
用到的算子有read csv,select attribute,fp-growth,create association rules;set role,decision tree,apply model,cross validation
Exteter是一家综合类百货公司。其销售的商品种类包括:服装、家具用品、健康相关产品、汽车、个人电子产品、电脑、花园相关产品、新奇礼品和珠宝等九大类。为了降低广告促销的成本,公司希望通过挖掘顾客购买记录数据,实现当顾客购买某一件产品时,将“诱饵”商品推荐给顾客,尽可能促使顾客的购买。
公司现有4998条用户购买历史记录(见“数据集-作业1-CatalogCrossSell.xls”),每条记录包含以下字段:
(1)Customer Number:编号,每个顾客有一个唯一的编号用以识别用户;
(2)Clothing Division:0/1, 顾客是否购买了服装。0为未购买,1为购买;
(3)Housewares Division:0/1,顾客是否购买了家具用品。0为未购买,1为购买;
(4)Health Products Division:0/1,顾客是否购买了与健康相关的商品。0为未购买,1为购买;
(5) Automotive Division:0/1,顾客是否购买了汽车。0为未购买,1为购买;
(6)Personal Electronics Division:0/1顾客是否购买了个人电子产品。0为未购买,1为购买;
(7)Computers Division:0/1,顾客是否购买了电脑。0为未购买,1为购买;
(8)Garden Division:0/1,顾客是否购买了有关花园的产品。0为未购买,1为购买;
(9)Novelty Gift Division:0/1,顾客是否购买了新奇礼品。0为未购买,1为购买;
(10)Jewelry Division:0/1, 顾客是否购买了珠宝商品。0为未购买,1为购买。
一、关联分析
1.构建过程
1.1导入数据
选择方法1将数据导入,如图

1.2检查缺失值,异常值
引入Numerical to Binominal算子
将除了Customer Number之外的变量放到右边,如图

这些变量都要0/1变为flase/true
1.3 约减数据集中属性
引入Select Attributes算子,
将除了Customer Number之外的变量放到右边(保留了顾客对不同商品的购买情况),如图
1.4 FP-Growth找到频繁项集
引入FP-Growth算子
设置min support为0.95
如下图,我们可以看到在size2,3中有很多
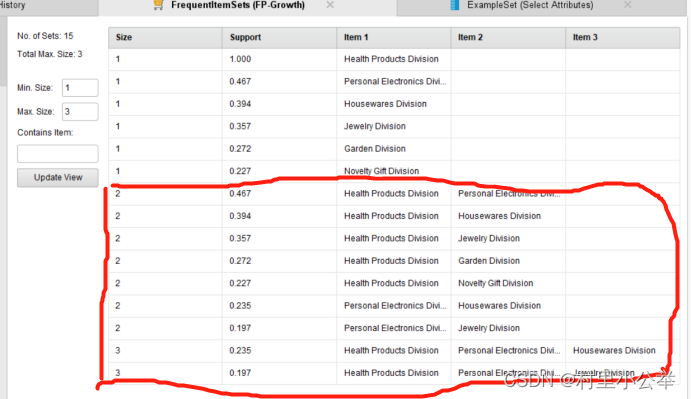
例如,家具用品的购买就和个人电子产品、珠宝商品、花园产品、新奇产品可能存在关联
Size3表示一项的购买可能与其他两项有关,这里就不一一解释。
1.5 产生关联规则
引入Create Association Rules算子
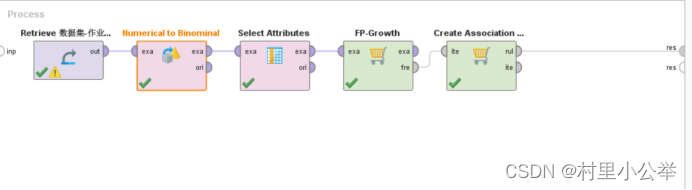
FP-Growth的支持度(Support)参数为0.95情况下,如下图
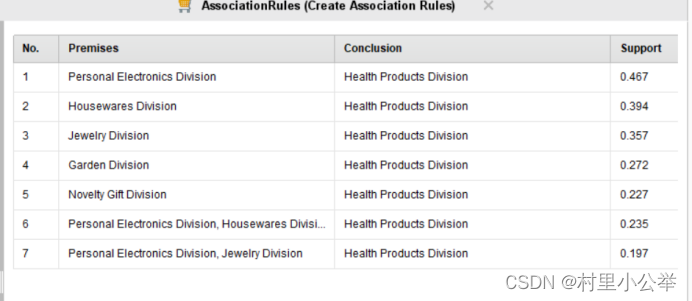
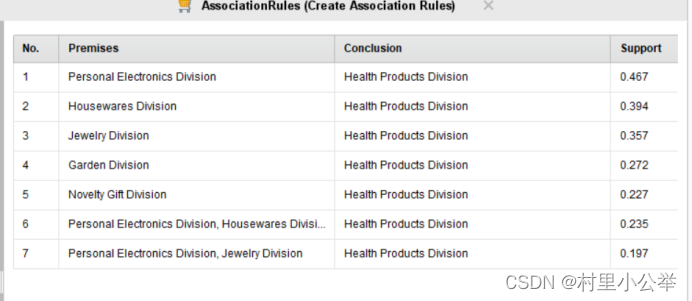
FP-Growth的支持度(Support)参数为0.85情况下,如下图
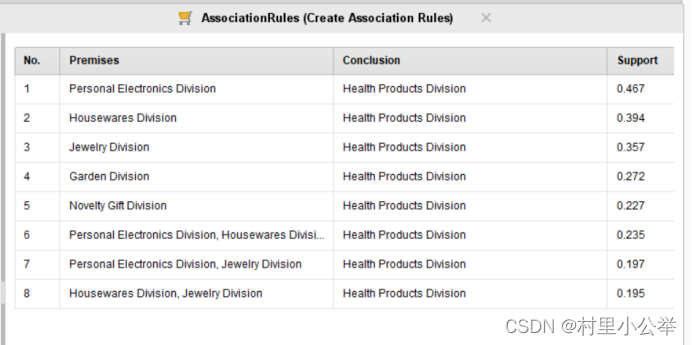
FP-Growth的支持度(Support)参数为0.75情况下,如下图
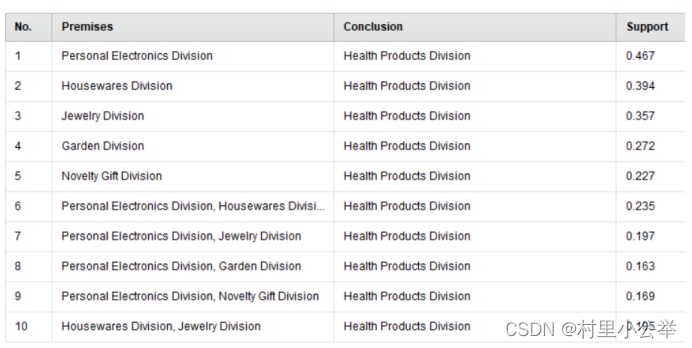
FP-Growth的支持度(Support)参数为0.5情况下,如下图
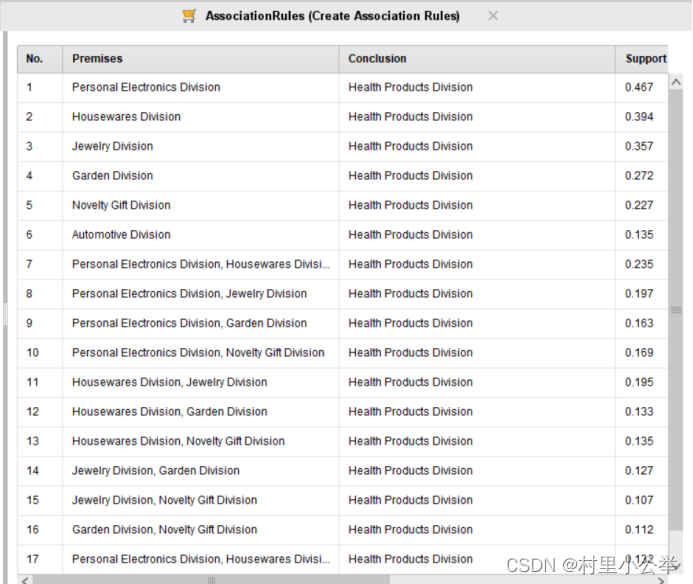
2.对结果的评述
*2.1 FP-Growth的支持度(Support)参数为0.95情况*
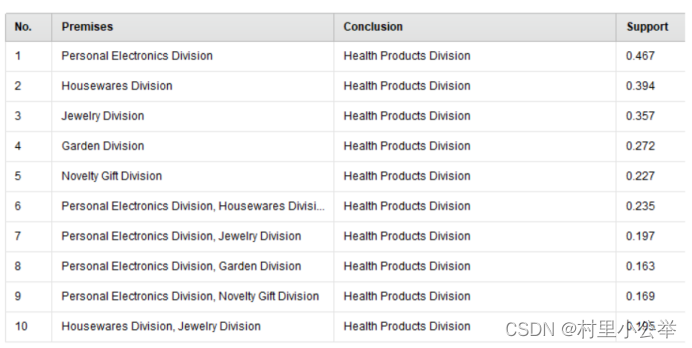
购买了个人电子产品可以推出买了健康相关产品
购买了家具用品可以推出买了健康相关产品
购买了珠宝产品可以推出买了健康相关产品
购买了花园相关产品可以推出买了健康相关产品
购买了新奇产品产品可以推出买了健康相关产品
还有可能由购买了两样物品推出购买了另外的一项产品
购买了个人电子设备和家具可以推出购买了健康有关产品
购买了个人电子产品和珠宝可以推出购买了健康有关产品
2.2 不同min support对关联规则结果的影响
下图依次为min support为0.95,0.85,0.75
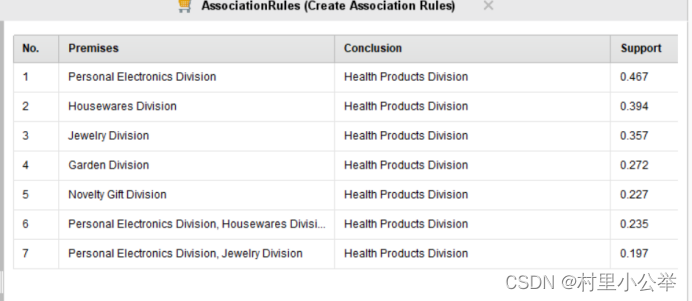
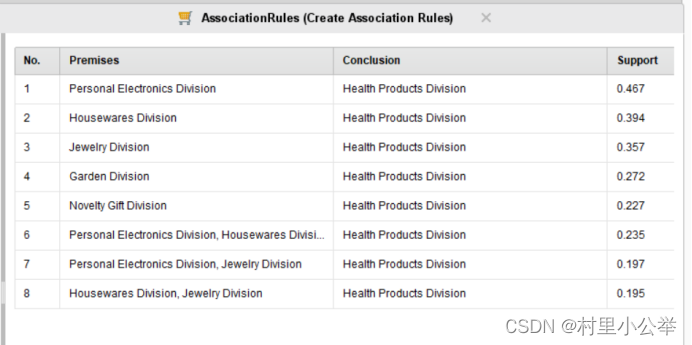
首先,随着支持度的下降,我们可以看到相关联的变量越来越多。但是到了后面的的置信度(support)越来越低,即两个购买行为之间不是太过关联。
同时,我们可以看到,所有的购买行为都是预测会购买健康类的产品,但是由于健康类的产品可以认为是人们日常生活中必须的产品,所以参考意义不大。
2.3 不同min confidence对结果的影响
在之前min confidence为0.8的情况下都是预测健康类,现在我们将min confidence放宽到0.5

结果为

产生了更为多样的预测结果(家具类的购买推出电子产品的购买)
3.促销政策
由之前的关联规则结果,我们可以知道,健康类的产品和其他不同的产品购买相关性很多。可以认为健康类产品是一种必需品,因此可以在商场显眼的位置摆放健康类产品,或者是在顾客结账的地方摆放。还可以将健康类产品和其他的产品捆绑销售。
根据修改min confidence之后的结果,我们知道家具类的购买和电子产品的购买相关联。我们可以在商场的家具购买区判别设置电子产品体验区。
二、分类预测
1.对Titannic Unlabeld进行预测
1.1构建过程
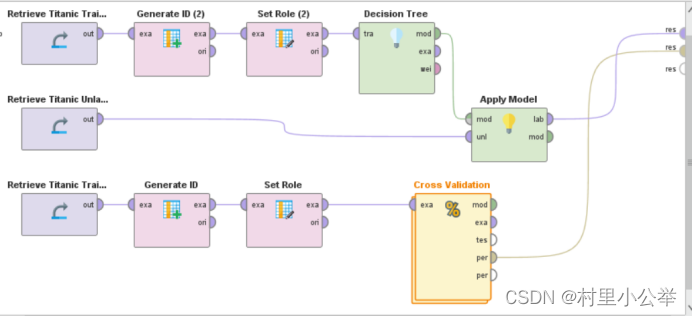
我们对训练数据进行观察,发现没有唯一ID的一列,我们通过Generate ID算子来构建id属性一列
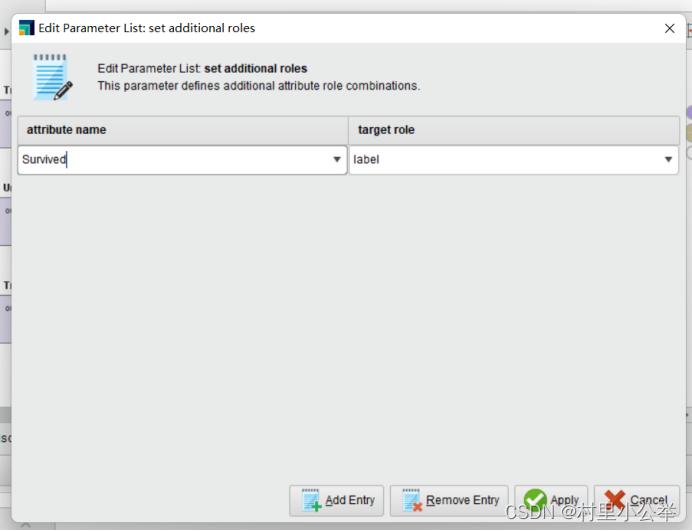
加入Set Role算子
加入Decision Tree和Apply Model算子

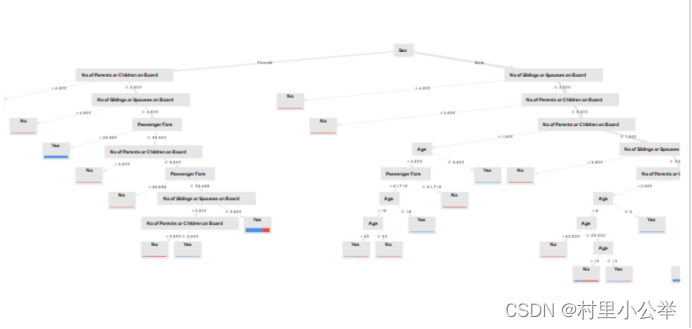

1.2 预测结果
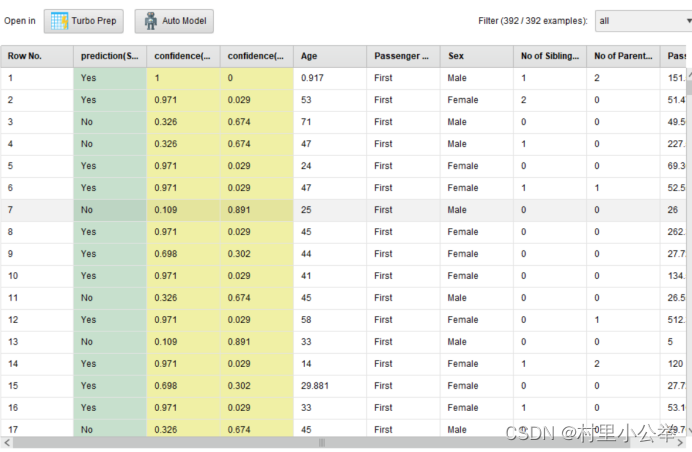
Yes表示存活
1.3 构建决策树过程的发现
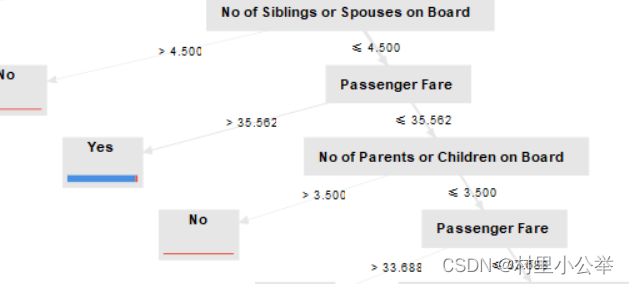
票价大于35.562,且为女性的容易存活
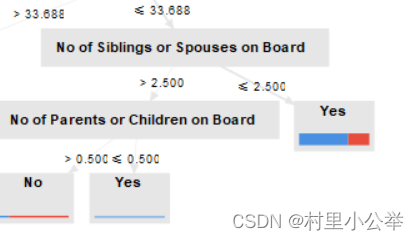
有父母或者小孩的不容易存活
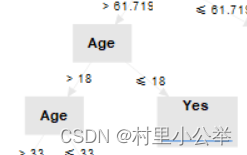
小于18岁的容易存活

票价小于26.144的男性不容易存活
2.五折交叉检验
2.1 引入Cross Validation算子
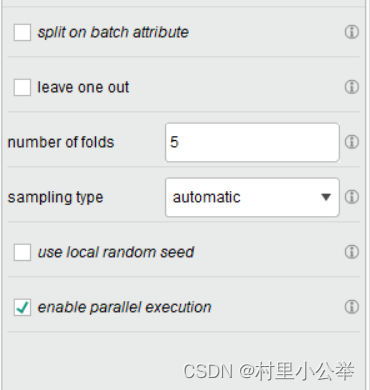
2.2 将number of folds改为5
2.3 进入子流程进行配置
如图
2.4 结果
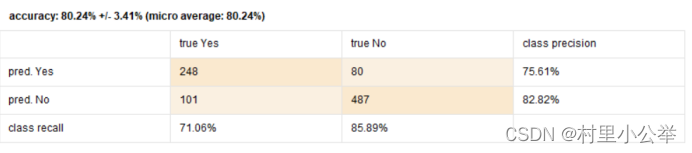
如图,我们可以看到,对于Yes的预测,准确率有71.06%。
对于No的预测,准确率有85.89%。
accuracy: 80.24% +/- 3.41% (micro average: 80.24%)
3.改变criterion参数
将参数修改为gini_index
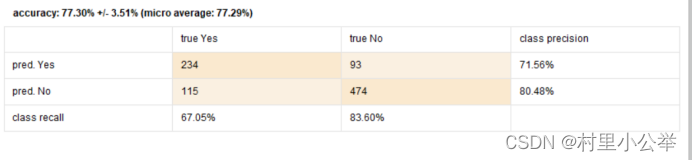
根据检验表,我们可以看到准确率相较于gini_ratio有下降
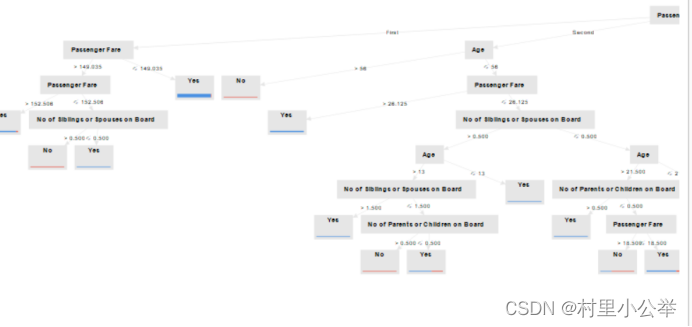
根据决策树,我们树的广度提高了,深度减少了
将参数改为accuracy
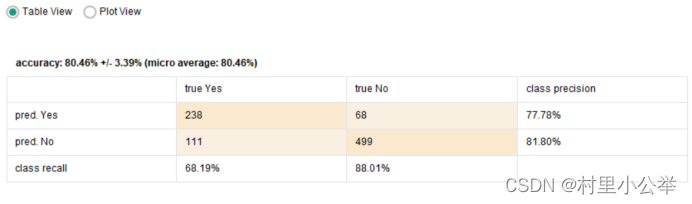
对于Yes的预测准确率下降
对于No的预测准确率上升
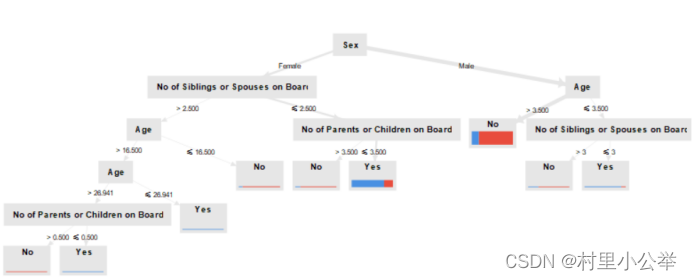
决策树层层递进,一目了然。
版权归原作者 村里小公举 所有, 如有侵权,请联系我们删除。