
深度学习相关概念:交叉熵损失
我在学习深度学习的过程中,发现交叉熵损失在分类问题里出现的非常的频繁,但是对于交叉熵损失这个概念有非常的模糊,好像明白又好像不明白,因此对交叉熵损失进行了学习。
交叉熵损失详解
1.激活函数与损失函数
首先我们要知道的一点是,交叉熵损失是损失函数的一种。但是在神经网络中,我们常常又听到另外一种函数:激活函数,这2种函数到底有什么区别呢?他们的作用是什么?
1.1激活函数:
激活函数就是将神经网络上一层的输入,经过神经网络层的非线性变换转换后,通过激活函数,得到输出。常见的激活函数包括:Sigmoid、Tanh、 Relu等。
不同的激活函数之间有以下的区别:
- 梯度特性不同,Sigmoid函数和Tanh函数的梯度在饱和区非常平缓,接近于0,很容易造成梯度消失的问题,减缓收敛速度。但梯度平缓使得模型对噪声不敏感。
- Relu函数的梯度大多数情况下是常数,有助于解决深层网络的收敛问题。Relu函数的另一个优势在于其生物方面的合理性,它是单边的,更符合生物神经元的特征。Relu更容易学习优化,是因为其分段线性性质,导致其前传、后传、求导都是分段线性,而传统的Sigmoid函数,由于两端饱和,在传播中容易丢失信息。
1.2损失函数:
损失函数是度量神经网络的输出的预测值与实际值之间的差距的一种方式。常见的损失函数包括:对数损失函数、交叉熵损失函数、回归中的Mae(L1 Loss) Mse(L2 Loss)损失函数等。
2.对数损失函数(常用于二分类问题):
Tip:什么是二分类问题?
即某一事件只存在是(1)或者不是(0)的现象。如果分类任务中有两个类别,比如我们想识别一幅图片是不是狗。我们训练一个分类器,输入一幅图片,输出是不是狗,用y=0或1表示。
对数损失函数(二分类交叉熵损失,逻辑回归损失):
对数损失函数的基本思想是极大似然估计,极大似然估计简单来说,就是如果某一个事件已经发生了,那么就认为这事件发生的概率应该是最大的。似然函数就是这个概率,我们要做的就是基于现有数据确定参数从而最大化似然函数。在进行似然函数最大化时,会对多个事件的概率进行连续乘法。连续乘法中很多个小数相乘的结果非常接近0,而且任意数字发生变化,对最终结果的影响都很大。为了避免这两种情况,可以使用对数转换将连续乘法转换为连续加法。对数函数是单调递增函数,转换后不会改变似然函数最优值的位置。前面负号,我们就将最大似然函数转换为求解最小损失函数。二分类问题的对数损失函数如下: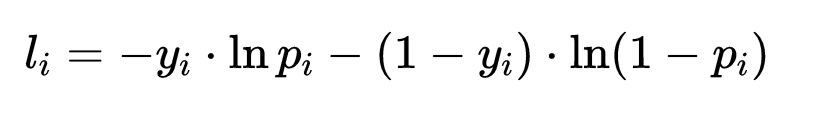
y_i表示实际情况下某类事件是否发生(0或1),p_i表示事件发生的概率,由sigmoid函数得到概率p。
如果样本只有一个的话,会有如下两种情况:
当y=1时,损失函数为 -ln§,如果想要损失函数尽可能的小,那么概率p就要尽可能接近1。
当y=0时,损失函数为 -ln(1-p),如果想要损失函数尽可能的小,那么概率p就要尽可能接近0。
但是如果有m个样本的时候,则损失函数公式如下:
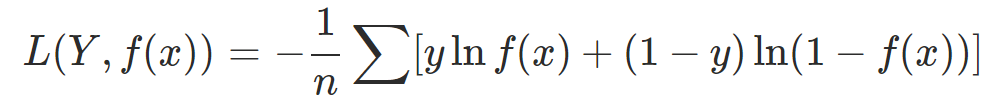
假设有三个独立事件,1 表示事件发生,现在三个事件发生情况为(1,1,0),通过神经网络得到三个事件发生的概率为(0.8, 0.7, 0.1),使用上面的公式计算损失值为0.69,损失值很小,说明神经网络预测的这组概率正确的可能性很大;同样的这组概率,三个事件发生情况为(0,0,1),计算得到的损失值5.12,损失值很大,说明神经网络预测的这组概率正确的可能性很小。
3.交叉熵、熵、相对熵三者之间的关系
交叉熵、相对熵、熵之间可以相互推导。具体见下图。
相对熵用来衡量两个分布之间的不相似性。越不相似的相对熵越大,越相似的相对熵越小。例如,狗和猪的相似 性为0.02,猫和狗的相似性可能为0.2.
当事件分布满足one-hot分布,即A,B,C三件事的发生概率为(1 0 0)或(0 1 0)或(0 0 1)时,交叉熵=熵,也就是说交叉熵损失函数等于对数损失函数,具体推导见下图。

4.交叉熵损失函数(常用于多分类问题)
Tips:什么是多分类?
多类分类(Multiclass classification): 表示分类任务中有多个类别, 比如对一堆动物图片分类, 它们可能是猫、狗、鸟等. 多类分类是假设每个样本都被设置了一个且仅有一个标签: 一个动物可以是狗或者猫, 但是同时不可能是两者。
4.1交叉熵的作用:
衡量多分类器输出与预测值之间的关系
交叉熵损失函数的标准形式如下: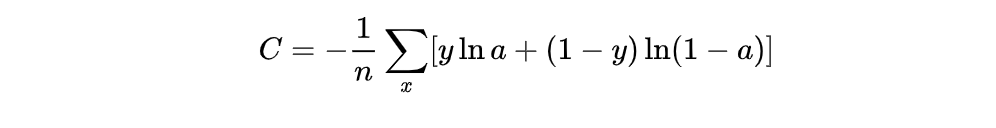
注意公式中 x 表示样本, y表示实际的标签,a 表示预测的输出, n表示样本总数量。
5.交叉熵损失 VS 多类支撑向量机损失
在下面的图中,第二行居然有一个0.23,接近0.24的损失,而多类支撑向量机损失确是零,为什么会有这样的损失?因为你把这(10(鸟) 9(猫) 9(狗))归一化以后是不是近似于接近于这个事情的概率是1/3,就可能是1.2/3、0.9/13、0.9/3,第一个就比第二个强了一丢丢。但是从概率的角度讲,这个地方的损失是负的,接近于-log(1/3),但是虽然鸟是比猫狗和猫大了,但是鸟的概率值还很小,鸟的概率我是0.34,其他两个都0.33,鸟是最大的。我们做分类输出的时候,我们是会把它判断成鸟,但是神经网络输出的时候你是属于鸟,但是你的概率只有0.34,所以神经网络不希望这样,神经网络希望输出的结果训练以后说的,我告诉你属于鸟,其实而且鸟类的概率比较高,最好是0.9以上。但是多类支撑向量机损失在这个情况下,他会把损失判断为0,不在优化算法,但是由于3者之间差距实在太小,你这次可能预测为鸟类是正确的,但是下次就未必正确,这就导致我们神经网络的训练精度不能提高。但是交叉熵损失,在这种情况下他并没有停止训练,这个时候他依然有很大的损失,他会要求这个分数尽量的高。而且不仅要求鸟类高,我还要求猫和狗的概率低,所以交叉商损失就是这个作用,就是我高的时候不是要压低别人的分数,而多类支持向量机损失呢,我只要比别人高一分就行了,我不管你是多少分,我这比你高一分儿我就完事儿了。这就是这两类损失最大区别。所以有些时候在我们有些时候训练分类器的时候,我们会遇到这样的情况:我这个损失函数一直没怎么变的,但是我的预测精度acc却在一直的增加。


如上图,尽管A组和B组的损失几乎是一样的,但是却是预测正确和预测错误,在我反向传播时权重稍微调整一下,我就能让我预测正确,但是我的损失并没有怎么样的改变,这就是为什么我的总损失并没有怎么样变化,但是我的精度在一直在上升,就是因为我们这个概率预测的这个值略微比其他的渗出了一点点,大家还处于势均力敌的状态。
版权归原作者 Jsper0420 所有, 如有侵权,请联系我们删除。