
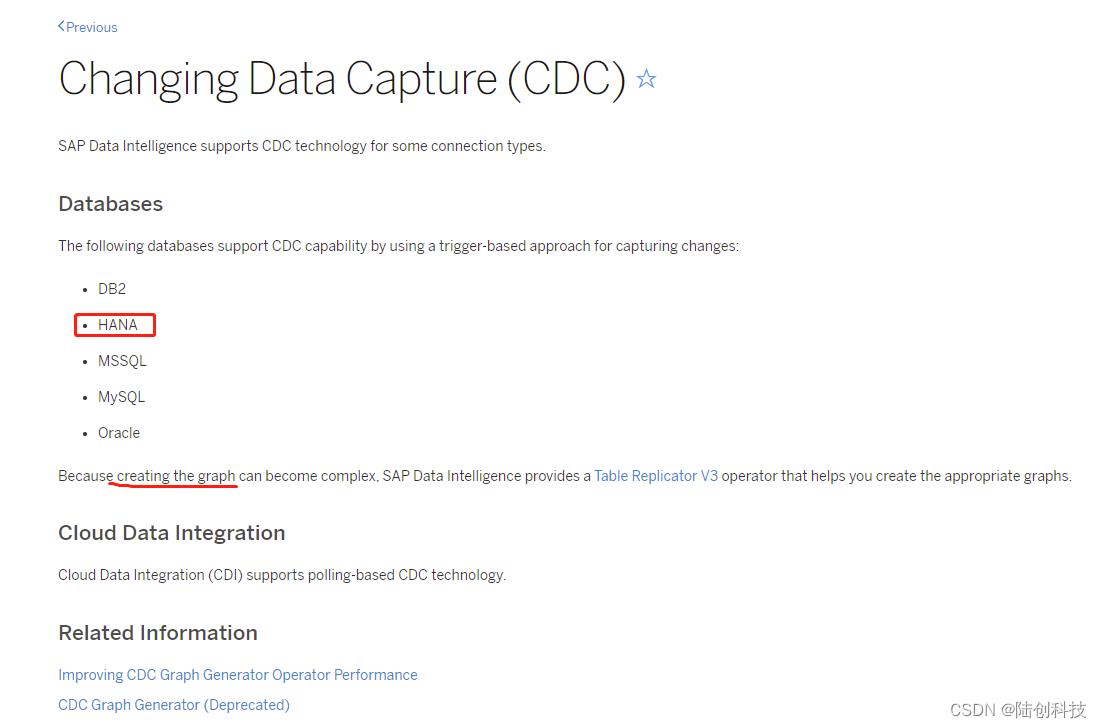
hana数据库实时同步目前接触到有两种方式,一种是通过kafka connector的方式,定时全量或增量的拉取数据发送到kafka,这算是一种伪实时的方式;还有一种hana本身支持cdc,但是像Debezium这种实时增量同步工具并没有提供对应的connectors,通过查阅hana官方文档,目前好像只能在sap系统基础上通过graph编程的方式来搞,他是一种可视化的组件开发方式,目前暂无sap环境,打不开这个可视化的graph编程页面,不好尝试
目前先介绍第一种伪实时的数据同步方式
kafka原生没有提供连接sap的connector,基于github上开源的项目kafka-connector-hana来实现,github地址:GitHub - SAP/kafka-connect-sap: Kafka Connect SAP is a set of connectors, using the Apache Kafka Connect framework for reliably connecting Kafka with SAP systems
步骤:
1.项目下载,打包
在modules目录下会生成两个jar包,区分不同的scala版本
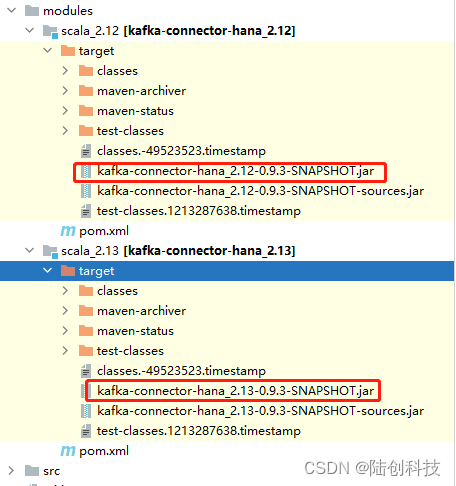
由于我们的kafka环境是scala2.13版本,所以此处采用kafka-connector-hana_2.13-0.9.3-SNAPSHOT.jar
- 部署
将kafka-connector-hana_2.13-0.9.3-SNAPSHOT.jar和sap的jdbc驱动包ngdbc-2.5.49.jar放置到kafka环境的libs目录中
示例:
1.定时全量同步表TEST_TABLE1数据到kafka
创建配置文件connect-hana-source-1.properties,将文件放置到kafka环境的config目录
name=test-topic-1-source
connector.class=com.sap.kafka.connect.source.hana.HANASourceConnector
tasks.max=1
topics=test_topic_1
connection.url=jdbc:sap://10.88.36.186:39017?reconnect=true
connection.user=SYSTEM
connection.password=1234@Qwer!
test_topic_1.table.name="TEST"."TEST_TABLE1"
test_topic_1.poll.interval.ms=60000
执行如下命令:
./bin/connect-standalone.sh config/connect-standalone.properties config/connect-hana-source-1.properties
kafka将接收到如下消息,包含了字段信息和记录信息

2.定时增量同步表TEST_TABLE1数据到kafka
创建配置文件connect-hana-source-2.properties,将文件放置到kafka环境的config目录
(增量同步,要求表中有增量标识字段)
name=test-topic-2-source
connector.class=com.sap.kafka.connect.source.hana.HANASourceConnector
tasks.max=1
mode=incrementing
topics=test_topic_2
connection.url=jdbc:sap://10.88.36.186:39017?reconnect=true
connection.user=SYSTEM
connection.password=1234@Qwer!
test_topic_2.table.name="TEST"."TEST_TABLE1"
test_topic_2.poll.interval.ms=10000
test_topic_2.incrementing.column.name=ID
往表中插入两条数据,kafka收到的消息如下:

可以看到此处都是增量的消息
配置说明:
- topics - This setting can be used to specify a comma-separated list of topics. Must not have spaces.
- mode- This setting can be used to specify the mode in which data should be fetched from SAP DB table. Default is bulk. And supported values are bulk, incrementing.
- queryMode- This setting can be used to specify the query mode in which data should be fetched from SAP DB table. Default is table. And supported values are table, query ( to support sql queries ). When using queryMode: query it is also required to have query parameter defined. This query parameter needs to be prepended by TopicName. If the incrementing.column.name property is used together to constrain the result, then it can be omitted from its where clause.
- {topic}.table.name- This setting allows specifying the SAP DB table name where the data needs to be read from. Should be a String. Must be compatible to SAP DB Table name like "SCHEMA"."TABLE".
- {topic}.query- This setting allows specifying the query statement when queryMode is set to query. Should be a String.
- {topic}.poll.interval.ms- This setting allows specifying the poll interval at which the data should be fetched from SAP DB table. Should be an Integer. Default value is 60000.
- {topic}.incrementing.column.name- In order to fetch data from a SAP DB table when mode is set to incrementing, an incremental ( or auto-incremental ) column needs to be provided. The type of the column can be numeric types such as INTEGER, FLOAT, DECIMAL, datetime types such as DATE, TIME, TIMESTAMP, and character types VARCHAR, NVARCHAR containing alpha-numeric characters. This considers SAP DB Timeseries tables also. Should be a valid column name ( respresented as a String) present in the table. See data types in SAP HANA
- {topic}.partition.count- This setting can be used to specify the no. of topic partitions that the Source connector can use to publish the data. Should be an Integer. Default value is 1.
基于官方的cdc方案
官方文档中所描述的sap的cdc,是基于触发器实现的

如果要体验sap本身提供的该功能,需安装SAP Data Intelligence,所需服务器资源比较大,而且要求是3个节点,部署教程:
[Quick Start Guide – Part I] Installing SAP Data Intelligence on Red Hat Openshift | SAP Blogs
如果不在此平台操作,我们自己的实现思路是这样(该思路也是网上找到的):
1.创建目标表的日志表
-- 目标表
CREATE COLUMN TABLE "PAX" ("ID" INTEGER CS_INT GENERATED BY DEFAULT AS IDENTITY, "NAME" VARCHAR(64), PRIMARY KEY ("ID")) UNLOAD PRIORITY 5 AUTO MERGE ;
-- 目标表的日志表
CREATE COLUMN TABLE "PAX_JOURNAL" ("ID_JOURNAL" INTEGER CS_INT GENERATED BY DEFAULT AS IDENTITY, "ACTION_JOURNAL" VARCHAR(1), "TIMESTAMP_JOURNAL" LONGDATE CS_LONGDATE, "ID" INTEGER CS_INT, "NAME" VARCHAR(64), PRIMARY KEY("ID_JOURNAL")) UNLOAD PRIORITY 5 AUTO MERGE ;
2.创建触发器trigger,监听目标表的insert,update,delete操作,在目标表有此类操作时,会将日志写到对应的日志表中
--触发器,此处只监听了update
CREATE TRIGGER "TRG_PAX_AFTER_ROW_UPDATE" AFTER
UPDATE
ON
"PAX" REFERENCING NEW ROW mynewrow FOR EACH ROW
BEGIN
INSERT
INTO
PAX_JOURNAL (ACTION_JOURNAL, TIMESTAMP_JOURNAL, ID, NAME)
VALUES ('U', CURRENT_TIMESTAMP, :mynewrow.ID, :mynewrow.NAME);
end;
3.采用本文档上半部分所描述的kafka-connector,定时读取日志表中的内容发送至kafka平台
(猜想:既然sap的cdc是基于trigger实现,那么SAP Data Intelligence平台上的基于图形化的hana cdc组件最底层也是采用trigger实现,只不过做了层封装,如自动建日志表,自动建trigger,然后将change log写到targets)
版权归原作者 陆创科技 所有, 如有侵权,请联系我们删除。