
Pandas是我们最常用的数据处理Python库之一。尽管您可能已经与它共事多年,但可能还有许多您尚未探索的实用方法。我将向您展示一些可能未曾听说但在数据整理方面非常实用的方法。

我目前日常使用的是pandas 2.2.0,这是本文时可用的最新版本。
import pandas as pd
import numpy as np
print(pd.__version__)
1、agg
你可能已经熟悉使用pandas进行聚合操作,比如使用sum或min等方法。可能也已经结合groupby使用过这些方法。agg方法可以在DataFrame上执行一个或多个聚合操作。
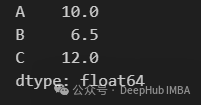
通过将字典传递给agg方法,指示要为DataFrame的每一列计算哪些聚合操作(sum、mean、max等)。字典的键表示我们要对其执行聚合操作的列,而值表示我们要执行的操作。
data = {
"A": [1, 2, 3, 4],
"B": [5, 6, 7, 8],
"C": [9, 10, 11, 12],
}
df = pd.DataFrame(data)
df.agg({"A": "sum", "B": "mean", "C": "max"})
agg并不仅限于为每列传递单个操作。在下一段代码中可以计算列A总和和平均值
df.agg({"A": ["sum", "mean"], "B": "mean", "C": "max"})
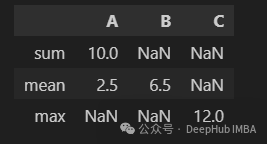
在生成的DataFrame中,可以观察到一些NaN值,这些值对应于字典中没有请求的列和操作的组合。
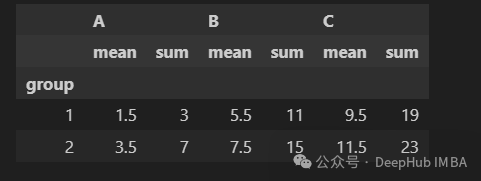
下面我们添加一个分组列。要计算每个两个组内所有三列的平均值和总和。
data = {
"group": [1, 1, 2, 2],
"A": [1, 2, 3, 4],
"B": [5, 6, 7, 8],
"C": [9, 10, 11, 12],
}
df = pd.DataFrame(data)
df.groupby("group").agg(["mean", "sum"])
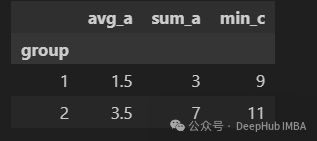
最后,就是我们可以将最终生成的列重新命名:
df.groupby("group").agg(
avg_a=("A", "mean"),
sum_a=("A", "sum"),
min_c=("C", "min"),
)
2、assign
assign方法用于创建带有附加列的新DataFrame,并根据现有列或操作分配值。
df = pd.DataFrame({"Value": [10, 15, 20, 25, 30, 35]})
df.assign(value_cat=np.where(df["Value"] > 20, "high", "low"))

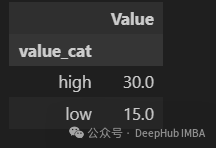
这种方法在链式操作中最有用,因为我们不一定对中间步骤感兴趣,并且并不想将中间结果添加到原始DataFrame中。
df.assign(value_cat=np.where(df["Value"] > 20, "high", "low")).groupby(
"value_cat"
).mean()
3、combine_first
combine_first方法用于组合两个Series(或DataFrame中的列),从第一个Series中选择值,并用第二个Series中的相应值填充任何缺失的值。
如果你对SQL熟悉的话,那么pandas的combine_first方法类似于SQL中的COALESCE函数。
s1 = pd.Series([1, 2, np.nan, 4, np.nan, 6])
s2 = pd.Series([10, np.nan, 30, 40, np.nan, 60])
s1.combine_first(s2)
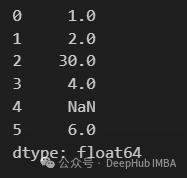
可以看到s1中缺失的值被s2的值填充。如果s2也是缺失值,则结果为缺失值。这种方法也可以用于DataFrame的列。
如果我们希望使用2列以上的列来更新缺失的值,我们也可以链接combine_firstmethods。
4、cumsum / cummin / cummax / cumprod
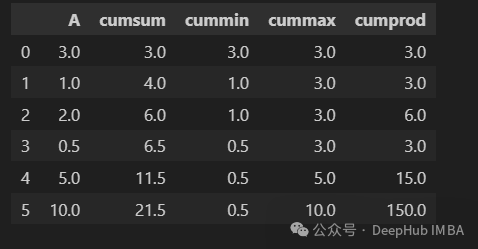
cumsum、cummin、cummax和cumprod方法用于计算Series或DataFrame中元素的累积和、最小值、最大值和乘积。
data = {
'A': [3, 1, 2, 0.5, 5, 10],
}
df = pd.DataFrame(data)
df["cumsum"] = df["A"].cumsum()
df["cummin"] = df["A"].cummin()
df["cummax"] = df["A"].cummax()
df["cumprod"] = df["A"].cumprod()
df
5、cut / qcut
cut函数将数据划分为相同宽度的桶。这意味着每个桶都有相同的范围,但是每个桶中的数据点数量可能不同。
df = pd.DataFrame(
{
"name": ["Alice", "Bob", "Charlie", "Dylan", "Eve", "Frank"],
"years_of_exp": [10, 2, 0, 5, 6, 8],
}
)
pd.cut(df["years_of_exp"], bins=3)
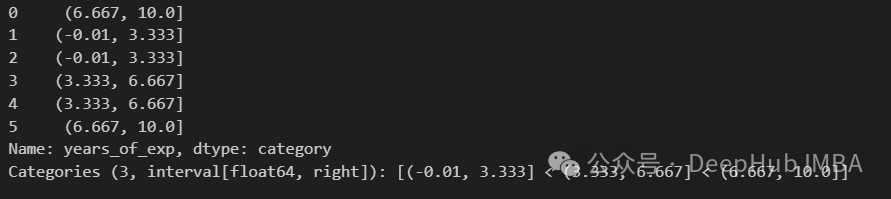
cut函数将所有观测值分类到三个长度相等(长度约为3.33)的桶中。
这里需要强调下区间符号。
[0,10]:区间两边都闭合,即同时包含0和10
(0,10):间隔两边都不闭合,即不包括0和10
[0,10):区间左侧闭合,表示包含0,但不包含10。
我们可以定义桶的区间
exp_bins = [0, 2, 5, 10]
pd.cut(df["years_of_exp"], bins=exp_bins)
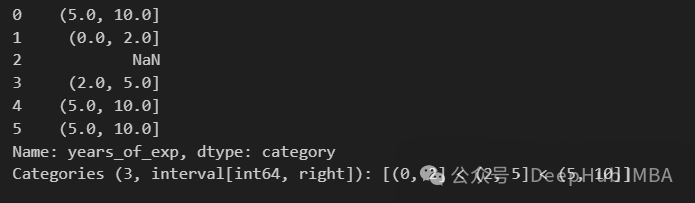
在输出中看到一个NaN值。这是因为最低值不包括在范围内。我们可以通过将include_lowest设置为True来解决这个问题。
还可以为桶分配自定义标签名称,这在特征工程时特别有用
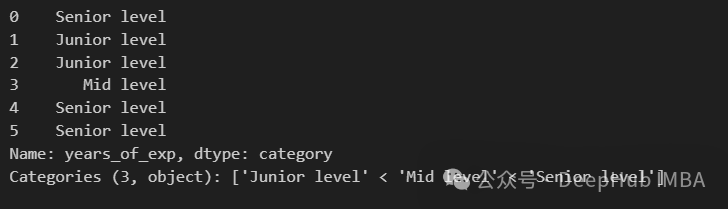
exp_labels = ["Junior level", "Mid level", "Senior level"]
pd.cut(df["years_of_exp"], bins=exp_bins, include_lowest=True, labels=exp_labels)
qcut函数根据分位数将数据划分为桶。这确保了每个桶具有大致相同数量的数据点。
pd.qcut(df["years_of_exp"], q=3)
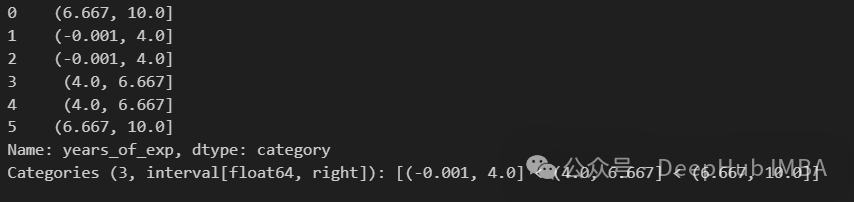
使用qcut每个桶中都有2个值。cut根据区间划分数据,而qcut则根据分位数划分数据。
6、duplicate / drop_duplicate
duplicate方法返回一个boolean Series,指示DataFrame中的每个元素是否重复(True)或不重复(False)。
data = {"A": [1, 2, 2, 3, 4, 4], "B": ["x", "y", "y", "z", "w", "w"]}
df = pd.DataFrame(data)
df.duplicated()
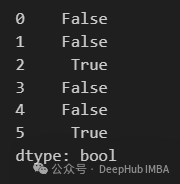
duplicate的默认设置 keep="first" ,保留第一个匹配的值,并将所有后续的观测值标记为duplicate.
也可以使用 keep="last" 保留最后的值,还可以使用keep=False 将所有的重复值标记为True
df.duplicated(keep=False)

最后使用drop_duplduplicate方法直接删除重复项。drop_duplduplicate方法也可以设置keep参数
df.drop_duplicates()
7、isin
isin方法用于筛选Series和dataframe,该方法返回一个布尔Series,显示列中的每个值是否在指定值范围内。
data = {
"Name": ["Alice", "Bob", "Charlie", "David", "Eve"],
"Value": [1, 1, 1, 2, 2],
}
df = pd.DataFrame(data)
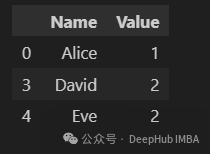
selected_names = ["Alice", "David", "Eve"]
df[df["Name"].isin(selected_names)]
8、merge_ordered
merge_ordered函数用来合并两个dataframe。当我们有两个具有顺序的dataframe,并且希望在保持索引的顺序的同时合并它们时(比如说时间序列),这个函数特别有用。
df1 = pd.DataFrame(
{
"date": pd.date_range(start="2022-01-01", periods=5)[::-1],
"value_df1": [10, 15, 20, 25, 30],
}
)
df2 = pd.DataFrame(
{
"date": pd.date_range(start="2022-01-03", periods=4)[::-1],
"value_df2": [100, 150, 250, 300],
}
)
pd.merge_ordered(df1, df2, on="date", fill_method="ffill")
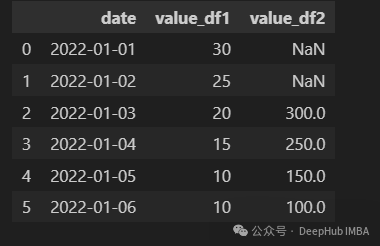
merge_ordered中连接的默认是outer join,所以fill_method需要设置一种方法来填充缺失值。
9、pct_change
pct_change用于计算Series或DataFrame中当前元素和先前元素之间的百分比变化。它用于分析价值随时间变化的百分比,特别是在金融时间序列数据中,例如股票价格。
data = {
"date": pd.date_range(start="2022-01-01", end="2022-01-05"),
"price": [100, 105, 98, 110, 120],
}
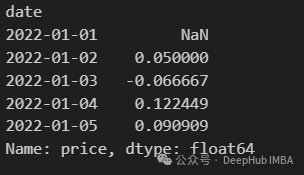
df = pd.DataFrame(data).set_index("date")
df["price"].pct_change()
10、select_dtypes
select_dtypes用于根据数据类型筛选DataFrame中的列。我们可以使用它来选择具有特定数据类型的列,例如数字类型(int64、float64)、对象类型(str、object)、布尔类型或日期时间类型等。
我们选择整数列和浮点列,即数字列。
data = {
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 22],
"salary": [50000.0, 60000.0, 45000.0],
"date_joined": ["2022-01-01", "2022-02-15", "2021-12-10"],
"remote_worker": [True, False, True]
}
df = pd.DataFrame(data)
df.select_dtypes(include=["int64", "float64"])
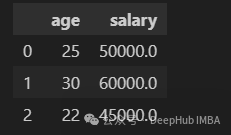
或者可以直接这样写
df.select_dtypes(include="number")
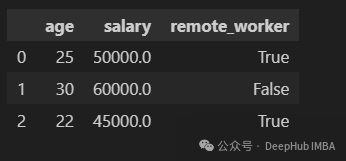
select_dtypes,还可以指定要排除哪些数据类型
df.select_dtypes(exclude="object")
总结
pandas是一个非常庞大的库,我们最常用的只是其中的一些方法,可能还有许多尚未探索的实用方法。希望本文介绍的10各高级技巧可以帮你更有效地处理各种数据,更灵活地满足各种数据处理需求。