
摘要:本文整理自 Apache Flink PMC 李劲松(之信)在 9 月 24 日 Apache Flink Meetup 的分享。主要内容包括:
- 介绍 Flink Table Store
- 应用场景
- Demo
- 后续挑战
Tips:点击「阅读原文」获取演讲 ppt~
01
介绍 Flink Table Store
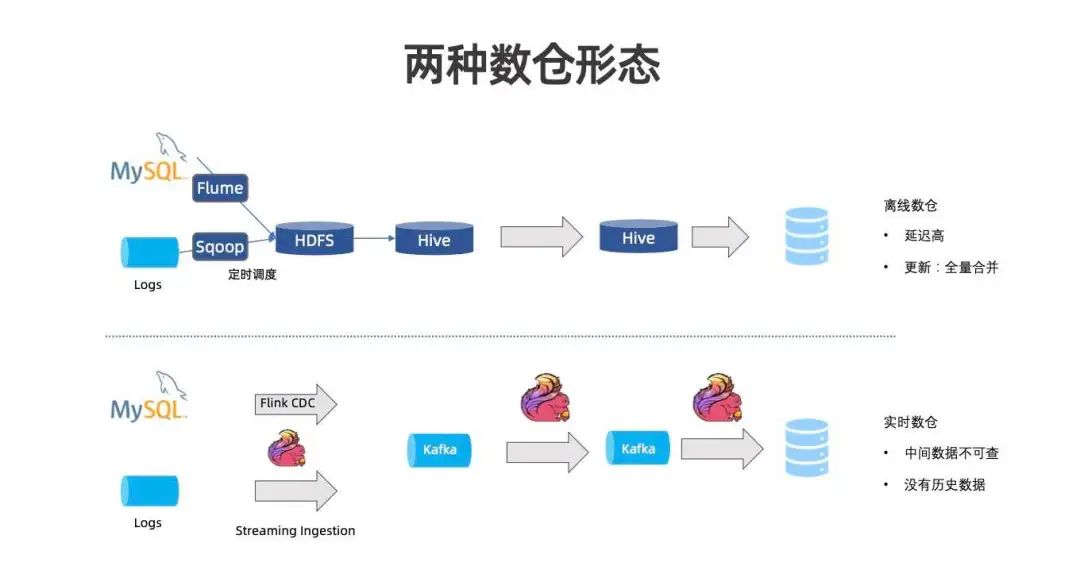
离线数仓和实时数仓是两个典型的数仓形态。
离线数仓为批调度的方式,延迟较高,另外更新为全量合并,代价高。实时数仓为流的形式,数据能够达到较低的延迟,但是中间数据不可查,也没有历史数据的沉淀。
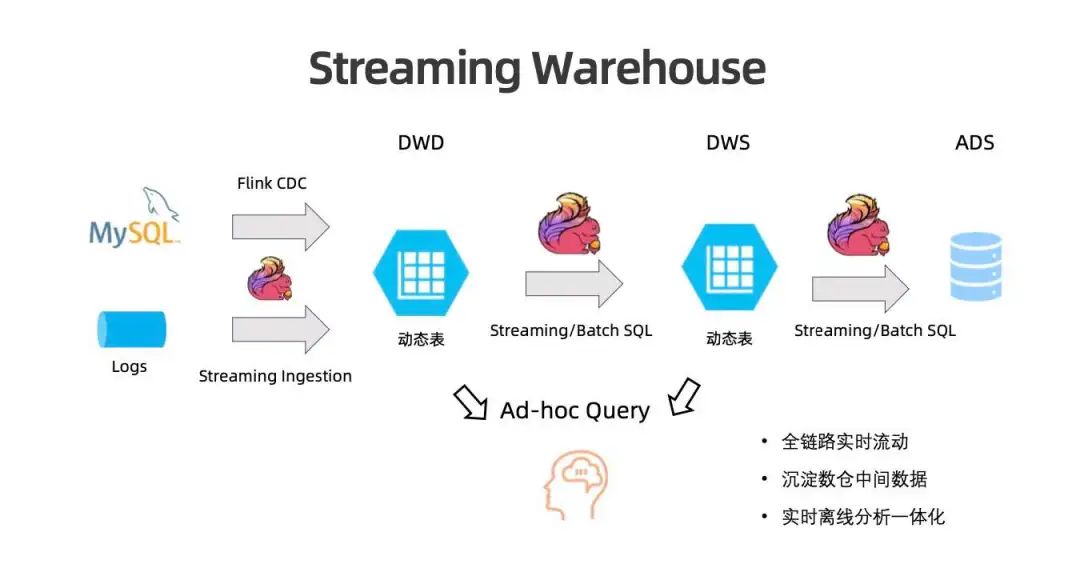
因此,业界提出了 Streaming Warehouse。其特点为有存储,有 Queue 的能力,能够让数据流动起来,也能够沉淀历史数据,可以供各种查询引擎比如 Spark 、Flink 进行 ad-hoc 查询。架构特点为全链路实时流动,沉淀数仓的中间数据,随时可查,实时、离线分析一体化。

总结来说,动态表需要的能力有如下三个:
- Table Format:能存储全量数据,能够提供很强的更新能力以处理数据库 CDC 和流处理产生的大量更新数据, 且能够面向 Ad-Hoc 提供高效的批查询。
- Streaming Queue:流读、流写,能在存储上建立增量处理 Pipeline。
- Lookup Join:面向 Flink 维表 Join 提供 Lookup Join 的能力。
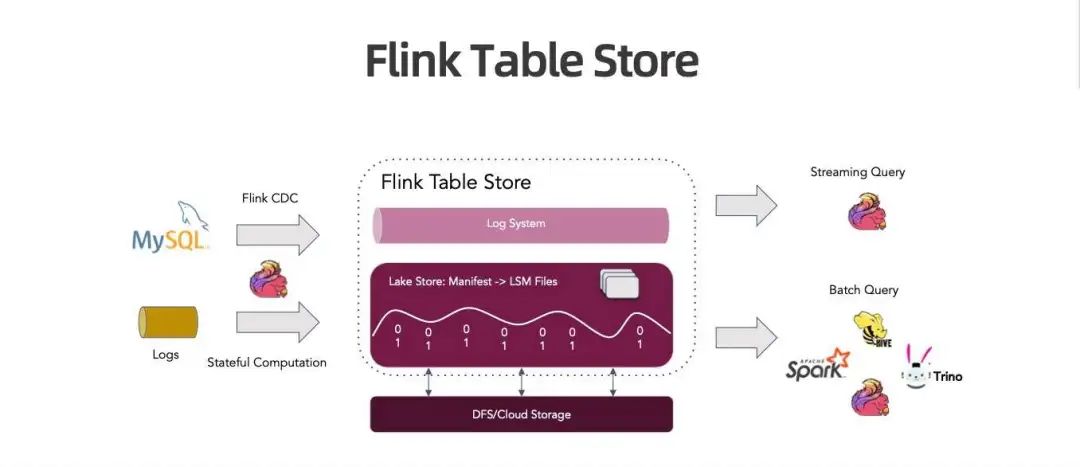
Flink Table Store 能够很好地满足以上三个需求。它是一个湖存储,可以接收上游来自 MySQL Flink CDC、Logs 、Flink 产生的 Stateful Computation 等大量更新的数据,写入湖存储,湖存储只是一个 lib/jar,置于 Flink 侧能流写流读,置于 Spark 侧可写可查询,本身是建立在 HDFS 或对象存储之上。
下游可以被 Flink Streaming 查询,建立 Streaming Pipeline ,也可以被各种引擎查询,比如 Hive、Spark、Trino 等。
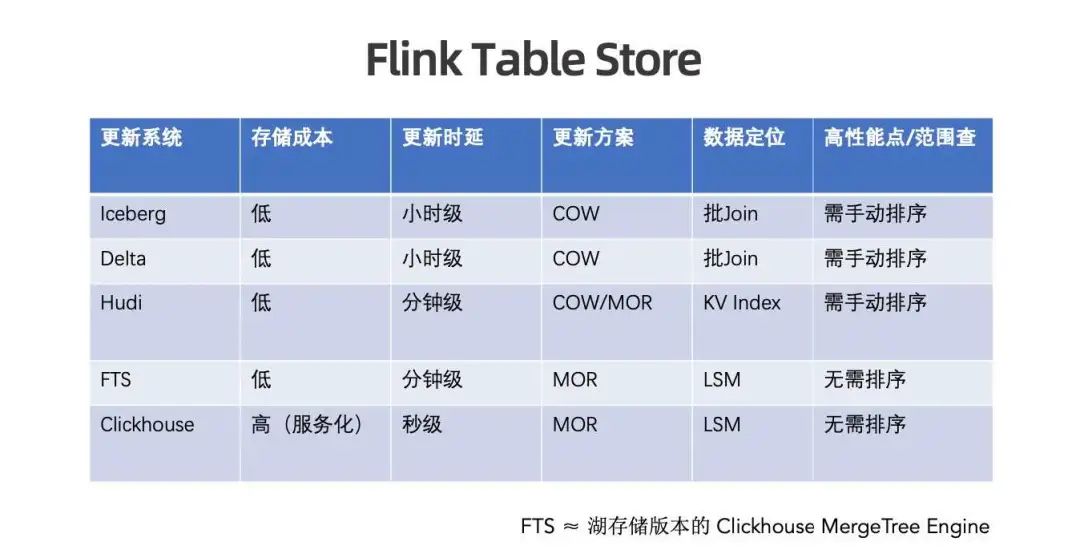
建立 Flink Table Store 的根本原因是为了弥补社区现有的缺失。我们期望 Flink Table Store 能够达到 OLAP 引擎的快速更新和快速查询能力,又有湖存储的低成本特性。
上图可见,Iceberg、Delta、Hudi 等都具有较低的存储成本,更新时延从小时级到分钟级不等,更新方案有 copy on write 、merge on read 。如果想要高性能查询,需要对湖存储进行手动排序。Clickhouse 是存储成本较高的 OLAP 系统,能提供秒级更新时延,查询性能非常快,基于 LSM 组织架构能达到非常好的更新效果和查询加速。
Flink Table Store 可以认为是湖存储版本的 Clickhouse MergeTree Engine,我们期望能够借此贴近 Streaming Warehouse 并发挥最大作用。
02
应用场景
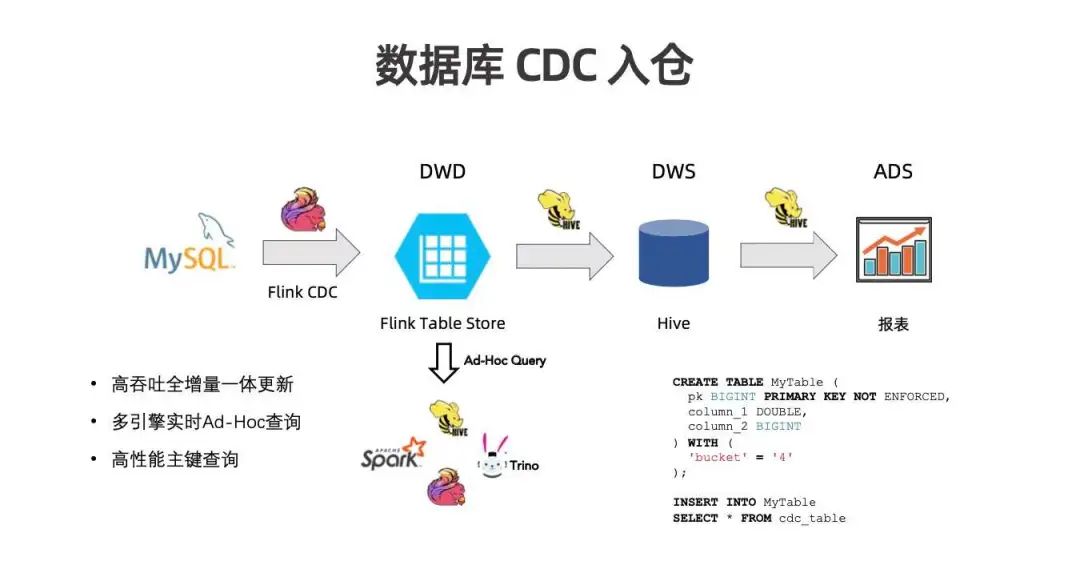
Flink CDC 缺少一个能够提供全增量一体导入的存储系统,而这可以通过 Flink Table Store 来实现。DDL 也很简单,通过 Create Table 和 Insert Into 即可全增量一体地读取 CDC 数据写入 Flink Table Store 中。Flink Table Store 能够提供高吞吐、全增量一体的更新,简化了流程,提升链路的易用性。存储也较为开放,能够被多引擎实时 Ad-Hoc 查询。LSM 按照 Key 来排序,如果查询条件中有 Key 相关的过滤条件,即可达到高性能的主键查询。
链路的第一步并不是要替换整个数仓,而是尽可能切入 ODS/DWD 层,实现更好的数据库 CDC 入湖入仓体验。
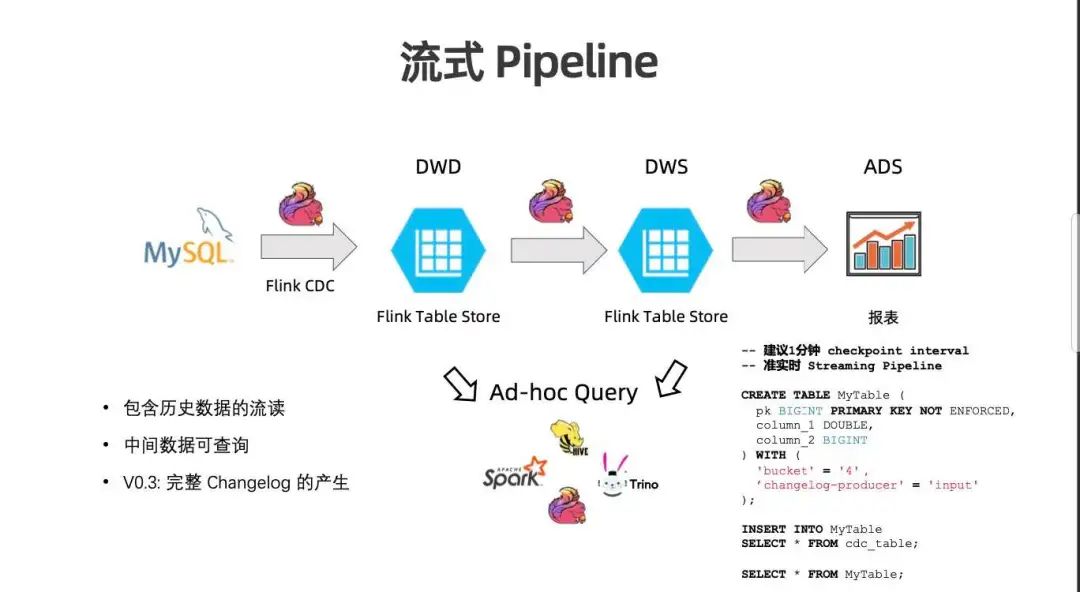
Flink Table Store 建好后即可直接对湖存储进行流读。如果能允许分钟级的流式 Pipeline ,那么 Flink Table Store 将是很好的选择。
Flink Table Store 包含历史数据的流读,能存储全量数据,因此每一次启动流读都是全量数据,能产出最正确的结果。建立流式 Pipeline 后,每一个中间表都可查询。
上图中的配置 Changelog-Producer=Input,表明整个流 Pipeline 是靠源头的 MySQL 数据给 CDC 产生的 Changelog 来产生正确的处理链路。
如果上游不是 CDC 或是包含随机字段或包含随机维表,则链路很有可能产生数据不正确的问题,这时为了解决数据的正确性问题,Flink SQL会在 Source 后面产生 Changelog Normalizer 节点,物化所有数据,以此产生正确的 Changelog 数据,而这是一个非常高消耗的节点。另外,如果你的 FTS 表声明了 Merge-Engine,比如是 Partial-Update,也需要存储本身来产生 Changelog,因为在写入时是拿不到完整的全行数据。
针对该缺点,FTS 0.3 版本将实现让存储本身能够产生完整的 Changelog,避免 Normalization 导致的成本,使 Streaming 分析没有后顾之忧。
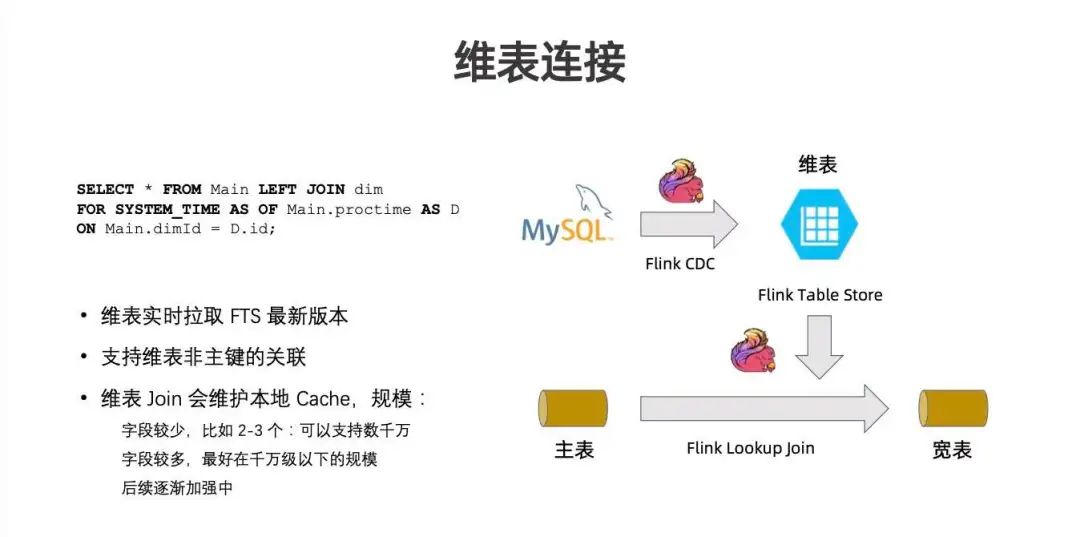
在 Streaming Warehouse 中, Flink 应用对存储的另一个需求是能够做维表 Lookup Join,因此 Flink Table Store 0.3 版本提供了该能力。可以创建 Flink Table Store 表,达到维表 Join 的效果。
Flink Table Store 带来价值在于能够实时拉取 Flink Table Store的最新版本,支持维表主键的关联,也支持维表非主键的关联。维表 Join 会将 Flink Table Store 的数据通过 projection push down 、filter push down 后拉到本地,进行本地 cache ,无需担心 OOM 。字段较少时可以支持个数千万字段,整体建议千万级以下规模,后续也将逐步加强,希望能够达到HBase类似的存储计算分离效果。
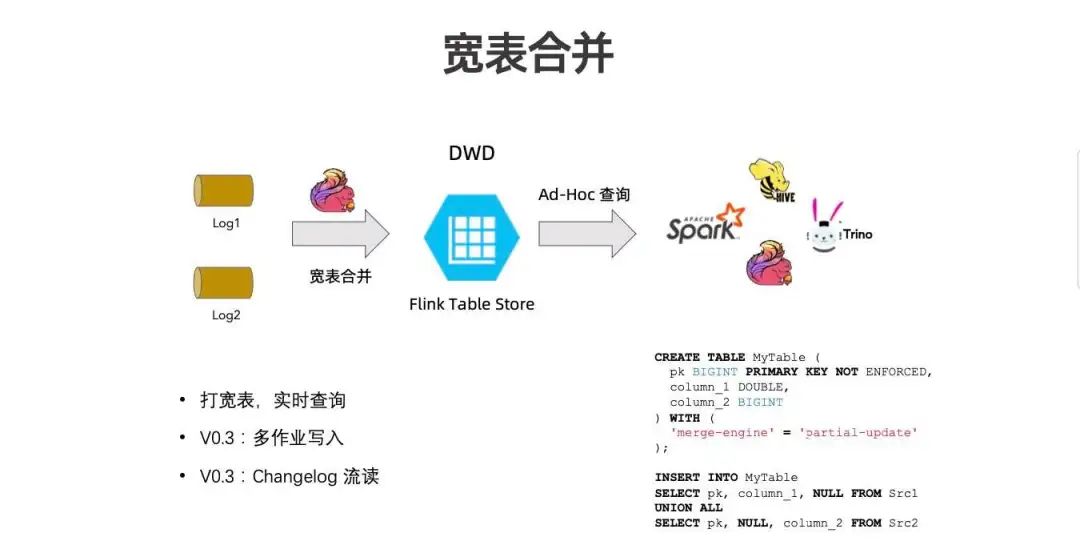
宽表合并本质上是宽表 Join ,可以用双流 Join 的方式来解决。但有些场景的数据量比较大,双流 Join 成本上难以满足。存储本身在特殊 Join 上、同 PK 打宽表的场景下,也可以通过存储延迟 Merge 的方式实现宽表合并效果。
如上图右侧代码所示,只需指定 Merge-Engine=Partial-Update ,写入时即可将两张表进行 union all 并写入同一张表,实现按主键打宽表。打宽表写入后,可通过多引擎实时查询,能查询到最新 Snapshot 。
当前版本尚存在一些缺陷,因为 Flink Table Store 目前不支持多作业写入,因此只能通过 union all 的方式, 0.3 版本中会提出多 Writer 并发写入的能力。另外,宽表只能被 ad-hoc 查询,无法被流读,0.3 版本也会开发 Changelog 生成来实现流读能力。
03
Demo
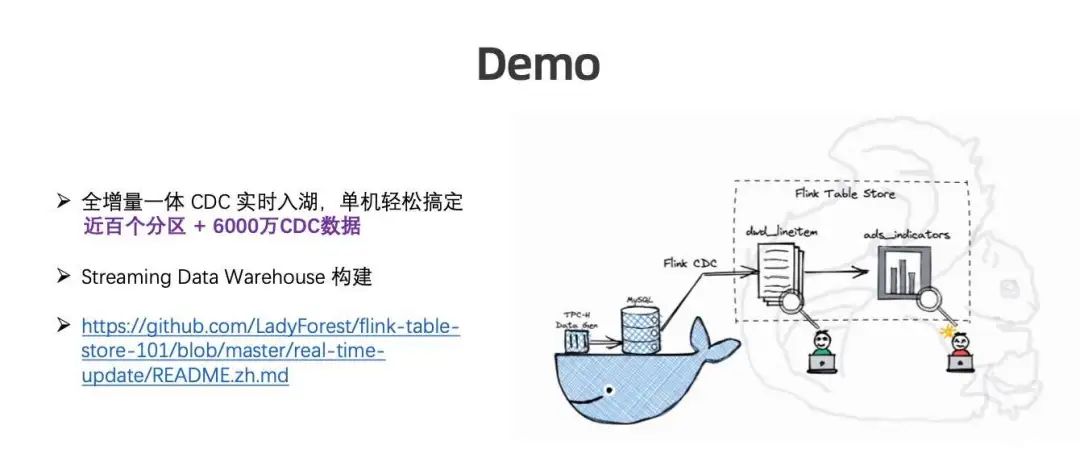
Demo 内容为:Docker 里面有数据,通过 TPC-H Data Gem的方式全量导入 MySQL 中,不断地有线程产生增量数据。创建 Flink 集群、Flink Table Store 表,通过 Flink CDC 导入,创建Streaming Pipeline,最终产生聚合数据。
本 Demo 为全增量一体 CDC 实时入湖,单机轻松完成近百个分区 +6000 万 CDC 数据。
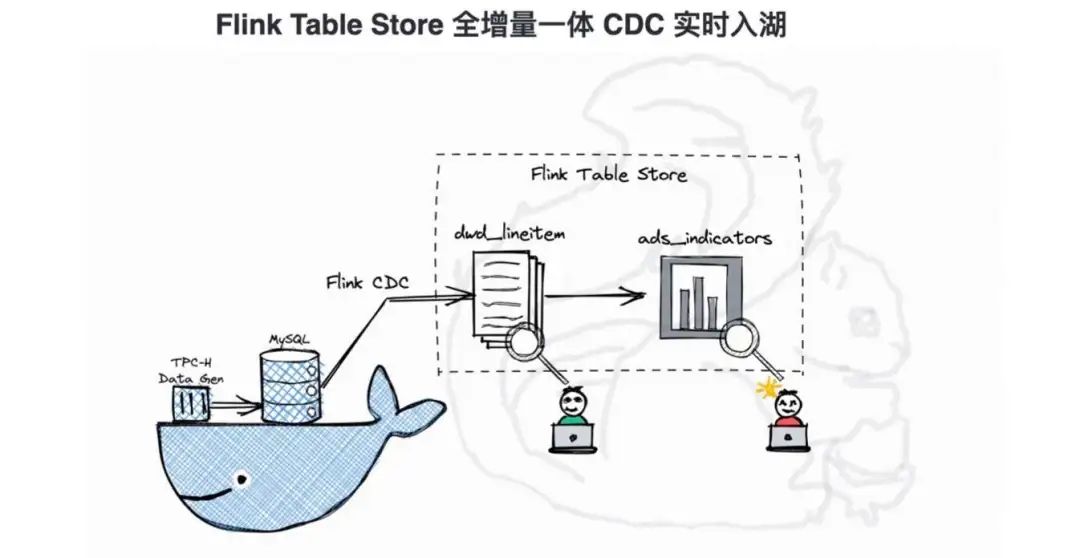
Flink Table Store 作为湖存储,支持大规模实时更新写入是其核心特性之一。配合 Flink CDC 即可替代以前两条割裂的全量链路加增量链路分别同步的情况,实现将数据库中全量和增量数据一起同步入湖。
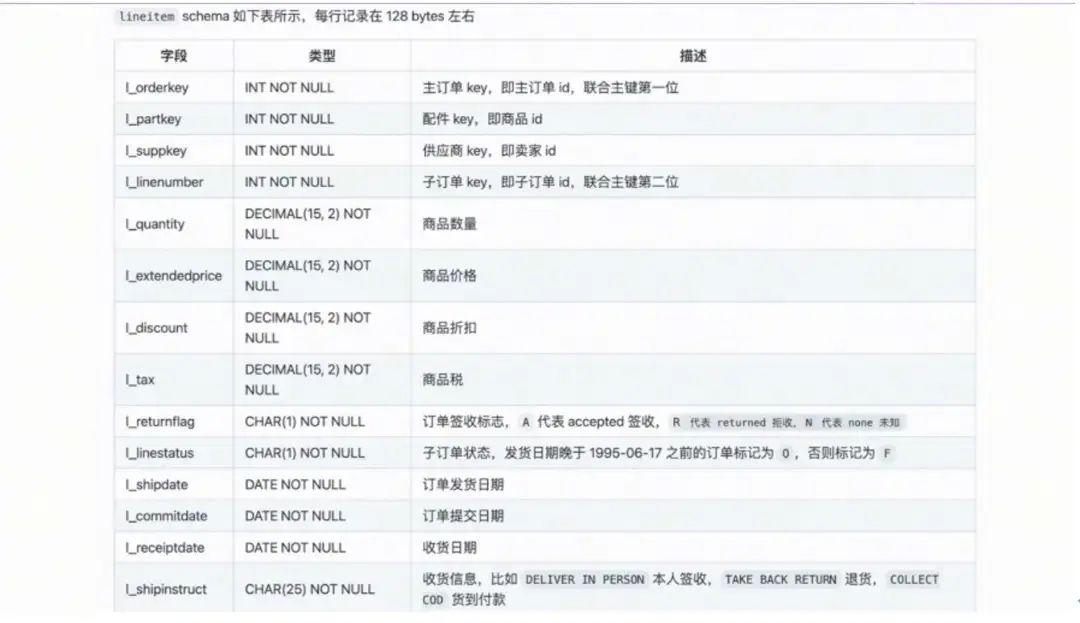
本 demo 的 Schema 包含主子订单 ID 、商品 ID 、卖家 ID、 价格、发货、履约日期和物流等一系列信息。

每条记录大约为 128 bytes ,总共生成大约 5990 万+条数据。同步写入 Flink Table Store 明细表时,以发货日期作为分区字段,创建年+月二级分区。时间跨度为 7 年,因此一共动态写入 84 个分区。
经测试,在单机并发为 2,Checkpoint Interval 为 1min 的配置下,46 min 内写入 59.9 million 去哪量数据,平均写入性能为 1.3 million/min。如果在生产环境下使用 20 个并发,可以在一小时内同步超过 6 亿条数据,非常可观。
将 Flink-Table-Store-101 克隆到本地,然后切换到 Real- Time-Update 目录下,启动容器。此处会先构建自定义 MySQL 镜像,在 Container 启动之后,自动生成 5900 万+条数据,并通过 load data info 导入到 MySQL lineitem 表。生成的数据总共切分为 16 个 chunk ,大约需要 1 分钟左右可生成完毕。数据生成完毕后导入 chunk,大约需要 15 分钟。
启动集群,准备好依赖。打开 Localhost 8081。
数据全部导入完成后,开启全量同步。
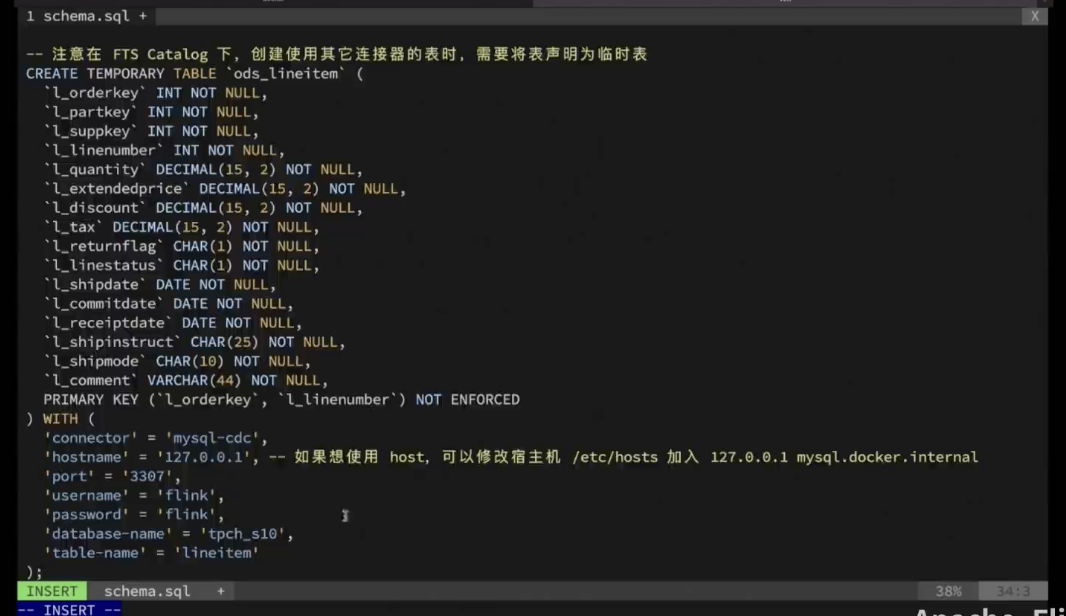
创建 Schema.sql 文件,导入所有建表语句。主要内容为:创建 Table Store Catalog ,指定 Warehouse 为 Time 文件目录下的 Table-Store-101,并将 Table Store 设置为 Current Catalog。创建 CDC 的 ODS Table ,需要注意是,在 Flink Table Store Catalog 下,其他表需要声明成 Temporary Table 。
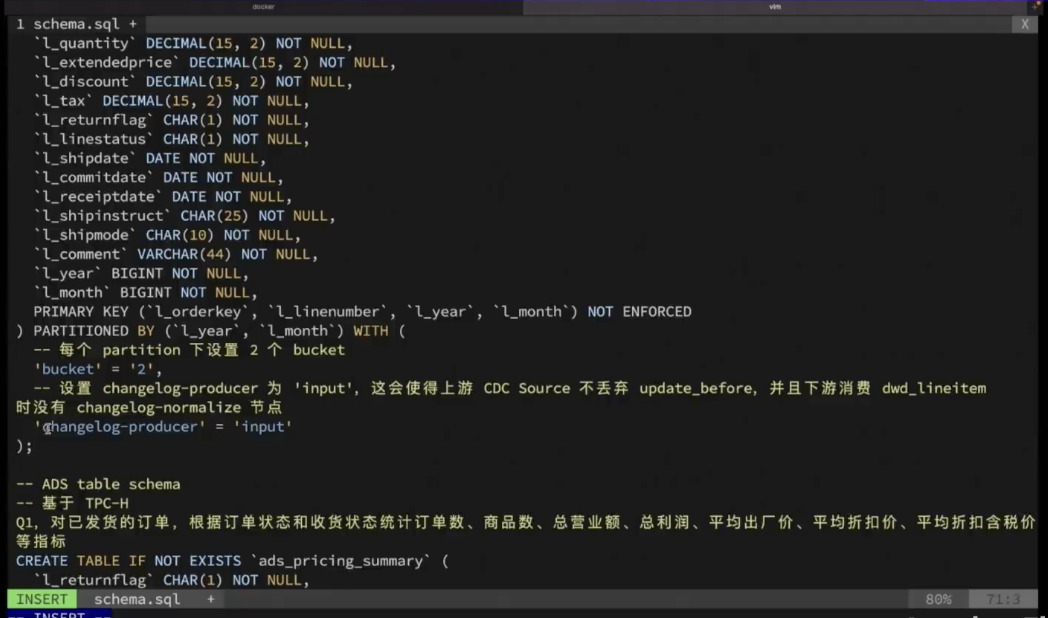
创建 DWD Table ,额外新增了两个分区字段,l_year 和 l_ month 。每个 Partition 下面设置两个 Bucket ,使用 Input 作为 Changelog Producer ,使得上游 CDC 不丢弃 Update_Before,并且下游消费时候不会产生 Changelog-Normalize 节点。
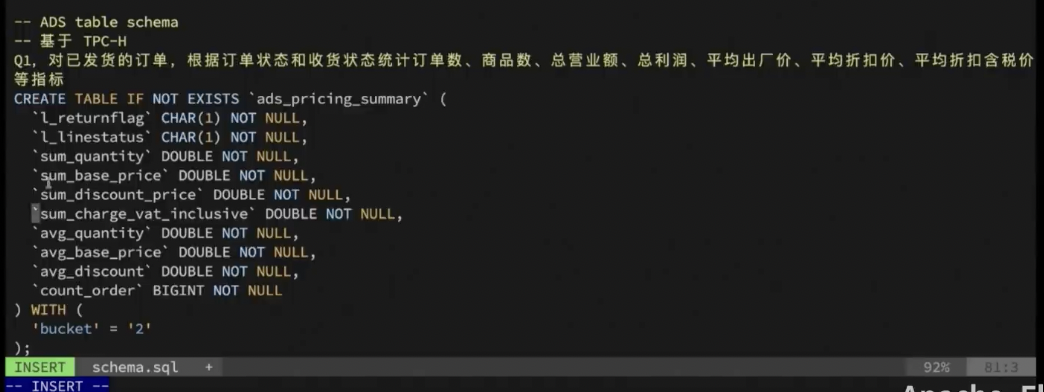
接下来为聚合作业 Schema。
保存并且将其作为启动 SQL Client 的初始化文件。

启动 SQL Client,提交全量同步作业,使用内置函数 year() 和 month()来生成两个分区字段。

作业提交后,上图可见数据已经读取进来。
切换到 Flink Table Store 目录,查看生成的 Snapshot Manifest 文件和 SST 文件。
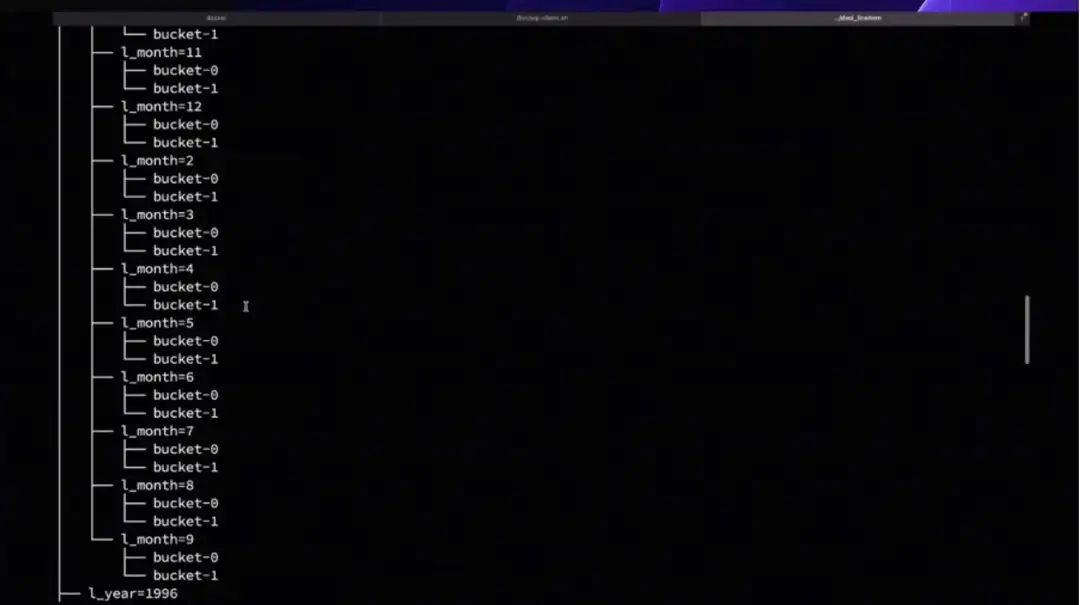
显示分区下的数据已经写入。

查看 Snapshot 显示已经提交一次。
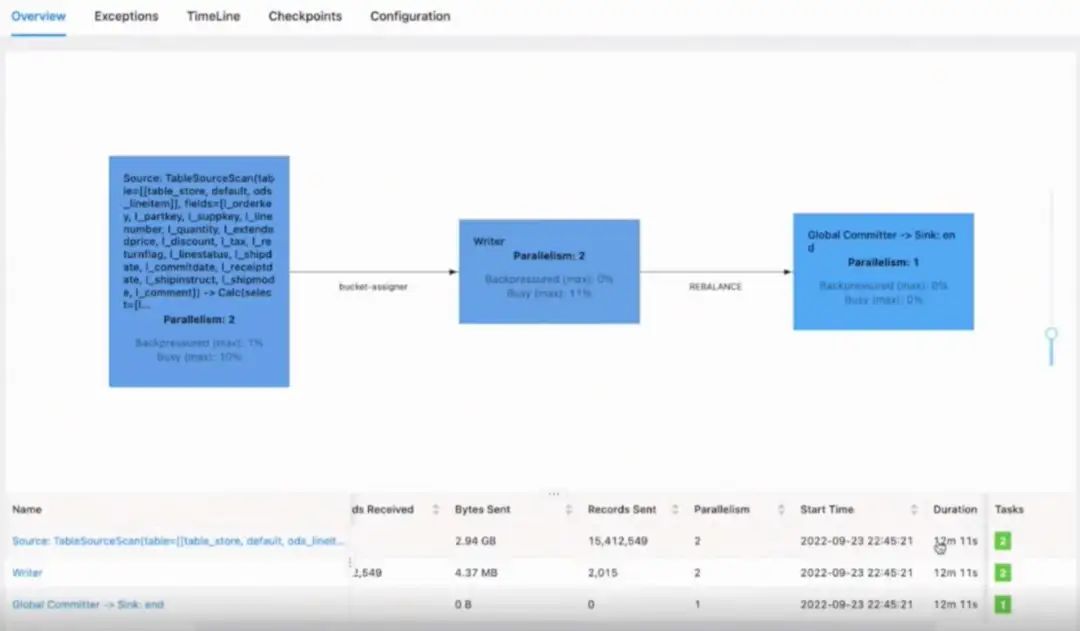
启动 12 分钟以后,可以看到全量数据已经同步完成。
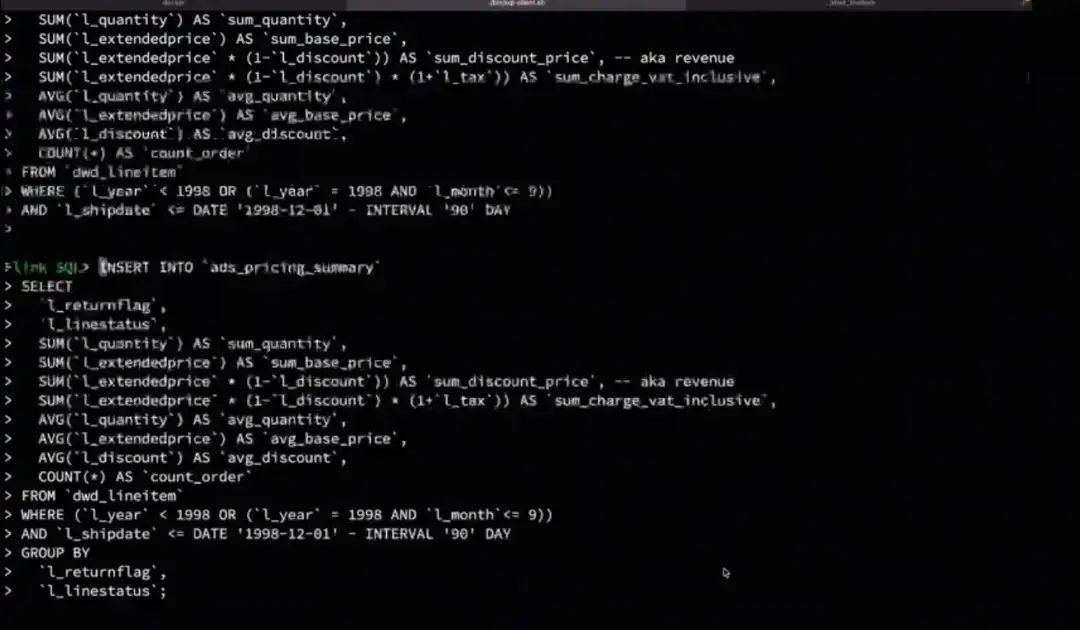
提交聚合作业。聚合作业计算完成后,开始查询。
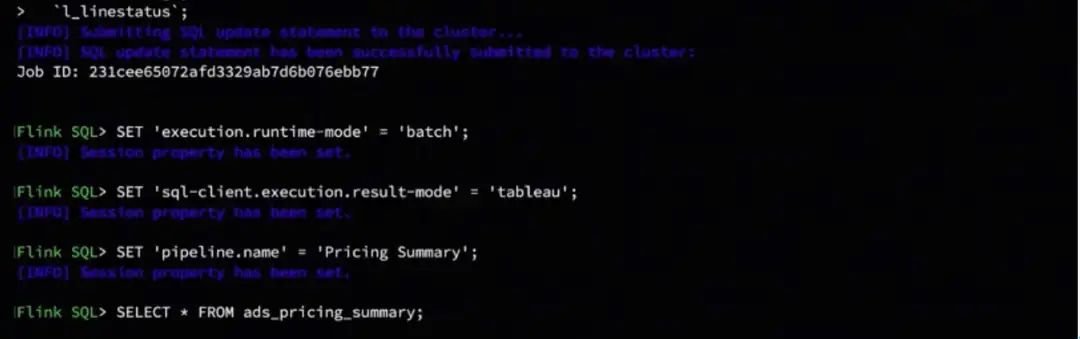
切换到 Batch 模式,提交查询作业。

查询作业结束以后,为了展示方便,对其进行排序。
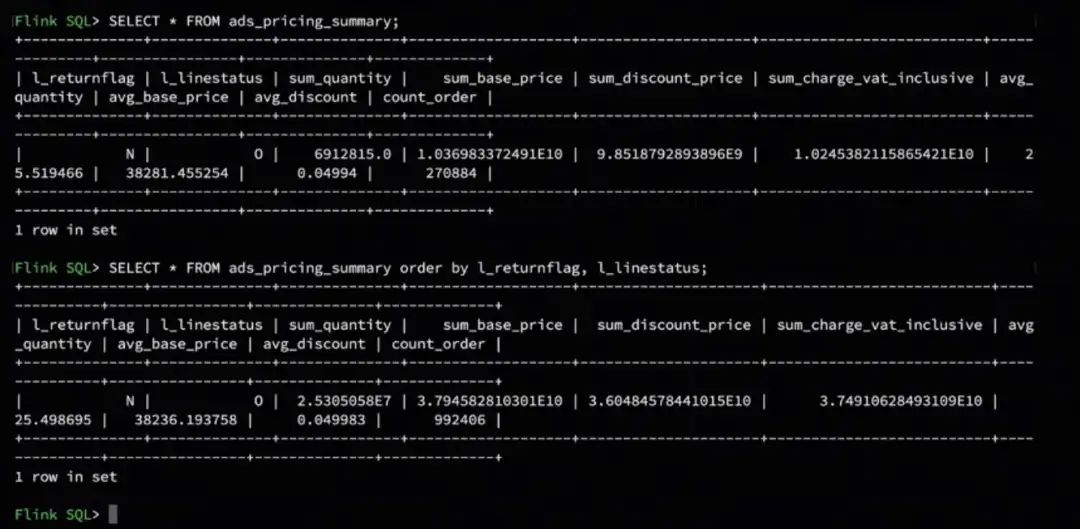
结果显示为一条数据,数据已更新。

除了查询聚合数据外,也可以查明细数据。比如发现 1998 年 12 月订单数据有问题,需要排查明细进一步定位问题范围。再查询退货情况以及聚合结果,可以看到数据在更新。
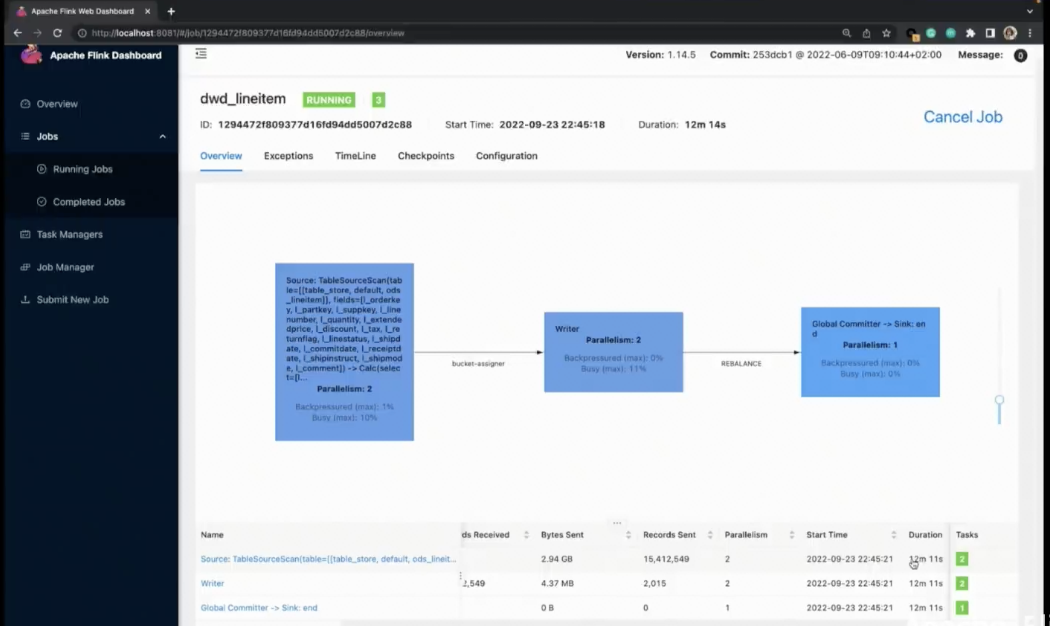
查看明细层作业,可以看到增量数据已经开始导入,到目前为止写入 6000 万条数据。
04
后续挑战

Streaming Data Warehouse 面临的挑战主要有以下四个方面。
- 第一,存储管控。我们希望通过 Flink CDC、Flink SQL 流批一体计算加上 Flink Table Store 存储打造闭环,通过 Flink SQL 来管控运维、执行 Pipeline 的 一整套系统,需要运维管控元数据的工作,这也是 Flink 1.17 的重点推进方向。
- 第二,流计算准确性。想要完全分层次的 Streaming Pipeline ,本质上要求存储能够自己产生完整的 Changelog ,则流计算中的手动去重、莫名其妙的数据正确性等问题都能够自然而然得到解决。
- 第三,Join 。Join 在逻辑上存在诸多问题,维表 Join 需要额外系统,但有时语义不满足,因为维表更新并不触发计算。而且维表 Join 具有一定的随机性,会破坏完整的 Changelog 定义。另外,双流 Join 需要保存全量明细,代价太高。
- 第四,物化视图一致性。构建 Streaming Data Warehouse 本质上是构建一系列物化视图,而如果Streaming Data Warehouse 的每个 Table 都可查,一致性却无法保障,最终呈现的也是不一致的视图。
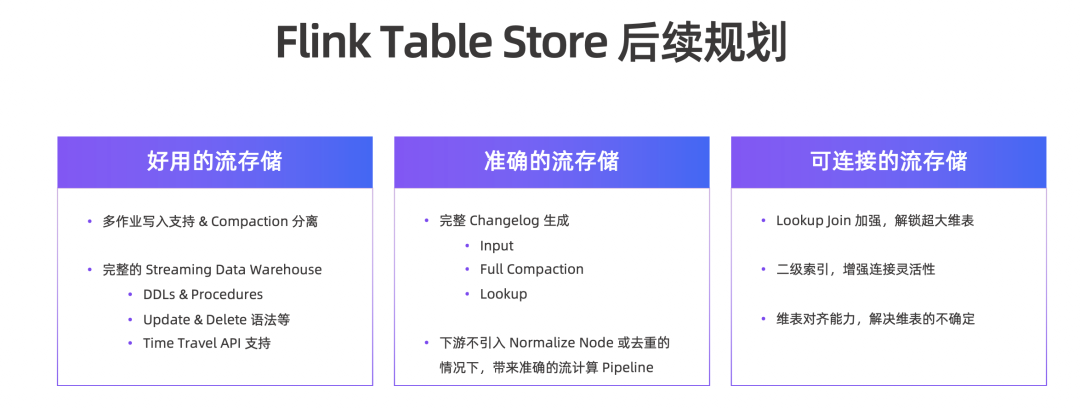
Flink Table Store后续规划的三个目标如下:
- 第一,好用的流存储。比如多作业写同时写入、Compaction 分离,比如完整的 Streaming Data Warehouse API 设计,包括完整的 DDL、Update、Delete 语法、Time Travel API 支持。以上能力将与 Flink 社区一起在 1.17 版本中重点攻克。
- 第二,准确的流存储。存储本身能够产生完整的 Changelog ,下游的流计算易用性才能真正得到提高。
- 第三,可连接的流存储。继续增强 Lookup Join ,实现二级索引以更好地 Join,实现维表对齐能力,解决维表不确定性。
Q&A
Q:现在业务是用 Flink CDC 写 Hudi 表,与 Hive 集成映射。如果换成 SQLGateway ,版本是否会有影响?
A:目前 SQLGateway 与 Flink 版本绑定在一起。比如升级到 Flink 1.16, 则 Gateway 、Hudi、Hive 都要适配 Flink 1.16。后续我们会增强 Gateway 和 Flink 版本的解耦。
Q:Flink Table Store 与 Hudi、Lceberg 的差别在哪里?
A:本质差别在于数据定位。Flink Table Store使用 LSM 结构来更新和接受查询,相当于在写过程中不断地 Spill、 Compaction,其优点在于编写进来的数据已经排序好。并且通过 Append Spill 来更新,更新性能高。另外,LSM 结构可以在存储上有更大的扩展性,比如类似 Clickhouse 那样可以有各种场景的 MergeTree,加速查询。
Q:Flink Table Store 的 Compaction 操作是在写入时完成吗?
A:是的,默认情况下创建作业后,通过 Streaming 写入,在写入作业 Writer 中,后台线程会不断地进行 Compaction 。当然,也可以选择将 Compaction 分离为单独的 Compaction 作业来完成。
Q:目前只能通过 Flink SQL 来查询 Table Store 吗?
A:不是。Flink Table Store 本质上是 Flink 在写的时候,通过一定的组织方式将数据通过文件方式放在 DFS 上,类似于 RocksDB 的分层分 level 的文件组织方式。Flink Table Store 现在有 Spark、Trino、Hive 查询,只要将 Flink Table 输入 Jar 包,放置于 Hive Spark 的 Lib 下,即可直接查询 Flink Table Store 表。
Q:查询速度与 Clickhouse 接近吗?
A:如果通过 PK 查询,并且有 Filter 条件,则查询速度非常快。这也是 Clickhouse 引入 LSM 做 Merge Engine 的原因。但是如果需要大量计算,那还是 Clickhouse 的查询快很多。
**■ **Flink Table Store 目前已经发布 0.3.0:https://flink.apache.org/news/2023/01/13/release-table-store-0.3.0.html
最后,欢迎大家扫码加入【Flink Table Stare 交流群】交流和反馈相关的问题和想法。

往期精选
▼ 关注「Apache Flink」,获取更多技术干货 ▼

 *点击「阅读原文*」,获取演讲 **PPT~
*点击「阅读原文*」,获取演讲 **PPT~
版权归原作者 Apache Flink 所有, 如有侵权,请联系我们删除。