
一、Text2SQL概述
Text-to-SQL(或者Text2SQL),顾名思义就是把文本转化为SQL语言,更学术一点的定义是:把数据库领域下的自然语言(Natural Language,NL)问题,转化为在关系型数据库中可以执行的结构化查询语言(Structured Query Language,SQL),因此Text-to-SQL也可以被简写为NL2SQL。· 输入:自然语言问题,比如“查询表t_user的相关信息,结果按id降序排序,只保留前10个数据 ”· 输出:SQL,比如“SELECT * FROM t_user ORDER BY id DESC LIMIT 10”
Text2SQL应用主要是帮助用户减少开发时间,降低开发成本。“打破人与结构化数据之间的壁垒”,即普通用户可以通过自然语言描述完成复杂数据库的查询工作,得到想要的结果。
添加图片注释,不超过 140 字(可选)
二、LLM 应用架构
LangChian 作为一个大语言模型开发框架,是 LLM 应用架构的重要一环。那什么是 LLM 应用架构呢?其实就是指基于语言模型的应用程序设计和开发的架构。
LangChian 可以将 LLM 模型、向量数据库、交互层 Prompt、外部知识、外部工具整合到一起,进而可以自由构建 LLM 应用。

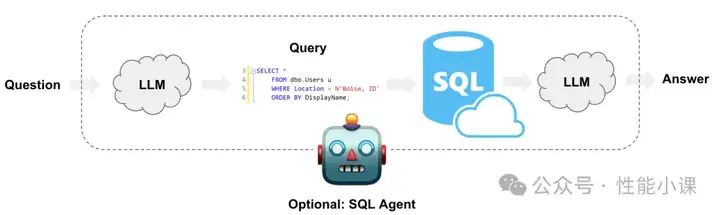
添加图片注释,不超过 140 字(可选)
基于LLM的应用开发基本架构如上图,本文介绍以LangChain + LLM + RDB的方式来实现Text2SQL的实践方案。
三、LangChain 组件

添加图片注释,不超过 140 字(可选)
如上图,LangChain 包含六部分组成,分别为:Models、Prompts、Indexes、Memory、Chains、Agents。
四、Text2SQL实战应用
我们可以用来构建问答系统的一种最常见类型的数据库是SQL数据库。LangChain提供了许多内置的链和代理,它们与SQLAlchemy支持的任何SQL方言兼容(例如,MySQL、PostgreSQL、Oracle SQL、Databricks、SQLite)。它们支持以下用例:●根据自然语言问题生成要运行的查询;●创建能够根据数据库数据回答问题的聊天机器人;●基于用户想要分析的洞察构建自定义仪表板;●......
架构
在高层次上,任何SQL链和代理的步骤包括:
1、 将问题转换为SQL查询:模型将用户输入转换为SQL查询。2、 执行SQL查询:执行SQL查询。3、 回答问题:模型使用查询结果回应用户输入。
添加图片注释,不超过 140 字(可选)
环境部署
安装LangChain组件
pip install --upgrade --quiet langchain langchain-community langchain-openai
安装数据库环境下面的例子将使用SQLite连接与Chinook数据库。请按照以下安装步骤在同一目录下创建Chinook.db:●将此文件保存为Chinook_Sqlite.sql●运行sqlite3 Chinook.db●运行.read Chinook_Sqlite.sql●测试SELECT * FROM Artist LIMIT 10;现在,Chinhook.db已经在我们的目录中,我们可以使用由SQLAlchemy驱动的SQLDatabase类与之交互:
from langchain_community.utilities import SQLDatabase db = SQLDatabase.from_uri("sqlite:///Chinook.db") print(db.dialect) print(db.get_usable_table_names()) db.run("SELECT * FROM Artist LIMIT 10;")
数据准备
案例使用SQLite 和示例Chinook 数据库,用户可按照https://database.guide/2-sample-databases-sqlite/ 上的说明进行设置。Chinook表示一个数字多媒体商店,包含了顾客(Customer)、雇员(Employee)、歌曲(Track)、订单(Invoice)及其相关的表和数据,数据模型如下图所示。

添加图片注释,不超过 140 字(可选)
Chain
让我们来创建一个简单的链,它接收一个问题,将其转化为SQL查询,执行这个查询,并使用结果来回答原始问题。
将问题转换为SQL查询
SQL链或代理的第一步是将用户输入转换成SQL查询。LangChain内置了一个用于此目的的链:create_sql_query_chain。
from langchain.chains import create_sql_query_chain from langchain_community.utilities.sql_database import SQLDatabase # 但问封装的大模型调用接口 from langchain_community.llms.dquestion import DQuestion db = SQLDatabase.from_uri("sqlite:///Chinook.db") # from langchain_openai import ChatOpenAI # llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0) # 调用但问封装的大模型对象 llm = DQuestion(temperature=0) chain = create_sql_query_chain(llm, db) response = chain.invoke({"question": "有多少名员工?"}) print(response)
可以直接执行生成的sql语句,验证正确性
result = db.run(response) print(result)
查看完整的提示词
chain.get_prompts()[0].pretty_print()
执行SQL查询
现在我们已经生成了一个SQL查询,我们想要执行它。这是创建SQL链中最危险的部分。仔细考虑是否适合在您的数据上运行自动化查询。尽可能最小化数据库连接权限。考虑在查询执行之前添加一个人工审批步骤到您的链中(见下文)。
我们可以使用QuerySQLDatabaseTool工具轻松地将查询执行添加到我们的链中:
from langchain.chains import create_sql_query_chain from langchain_community.tools.sql_database.tool import QuerySQLDataBaseTool # 但问封装的大模型调用接口 from langchain_community.llms.dquestion import DQuestion from langchain_community.utilities.sql_database import SQLDatabase db = SQLDatabase.from_uri("sqlite:///Chinook.db") # 调用但问封装的大模型对象 llm = DQuestion(temperature=0) generate_query = create_sql_query_chain(llm, db) execute_query = QuerySQLDataBaseTool(db=db) chain = generate_query | execute_query result = chain.invoke({"question": "有多少名员工?"}) print(result)
直接回答问题
既然已经有了自动生成和执行查询的方法,我们只需要将原始问题和SQL查询结果结合起来生成最终答案。我们可以通过再次将问题和结果传递给大型语言模型(LLM)来实现这一点:
from operator import itemgetter from langchain.chains import create_sql_query_chain from langchain_community.llms.dquestion import DQuestion from langchain_community.tools.sql_database.tool import QuerySQLDataBaseTool from langchain_community.utilities.sql_database import SQLDatabase from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate from langchain_core.runnables import RunnablePassthrough answer_prompt = PromptTemplate.from_template( """Given the following user question, corresponding SQL query, and SQL result, answer the user question. Question: {question} SQL Query: {query} SQL Result: {result} Answer: """ ) db = SQLDatabase.from_uri("sqlite:///Chinook.db") # 调用但问封装的大模型对象 llm = DQuestion(temperature=0) generate_query = create_sql_query_chain(llm, db) execute_query = QuerySQLDataBaseTool(db=db) answer = answer_prompt | llm | StrOutputParser() chain = ( RunnablePassthrough.assign(query=generate_query).assign( result=itemgetter("query") | execute_query ) | answer ) response = chain.invoke({"question": "有多少名员工?"}) print(response)
Agents
LangChain 提供了一个 SQL Agent,它提供了一种更灵活的方式来与 SQL 数据库交互。使用 SQL Agent 的主要优势包括:
●它可以根据数据库的模式(schema)以及数据库的内容(例如描述特定表)来回答问题。●它可以通过运行生成的查询、捕获追踪信息(traceback)并正确地重新生成查询来从错误中恢复。●它可以回答需要多个相关查询的问题。●它通过只考虑相关表的模式来节省tokens。为了初始化代理,我们使用 create_sql_agent 函数。这个代理包含了 SQLDatabaseToolkit,它包含了以下工具:●创建和执行查询●检查查询语法●检索表描述●更多功能...这些工具使得与数据库的交互更加高效和智能,同时也提高了处理复杂查询和错误恢复的能力。 我们将使用一个 OpenAI 的聊天模型和一个名为 "openai-tools" 的agent,这个agent将使用 OpenAI 的函数调用 API 来驱动代理的工具选择和调用。
示例
agent首先会选择哪些表格是相关的,然后将这些表格的模式(schema)以及一些示例行添加到提示(prompt)中。
from dotenv import load_dotenv from langchain_community.agent_toolkits import create_sql_agent from langchain_community.utilities.sql_database import SQLDatabase from text2sql import DQuestionChat load_dotenv() # from langchain_openai import ChatOpenAI llm = DQuestionChat(temperature=0) db = SQLDatabase.from_uri("sqlite:///Chinook.db") agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True) agent_executor.invoke({"input": "列出每个国家的总销售额。哪个国家的客户消费最多?"})
使用动态的少量样本(few-shot)提示
使用动态的少量样本(few-shot)提示是一种策略,它结合了少量的示例(few-shot)学习和动态生成的提示(prompt),以便在与大型语言模型(如 OpenAI 的 GPT-3)交互时提高效率和准确性。这种方法通常涉及以下几个步骤:1. 少量样本学习(Few-shot Learning):在这种方法中,模型会被提供少量的示例,这些示例展示了如何完成特定的任务。例如,如果你想要模型生成 SQL 查询,你可以提供几个关于如何构建这些查询的示例。2. 动态提示(Dynamic Prompting):在与模型交互时,动态地构建提示,这些提示会根据当前的任务和上下文进行调整。这意味着提示会随着对话的进展而变化,以更好地引导模型生成正确的输出。3. 工具选择和调用(Tool Selection and Invocation):在 "openai-tools" 代理中,模型会根据动态提示来选择最合适的工具(例如,SQL 查询生成器)并调用它来完成任务。这可能涉及到解析用户的输入,确定所需的工具,然后生成相应的输出。4. 相关性判断(Relevance Determination):代理会评估哪些数据库表格与用户的问题最相关,并据此调整提示,确保模型能够专注于生成最有用的信息。5. 模式和样本行添加(Adding Schema and Sample Rows):在构建提示时,代理会将相关表格的模式和一些示例行添加到提示中,这样模型就可以理解数据的结构和内容,从而生成更准确的查询。这种方法的优势在于,它允许模型在有限的信息下快速适应新任务,同时通过动态调整提示来提高生成内容的相关性和准确性。这对于需要处理复杂查询和数据库操作的场景特别有用。
处理高基数列
为了筛选包含专有名词(如地址、歌曲名或艺术家)的列,我们首先需要双重检查拼写,以便正确筛选数据。我们可以通过创建一个包含数据库中所有不同专有名词的向量存储库来实现这一点。然后,每当用户在问题中包含一个专有名词时,代理就可以查询这个向量存储库,以找到那个词的正确拼写。这样,代理可以在构建目标查询之前确保理解用户所指的实体。高基数列(High-cardinality columns)通常指的是那些具有大量唯一值的数据库列。在处理这类列时,可能需要采取一些策略来优化查询性能,因为高基数列可能导致查询效率降低,尤其是在执行聚合操作或需要对这些列进行索引时。处理高基数列的方法可能包括:1. 索引优化:虽然高基数列通常不适合建立索引,但在某些情况下,如果列的值分布不均匀,可以考虑对列的一部分值建立索引。
列拆分:如果列的值可以进一步细分为更小的类别,可以考虑将列拆分为多个列,每个列包含较少的唯一值。3. 数据规范化:通过规范化数据,例如使用哈希函数或编码技术,可以将高基数列转换为具有较低基数的列。
使用近似算法:在某些情况下,可以使用近似算法来处理高基数列,以减少计算复杂度。5. 避免在WHERE子句中使用:如果可能,避免在WHERE子句中直接使用高基数列进行过滤,因为这可能导致全表扫描。
使用位图索引:对于某些数据库系统,位图索引可以有效地处理高基数列,尤其是在进行范围查询时。在实际应用中,处理高基数列的具体策略取决于数据库的设计、查询模式以及性能要求。
版权归原作者 但问智能 所有, 如有侵权,请联系我们删除。