
LRU是什么?
LRU是内存淘汰策略,LRU (Least recently used:最近最少使用)算法在缓存写满的时候,会根据所有数据的访问记录,淘汰掉未来被访问几率最低的数据。也就是说该算法认为,最近被访问过的数据,在将来被访问的几率最大。
那LRU使用什么实现的呢?双链表的话,那查询的时间复杂度不就是O(n)了,那应该怎么办,于是可以用双链表加Map的方式进行插入和查询,在插入的时候,把key,value 存到map中,那么这样查询的时候时间复杂读不就是O(n)了
假如现在我设定的内存就能存放5个数据块,现在进行插入
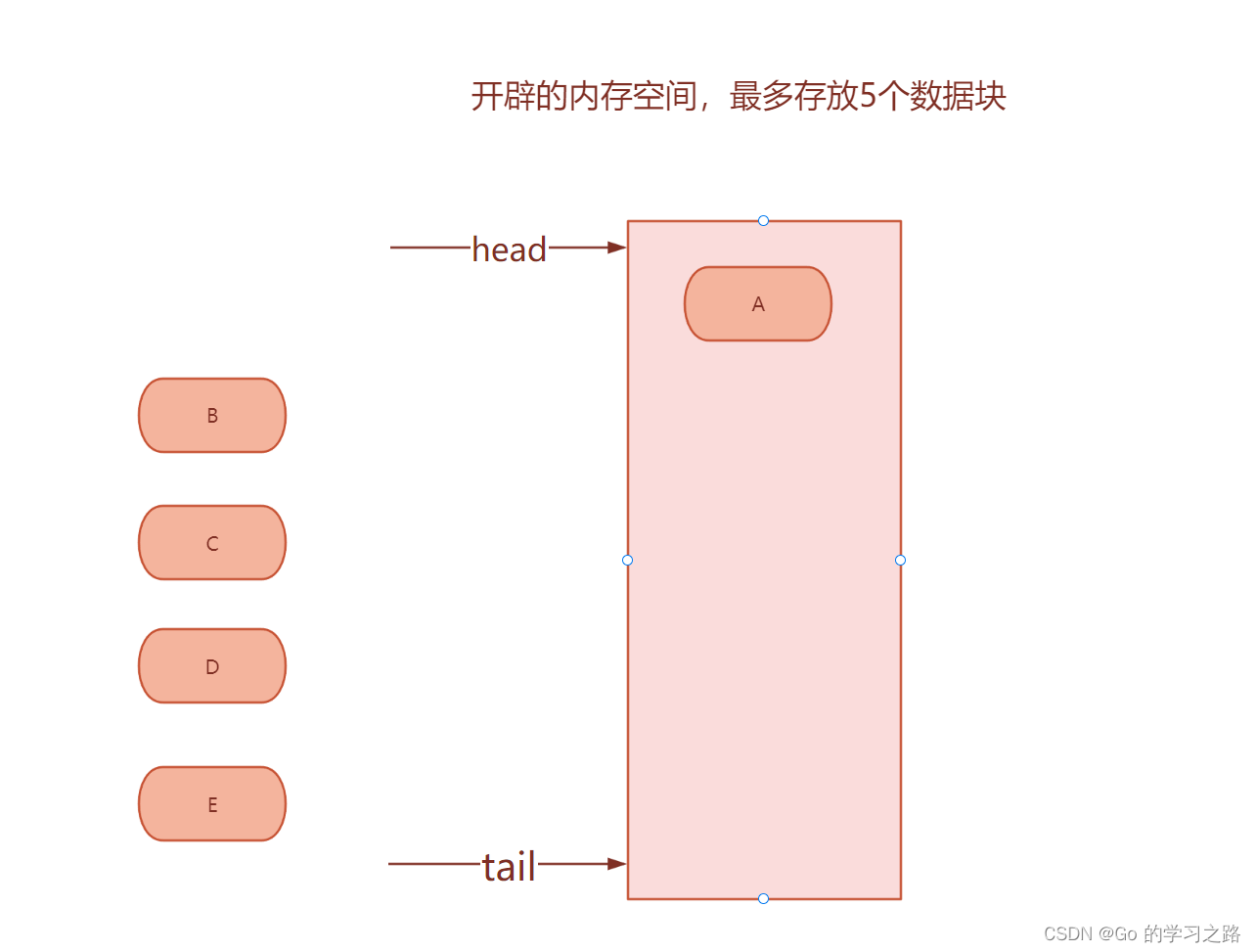 下面一次性插入五个数据块,此时,如果再有元素想插入应该怎么办?
下面一次性插入五个数据块,此时,如果再有元素想插入应该怎么办?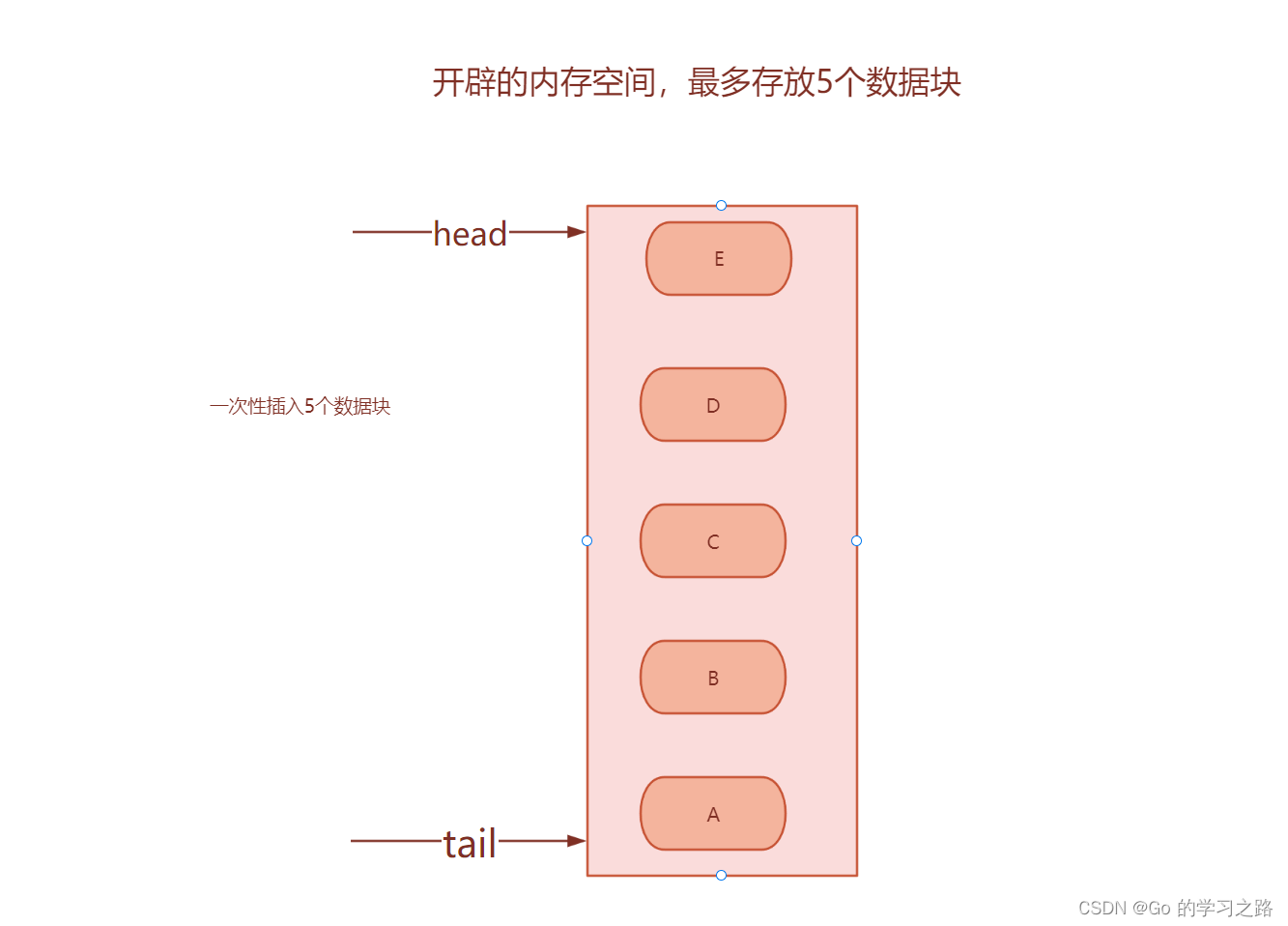
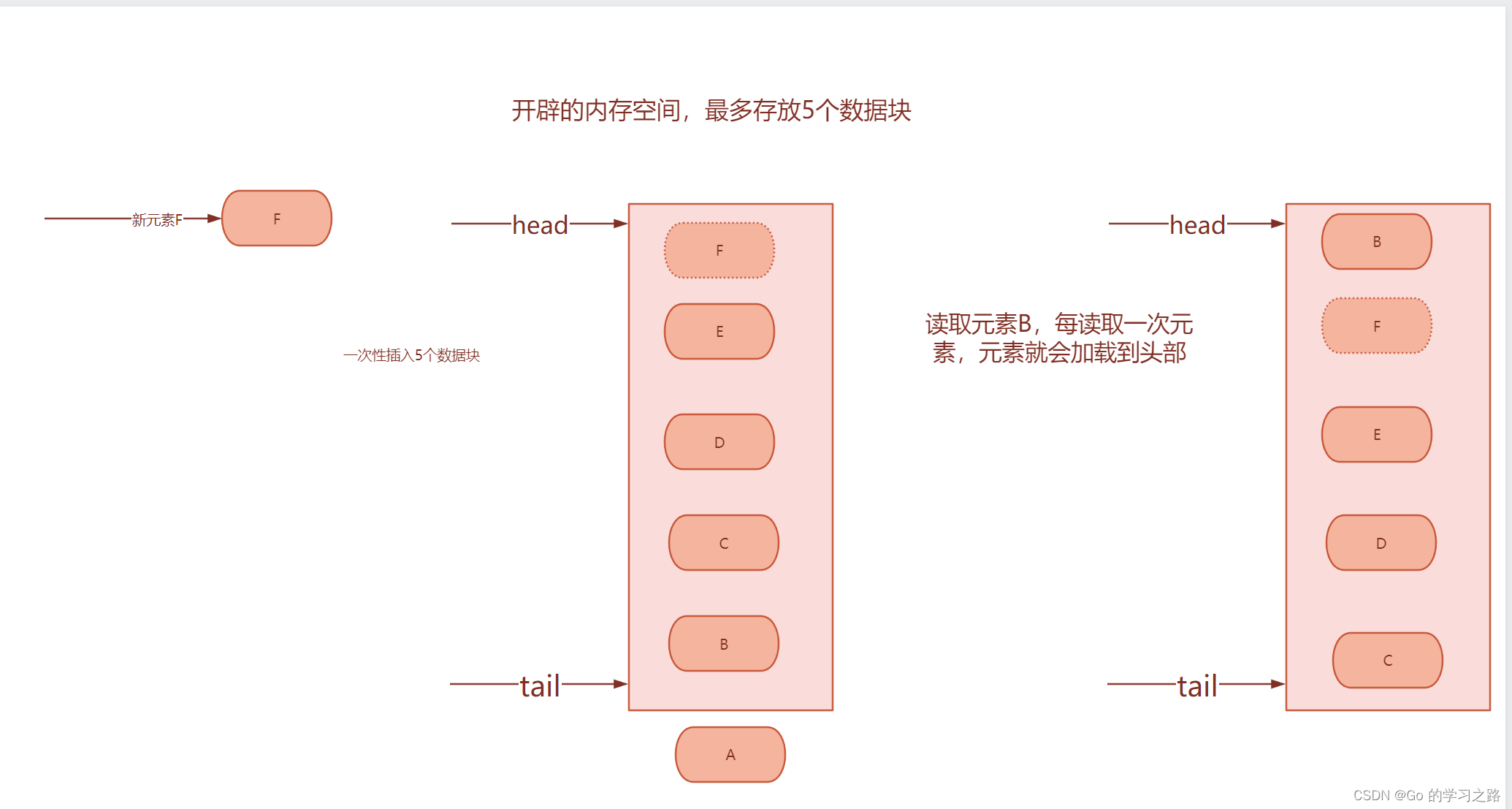
如果内存被读满,那么他就会
淘汰链表的最后一个元素
,如果读取链表中的元素,他就会加载到
链表的头部
代码的具体实现
代码和双链表的思想一样,只不过加入了一个hashmap
package main
import("fmt")// LruNode创建双链表的节点type LruNode struct{
next, prev *LruNode
Value any
Key string
list *LRU
}type LRU struct{
Length uint
maxBytes uint
Cache map[string]*LruNode
root LruNode
}funcNewLRU()*LRU {returnnew(LRU).Init()}func(l *LRU)Init()*LRU {
l.root.next =&l.root
l.maxBytes =5
l.root.prev =&l.root
l.Cache =make(map[string]*LruNode)
l.Length =0return l
}// FrontBack 前插func(l *LRU)FrontBack(k string, v any){if node, ok := l.Cache[k];!ok {
nodeNow :=&LruNode{Value: v, Key: k}
l.Cache[k]= nodeNow
l.insert(nodeNow,&l.root)if l.Length+1> l.maxBytes {delete(l.Cache, l.root.prev.Key)
l.delete(l.root.prev)}}else{delete(l.Cache, k)
nodeNow :=&LruNode{Value: v, Key: k}
l.Cache[k]= node
l.insert(nodeNow,&l.root)}}// GetValue 查找k,vfunc(l *LRU)GetValue(k string)(val any, ok bool){if node, ok := l.Cache[k]; ok {
l.delete(node)
l.insert(node,&l.root)return node.Value, ok
}returnnil, ok
}func(l *LRU)insert(node, root *LruNode){
node.prev = root
node.next = root.next
node.prev.next = node
node.next.prev = node
l.Length++
node.list = l
}func(l *LRU)delete(node *LruNode){
node.prev.next = node.next
node.next.prev = node.prev
l.Length--}// PrintlnDList 打印双链表的所有元素func(l *LRU)PrintlnDList1(){if l.Length ==0{}
prev := l.root.next
index :=0for prev.Value !=nil{
fmt.Printf("下标index: %d 元素 Element: %d\n", index, prev.Value)
prev = prev.next
index++}return}funcmain(){
a :=NewLRU()
a.FrontBack("1",1)
a.FrontBack("2",2)
a.FrontBack("3",3)
a.FrontBack("4",4)
a.FrontBack("5",5)
a.FrontBack("5",5)
a.FrontBack("6",6)
a.FrontBack("7",7)
a.GetValue("4")
a.PrintlnDList1()}
本文转载自: https://blog.csdn.net/qq_29647593/article/details/135828655
版权归原作者 Go 的学习之路 所有, 如有侵权,请联系我们删除。
版权归原作者 Go 的学习之路 所有, 如有侵权,请联系我们删除。