
使用Intellij idea编写Spark应用程序(Scala+Maven)
对Scala代码进行打包编译时,可以采用Maven,也可以采用sbt,相对而言,业界更多使用sbt。这里介绍IntelliJ IDEA和Maven的组合使用方法。IntelliJ IDEA和SBT的组合使用方法,请参考“使用Intellij Idea编写Spark应用程序(Scala+SBT)”。
安装 IntelliJ IDEA
本次运行系统为Ubuntu16.04。
我们可以访问官网下载安装包。文件较大,一般需要20分钟左右。有两种下载选择,我们选择下载正版,教程将使用试用版的idea。
下载后,我们把压缩包解压并且改名。
cd ~/下载sudo tar -zxvf ideaIU-2016.3.4.tar.gzsudo mv idea-IU-163.12024.16 /usr/local/Intellij
然后打开Intellij文件夹,并且使用其bin文件夹下的idea.sh打开程序。
cd /usr/local/Intellij/bin./idea.sh
会出现如图界面。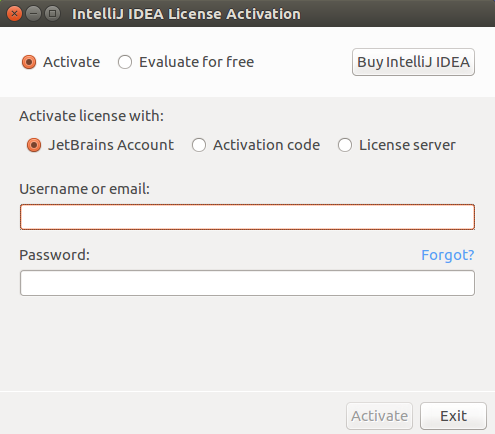
选择Ecalute for free进入免费试用版。
接下来要把程序放到启动栏里快捷启动。
首先进入到applications文件夹下,并且编辑idea.desktop文件
cd /usr/share/applicationssudo gedit idea.desktop
在打开的文档里添加如下内容
[Desktop Entry]Encoding=UTF-8Version=1.0Name=IntelliJ IDEAGenericName=Java IDEComment=IntelliJ IDEA is a code-centric IDE focused on developer productivity. The editor deeply understands your code and knows its way around the codebase, makes great suggestions right when you need them, and is always ready to help you shape your code.Exec=/usr/local/Intellij/bin/idea.shIcon=/usr/local/Intellij/bin/idea.pngTerminal=falseType=ApplicationCategories=Development;IDE
然后在启动栏里选择查找程序的那个应用(一般在启动栏第一个)。搜索Intellij即可找到程序,点击就可以启动idea。这时候就可以把程序锁定到启动栏使用了。如果搜索没找到,请重启系统。
在Intellij里安装scala插件,并配置JDK,scala SDK
首先如图打开plugins界面。
然后我们点击Install JetBrain Plugins…如下图
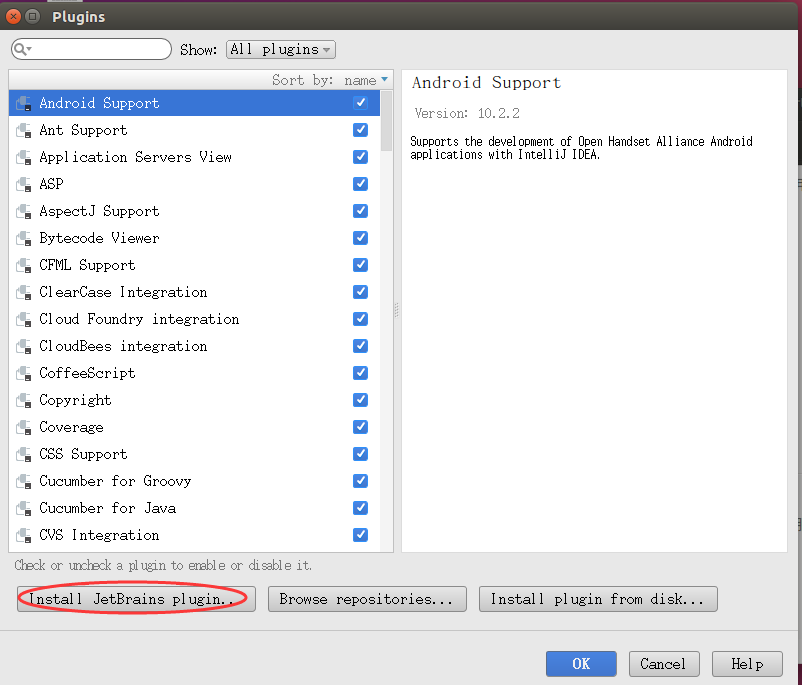
搜索并安装scala。
等待安装完成后我们就可以配置JDK跟scala SDK。
配置JDK
首先打开 Project Structure,如下图。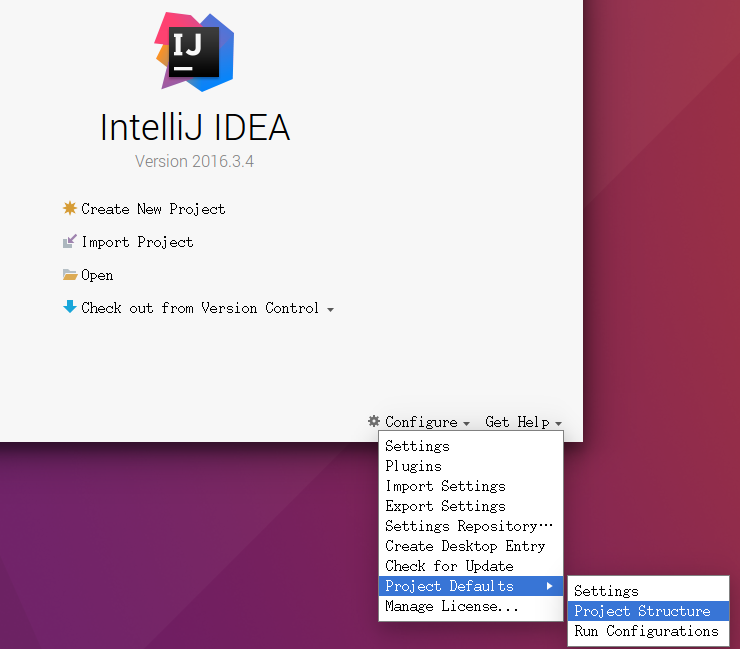
添加JDK(这里默认已经安装JDK并且配置了环境变量),操作按下面两张图。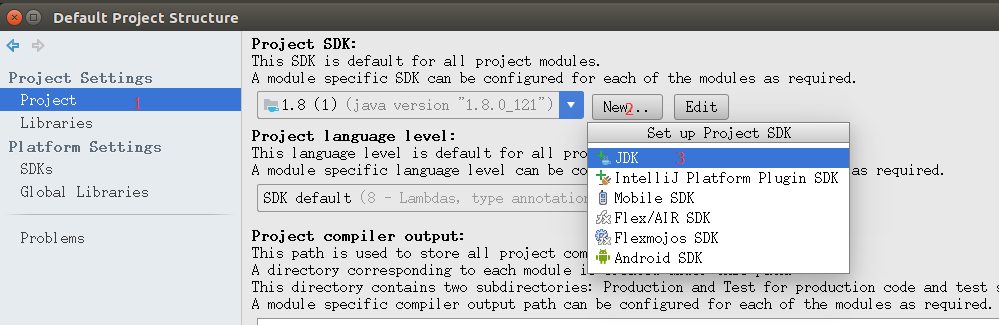
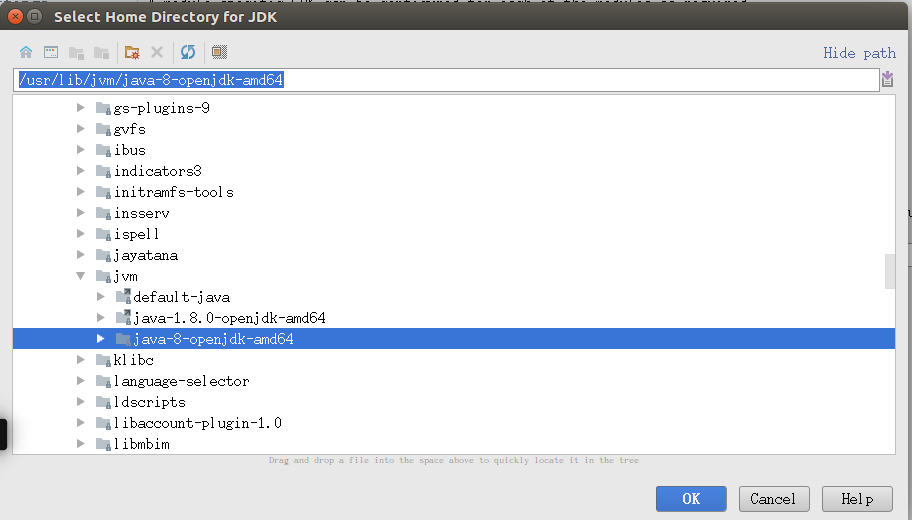
配置全局Scala SDK
还是在Project Structure界面,操作如下。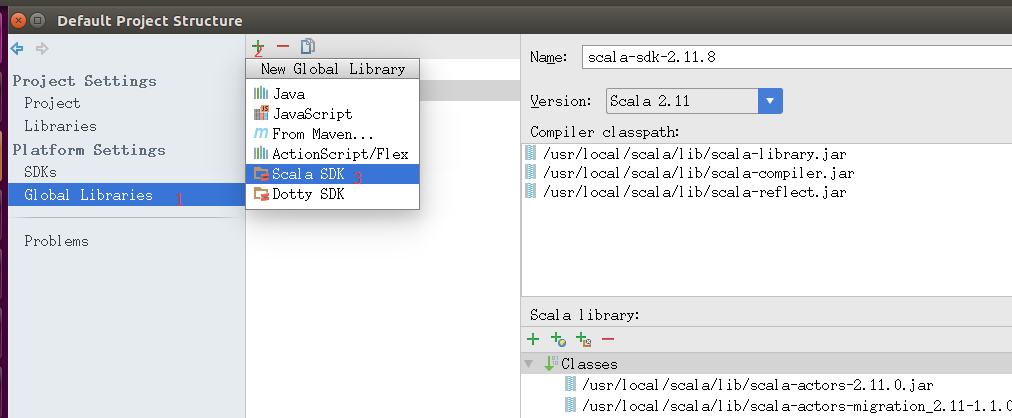
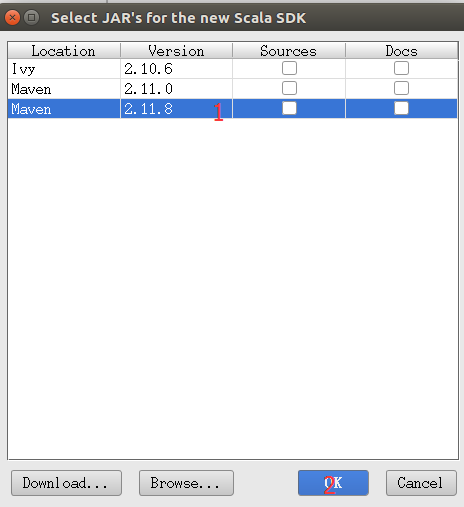
然后右键已经添加的SDK选择Copy to Project Libraries…OK确认。如图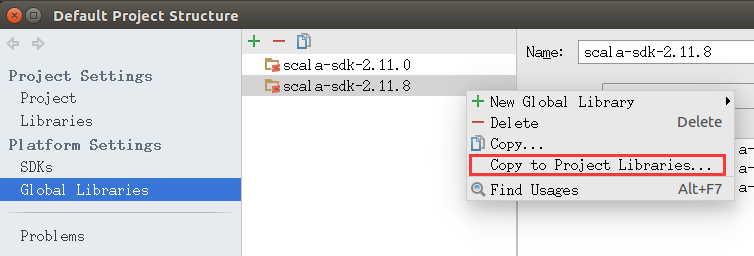
配置好后就可以创建工程文件了。
创建Maven工程文件
点击初始界面的Create New Project进入如图界面。并按图创建Maven工程文件。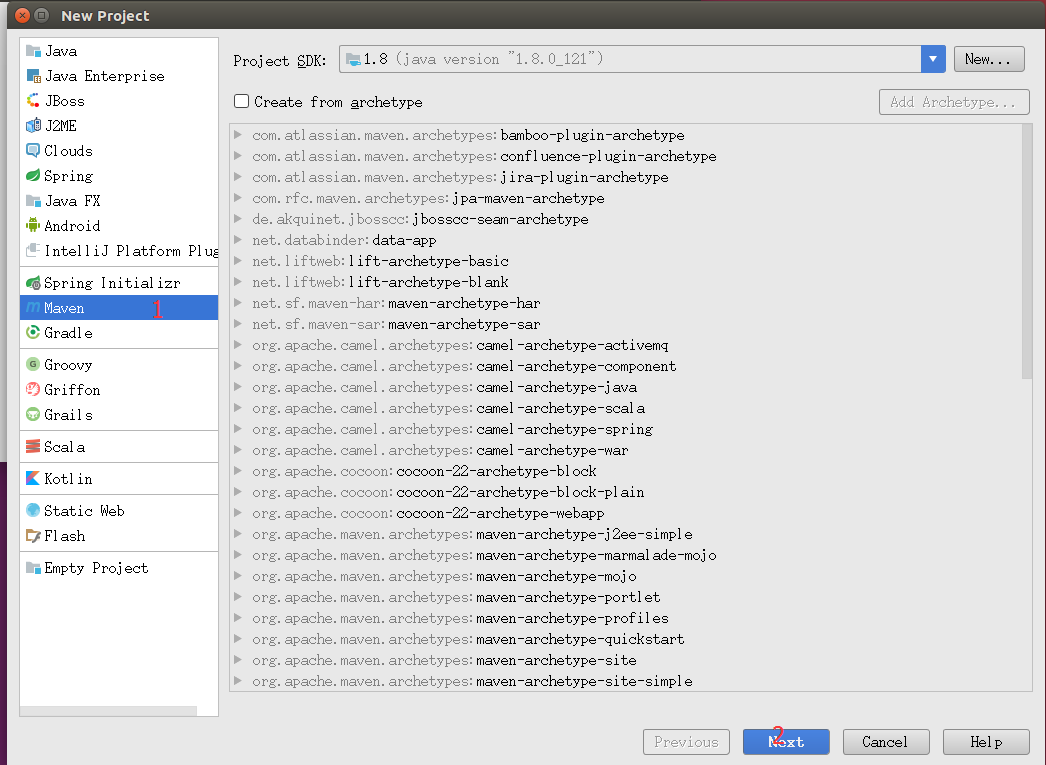
填写GroupId:dblab;以及ArtifactId:WordCount,如图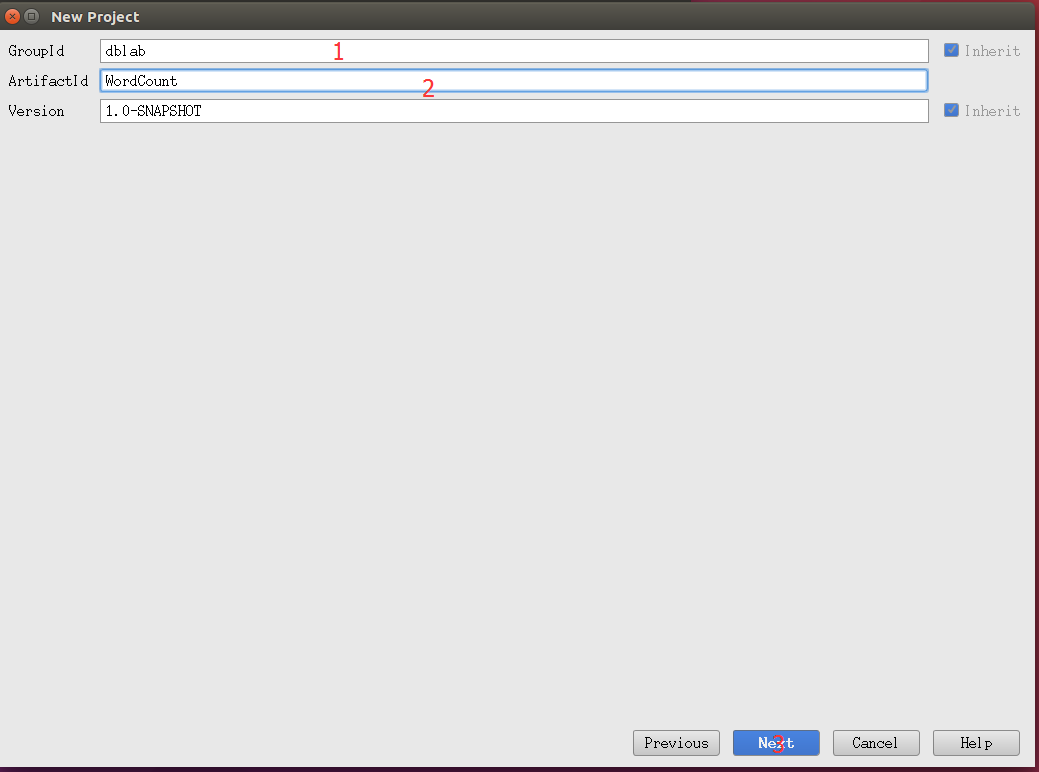
然后按下图填写各项,这一步容易出错请认真填写。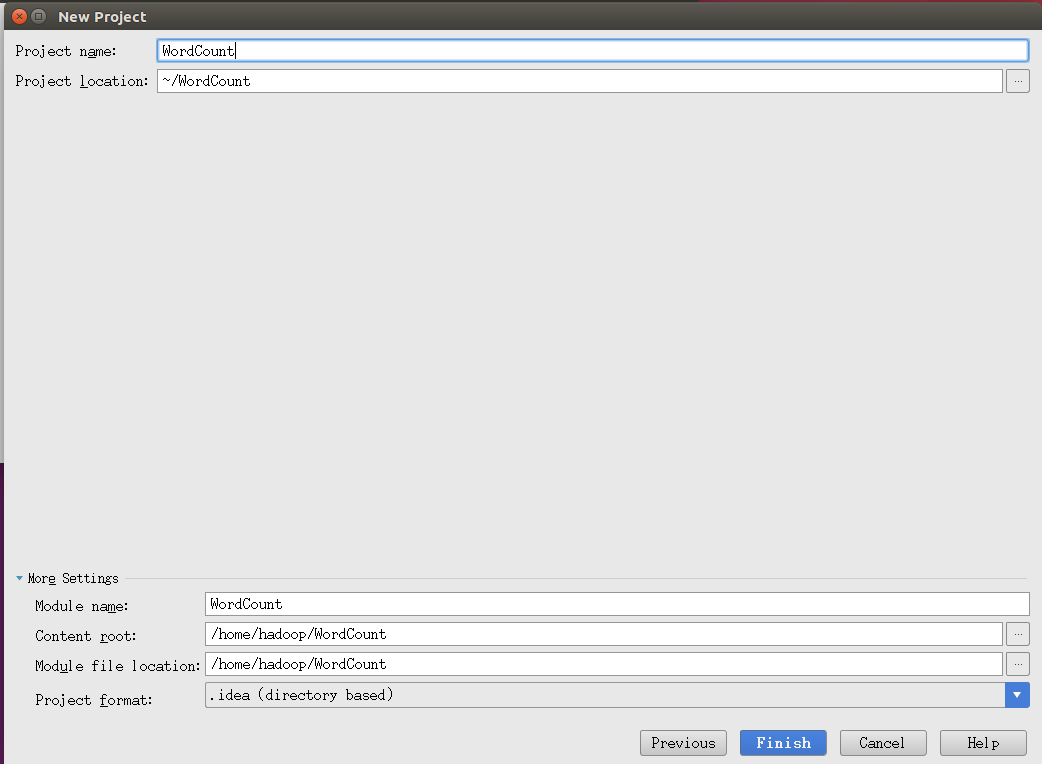
到此创建工程文件完成。
前置的一些配置
将scala框架添加到项目
在IDEA启动后进入的界面中,可以看到界面左侧的项目界面,已经有一个名称为WordCount的工程。请在该工程名称上右键单击,在弹出的菜单中,选择Add Framework Surport ,在左侧有一排可勾选项,找到scala,勾选即可。
创建WordCount文件夹,并作为sources root
在src文件夹下创建一个WordCount文件夹。
右键新建的文件夹,按图把该文件夹设置为sources root。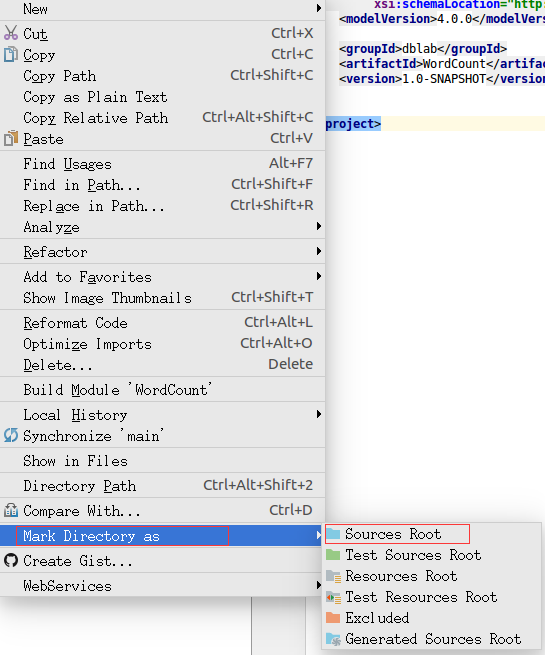
两次的代码黏贴
黏贴wordcount代码到WordCount.scala
然后就可以通过右键刚刚设置为sources root的wordcount文件夹,就有了new->scala class的选项。
我们新建一个scala class,并且命名WordCount,选着为object类型。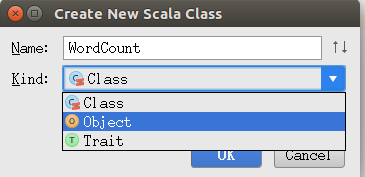
打开建好的WordCount.scala文件,清空!然后黏贴以下代码:
importorg.apache.spark.SparkContext
importorg.apache.spark.SparkContext._
importorg.apache.spark.SparkConf
object WordCount {def main(args: Array[String]){val inputFile ="file:///usr/local/spark/mycode/wordcount/word.txt"val conf =new SparkConf().setAppName("WordCount").setMaster("local")val sc =new SparkContext(conf)val textFile = sc.textFile(inputFile)val wordCount = textFile.flatMap(line => line.split(" ")).map(word =>(word,1)).reduceByKey((a, b)=> a + b)
wordCount.foreach(println)}}
黏贴pom.xml代码
现在清空pom.xml,把以下代码黏贴到pom.xml里。
<?xml version="1.0" encoding="UTF-8"?><projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>dblab</groupId><artifactId>WordCount</artifactId><version>1.0-SNAPSHOT</version><properties><spark.version>2.1.0</spark.version><scala.version>2.11</scala.version></properties><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_${scala.version}</artifactId><version>${spark.version}</version></dependency></dependencies><build><plugins><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><version>2.15.2</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.6.0</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><version>2.19</version><configuration><skip>true</skip></configuration></plugin></plugins></build></project>
黏贴好后,右键点击工程文件夹,更新一下,按下图操作。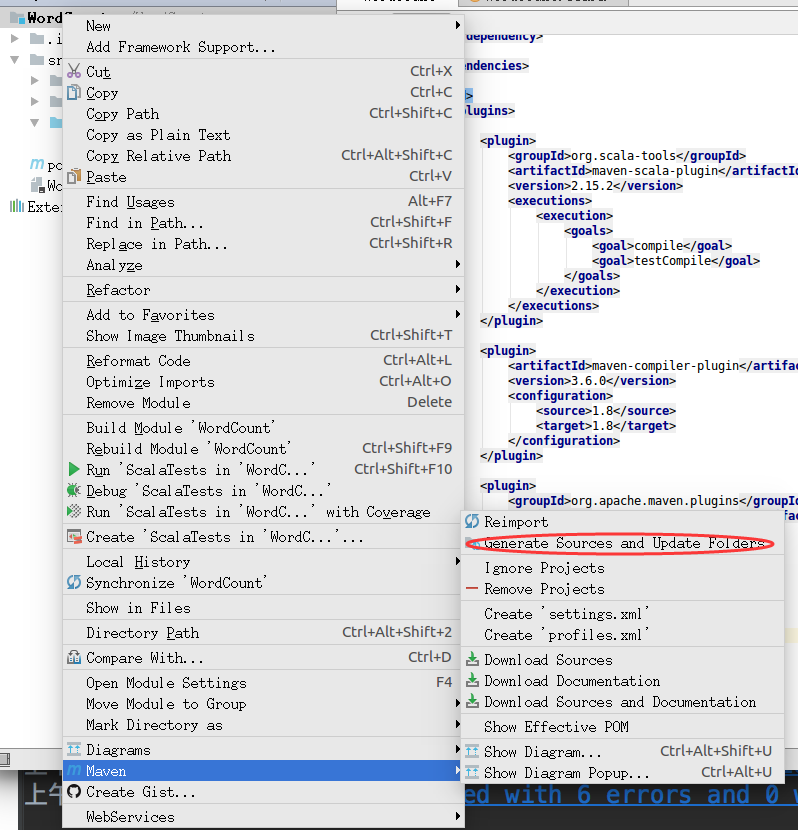
这时候注意要记得点击右下角的“Import Changes Enables Auto-Import ”中的”Enables Auto-Import”。如图。
等待一段时间,可以看底部的进度条。等执行完毕,我们再进行后面的操作。
运行WordCount程序
在WordCount.scala代码窗口内的任意位置,右键点击,可以唤出菜单,选择Run ‘WordCount’。运行的结果如下。注意根据代码,你必须有
/usr/local/spark/mycode/wordcount/word.txt
这个文件。输出信息较多,你可以拖动一下寻找结果信息。
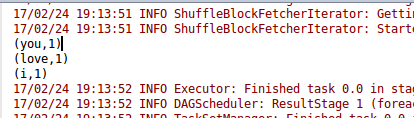
打包WordCount程序的jar包
首先打开File->Project Structure。如图。
然后选择Artifacts->绿色加号->Jar->From moduleswith dependencies…如图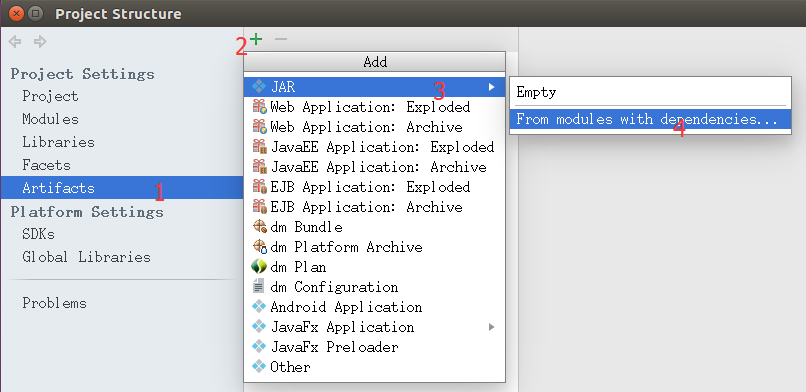
选择Main Class,如图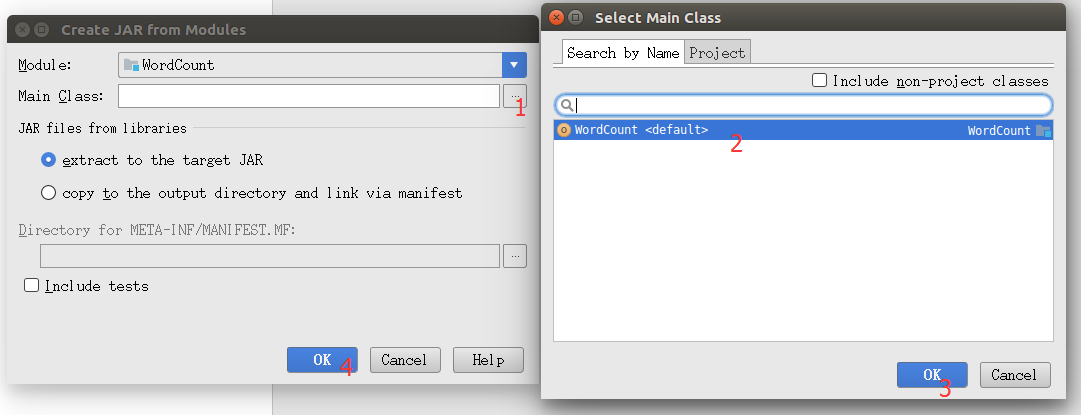
然后因为只是在Spark上运行的,所以要删除下图红框里多余的部分,保留WordCount.jar以及‘WordCount’ compile output。小提示,这里可以利用Ctrl+A全选功能,选中全部选项,然后,配合Crtl+鼠标左键进行反选,也就是按住Ctrl键的同时用鼠标左键分别点击WordCount.jar和‘WordCount’ compile output,从而不选中这两项,最后,点击页面中的删除按钮(是一个减号图标),这样就把其他选项都删除,只保留了WordCount.jar以及‘WordCount’ compile output。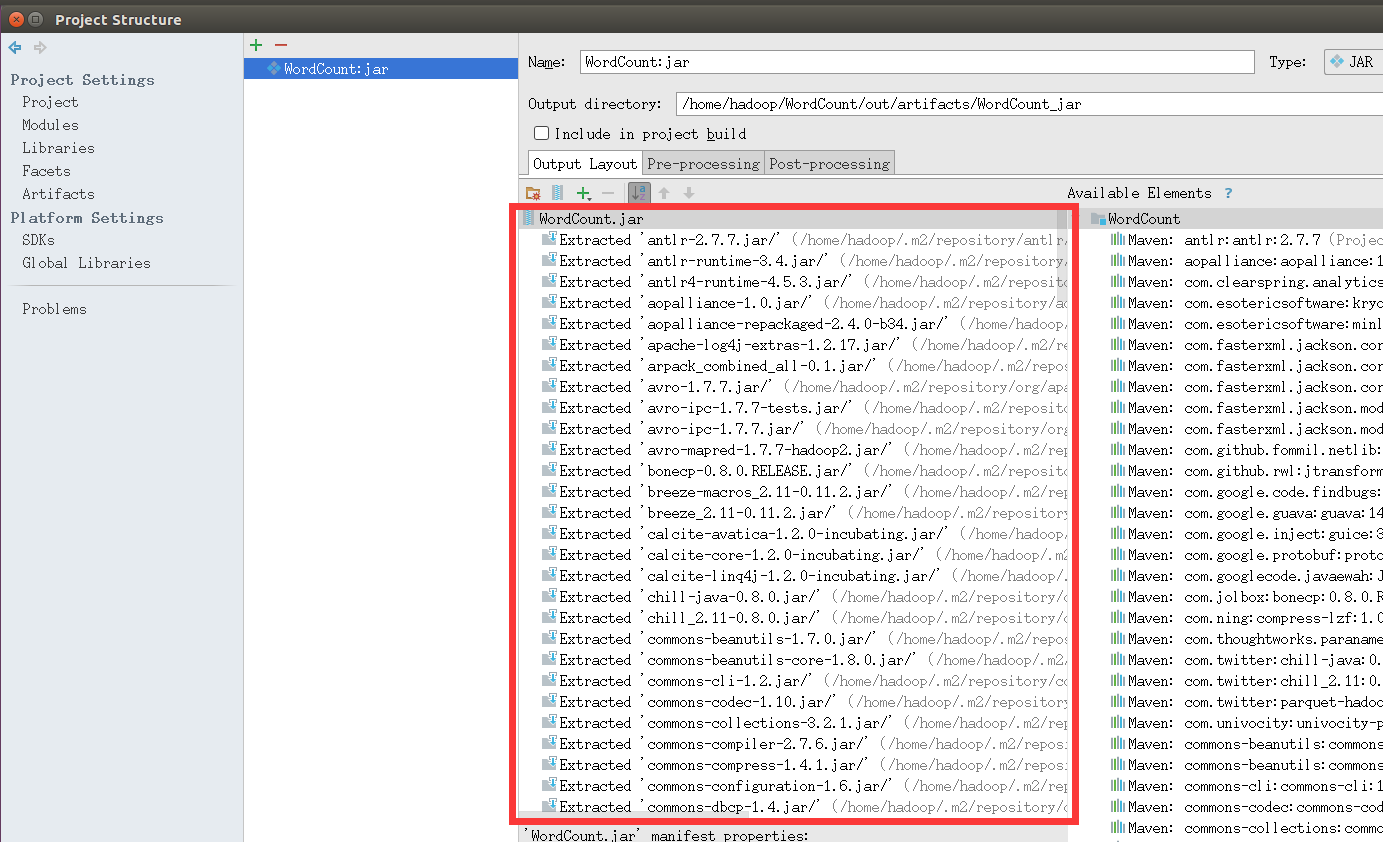
然后点击Apply,再点击OK,如图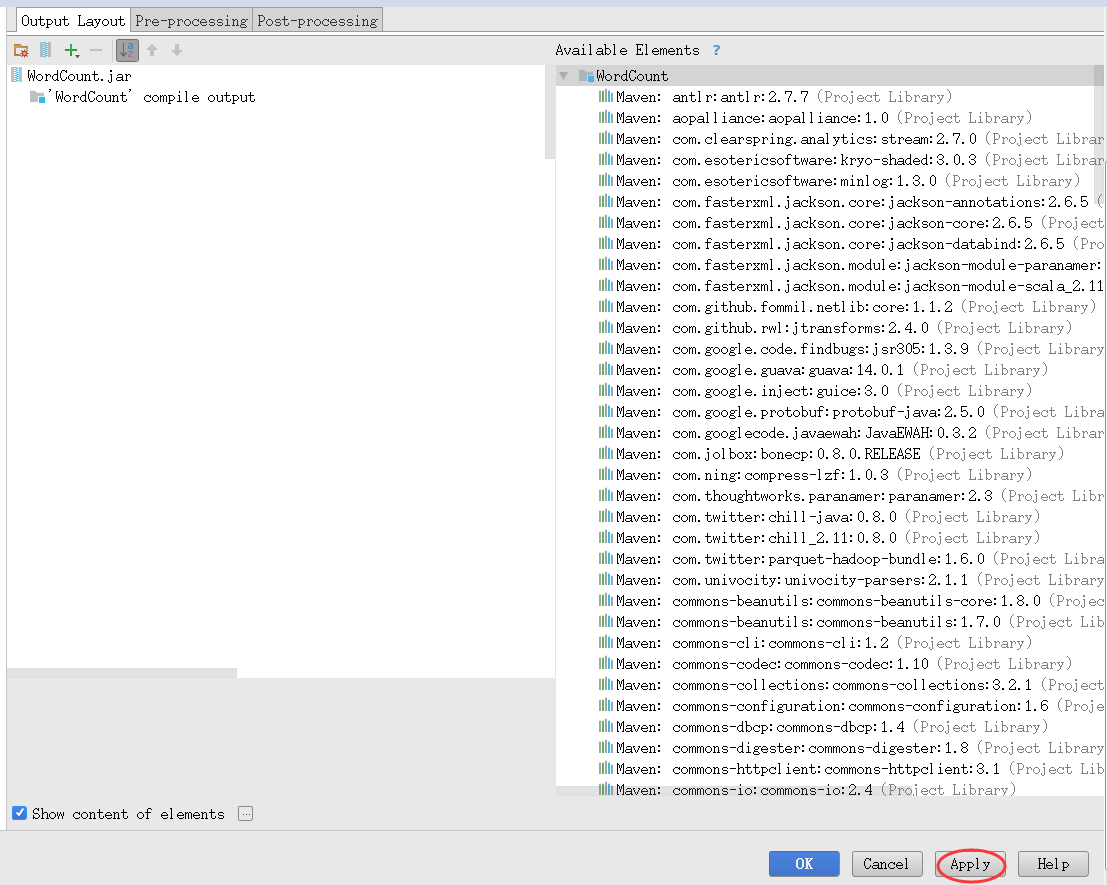
接着就可以导出Jar包了。选择Build->Build Artifacts…,在弹出的窗口选择Bulid就可以了。如下图: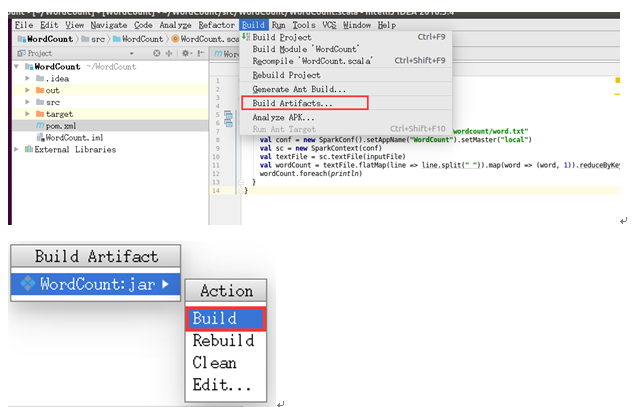
导出的Jar包会在工程文件“/home/wordcount/”目录下的“out/artifacts/WordCount_jar”目录下。把他复制到/home/hadoop目录下。也就是主文件夹目录下,如下图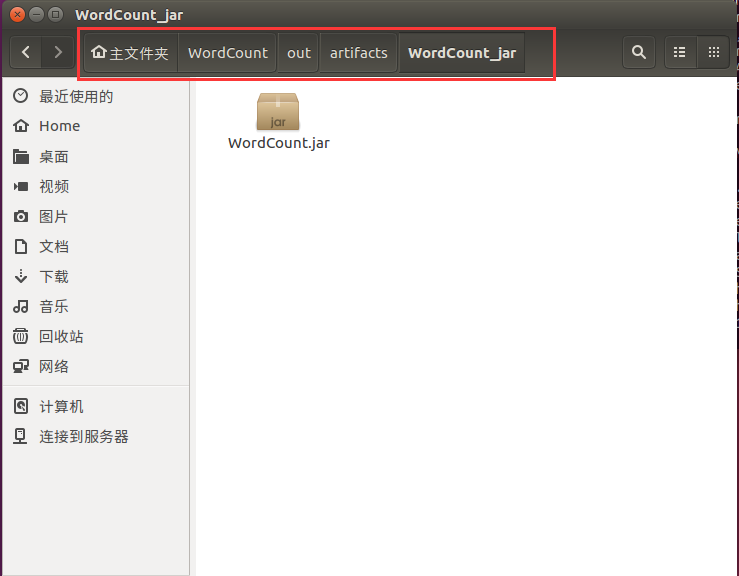
实际上,可以用命令来复制WordCount.jar文件,请打开一个Linux终端,输入如下命令:
cd ~cp /home/hadoop/WordCount/out/artifacts/WordCount_jar/WordCount.jar /home/hadoop
然后在终端执行以下命令,运行Jar包:
cd ~/usr/local/spark/bin/spark-submit --class WordCount /home/hadoop/WordCount.jar
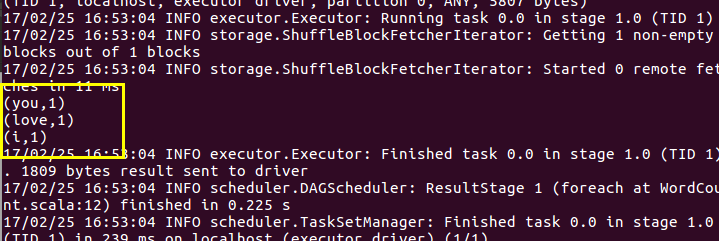
运行结果如下(输出的信息较多请上下翻一下就能找到),要求还是跟上述一样要有那个文件存在。
版权归原作者 不二人生 所有, 如有侵权,请联系我们删除。