
1. 问题背景
用spark-sql,insert overwrite分区表时发现两个比较麻烦的问题:
- 从目标表select出来再insert overwrite目标表时报错:Error in query: Cannot overwrite a path that is also being read from.
- 从其他表select出来再insert overwrite目标表时,其他分区都被删除了.
2. 问题描述
2.1 代码示例
drop table pt_table_test1;
create table pt_table_test1 (
id int,
region string,
dt string
) using parquet
partitioned by (region, dt)
;
drop table pt_table_test2;
create table pt_table_test2 (
id int,
region string,
dt string
) using parquet
partitioned by (region, dt)
;
set hive.exec.dynamic.partition =true;
set hive.exec.dynamic.partition.mode = nonstrict;
truncate table pt_table_test1;
insert into table pt_table_test1 values (1,'id', '2022-10-01'),(2,'id', '2022-10-02'),(3,'ph', '2022-10-03'),(1,'sg', '2022-10-01'),(2,'sg', '2022-10-02'),(3,'ph', '2022-10-03');
select * from pt_table_test1;
insert overwrite table pt_table_test1 select * from pt_table_test1 where dt = '2022-10-01';
select * from pt_table_test1;
truncate table pt_table_test2;
insert into table pt_table_test2 values (2,'id', '2022-10-01'),(2,'id', '2022-10-02'),(2,'sg', '2022-10-01'),(2,'sg', '2022-10-02');
insert overwrite table pt_table_test1 select * from pt_table_test2 where id = 2;
select * from pt_table_test1;
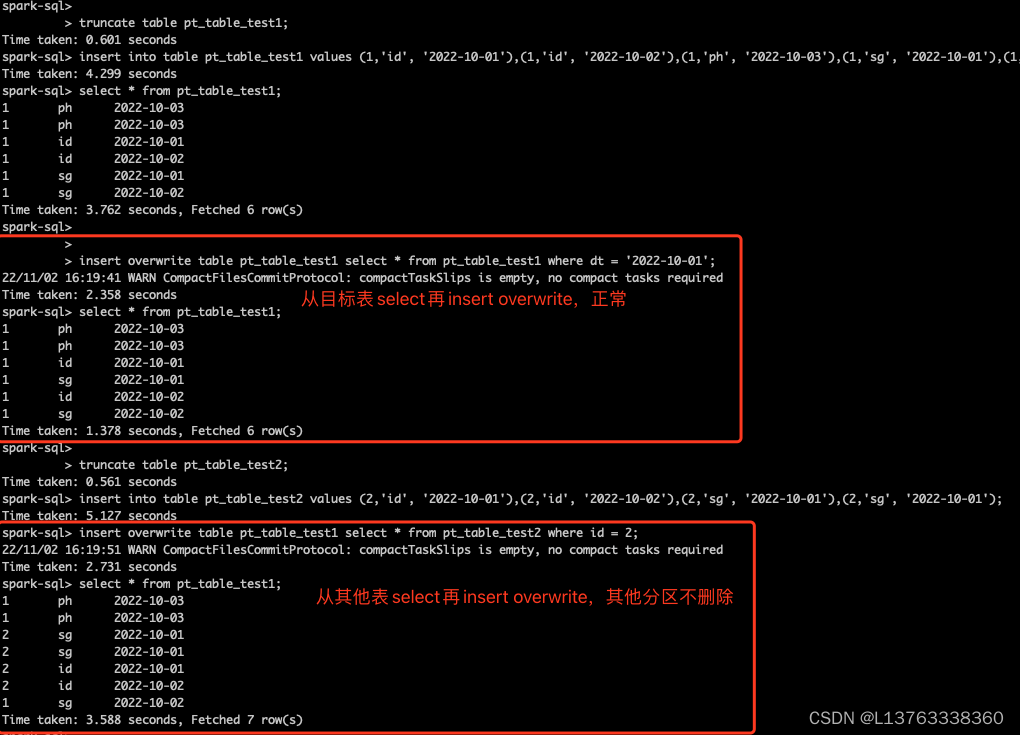
2.2 错误演示

3. 解决方法
印象中这两个问题也出现过,但凭经验和感觉,应该可以解决。找到以前正常运行的表,对比分析了下,发现是建表方式不一致问题:
- 错误建表,指定表的文件格式:using parquet
- 正确姿势,指定表的文件格式:stored as parquet
3.1 示例代码
drop table pt_table_test1;
create table pt_table_test1 (
id int,
region string,
dt string
) stored as parquet
partitioned by (region, dt)
;
drop table pt_table_test2;
create table pt_table_test2 (
id int,
region string,
dt string
) stored as parquet
partitioned by (region, dt)
;
set hive.exec.dynamic.partition =true;
set hive.exec.dynamic.partition.mode = nonstrict;
truncate table pt_table_test1;
insert into table pt_table_test1 values (1,'id', '2022-10-01'),(1,'id', '2022-10-02'),(1,'ph', '2022-10-03'),(1,'sg', '2022-10-01'),(1,'sg', '2022-10-02'),(1,'ph', '2022-10-03');
select * from pt_table_test1;
insert overwrite table pt_table_test1 select * from pt_table_test1 where dt = '2022-10-01';
select * from pt_table_test1;
truncate table pt_table_test2;
insert into table pt_table_test2 values (2,'id', '2022-10-01'),(2,'id', '2022-10-02'),(2,'sg', '2022-10-01'),(2,'sg', '2022-10-02');
insert overwrite table pt_table_test1 select * from pt_table_test2 where id = 2;
select * from pt_table_test1;
3.2 正确演示
4. using parqnet和stored as parquet
对比两种建表:
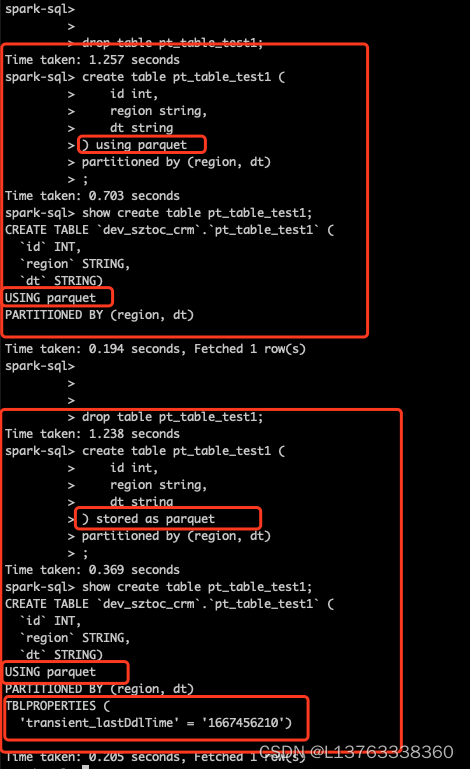
- 建表无论是using parquet还是stored as parquet,执行show create table都显示: USING parquet。
- stored as parquet时,执行show create table,新增了TBLPROPERTIES属性。
本文转载自: https://blog.csdn.net/L13763338360/article/details/127653946
版权归原作者 L13763338360 所有, 如有侵权,请联系我们删除。
版权归原作者 L13763338360 所有, 如有侵权,请联系我们删除。