name><value>268435456</value></property>
<property>
<name>dfs.namenode.handler.count</name><value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hdfs/data/</value>
</property>
<property>
<name>dfs.namenode.http-address</name><value>master:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
具体版本名称根据自己的实际情况来确定
切勿盲目CV
6.4 yarn-site.xml修改 | master节点
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name><value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop/etc/*,/usr/local/hadoop/lib/*,/usr/local/hadoop/etc/hadoop/*,/usr/local/hadoop/share/hadoop/common/*,/usr/local/hadoop/share/hadoop/common/lib/*,/usr/local/hadoop/share/hadoop/mapreduce/*,usr/local/hadoop/share/hadoop/mapreduce/lib/*,/usr/local/hadoop/share/hadoop/hdfs/*,/usr/local/hadoop/share/hadoop/hdfs/lib/*,/usr/local/hadoop/share/hadoop/yarn/*,/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
具体版本名称根据自己的实际情况来确定
切勿盲目CV
6.5 mapred-site.xml修改 | master节点
同样在同级目录下,vim编辑键入:
具体版本名称根据自己的实际情况来确定
切勿盲目CV
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.application.classpath</name><value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value></property></configuration>
6.6 works 修改 | master节点
同样在同级目录下面编辑
vim works
然后键入子节点的名字如
slave1
slave2
step7. 配置文件的复制
将如上所示的配置文件直接复制到其他节点,因为已经实现了互通以及ssh免密登录,所以说:
scp hadoop-env.sh root@slave1:/usr/local/hadoop/etc/hadoop/
scp core-site.xml root@slave1:/usr/local/hadoop/etc/hadoop/
scp hdfs-site.xml root@slave1:/usr/local/hadoop/etc/hadoop/
scp mapred-site.xml root@slave1:/usr/local/hadoop/etc/hadoop/
scp yarn-site.xml root@slave1:/usr/local/hadoop/etc/hadoop/
scp workers root@slave1:/usr/local/hadoop/etc/hadoop/
如果有多个节点,可以将slave1替换为slave2
step8. 配置目录的创建
mkdir /usr/hadoop
mkdir /usr/hadoop/tmp
mkdir /usr/local/hadoop/hdfs
mkdir /usr/local/hadoop/hdfs/name
mkdir /usr/local/hadoop/hdfs/data
step9. 格式化并启动Hadoop
在各个节点输入
hdfs namenode -format
如果出现: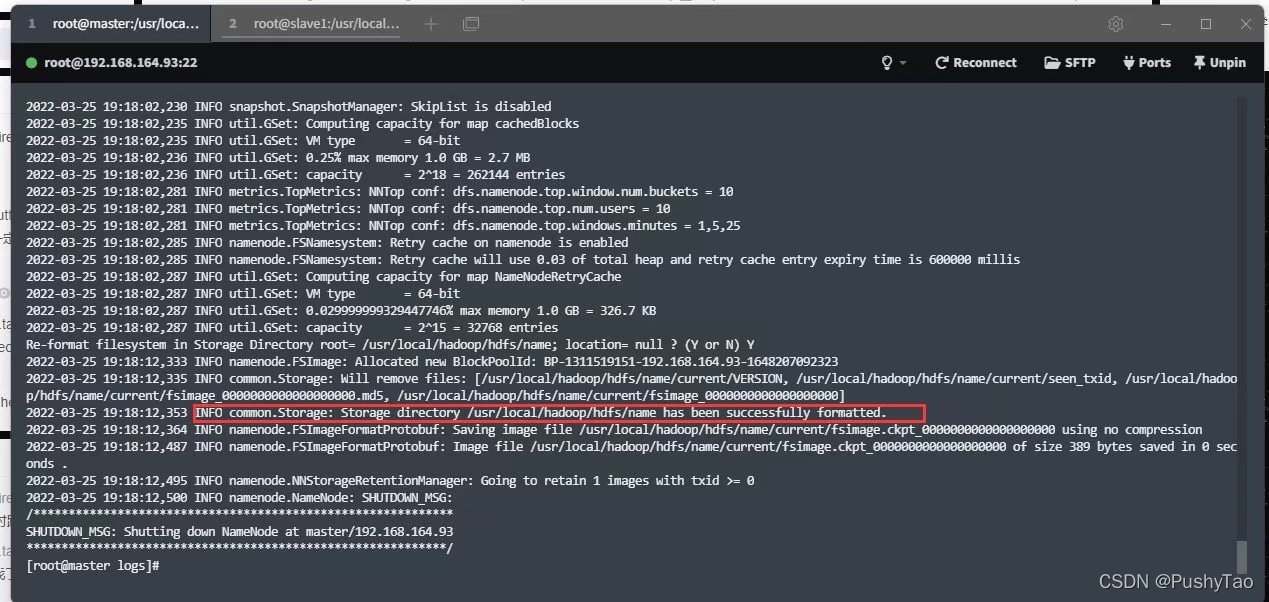
则表明格式化成功
在主机进行:
/usr/local/hadoop/sbin/start-all.sh
然后:
输入
jps
查看Java进程情况
step10. 浏览器查看集群
在浏览器输入:
master:50070
会显示相信的信息: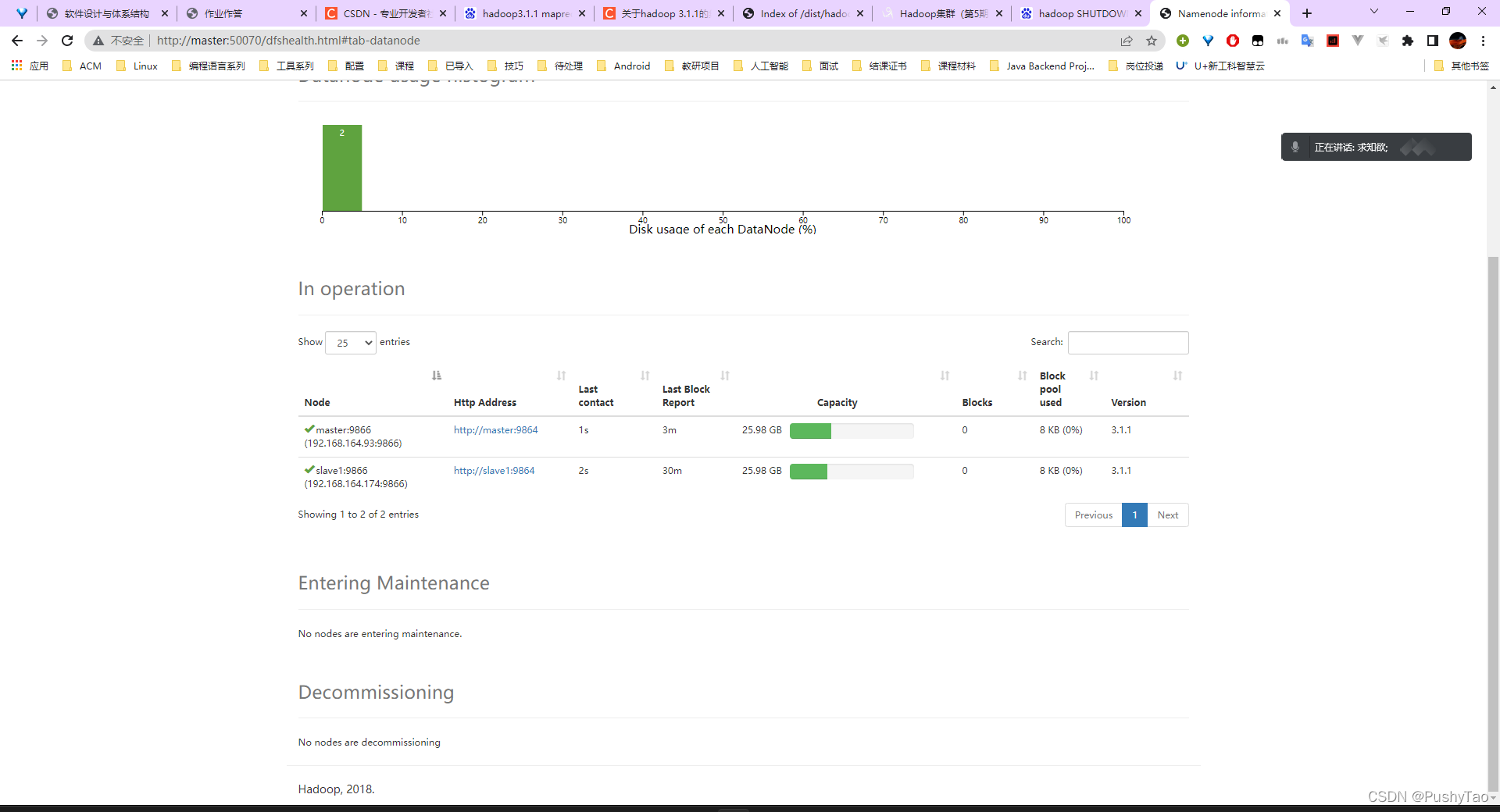
若能够查看到各个节点的信息(master,slave1,slave2等)则说明配置成功
如果访问不到或者是访问不强,可以考虑关闭防火墙
本文转载自: https://blog.csdn.net/weixin_45712255/article/details/123833758
版权归原作者 PushyTao 所有, 如有侵权,请联系我们删除。
版权归原作者 PushyTao 所有, 如有侵权,请联系我们删除。