
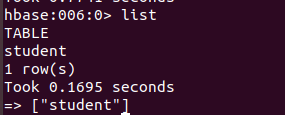
一.实验内容
HBase编程实践:
1)在Hadoop基础上安装HBase;
2)使用Shell命令(create:创建表、list:列出HBase中所有的表信息、put:向表、行、列指定的单元格添加数据等);使用HBase常用Java API创建表、插入数据、浏览数据。
二.实验目的
1、理解HBase在Hadoop体系结构中的角色。
2、熟练使用HBase操作常用的Shell命令。
3、熟悉HBase操作常用的JavaAPI。
三.实验过程截图及说明
1、安装HBase
(1)解压HBase文件到/usr/local目录下,并将目录改名为hbase:

(2)设置访问权限:

(3)编辑~/.bashrc文件:
vim ~/.bashrc
# 如果没有引入过PATH请在~/.bashrc文件尾行添加如下内容:
export PATH=$PATH:/usr/local/hbase/bin
然后输入source ~/.bashrc使配置立即生效
(4)输入hbase version验证一下:
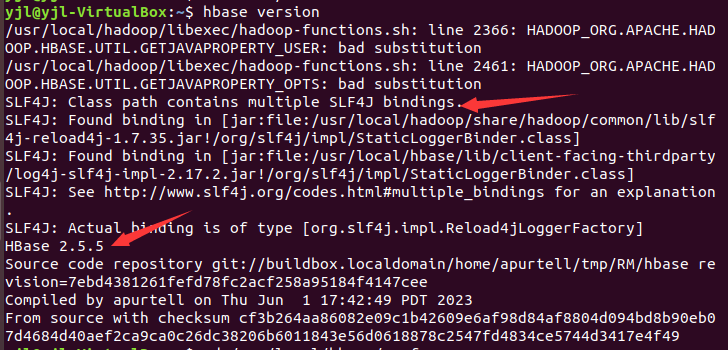
(5)版本没问题,设置成功。但是发现上图第一个箭头所指处有一个警告,SLF4J警告消息表示类路径中存在多个SLF4J绑定。警告提供了检测到的绑定位置,并告知你只能同时使用一个绑定。可以用(6)(7)两步来解决。
(6)进入HBase配置目录,修改配置:

(7)将此行的注释去掉:

(8)验证一下,看看hbase的版本,发现警告消失了,配置成功:

2、配置伪分布式模式:
(1)配置hbase-env.sh文件:


(2)配置hbase-site文件:
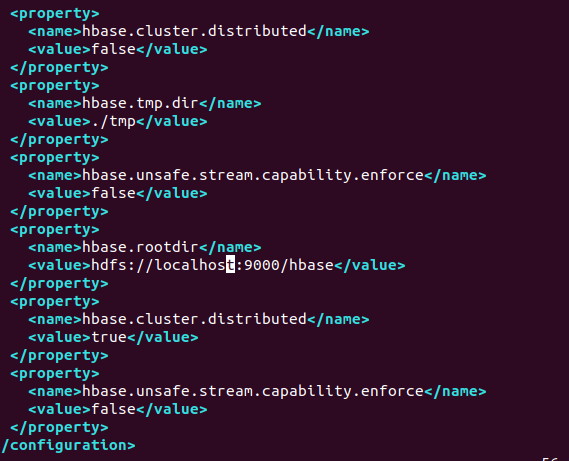
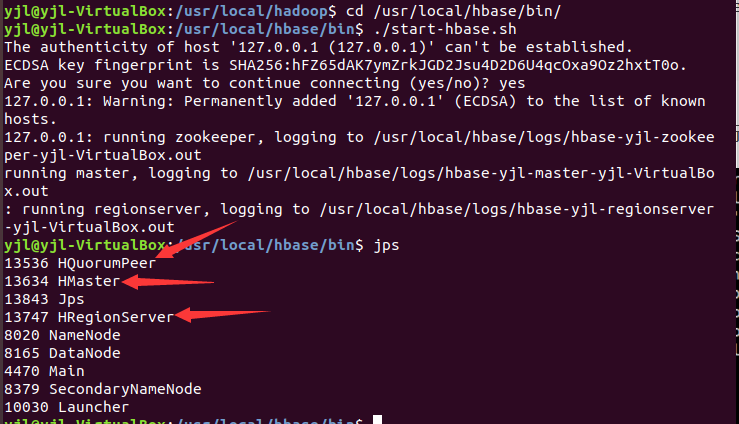
(3)测试运行hbase。先要开启Hadoop,再开hbase,开关顺序一定要是(开启Hadoop->开启hbase->关闭hbase->关闭Hadoop):
开Hadoop:

开hbase:
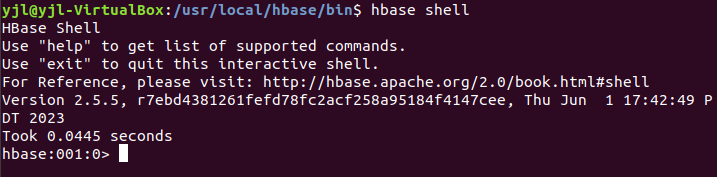
(4)开启hbase的shell命令:
3、使用hbase的shell命令来操作表:
(1)创建表:

(2)list:
(3)使用put命令向某表某行中插入一列:

参数说明: 在student表的行键为95001的行中,插入一个名为Sname的列,并设置其值为YangJile。此处的行键可以代指学生的学号,也可表示为student表添加了学号为95001,名字为YangJile的一行数据,其行键为95001。
hbase中用put命令添加数据,注意:一次只能为一个表的一行数据的一个列,也就是一个单元格添加一个数据,所以直接用shell命令插入数据效率很低,在实际应用中,一般都是利用编程操作数据。

参数说明:在student表的行键为95001的行中,在course列族下存储一个名为math的列,并设置其属性值为80。下同。

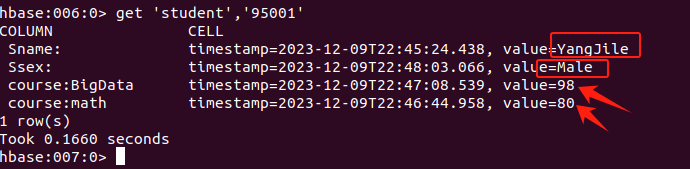
(4)使用get命令查看某表的某行的值:
get命令,用于查看表的某一行数据。
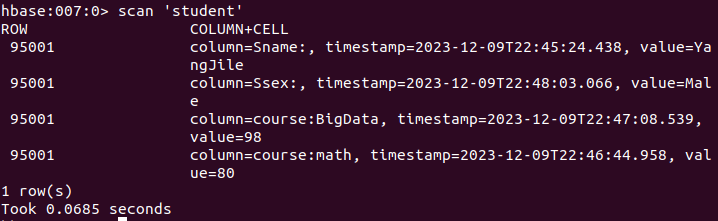
(5)使用scan命令查看表的所有行:
scan命令用于查看某个表的全部数据。
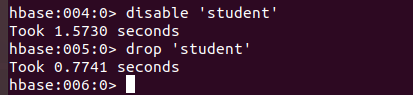
(6)删除表的两步走操作:
先disable,让表不可用,再drop删除表。
4、使用hbase提供的javaAPI来编程实现类似操作:
(1)在com.ecjtu下创建hbase包,再创建一个dataSqlOP.java文件:

(2)导入需要用到的依赖:

(3)编写初始化函数:

(4)编写创建表函数:

(5)编写插入数据函数;

(6)编写获取数据函数:
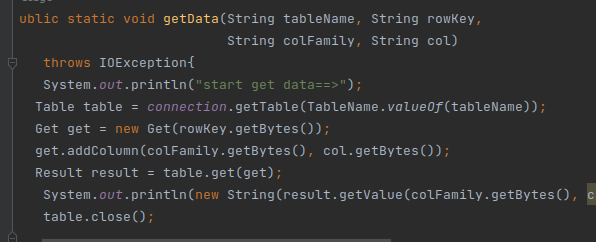
(7)编写主函数,在主函数中调用各个方法测试运行:
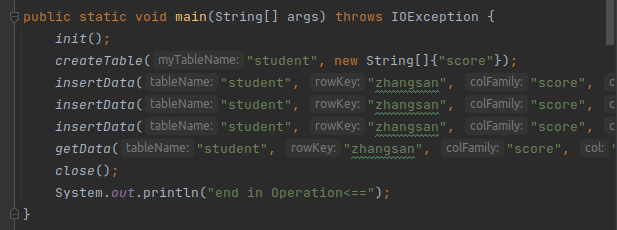
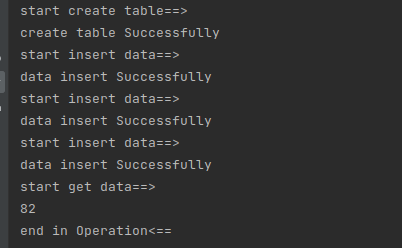
(8)运行结果:
5、实验总结及心得体会
实验总结:
在本实验中,我深入了解了HBase在Hadoop体系结构中的角色,以及其常用的Shell命令和Java API。
(1)首先,我在Hadoop基础上成功安装了HBase,为其后续应用奠定了基础。
(2)在Shell命令方面,我实践了创建表(create)、列出HBase中所有的表信息(list)、向表、行、列指定的单元格添加数据(put)等操作。这些命令帮助我们更好地管理和操作HBase表格,为大数据处理提供了便利。
(3)此外,我还使用了HBase常用的Java API来创建表、插入数据、浏览数据。通过这些API,我实现了对HBase表格的编程操作,进一步提高了数据处理效率。
(4)实验的二个目的是让我熟练掌握HBase的操作,从而在实际应用中能够灵活运用。通过对HBase角色、Shell命令和Java API的学习,我能够更好地应对各种数据处理挑战,为我国大数据领域的发展贡献力量。
(5)总之,本次实验使我受益匪浅,对HBase的认识和操作水平得到了全面提升。在未来的学习和工作中,我将不断探索和实践,为大数据技术的发展贡献自己的力量。
心得体会:
在这次的HBase编程实践中,我深深地理解了HBase在Hadoop体系结构中的角色。HBase是一个分布式的、版本化的典型非关系型数据库,它被设计用来处理海量数据,并提供了随机读写访问数据的能力。在Hadoop的文件系统HDFS之上,HBase提供了实时读写访问数据的能力。
我首先在Hadoop环境下安装了HBase,然后使用Shell命令创建了一个表,并通过list命令列出了HBase中所有的表信息。接着,我使用put命令向表、行、列指定的单元格添加数据。这些操作都是通过HBase的Shell命令完成的,这让我对HBase的操作有了初步的了解。
接下来,我使用了HBase的Java API进行编程。在这个过程中,我深入了解了HBase的内部机制,包括它如何在内部管理数据,以及如何通过Java API进行操作。我也了解了HBase的一些特性,比如它如何支持实时读写,以及它如何通过水平扩展来应对大数据量的存储和处理。
总的来说,这次的HBase编程实践让我收获颇丰。我不仅掌握了HBase的基本操作,而且对HBase的工作原理和特性有了更深的理解。我相信这些知识和经验将对我未来的学习和工作产生积极的影响。
6、完整报告在文章开头,挂载。
版权归原作者 我要八百米跑 所有, 如有侵权,请联系我们删除。