
**1 **基本信息
1.1** **系统名称
基于Spark的智能餐饮推荐系统
1.2** 开发运行环境**
Linux: Ubuntu 14.04
MySQL: 5.7.16
Hadoop: 2.7.1
Hive: 1.2.1
Sqoop: 1.4.6
Spark: 2.1.0
Eclipse: 3.8 (注意:Eclipse 3.8是一个较旧的版本,考虑使用更新版本)
ECharts: 3.4.0
1.3** **使用的核心技术
Spark大数据分析框架
MLlib机器学习库
MySQL数据库管理系统
Hadoop生态系统(HDFS, YARN等)
Hive数据仓库
Sqoop数据导入导出工具
ECharts数据可视化库
- 系统功能设计
本系统旨在通过大数据分析,为用户提供个性化的餐饮推荐。通过分析用户的饮食偏好、历史记录等信息,结合餐饮商户的菜品、评价等数据,为用户提供精准、及时的推荐服务。
2.1系统总体功能
本系统旨在通过大数据分析,为用户提供个性化的餐饮推荐。通过分析用户的饮食偏好、历史记录等信息,结合餐饮商户的菜品、评价等数据,为用户提供精准、及时的推荐服务。
2.2系统模块详细设计
2.2.1 数据预处理功能模块
对原始数据进行清洗、转换、整合等预处理操作
为后续的数据分析和推荐算法提供规范、统一的数据格式
2.2.2 推荐算法功能模块
推荐算法功能是基于python机器学习库实现的,旨在通过分析用户的历史行为和偏好,以及餐饮商户的菜品、评价等信息,为用户提供个性化的餐饮推荐。该功能采用了协同过滤(Collaborative Filtering)算法,包括用户-用户(User-User)协同过滤和物品-物品(Item-Item)协同过滤,以确保推荐的准确性和多样性。
2.2.3 ECharts功能模块
ECharts 是一个使用 JavaScript 实现的开源可视化库,可以生成各种类型的图表,包括折线图、柱状图、散点图、饼图等。在智能餐饮推荐系统中,ECharts 可以用于展示用户行为数据、菜品销售数据、用户评价等,帮助餐饮管理者直观地了解餐厅的运营情况和用户偏好。
2.3数据库设计(使用E-R图或者三线表)
用户表:存储用户基本信息(如ID、姓名等)
菜单表:存储菜单(编号、菜品名)
- 系统实现
3.** 数据预处理功能实现**
3.1.1 功能描述
数据预处理功能在智能餐饮推荐系统中扮演着至关重要的角色。它负责清洗、转换、整合从各种数据源中收集到的原始数据,以确保数据的质量和一致性,为后续的数据分析和推荐算法提供规范、统一的数据格式。
数据清洗:去除重复、缺失或异常的数据记录,处理格式不一致的数据字段。
数据转换:将数据从原始格式转换为适合分析的格式,例如将字符串类型的日期转换为日期格式,将文本型的评价转换为数值型评分等。
数据整合:将来自不同数据源的数据整合到一起,形成完整的数据集,以便进行统一的分析和处理。
3.1.2 核心代码
第1步:读取数据
val path = "/home/hadoop/Meal.json"
val df = spark.read.json(path)
df.printSchema()
df.createOrReplaceTempView("data")
spark.sql("select userid, mealid, rating, review from data").show(5)
第2步:数据探索
scala
spark.sql("select count(*) as records from data").show()
spark.sql("select count(distinct userid) as users from data").show()
第3步:按日期分组统计数据分布
scala
val dataWithDate = spark.sql("select *, (From_Unixtime(reviewtime, 'yyyy-MM-dd')) as reviewdate from data")
dataWithDate.createOrReplaceTempView("dataWithDate")
第4步:查询最新评分记录
scala
val lastRating = spark.sql("select userid, mealid, MAX(reviewtime) as lastdate from data group by userid, mealid")
lastRating.createOrReplaceTempView("lastRatingPair")
val lastRatingRecord = spark.sql(
"""select a.userid, a.mealid, a.rating, a.reviewtime
from data a
join lastRatingPair b
on a.userid = b.userid and a.mealid = b.mealid and a.reviewtime = b.lastdate"""
)
lastRatingRecord.createOrReplaceTempView("lastRatingRecord")
第5步:数据去重和排序
// 将DataFrame转换为RDD
val ratingrdd = lastRatingRecord.rdd.map(row =>
(row.getAs[String]("userid"), row.getAs[String]("mealid"), row.getAs[Double]("rating"), row.getAs[Long]("reviewtime"))
)
// 对mealid进行编码
val mealzipcode = ratingrdd.map(_._2).distinct.sortBy(x => x).zipWithIndex.map(a => (a._1, a._2.toInt))
// 对userid进行编码
val userzipcode = ratingrdd.map(_._1).distinct.sortBy(x => x).zipWithIndex.map(a => (a._1, a._2.toInt))
// 将编码结果收集到Map中
val userzipcodemap = userzipcode.collect().toMap
val mealzipcodemap = mealzipcode.collect().toMap
// 将原始数据中的userid和mealid替换为编码后的值,并按时间排序
val ratingcodelist = ratingrdd.map {
case (userid, mealid, rating, reviewtime) =>
(userzipcodemap(userid), mealzipcodemap(mealid), rating, reviewtime)
}.sortBy(_._4)
第6步:数据集分割
val totalnum = ratingcodelist.count()
val splitpoint1 = (totalnum * 0.8).toInt
val splitpoint2 = (totalnum * 0.9).toInt
3.1.3 运行截图
第1步:读取数据
第2步:数据探索
第3步:按日期分组统计数据分布
第4步:查询最新评分记录
第5步:数据去重和排序
第6步:数据集分割
3**.2 推荐算法功能实现**
3.2.1 功能描述
推荐算法功能是基于python机器学习库实现的,旨在通过分析用户的历史行为和偏好,以及餐饮商户的菜品、评价等信息,为用户提供个性化的餐饮推荐。该功能采用了协同过滤(Collaborative Filtering)算法,包括用户-用户(User-User)协同过滤和物品-物品(Item-Item)协同过滤,以确保推荐的准确性和多样性。
3.2.2 核心代码
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
import chardet
def detect_encoding(file_path):
with open(file_path, 'rb') as f:
result = chardet.detect(f.read())
return result['encoding']
user_item_file = 'userzipcode.csv'
menu_file = 'meal_list.csv'
user_item_encoding = detect_encoding(user_item_file)
menu_encoding = detect_encoding(menu_file)
user_item_data = pd.read_csv(user_item_file, encoding=user_item_encoding)
menu_data = pd.read_csv(menu_file, encoding=menu_encoding)
# 后续流程...
# 3.合并用户评价数据和菜品名称数据
data = pd.merge(user_item_data, menu_data, left_on='MealID', right_on='mealID')
# 4.加载训练数据
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
# 5.加载推荐模型
tfidf = TfidfVectorizer(stop_words='english')
train_tfidf_matrix = tfidf.fit_transform(train_data['Review'])
# 6.计算余弦相似度
cosine_sim = linear_kernel(train_tfidf_matrix, train_tfidf_matrix)
# 7.为用户推荐菜品
def get_recommendations(user_id, num_recommendations):
# 获取用户的所有评价记录
user_reviews = train_data[train_data['UserID'] == user_id]
if user_reviews.empty:
return "User not found or has no reviews."
# 获取用户最后一次评价的菜品索引
user_last_review_index = user_reviews.index[-1]
# 计算与用户最后一次评价的菜品的相似度
sim_scores = list(enumerate(cosine_sim[user_last_review_index]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# 获取前num_recommendations个最相似的菜品的索引
sim_scores = sim_scores[1:num_recommendations+1]
meal_indices = [i[0] for i in sim_scores]
# 返回最相似的菜品名称
return train_data.iloc[meal_indices]['meal_name']
# 示例:
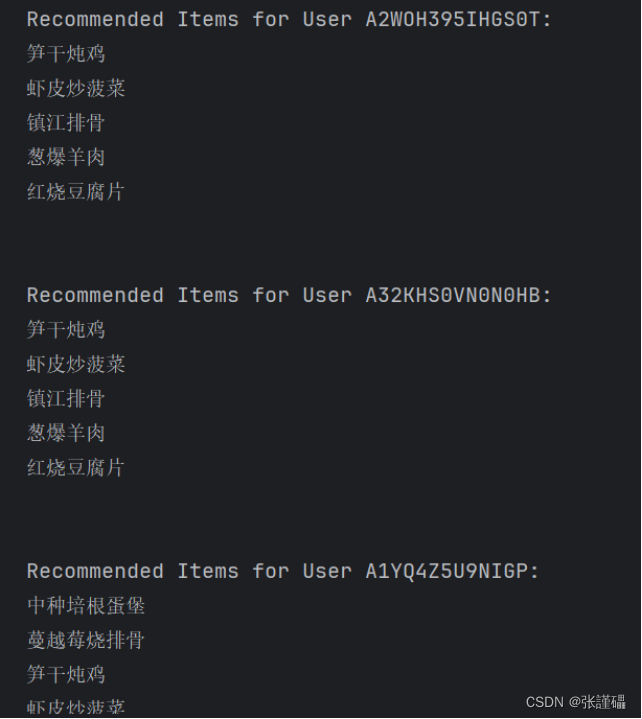
user_id = 'A2WOH395IHGS0T' # 请根据实际数据中的UserID进行更改
num_recommendations = 5
recommended_items = get_recommendations(user_id, num_recommendations)
print("Recommended Items for User", user_id)
for item in recommended_items:
print(item)
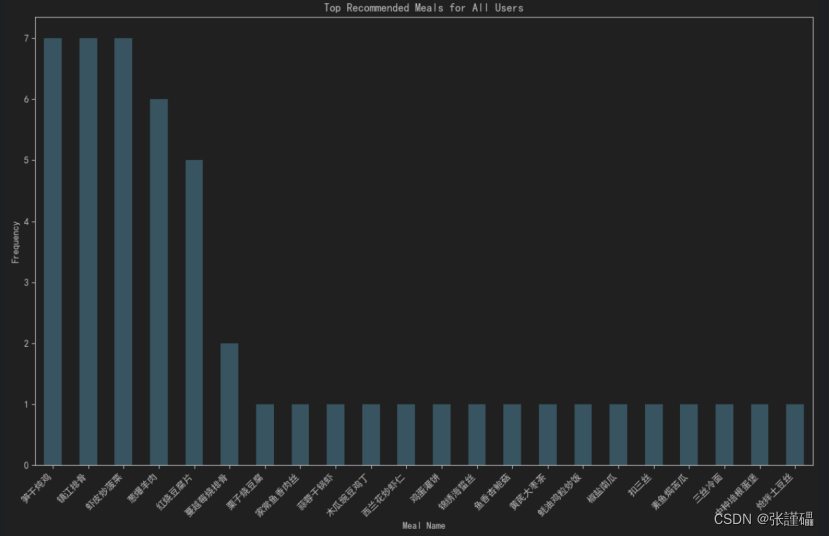
3.2.3 运行截图
3**.3 **ECharts功能实现
3.3.1 功能描述
ECharts 是一个使用 JavaScript 实现的开源可视化库,可以生成各种类型的图表,包括折线图、柱状图、散点图、饼图等。在智能餐饮推荐系统中,ECharts 可以用于展示用户行为数据、菜品销售数据、用户评价等,帮助餐饮管理者直观地了解餐厅的运营情况和用户偏好。
3.3.2 核心代码
Jsp代码:
<%@ page language="java" import="dbtaobao.connDb,java.util.*" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%
ArrayList<String[]> list = connDb.index();
%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>ECharts 可视化分析餐饮推荐</title>
<link href="./css/style.css" type='text/css' rel="stylesheet"/>
<script src="./js/echarts.min.js"></script>
</head>
<body>
<div class='header'>
<p>ECharts 可视化分析餐饮推荐</p>
</div>
<div class="content">
<div class="nav">
<ul>
<li class="current"><a href="#">不同星级菜品消费对比</a></li>
<li><a href="./index1.jsp">菜品消费是否推荐对比</a></li>
<li><a href="./index2.jsp">部分菜品消费数量对比</a></li>
<li><a href="./index3.jsp">销售前五的菜品</a></li>
</ul>
</div>
<div class="container">
<div class="title">不同星级菜品消费对比</div>
<div class="show">
<div class='chart-type'>饼图</div>
<div id="main"></div>
</div>
</div>
</div>
<script>
//基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
option = {
backgroundColor: '#2c343c',
title: {
text: '不同星级菜品消费对比比例图',
left: 'center',
top: 20,
textStyle: {
color: '#ccc'
}
},
tooltip : {
trigger: 'item',
formatter: "{a} <br/>{b} : {c} ({d}%)"
},
visualMap: {
show: false,
min: 80,
max: 600,
inRange: {
colorLightness: [0, 1]
}
},
series : [
{
name:'消费行为',
type:'pie',
radius : '55%',
center: ['50%', '50%'],
data:[
{value:<%=list.get(0)[1]%>, name:'2'},
{value:<%=list.get(1)[1]%>, name:'3'},
{value:<%=list.get(2)[1]%>, name:'4'},
{value:<%=list.get(3)[1]%>, name:'5'},
].sort(function (a, b) { return a.value - b.value}),
roseType: 'angle',
label: {
normal: {
textStyle: {
color: 'rgba(255, 255, 255, 0.3)'
}
}
},
labelLine: {
normal: {
lineStyle: {
color: 'rgba(255, 255, 255, 0.3)'
},
smooth: 0.2,
length: 10,
length2: 20
}
},
itemStyle: {
normal: {
color: '#c23531',
shadowBlur: 200,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
},
animationType: 'scale',
animationEasing: 'elasticOut',
animationDelay: function (idx) {
return Math.random() * 200;
}
}
]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
</body>
</html>
Java代码:
package dbtaobao;
import java.sql.*;
import java.util.ArrayList;
public class connDb {
private static Connection con = null;
private static Statement stmt = null;
private static ResultSet rs = null;
//连接数据库方法
public static void startConn(){
try{
Class.forName("com.mysql.jdbc.Driver");
//连接数据库中间件
try{
con = DriverManager.getConnection("jdbc:MySQL://localhost:3306/dbtaobao","root","123456");
}catch(SQLException e){
e.printStackTrace();
}
}catch(ClassNotFoundException e){
e.printStackTrace();
}
}
//关闭连接数据库方法
public static void endConn() throws SQLException{
if(con != null){
con.close();
con = null;
}
if(rs != null){
rs.close();
rs = null;
}
if(stmt != null){
stmt.close();
stmt = null;
}
}
//数据库双11 所有买家消费行为比例
public static ArrayList index() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("SELECT `action`, COUNT(*) AS num\n"
+ "FROM `user_log`\n"
+ "GROUP BY `action`\n"
+ "ORDER BY num DESC;\n"
+ "");
while(rs.next()){
String[] temp={rs.getString("action"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
//男女买家交易对比
public static ArrayList index_1() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("SELECT gender, COUNT(*) AS num\n"
+ "FROM user_log\n"
+ "GROUP BY gender\n"
+ "ORDER BY gender DESC;\n"
+ "");
while(rs.next()){
String[] temp={rs.getString("gender"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
//男女买家各个年龄段交易对比
public static ArrayList index_2() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("SELECT gender, age_range, COUNT(*) AS num\n"
+ "FROM user_log\n"
+ "GROUP BY gender, age_range\n"
+ "ORDER BY gender DESC, age_range DESC;\n"
+ "");
while(rs.next()){
String[] temp={rs.getString("gender"),rs.getString("age_range"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
//获取销量前五的商品类别
public static ArrayList index_3() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("SELECT cat_id, COUNT(*) AS num\n"
+ "FROM user_log\n"
+ "GROUP BY cat_id\n"
+ "ORDER BY COUNT(*) DESC\n"
+ "LIMIT 5;\n"
+ "");
while(rs.next()){
String[] temp={rs.getString("cat_id"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
//各个省份的总成交量对比
public static ArrayList index_4() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select province,count(*) num from user_log group by province order by count(*) DESC");
while(rs.next()){
String[] temp={rs.getString("province"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
}
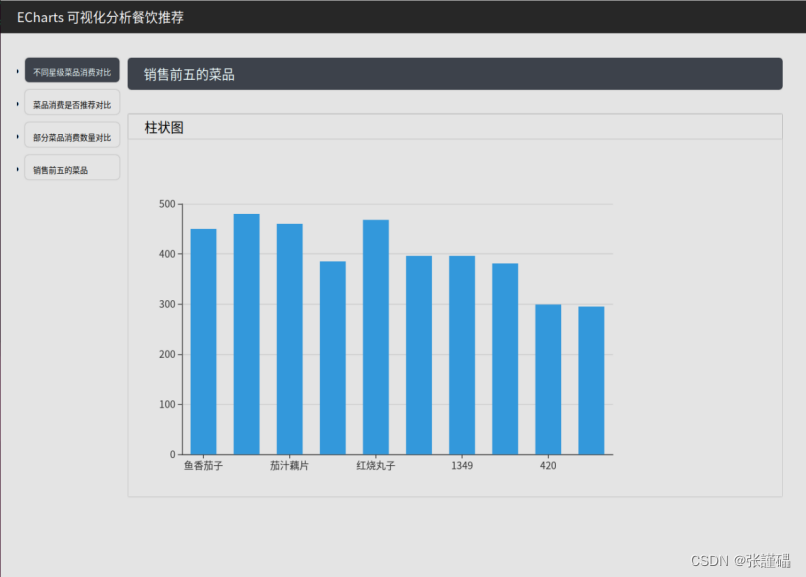
3.1.3 运行截图
4.总结体会
通过本系统的设计与实现,我深刻体会到了大数据和机器学习在智能推荐领域的应用价值。在实际开发过程中,我遇到了许多挑战,如数据清洗的复杂性、推荐算法的优化等。但通过不断的学习和实践,我逐渐掌握了相关技术,并成功实现了系统的各项功能。未来,我将继续深入研究大数据和机器学习领域,探索更多可能的应用场景。
5.附录
版权归原作者 张謹礧 所有, 如有侵权,请联系我们删除。