

各位大佬们好!我是小白,前两天接了一个单子,根据客户给出的公司名单去招标网获取公司的所有招标数据,因为客户给的实在太多了,小白也就勉为其难的答应了,做完之后连夜将自己的过程记录的下来跟大家分享一下,希望对一下刚接触的朋友提供一些帮助,也希望大佬们的指正,也欢迎加入我的公zhong号:小白的大数据之旅,一起交流学习。
本文爆肝3W字,里面每一个步骤都比较详细和清楚,可以认真慢慢观看,因为是临时写的,其实还是有一些不足的地方和需要优化的地方,大家如果有什么建议也可以在评论区讨论哦。祝大家事业有成,学业顺利!
初始化
导入必要的库
首先导入接下来自动化所需要的库
from selenium.webdriver.common.by import By
from time import sleep
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pandas as pd
import requests
from sqlalchemy import create_engine
import pymysql
- selenium.webdriver.common.by import By: Selenium是一个用于Web应用程序自动化测试的工具。By类提供了一系列用于定位页面元素的方法,如通过ID、名称、XPath、CSS选择器等。这使得编写用于自动化浏览器操作的脚本变得更加容易。
- from time import sleep: sleep函数用于使程序暂停执行指定的秒数。在自动化测试中,它常被用来等待页面加载完成或元素出现,以确保脚本的稳定性和准确性。
- from selenium import webdriver: webdriver是Selenium的核心组件之一,它提供了与浏览器交互的接口。通过它,你可以控制浏览器执行各种操作,如打开网页、点击按钮、填写表单等。
- from selenium.webdriver.chrome.options import Options: Options类允许你配置Chrome浏览器的启动选项,如设置无头模式(不打开浏览器界面)、禁用图片加载、设置代理等。这对于自动化测试中的浏览器行为定制非常有用。
- import pandas as pd: Pandas是一个强大的数据处理和分析库。它提供了易于使用的数据结构和数据分析工具,使得数据清洗、转换、分析和可视化变得更加简单和高效。
- import requests: Requests是一个用于发送HTTP请求的Python库。它简化了与Web服务的交互,使得发送GET、POST等请求以及处理响应变得直观和简单。
- from sqlalchemy import create_engine: SQLAlchemy是一个SQL工具包和对象关系映射(ORM)库。create_engine函数用于创建一个数据库引擎,该引擎可以与数据库建立连接,并执行SQL语句。它支持多种数据库后端,如MySQL、PostgreSQL等。
- import pymysql: PyMySQL是一个纯Python实现的MySQL客户端。它允许你通过Python代码与MySQL数据库进行交互,执行SQL语句、管理数据库连接等。与SQLAlchemy结合使用时,可以更方便地进行数据库操作。
定义数据库连接
首先定义一下数据库的连接,方便后面使用Pandas进行数据库的访问和写入
adb_param ={'DBHOST':'localhost','DBUSER':'root','DBPASS':'xxxx','DBNAME':'ectouch','PORT':3306}
这里定义了一个字典adb_param,包含了连接MySQL数据库所需的所有参数。其中,
DBHOST
是数据库主机地址,
DBUSER
是数据库用户名,
DBPASS
是数据库密码,
DBNAME
是数据库名,
PORT
是数据库端口号。
conn=create_engine('mysql+pymysql://{}:{}@{}:{}/{}'.format(adb_param['DBUSER'],
adb_param['DBPASS'],
adb_param['DBHOST'],
adb_param['PORT'],
adb_param['DBNAME']))
这里使用了一个格式化字符串,并通过.format方法将adb_param字典中的值插入到相应的位置。这样,就构造出了一个完整的MySQL数据库连接字符串。这个连接字符串遵循了
dialect+driver://username:password@host:port/database
的格式,其中
dialect
是数据库方言(这里是mysql),
driver
是数据库驱动(这里是pymysql),
username
是数据库用户名,
password
是数据库密码,
host
是数据库主机地址,
port
是数据库端口号,
database
是数据库名。
最后,将构造好的连接字符串传递给create_engine函数,创建了一个数据库连接引擎。这个引擎可以用于执行SQL语句、管理数据库连接等。
这里只是做一个爬虫项目,如果在企业级别的实战中,最好是把
账户
,
密码
这些都放大配置文件中。
设置参数关闭自动化检测
chrome_options = Options()# 关闭自动化检测
chrome_options.add_experimental_option('excludeSwitches',['enable-automation'])# 创建WebDriver对象,指定Chrome浏览器和ChromeOptions
driver = webdriver.Chrome(options=chrome_options)
数据库操作
表查询
首先我们先定义一个函数
find_all()
该函数用来从数据库中获取数据,因为在获取数据的时候,我们把获取到的每一个公司的情况都记录到数据库表中,这样方便最后能看到都有哪些表获取到了,那些表没有获取到,这样重新启动程序处理因为特殊情况获取失败的公司的时候,可以直接跳过已经处理完的公司
deffind_all(adb_param):
db = pymysql.connect(
host=adb_param['DBHOST'],
user=adb_param['DBUSER'],
password=adb_param['DBPASS'],
database=adb_param['DBNAME'],
port=adb_param['PORT'])
cursor = db.cursor()#select t1.`index`,t1.allinpay_order_sn,t1.amount,t1.description from tonglian_st2 as t1
cursor.execute('select company_name from company')
data = cursor.fetchall()
data =[row[0]for row in data]return data
- find_all 函数接收一个参数 adb_param,这是一个字典,包含了连接MySQL数据库所需的关键信息:主机地址(DBHOST)、用户名(DBUSER)、密码(DBPASS)、数据库名(DBNAME)以及端口号(PORT)。
- 函数首先利用 pymysql.connect 方法与数据库建立连接,所需参数均从 adb_param 字典中获取。连接成功后,会返回一个数据库连接对象 db。
- 随后,通过 db.cursor() 方法创建一个游标对象 cursor。游标在数据库操作中扮演着重要角色,它允许你执行SQL语句并获取结果。
- 接着,cursor.execute 方法被用来执行一个SQL查询语句,这里的查询是 select company_name from company,目的是从 company 表中检索所有公司的名称。
- 执行查询后,cursor.fetchall 方法被调用以获取查询结果的完整列表。这个方法会返回一个列表,其中每个元素都是一个包含查询结果行的元组。由于我们只关心 company_name 字段,因此使用列表推导式 [row[0] for row in data] 对结果进行处理,提取出每行结果中的第一个元素(即公司名称),并组成一个新的列表。
表插入
创建表
首先在数据库中创建一个表,这个表的作用是记录已经操作完成的公司名称,逐渐自增
CREATETABLE company (
id INTAUTO_INCREMENT,
company_name VARCHAR(50),PRIMARYKEY(id)-- 这里指定了主键,InnoDB会自动为其创建聚集索引 );
定义插入函数
定义一个数据库插入函数,将成功的表插入到数据库中
definsert_at(sql,adb_param):try:
db = pymysql.connect(
host=adb_param['DBHOST'],
user=adb_param['DBUSER'],
password=adb_param['DBPASS'],
database=adb_param['DBNAME'],
port=adb_param['PORT'])#print(sql)
cursor = db.cursor()
cursor.execute(sql)
db.commit()except Exception as e :print(e)print(sql)return
- 数据库连接:函数首先尝试使用pymysql.connect方法和adb_param字典中的信息建立数据库连接。
- SQL执行:连接成功后,函数创建一个游标对象cursor,并使用cursor.execute(sql)执行传入的SQL语句。执行完毕后,通过db.commit()提交事务,确保更改被保存到数据库中(如果SQL语句是插入、更新或删除操作的话)。
- 异常处理:如果在执行SQL语句或提交事务过程中发生异常,函数会捕获这个异常,并打印异常信息和传入的SQL语句。然后,函数通过return语句提前结束,不会执行后续的代码。需要注意的是,这里的return语句后面有一个多余的),这是一个语法错误,应该被移除。
- 游标管理:由于异常处理部分提前返回,如果SQL执行成功,函数会再次创建一个新的游标对象cursor(这里的代码设计存在问题,因为成功执行SQL后不应该再次创建游标,除非有必要执行另一个SQL语句)。然而,由于前面的异常处理可能导致函数提前返回,这个新创建的游标实际上只有在没有异常发生时才会被使用。
- 查询公司名称:无论前面的SQL语句执行成功与否(实际上,由于异常处理的存在,如果失败则函数不会执行到这里),函数都会尝试使用新创建的游标执行一个查询语句,从company表中检索所有公司的名称。
- 结果处理:查询结果通过cursor.fetchall()获取,并使用列表推导式处理成只包含公司名称的列表。
- 返回值:函数返回处理后的公司名称列表。
设置异常处理函数
因为在有一些情况下,每个招标信息的内容都是不固定的,例如项目编号,有的招标信息有,有的招标信息没有,所以要先做好异常处理,如果定位不到指定的元素就给默认是而不是报错
defget_element_text(dr,locator):"""
尝试获取指定定位器的元素文本,如果不存在则返回空字符串。
:param dr: 每个招标的实例
:param locator: 元素定位器,例如 (By.ID, 'element_id')
:return: 元素文本或空字符串
"""try:
element = dr.find_element(By.XPATH,locator)return element.text
except Exception:return""
设置报警函数
这一步可有可无,因为我担心有一些写入到数据库失败或者没有找到公司的情况,有这种情况的话就直接通过企业微信向我发送报警,因为要获取的公司很多数据量也很大,我们自己也不可能一直在电脑前面看着,直接挂到后台就行,然后如果程序出现问题直接通过机器人给我们报警就可以了,当然了,大家也可以采用其他方式进行报警提醒
defto_qw_error(mess):
url ="https://qyapi"
headers ={"Content-Type":"application/json"}
data ={"msgtype":"text","text":{"content": mess,"mentioned_mobile_list":["xxx"]}}
result = requests.post(url, headers=headers, json=data)return
url中写上企业微信的机器人地址
mentioned_mobile_list中写上自己的手机号,用于机器人进行@
该函数接收一个mess参数,该参数是要发送的报错信息
读取公司名称
因为要批量获取指定公司的名称,这些公司名称都放到了Excel文件中,所以要从Excel文件中读取这些公司的名称然后循环去自动化查询
# 读取要查询的公司名称
df = pd.read_excel('公司名称.xlsx')# 将结果转换成数组
company_lis = df.to_numpy()
打开网页
打开网页之后先停留10秒,因为没有登录
#打开网页
driver.get('https://xunbiaobao.baidu.com/s?q=%E5%8C%97%E4%BA%AC%E6%96%B9%E6%AD%A3%E7%A7%91%E6%8A%80%E4%BF%A1%E6%81%AF%E4%BA%A&tab=0&count')#等待50秒钟,最好别访问太快
sleep(50)
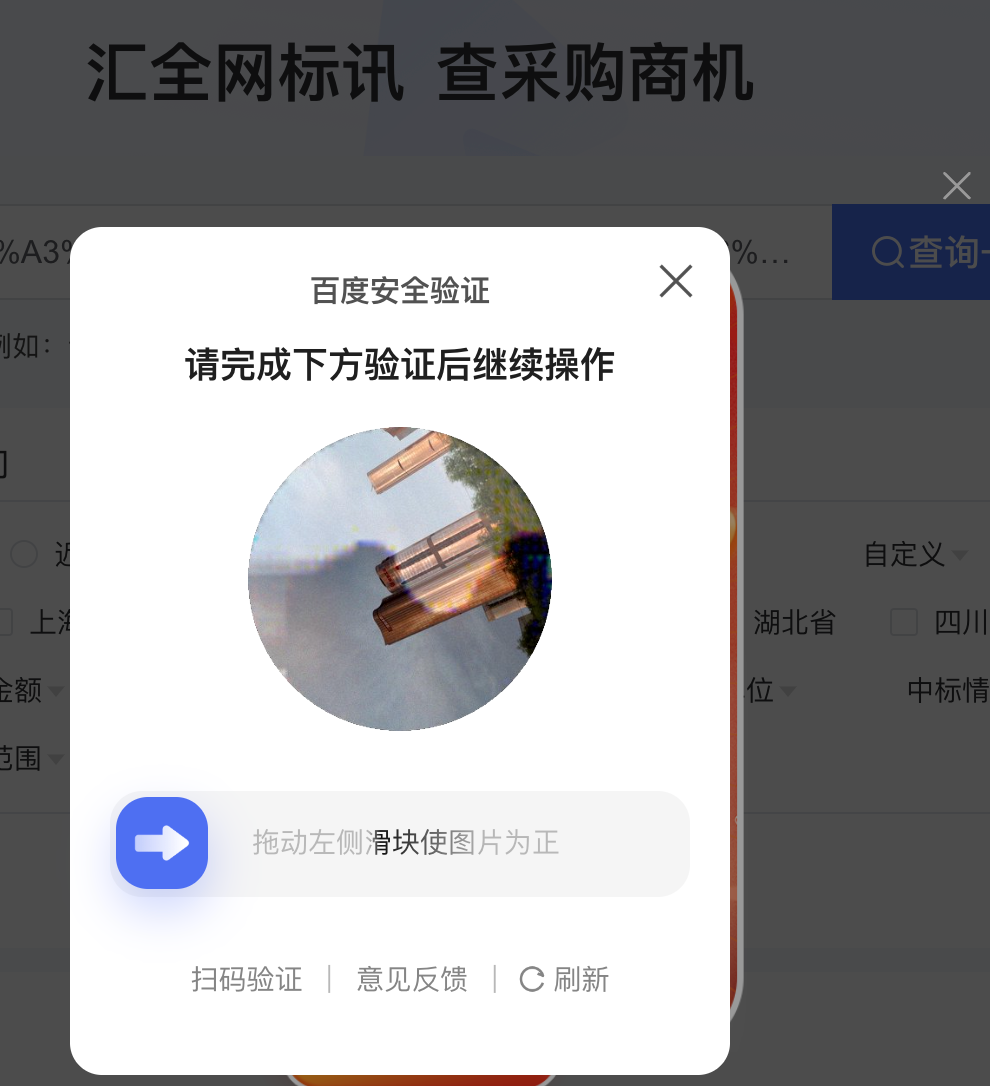
因为没有登录,打开网站的时候可能会出现一些验证,这些验证可能回不相同,这里暂时通过等待50秒之后手动处理验证
例如下面这种验证,但是验证可能不止一种
循环处理公司
开始循环遍历要查询的公司
for company_name in company_lis:
判断是否已处理
通过调用find_all()函数获取已经查询过的公司,然后进行判断,如果已经处理过了就跳过本次循环
data = find_all(adb_param)#如果已经执行过的公司就不处理了if company_name[0]in data :#已经执行过的表=公司不进行处理,跳过本次循环continueprint(f'当前正在执行公司名称为:{company_name}')
定位输入框
# 定位输入框
inputs = driver.find_element(By.XPATH,'/html/body/div[1]/div/div[1]/div[1]/div/div/section/span/span[1]/div[1]/div/input')# 先清空输入框,保证输入公司名之前输入框中是空的
inputs.clear()# 将公司名称写入到输入框中
inputs.send_keys(company_name[0])

点击查询
在输入完公司名称之后定位查询按钮点击查询
# 点击搜索
driver.find_element(By.XPATH,'/html/body/div[1]/div/div[1]/div[1]/div/div/section/span/span[2]/button').click()

滑动页面
因为在点击搜索之后页面可能会出现滑动到中间的位置,为了避免出现其他情况,点击搜索之后将页面滑动到最上方,因为查询到的结果就在最上方
# 使用JavaScript执行器让页面滚动到最上面,因为点击搜索之后可能会出现页面下滑的情况,导致点击企业的时候找不到,所以点击搜索后先把页面划到最上面
driver.execute_script("window.scrollTo(0, 0);")
查询到的公司
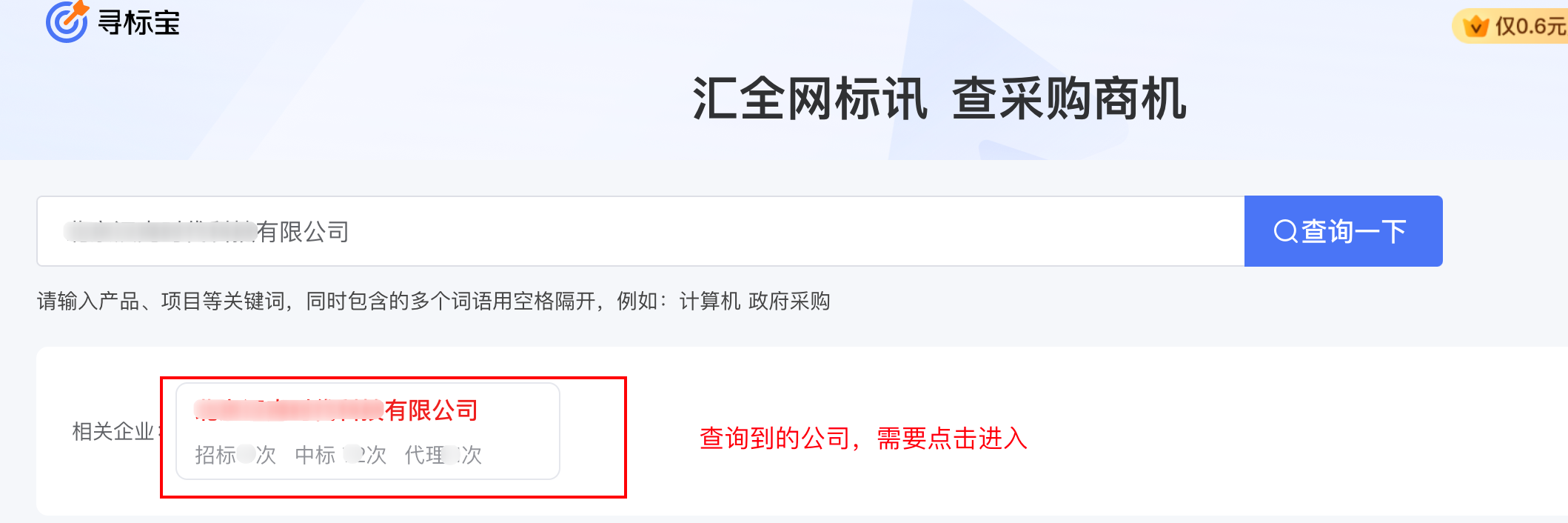
点击企业
查询之后出来的结果,我们点击自己查找的企业
try:# 点击企业
driver.find_element(By.XPATH,'//div[@class="enterprise-title"]').click()except Exception:#如何点击企业报错,说明没有找到企业,那么直接向企微发送报错信息
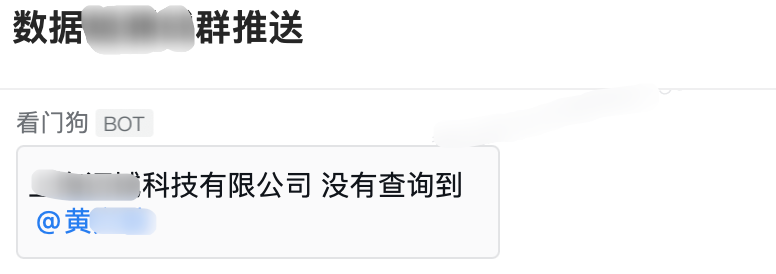
mess =f'{company_name[0]} 没有查询到'print(mess)
to_qw_error(mess)#然后跳出本次循环continue
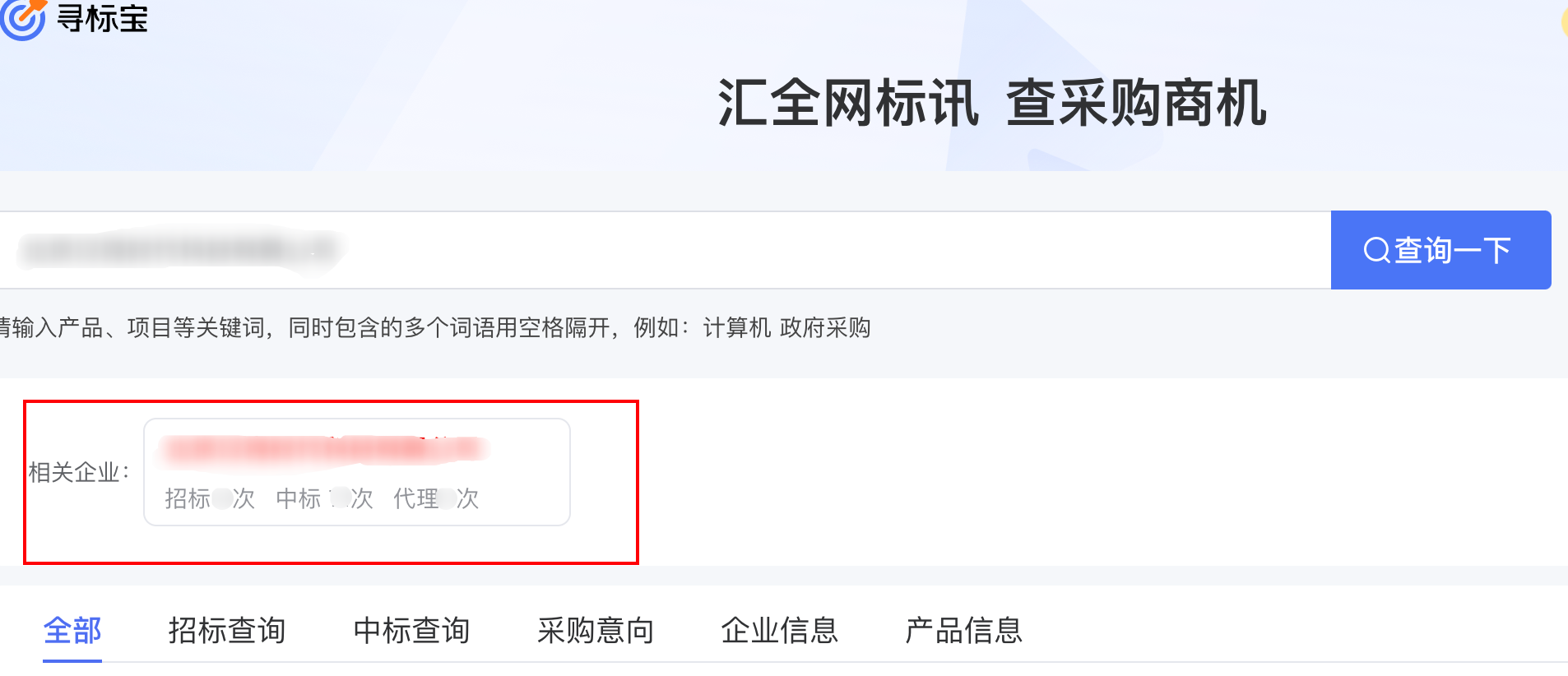
如果没有查找到指定的企业的话会报错,那么就捕捉到这个异常,通过企业微信报警函数发送一个报警信息,然后跳过本次循环,进行下一个公司的查询处理
没有找到指定公司的情况:
企微发送报警信息
跳转到最新的窗口
点击企业之后之后会进入到新的窗口,这时我们需要进行跳转,跳转到新的窗口,新的窗口就是该公司的信息
# 获取打开的多个窗口句柄,获取所有标签页
windows = driver.window_handles
# 切换到当前最新打开的窗口,-1指的是最后一个标签页,也就是最新的标签页
driver.switch_to.window(windows[-1])
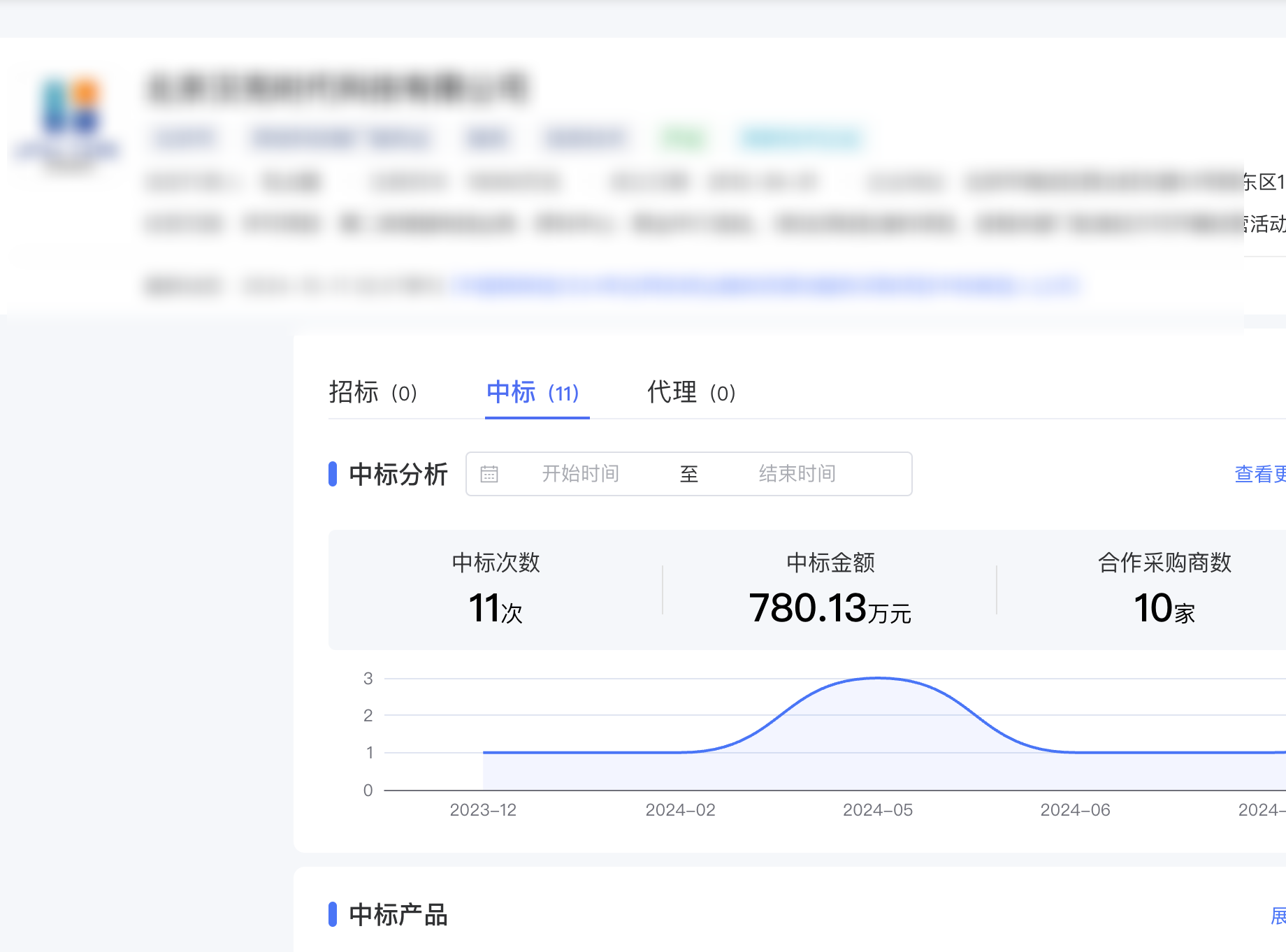
获取公司的基本信息
# 获取公司名称
company = get_element_text(driver,'/html/body/div[1]/div/div[1]/div/div[1]/div[1]/div[2]/div[1]')# 获取注册资本
capital = get_element_text(driver,'/html/body/div[1]/div/div[1]/div/div[1]/div[1]/div[2]/div[3]/div[2]/div[2]')# 获取成立日期
establishment = get_element_text(driver,'/html/body/div[1]/div/div[1]/div/div[1]/div[1]/div[2]/div[3]/div[3]/div[2]')# 获取企业地址
address = get_element_text(driver,'/html/body/div[1]/div/div[1]/div/div[1]/div[1]/div[2]/div[3]/div[4]/div[2]')# 获取经营范围
business = get_element_text(driver,'/html/body/div[1]/div/div[1]/div/div[1]/div[1]/div[2]/div[4]/span[1]')

调整单位角色
具体位置在这里
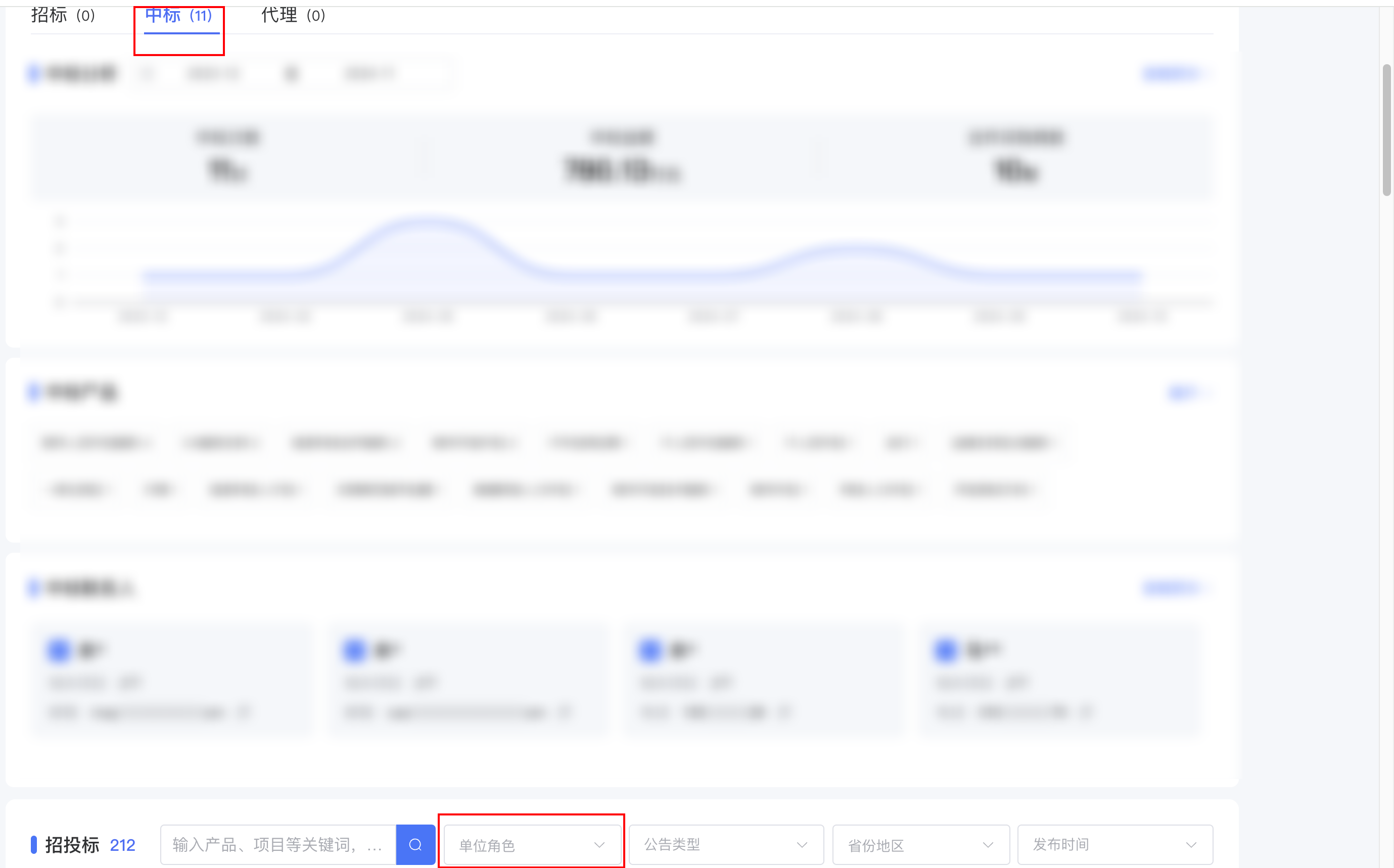
点击下拉框
# 定位到单位角色下拉框
driver.find_element(By.XPATH,'/html/body/div[1]/div/div[1]/div/div[5]/div[1]/div[2]/div[2]/div[1]/div/div/div[2]/div/span[1]/span').click()
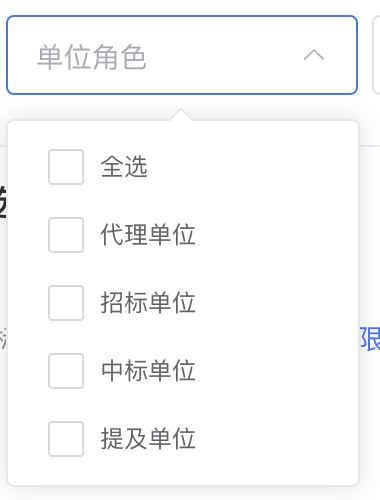
选中需要的内容
根据要求,我们只需要查看
中标单位
和
提及单位
,但是有的信息中会默认勾选其他单位,例如代理单位,这个时候就需要判断,如果非
中标单位
和
提及单位
被选中的话就取消勾选,如果
中标单位
和
提及单位
没有被选中就点击勾选
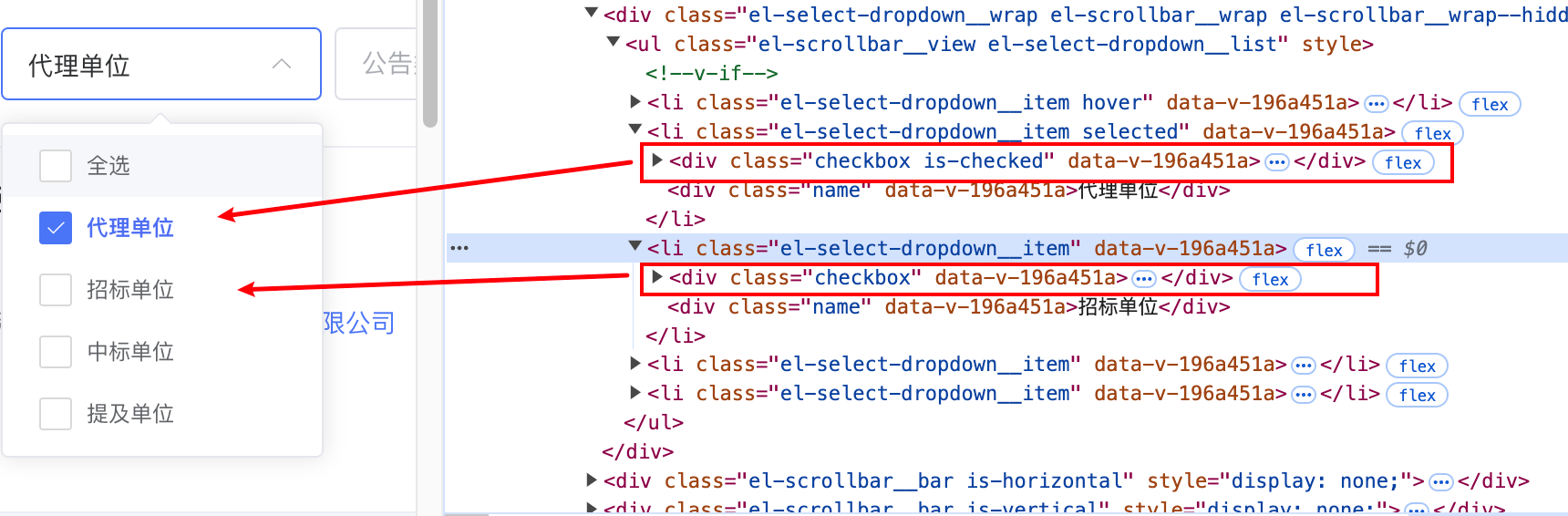
try:#代理单位
list_li2_div1 = driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[2]/div[1]').get_attribute('class')#如果代理单位的class不等于checkbox说明已经被选中了,那么就取消选中if list_li2_div1 !="checkbox":
driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[2]/div[1]').click()# 招标单位
list_li2_div1 = driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[3]/div[1]').get_attribute('class')# 如果招标单位的class不等于checkbox说明已经被选中了,那么就取消选中if list_li2_div1 !="checkbox":
driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[3]/div[1]').click()# 中标单位
list_li2_div1 = driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[4]/div[1]').get_attribute('class')# 如果中标单位的class等于checkbox说明没有被选中了,那么就点击选中if list_li2_div1 =="checkbox":
driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[4]/div[1]').click()# 提及单位
list_li2_div1 = driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[5]/div[1]').get_attribute('class')# 如果提及单位的class等于checkbox说明没有被选中了,那么就点击选中if list_li2_div1 =="checkbox":
driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[5]/div[1]').click()except Exception :
to_qw_error('点击复选框出错了,快来查看!!!')
这里是通过复选框中每个选项的class属性进行判断,如果class属性的值为
checkbox
就表示该复选框没有被选中,被选中的情况下class的值为
checkbox is-checked
,使用.get_attribute(‘class’)可以获取该标签的class属性的值,通过这个值来判断是否勾选
让复选框生效
因为页面没有查询按钮,在复选框中勾选了我们需要的选项后页面是不会生效的,需要点击页面空白处让复选框中的选项生效,这里随便找个位置点击一下,我找的是图标的位置,点击这个位置页面不会有其他反映,但是会让复选框生效
# 然后随机点击一个非有效的地方让刚才的提及中标生效,不然不生效
driver.find_element(By.XPATH,'/html/body/div[1]/div/div[1]/div/div[5]/div[1]/div[1]/div/span').click()

获取页数
当复选框生效之后,下面的招标信息表格中的内容就更新了,现在我们需要先获取更新后的页数,方便后面进行翻页的时候判断是否到了尾页
page =int(driver.find_element(By.XPATH,'/html/body/div[1]/div/div[1]/div/div[5]/section/div/div[2]/div/ul/li[last()]').text)# 获取总条数#article = int(driver.find_element(By.XPATH,'/html/body/div[1]/div/div[1]/div/div[5]/section/div/div[2]/div/span[1]').text)print(f'总页数为:{page} 页')

循环处理表格
初始化变量
首先初始化一些后面需要用到的变量,可以根据情况而定,然后开启循环,来循环处理每一页的内容,当前页的内容处理完之后就点击下一页,然后继续循环处理,当前页数到达页面总页数的时候,处理完本次之后就停止循环
#定义一个变量,判断当前执行到第几页,到达页面的最后一页的时候就停止当前循环
num =1#定义一个变量,判断当前执行到第几条数据
num2 =1#定一个空数组,存储获取到的招标信息,然后这个数组会放到Pandas中进行处理
df_lis =[]whileTrue:
判断是否最后一页
这里判断的时候是在循环开始的时候判断,而且判断的条件是大于,如果当前循环的次数大于页数就停止循环,表示该公司的招标信息已经获取完毕,例如总页数是10页,当前已经执行到第10页了,但是不满足下面的判断条件,循环还会走下去,继续获取第10页的内容,当第10页的内容获取完毕之后,循环再次回到这里,这个时候应该处理第11页了,num就等于11了,但是没有第11页,下面的条件生效直接停止循环
每十页停顿一下是为了防止访问过快被网站检测到,这个可以根据情况而定,可加可不加
# 如果超过页数,直接停止循环if num > page:break#每十页停顿一下if num%10==0:
sleep(2)
获取表格中的内容
现在就要开始获取招投标表格中各个公司的信息了
首先定位到表格
因为表格里面有多个公司,每个公司都在div标签下,所以使用find_elements来进行定位,定位到该页的所有公司,然后循环遍历每一个公司
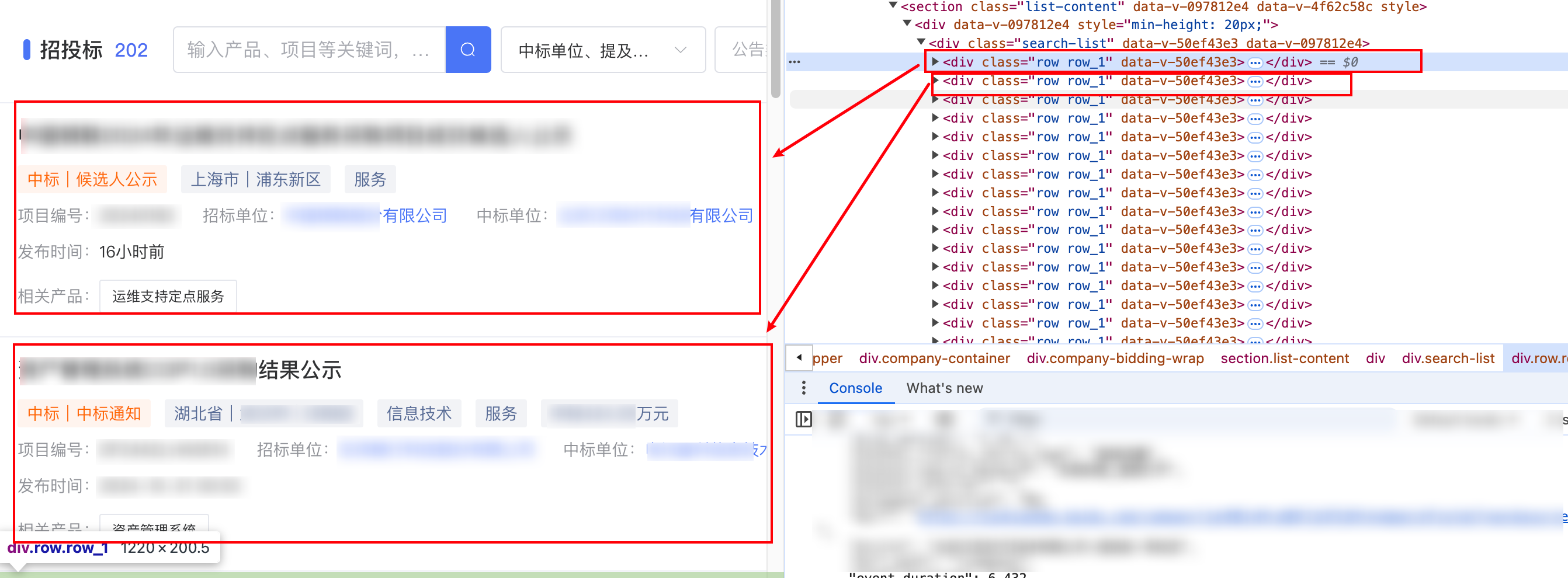
# 定位到表格
table = driver.find_element(By.XPATH,'//div[@class="search-list"]')
divs = table.find_elements(By.XPATH,'div[@class="row row_1"]')#循环处理每一个招标信息for div in divs:
- driver.find_element(By.XPATH,‘//div[@class=“search-list”]’):使用XPath定位到页面上类名为search-list的div元素,这里将其视为“表格”,尽管它实际上是一个div容器。
- table.find_elements(By.XPATH,‘div[@class=“row row_1”]’):在上一步定位的“表格”内,查找所有类名为row row_1的div元素。这些div元素代表了表格中的每一行数据,这里每一行代表一个招标信息。
- for div in divs::遍历上一步找到的所有div元素(即每个招标信息)。
开始循环遍历每一个公司
# 定位到表格
table = driver.find_element(By.XPATH,'//div[@class="search-list"]')
divs = table.find_elements(By.XPATH,'div[@class="row row_1"]')for div in divs:
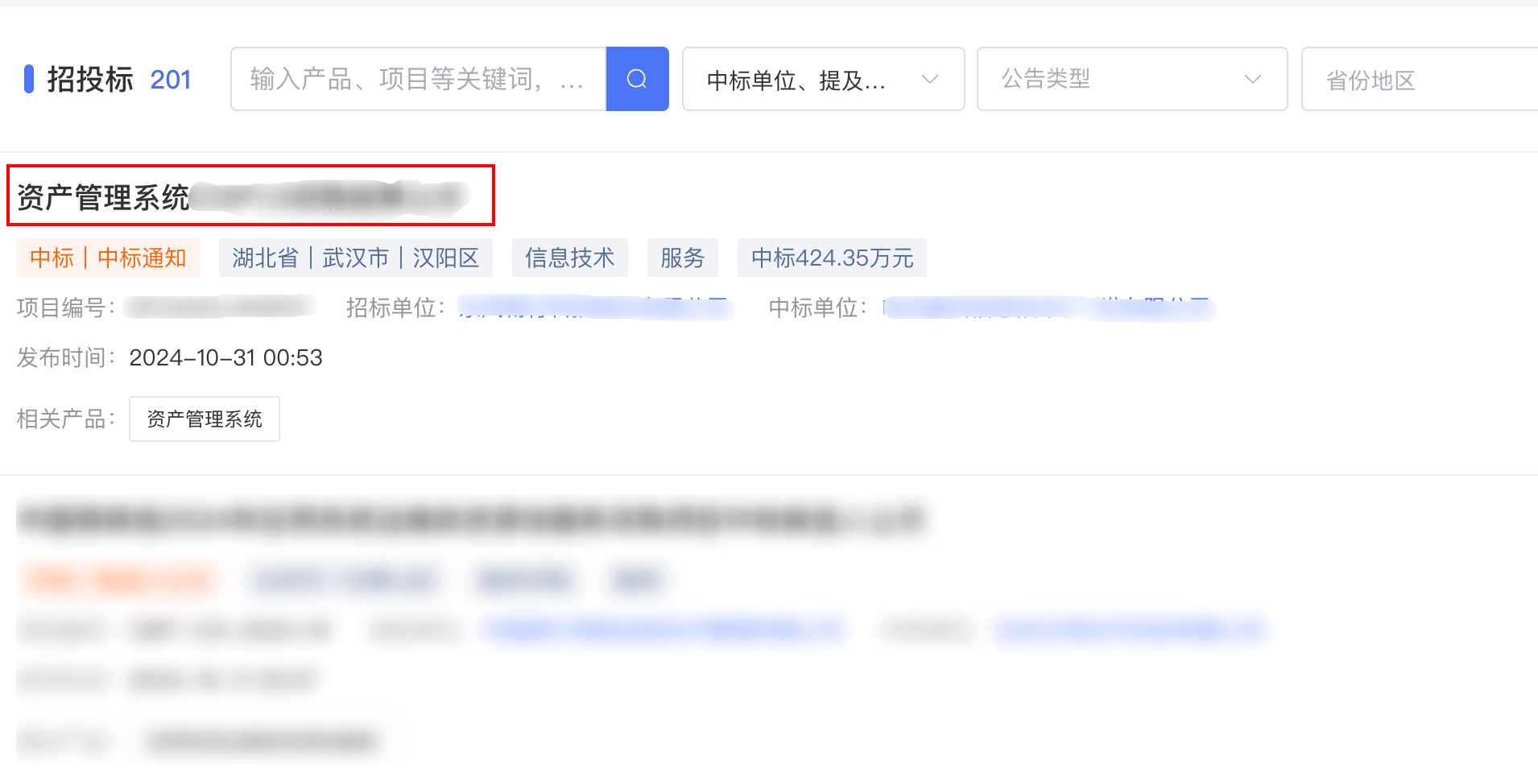
获取招标信息标题
for div in divs:#print(f'当前正在获取第 {num2} 条数据')# 获取招标名称try:
title = div.find_element(By.TAG_NAME,'h6').text
except Exception:
title ="没有获取到招标名称"
获取第一行的内容
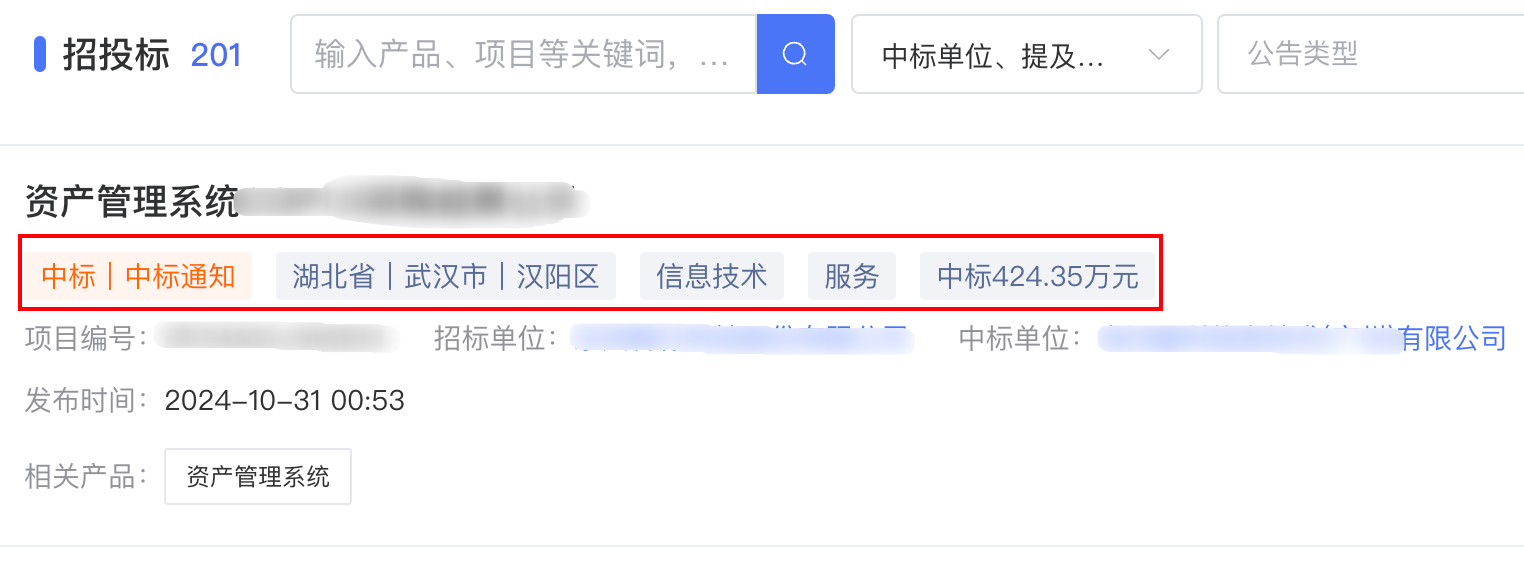
因为第一行的内容是不固定的,有个招标信息有,有的没有,而且数量还不一致,所以直接干脆放到一个变量中,通过循环遍历每一个,然后放到数组中,通过列表推导式进行拼接
try:# 获取第一行的内容,是多个内容,因为内容的数量不固定,直接通过循环获取然后每个内容用括号()包起来
spans = div.find_elements(By.XPATH,'div[@class="row-tags"]/span')# 初始化一个空列表,用于存储从span元素中提取的文本内容
content_lis =[]# 遍历所有找到的span元素for span in spans:# 将每个span元素的文本内容添加到列表中
content_lis.append(span.text)# 使用列表推导式和字符串的join方法,将列表中的每个元素用括号括起来,并拼接成一个字符串
content_tag =''.join([f'({x})'for x in content_lis])except Exception as e:print(e)# 如果在尝试获取内容的过程中发生任何异常,则将content_tag设置为空字符串
content_tag =""
获取第二行的内容
因为第二行的内容不一定存在所以在定位的时候要做好找不到的准备,所有通过前面定义的异常处理函数来定位,如果定位不到就给空字符串
# 获取第二行内容中的项目编号,调用函数,如果没有就返回空
sn = get_element_text(div,'div[@class="row-list"]/div[@class="flex product-no"]/div')# 获取第二行内容中的招标单位
bidding = get_element_text(div,'div[@class="row-list"]/div[@class="row-list company-name"]/div[1]/div')# 获取第二行内容中的中标单位
win = get_element_text(div,'div[@class="row-list"]/div[@class="row-list company-name"]/div[2]/div')

获取第三行的发布时间
在定位发布时间的时候,通过XPATH定位的时候有两个div标签并且改标签的
class
的值都是
row-tags
,但是根据查看,我们需要的是第二个div标签,那么定位的时候直接通过相对路径执行
class="row-tags"
,但是因为要获取的是第二个所以在后面加上
[2]
# 获取第三行的发布时间,有两个@class="row-tags"的div标签,在后面使用[2]这样就可以定位到第二个div[@class="row-tags"]的标签
release_times = get_element_text(div,'div[@class="row-tags"][2]/div/span[2]')
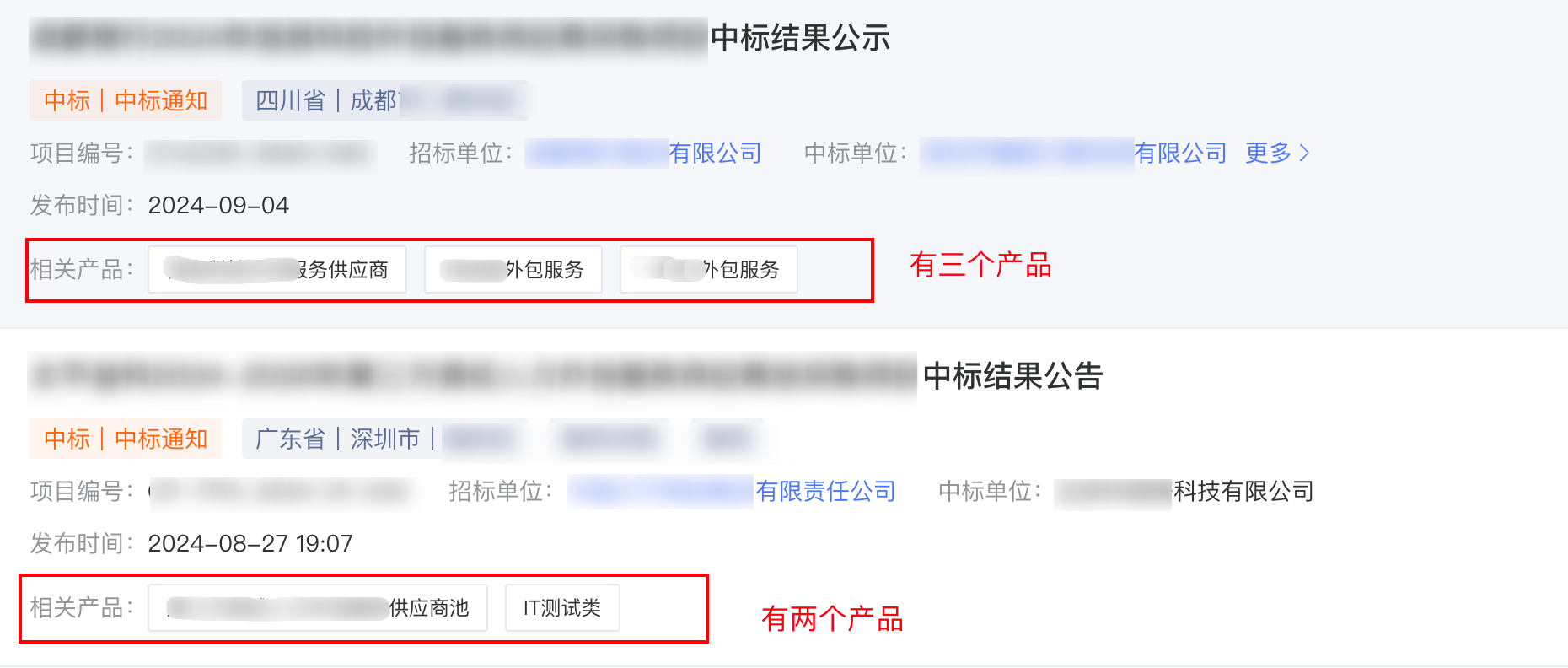
获取相关产品
每个招标信息的相关产品是不固定的,可能会没有,也可能会有一个或者多个,所以需要通过循环来获取所有的相关产品,如果没有定位到就说明该招标信息没有相关产品,那么就给一个默认值
try:# 尝试获取相关产品信息。由于一个招标信息可能包含多个产品,因此需要循环遍历这些产品,并将它们的信息拼接到一起
span_products = div.find_elements(By.XPATH,'div[@class="product-list"]/div/span')# 初始化一个空列表,用于存储从span元素中提取的产品信息
products_lis =[]# 遍历所有找到的产品span元素for span_product in span_products:# 将每个span元素的文本内容(即产品信息)添加到列表中
products_lis.append(span_product.text)# 使用列表推导式和字符串的join方法,将列表中的每个产品信息用括号括起来,并拼接成一个字符串
product =''.join([f'({x})'for x in products_lis])except Exception:# 如果在尝试获取产品信息的过程中发生任何异常,则将product设置为"无相关产品"
product ="无相关产品"#将获取到的信息添加到数组中
df_lis.append([company,capital,establishment,address,business,title,content_tag,sn,bidding,win,release_times,product])# num2自增加一,每次循环加一,为了记录获取到了第几条信息,可有可无
num2+=1
对页数进行处理
进入到上层循环中的最下面,等循环处理招标数据的循环执行完一遍之后就表示当前页的数据获取完毕,需要点击下一页或者其他操作
#如果只有1页,就直接停止循环,不要再点击下一页了if page ==1:breakprint(f'当前第 {num} 页')#让变量加1进入下一页的查询
num +=1#点击进入下一页try:#点击下一页
driver.find_element(By.XPATH,'/html/body/div[1]/div/div[1]/div/div[5]/section/div/div[2]/div/button[2]').click()except Exception as e:print(e)
处理数据
当所有页面处理完成之后,再进入到上一层循环,对数据进行处理,将数组中存储的数据放到Pandas中,然后通过Pandas存储到数据库中
存储数组
将数组中的数据存储到Pandas中,并且给每一个列命名
df = pd.DataFrame(data=df_lis,columns=['公司名称','注册资本','成立日期','企业地址','经营范围','招标项目名称','招标信息','项目编号','招标单位','中标单位','发布时间','相关产品'])
写入到数据库
#将Pandas中的数据写入到数据库中,数据库的表名就是查看公司的名称
df.to_sql(name=str(company_name[0]), con=conn, if_exists='append', chunksize=None)
记录已处理的表
#如果写入数据库完成之后,将成功的公司名称写入到数据库中的company表中作为记录,表名该公司已经处理完成,重启任务的时候不会重复处理
sql ='insert into company(company_name) values("{0}")'.format(company_name[0])#调用insert_at函数
insert_at(sql,adb_param)
进行预防处理
try:
sleep(15)#将Pandas中的数据写入到数据库中,数据库的表名就是查看公司的名称
df.to_sql(name=str(company_name[0]), con=conn, if_exists='append', chunksize=None)#如果写入数据库完成之后,将成功的公司名称写入到数据库中的company表中作为记录,表名该公司已经处理完成,重启任务的时候不会重复处理
sql ='insert into company(company_name) values("{0}")'.format(company_name[0])#调用insert_at函数
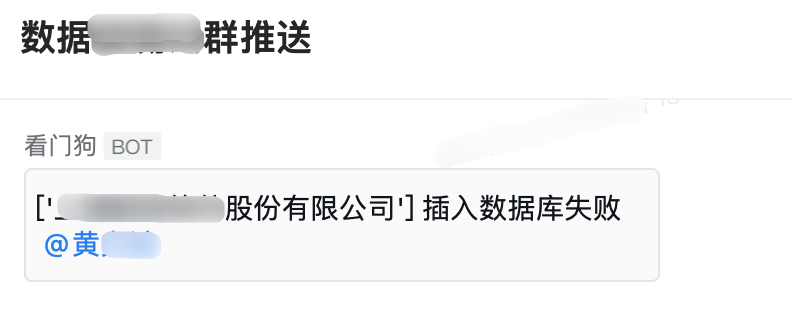
insert_at(sql,adb_param)except Exception as e:print(e)#定义报错信息,插入数据库失败
mess =f'{company_name} 插入数据库失败'#调用企微报警函数,将报错信息传入进去
to_qw_error(mess)
关闭页面
当前面获取完该公司的所有招标数据之后,就关闭当前页面,然后进入当上一个页面,再次搜索下一个公司进行处理
#当一个公司执行完毕之后,就关闭当前窗口然后进入上一个查询公司的窗口记录进行查询公司
driver.close()# 获取打开的多个窗口句柄,获取所有标签页
windows = driver.window_handles
# 切换到当前最新打开的窗口,0就是第一个窗口
driver.switch_to.window(windows[0])
完整代码
# coding:utf-8from selenium.webdriver.common.by import By
from time import sleep
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pandas as pd
import requests
from sqlalchemy import create_engine
import pymysql
adb_param ={'DBHOST':'localhost','DBUSER':'root','DBPASS':'xxxx','DBNAME':'ectouch','PORT':3306}
conn=create_engine('mysql+pymysql://{}:{}@{}:{}/{}'.format(adb_param['DBUSER'],
adb_param['DBPASS'],
adb_param['DBHOST'],
adb_param['PORT'],
adb_param['DBNAME']))#查询deffind_all(adb_param):
db = pymysql.connect(
host=adb_param['DBHOST'],
user=adb_param['DBUSER'],
password=adb_param['DBPASS'],
database=adb_param['DBNAME'],
port=adb_param['PORT'])
cursor = db.cursor()#select t1.`index`,t1.allinpay_order_sn,t1.amount,t1.description from tonglian_st2 as t1
cursor.execute('select company_name from company')
data = cursor.fetchall()
data =[row[0]for row in data]return data
definsert_at(sql,adb_param):try:
db = pymysql.connect(
host=adb_param['DBHOST'],
user=adb_param['DBUSER'],
password=adb_param['DBPASS'],
database=adb_param['DBNAME'],
port=adb_param['PORT'])#print(sql)
cursor = db.cursor()
cursor.execute(sql)
db.commit()except Exception as e :print(e)print(sql)returndefget_element_text(dr,locator):"""
尝试获取指定定位器的元素文本,如果不存在则返回空字符串。
:param dr: 每个招标的实例
:param locator: 元素定位器,例如 (By.ID, 'element_id')
:return: 元素文本或空字符串
"""try:
element = dr.find_element(By.XPATH,locator)return element.text
except Exception:return""#报警函数defto_qw_error(mess):#替换成自己的企业微信机器人Webhook地址
url ="https://qyapixxxxxx"
headers ={"Content-Type":"application/json"}
data ={"msgtype":"text","text":{"content": mess,# 替换成自己的手机号"mentioned_mobile_list":["xxxx"]}}
result = requests.post(url, headers=headers, json=data)return# 读取要查询的公司名称
df = pd.read_excel('公司名称.xlsx')
company_lis = df.to_numpy()
chrome_options = Options()# 关闭自动化检测
chrome_options.add_experimental_option('excludeSwitches',['enable-automation'])# 创建WebDriver对象,指定Chrome浏览器和ChromeOptions
driver = webdriver.Chrome(options=chrome_options)#打开网页
driver.get('https://xunbiaobao.baidu.com/s?q=%E5%8C%97%E4%BA%AC%E6%96%B9%E6%AD%A3%E7%A7%91%E6%8A%80%E4%BF%A1%E6%81%AF%E4%BA%A&tab=0&count')#等待10秒钟,最好别访问太快
sleep(50)for company_name in company_lis:
data = find_all(adb_param)#如果已经执行过的表就不处理了if company_name[0]in data :#已经执行过的表不进行处理,跳过本次循环continueprint(f'当前正在执行公司名称为:{company_name}')# 定位输入框
inputs = driver.find_element(By.XPATH,'/html/body/div[1]/div/div[1]/div[1]/div/div/section/span/span[1]/div[1]/div/input')# 先清空输入框,保证输入公司名之前输入框中是空的
inputs.clear()# 将公司名称写入到输入框中
inputs.send_keys(company_name[0])
sleep(0.5)# 点击搜索
driver.find_element(By.XPATH,'/html/body/div[1]/div/div[1]/div[1]/div/div/section/span/span[2]/button').click()
sleep(5)# 使用JavaScript执行器让页面滚动到最上面,因为点击搜索之后可能会出现页面下滑的情况,导致点击企业的时候找不到,所以点击搜索后先把页面划到最上面
driver.execute_script("window.scrollTo(0, 0);")try:# 点击企业
driver.find_element(By.XPATH,'//div[@class="enterprise-title"]').click()except Exception:#如何点击企业报错,说明没有找到企业,那么直接向企微发送报错信息
mess =f'{company_name[0]} 没有查询到'print(mess)
to_qw_error(mess)#然后跳出本次循环continue
sleep(3)# 获取打开的多个窗口句柄,获取所有标签页
windows = driver.window_handles
# 切换到当前最新打开的窗口,-1指的是最后一个标签页,也就是最新的标签页
driver.switch_to.window(windows[-1])
sleep(3)# 获取公司名称
company = get_element_text(driver,'/html/body/div[1]/div/div[1]/div/div[1]/div[1]/div[2]/div[1]')# 获取注册资本
capital = get_element_text(driver,'/html/body/div[1]/div/div[1]/div/div[1]/div[1]/div[2]/div[3]/div[2]/div[2]')# 获取成立日期
establishment = get_element_text(driver,'/html/body/div[1]/div/div[1]/div/div[1]/div[1]/div[2]/div[3]/div[3]/div[2]')# 获取企业地址
address = get_element_text(driver,'/html/body/div[1]/div/div[1]/div/div[1]/div[1]/div[2]/div[3]/div[4]/div[2]')# 获取经营范围
business = get_element_text(driver,'/html/body/div[1]/div/div[1]/div/div[1]/div[1]/div[2]/div[4]/span[1]')# 定位到单位角色下拉框
driver.find_element(By.XPATH,'/html/body/div[1]/div/div[1]/div/div[5]/div[1]/div[2]/div[2]/div[1]/div/div/div[2]/div/span[1]/span').click()
sleep(3)#lis_div = driver.find_element(By.XPATH,'//div[@id="el-popper-container-9470"]/div[3]/div/div/div')#driver.find_element(By.XPATH, '/html/body/div[2]/div[3]/div/div/div[1]/ul/li[5]/div[1]').click()# 不知道为什么,不打开浏览器的时候有时候定位元素会报错,然后我就先给一个trytry:#代理单位
list_li2_div1 = driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[2]/div[1]').get_attribute('class')#如果代理单位的class不等于checkbox说明已经被选中了,那么就取消选中if list_li2_div1 !="checkbox":
driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[2]/div[1]').click()# 招标单位
list_li2_div1 = driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[3]/div[1]').get_attribute('class')# 如果招标单位的class不等于checkbox说明已经被选中了,那么就取消选中if list_li2_div1 !="checkbox":
driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[3]/div[1]').click()# 中标单位
list_li2_div1 = driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[4]/div[1]').get_attribute('class')# 如果中标单位的class等于checkbox说明没有被选中了,那么就点击选中if list_li2_div1 =="checkbox":
driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[4]/div[1]').click()# 提及单位
list_li2_div1 = driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[5]/div[1]').get_attribute('class')# 如果提及单位的class等于checkbox说明没有被选中了,那么就点击选中if list_li2_div1 =="checkbox":
driver.find_element(By.XPATH,'/html/body/div[2]/div[3]/div/div/div[1]/ul/li[5]/div[1]').click()except Exception :
to_qw_error('点击复选框出错了,快来查看!!!')
sleep(2)# 然后随机点击一个非有效的地方让刚才的提及中标生效,不然不生效
driver.find_element(By.XPATH,'/html/body/div[1]/div/div[1]/div/div[5]/div[1]/div[1]/div/span').click()
sleep(3)#定位招标表格一共有几页,好做翻页操作,转换成int类型
page =int(driver.find_element(By.XPATH,'/html/body/div[1]/div/div[1]/div/div[5]/section/div/div[2]/div/ul/li[last()]').text)# 获取总条数#article = int(driver.find_element(By.XPATH,'/html/body/div[1]/div/div[1]/div/div[5]/section/div/div[2]/div/span[1]').text)print(f'总页数为:{page} 页')#定义一个变量,判断当前执行到第几页,到达页面的最后一页的时候就停止当前循环
num =1#定义一个变量,判断当前执行到第几条数据
num2 =1#定一个空数组,存储获取到的招标信息,然后这个数组会放到Pandas中进行处理
df_lis =[]whileTrue:# 如果超过页数,直接停止循环if num > page:break#每十页停顿一下if num%10==0:
sleep(2)#sleep(3)# 定位到表格
table = driver.find_element(By.XPATH,'//div[@class="search-list"]')
divs = table.find_elements(By.XPATH,'div[@class="row row_1"]')for div in divs:#print(f'当前正在获取第 {num2} 条数据')# 获取招标名称try:
title = div.find_element(By.TAG_NAME,'h6').text
except Exception:
title ="没有获取到招标名称"try:# 获取第一行的内容,是多个内容,因为内容的数量不固定,直接通过循环获取然后每个内容用括号()包起来
spans = div.find_elements(By.XPATH,'div[@class="row-tags"]/span')# 初始化一个空列表,用于存储从span元素中提取的文本内容
content_lis =[]# 遍历所有找到的span元素for span in spans:# 将每个span元素的文本内容添加到列表中
content_lis.append(span.text)# 使用列表推导式和字符串的join方法,将列表中的每个元素用括号括起来,并拼接成一个字符串
content_tag =''.join([f'({x})'for x in content_lis])except Exception as e:print(e)# 如果在尝试获取内容的过程中发生任何异常,则将content_tag设置为空字符串
content_tag =""# 获取第二行内容中的项目编号,调用函数,如果没有就返回空
sn = get_element_text(div,'div[@class="row-list"]/div[@class="flex product-no"]/div')# 获取第二行内容中的招标单位
bidding = get_element_text(div,'div[@class="row-list"]/div[@class="row-list company-name"]/div[1]/div')# 获取第二行内容中的中标单位
win = get_element_text(div,'div[@class="row-list"]/div[@class="row-list company-name"]/div[2]/div')# 获取第三行的发布时间,有两个@class="row-tags"的div标签,在后面使用[2]这样就可以定位到第二个div[@class="row-tags"]的标签
release_times = get_element_text(div,'div[@class="row-tags"][2]/div/span[2]')try:# 尝试获取相关产品信息。由于一个招标信息可能包含多个产品,因此需要循环遍历这些产品,并将它们的信息拼接到一起
span_products = div.find_elements(By.XPATH,'div[@class="product-list"]/div/span')# 初始化一个空列表,用于存储从span元素中提取的产品信息
products_lis =[]# 遍历所有找到的产品span元素for span_product in span_products:# 将每个span元素的文本内容(即产品信息)添加到列表中
products_lis.append(span_product.text)# 使用列表推导式和字符串的join方法,将列表中的每个产品信息用括号括起来,并拼接成一个字符串
product =''.join([f'({x})'for x in products_lis])except Exception:# 如果在尝试获取产品信息的过程中发生任何异常,则将product设置为"无相关产品"
product ="无相关产品"#将获取到的信息添加到数组中
df_lis.append([company,capital,establishment,address,business,title,content_tag,sn,bidding,win,release_times,product])#sleep(2)
num2+=1#如果只有1页,就直接停止循环,不要再点击下一页了if page ==1:breakprint(f'当前第 {num} 页')#让变量加1进入下一页的查询
num +=1#点击进入下一页try:#点击下一页
driver.find_element(By.XPATH,'/html/body/div[1]/div/div[1]/div/div[5]/section/div/div[2]/div/button[2]').click()except Exception as e:print(e)
df = pd.DataFrame(data=df_lis,columns=['公司名称','注册资本','成立日期','企业地址','经营范围','招标项目名称','招标信息','项目编号','招标单位','中标单位','发布时间','相关产品'])try:
sleep(15)#将Pandas中的数据写入到数据库中,数据库的表名就是查看公司的名称
df.to_sql(name=str(company_name[0]), con=conn, if_exists='append', chunksize=None)#如果写入数据库完成之后,将成功的公司名称写入到数据库中的company表中作为记录,表名该公司已经处理完成,重启任务的时候不会重复处理
sql ='insert into company(company_name) values("{0}")'.format(company_name[0])#调用insert_at函数
insert_at(sql,adb_param)except Exception as e:print(e)#定义报错信息,插入数据库失败
mess =f'{company_name} 插入数据库失败'#调用企微报警函数,将报错信息传入进去
to_qw_error(mess)#当一个公司执行完毕之后,就关闭当前窗口然后进入上一个查询公司的窗口记录进行查询公司
driver.close()# 获取打开的多个窗口句柄,获取所有标签页
windows = driver.window_handles
# 切换到当前最新打开的窗口,0就是第一个窗口
driver.switch_to.window(windows[0])# 结束任务
driver.quit()
最后
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走! 希望能帮助到你!【100%无套路免费领取】



版权归原作者 长风清留扬 所有, 如有侵权,请联系我们删除。