
部署Spark&PySpark简易教程
前提
已安装Hadoop。注意Spark版本要与Hadoop版本兼容。本文使用Spark3和Haoodp3。操作系统为CentOS7,jdk为1.8
安装文件
链接:https://pan.baidu.com/s/10nWDhDKhXV9KB1ZRvagDgQ?pwd=6okr
提取码:6okr
1、配置Python环境
配置Python环境是为了让Spark能够执行Python代码程序
本文使用Anaconda配置Python环境
(1)root用户或非root用户都可,本文使用普通用户。执行命令,安装Anaconda
sh Anaconda3-2021.05-Linux-x86_64.sh
PS:安装过程中:①协议部分选择yes;②安装路径自定义,如/export/server/anaconda3(如果路径输错字母,按ctrl+backspace删除字符);③初始化选择yes
PS:安装完成后,重新登陆当前用户,就可以使用conda命令了
(2)创建anaconda虚拟环境,虚拟环境名:pyspark
conda create -n pyspark python==3.8
(3)激活pyspark环境
conda activate pyspark
(4)安装pyspark(需要联网)
conda install pyspark
2、安装Spark
(1)解压Spark安装包到安装路径
tar -zxvf /tmp/spark-3.2.0-bin-hadoop3.2.tgz -C /export/server/
为安装路径创建软连接,方便访问
ln -s /export/server/spark-3.2.0-bin-hadoop3.2/ /export/server/spark
(2)配置环境变量(用root用户)
vim /etc/profile
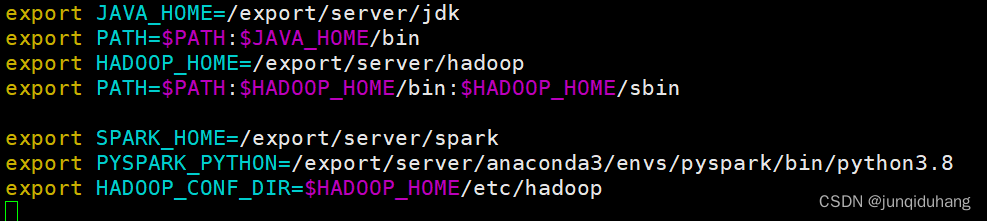
追加以下内容:
- SPARK_HOME: 表示Spark安装路径在哪里
- PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找python执行器
- JAVA_HOME: 告知Spark Java在哪里 (安装Hadoop时已配置)
- HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件在哪里
- HADOOP_HOME: 告知Spark Hadoop安装在哪里(安装Hadoop时已配置)
export SPARK_HOME=/export/server/spark
export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin/python3.8
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
使环境变量生效
source /etc/profile
3、分布式Spark——SparkAlone
相关概念请自行了解
本文使用3个结点:node1,node2和node3
(1)以上操作都在node1上进行。node2和node3上同样安装anaconda,解压spark安装包(后面可以直接发送node1配置完的安装包) ,配置环境变量。
(2)修改spark安装路径权限
chown -R hadoop:hadoop /export/server/spark
PS:hadoop为本文结点上的普通用户
(3)编辑Spark配置文件。进入配置文件目录:
cd $SPARK_HOME/conf
①编辑workers
改名
mv workers.template workers
编辑workers
vim workers
输入内容:
# 将里面的localhost删除, 追加
node1
node2
node3
②配置spark-env.sh
改名
mv spark-env.sh.template spark-env.sh
编辑spark-env.sh
vim spark-env.sh
在底部追加如下内容
# 注意使用自己机器上的实际路径
## 设置JAVA安装目录
JAVA_HOME=/export/server/jdk
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=node1
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的 webui端口
SPARK_MASTER_WEBUI_PORT=8080
# worker cpu可用核数
SPARK_WORKER_CORES=1
# worker可用内存
SPARK_WORKER_MEMORY=1g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的 webui地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
在HDFS上创建程序运行历史记录存放的文件夹(启动Hadoop)
hadoop fs -mkdir /sparklog
hadoop fs -chmod 777 /sparklog
③配置spark-defaults.conf文件
改名
mv spark-defaults.conf.template spark-defaults.conf
修改spark-defaults.conf
vim spark-defaults.conf
追加如下内容
# 开启spark的日期记录功能
spark.eventLog.enabled true
# 设置spark日志记录的路径
spark.eventLog.dir hdfs://node1:8020/sparklog/
# 设置spark日志是否启动压缩
spark.eventLog.compress true
④配置log4j.properties 文件
改名
mv log4j.properties.template log4j.properties
编辑
vim log4j.properties
参照下图修改:将INFO修改为WARN 设置日志输出级别为WARN,只输出警告和错误日志
设置日志输出级别为WARN,只输出警告和错误日志
4、分发Spark安装包到node2和node3
scp -r /export/server/spark-3.2.0-bin-hadoop3.2/ node2:/export/server/
scp -r /export/server/spark-3.2.0-bin-hadoop3.2/ node3:/export/server/
在node2和node3上分别创建spark安装路径的软链接
ln -s /export/server/spark-3.2.0-bin-hadoop3.2/ /export/server/spark
5、启动集群&运行示例程序
5.1 启动集群
进入spark安装路径
cd /export/server/spark
执行命令
# 启动全部master和worker
sbin/start-all.sh
# 停止全部
sbin/stop-all.sh
5.2 测试
Spark交互工具一览
bin/spark-submit,bin/pyspark(Python交互式Shell)和bin/spark-shell(Scala交互式Shell)
功能bin/spark-submitbin/pysparkbin/spark-shell功能提交java\scala\python代码到spark中运行提供一个
python
解释器环境用来以python代码执行spark程序提供一个
scala
解释器环境用来以scala代码执行spark程序特点提交代码用解释器环境 写一行执行一行解释器环境 写一行执行一行使用场景正式场合, 正式提交spark程序运行测试\学习\写一行执行一行\用来验证代码等测试\学习\写一行执行一行\用来验证代码等
如果要提交python代码文件到spark集群,使用spark-submit。
计算PI,输入以下命令。100为pi.py文件参数,是迭代次数,迭代次数越多,计算结果越精确。
bin/spark-submit --master spark://node1:7077 /export/server/spark/examples/src/main/python/pi.py 100
若能够看到PI的计算结果,则说明Spark&PySpark安装成功!
PS:需要启动Hadoop
6、Spark on Yarn
在spark-env.sh中增加以下内容,若已存在(本文已设置),则无需增加
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
再次执行计算Pi示例程序,这次提交到Yarn(需要启动Yarn)
bin/spark-submit --master yarn /export/server/spark/examples/src/main/python/pi.py 100
若能够看到PI的计算结果,则说明Spark on Yarn配置没有问题!
win环境输入 192.168.88.100:8088 进入 Yarn web界面,可以看到提交的任务。
192.168.88.100是 Yarn Resourcemanager所在结点IP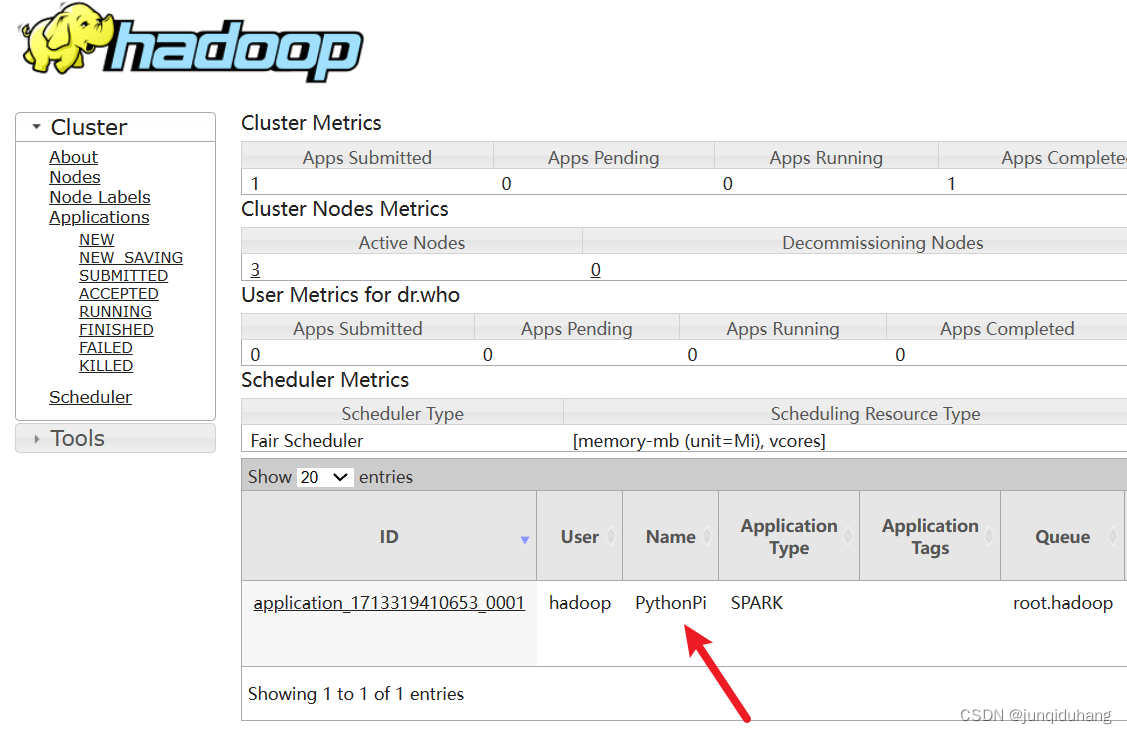
版权归原作者 junqiduhang 所有, 如有侵权,请联系我们删除。