
一文通吃:从 ZooKeeper 一致性,Leader选举讲到 ZAB 协议与 PAXOS 算法(上)
目录
一、ZooKeeper集群保证数据一致性
(一)一致性
(二)zookeeper保证数据一致性的协议
二、Zookeeper集群Leader选举
(一)ZooKeeper集群中三种类型的节点
(二)ZAB 中的节点有四种状态
(三)Leader选举过程
三、ZAB协议
(一)ZAB 协议 ZXID 是如何生成的
(二)ZAB协议——崩溃恢复模式
(三)ZAB协议——消息广播模式
四、Paxos算法
(一)关于ZAB协议中Leader的单点问题
(二)Paxos是什么
(三)问题背景
(四)相关概念
(五)Paxos算法处理过程
(六)总结:Paxos算法
本文将从ZooKeeper集群如何保证一致性,讲到zookeeper保证数据一致性的协议,然后展开讲Zookeeper集群Leader选举,包括集群三种节点的类型,ZAB协议中节点的四种状态,以及两种情况下Leader选举的过程。然后会详细展开讲解ZAB协议,包括ZAB协议中ZXID的结构,ZAB协议的两个重点,崩溃恢复模式和消息广播模式。然后会通过一个例子来说明ZAB协议中Leader的单点问题,进而引出Paxos算法。文章会分为上下两个篇章,本文为第一部分。
ZooKeeper集群保证数据一致性
首先我们先来了解一下,关于一致性问题。
一致性
我们用集群是为了提高整个系统的可用性,就是即使少数节点挂掉的话,整个集群还是可以去提供服务的。好,zookeeper集群每一个节点上面,它存储的数据都是全量的数据,也就是它们之间,每一台上面存储的数据都是同一份数据,而我们前面也提到,集群中它每个节点都可以去提供读取服务,所以这样的话,就得保证多个节点之间,它们的数据是一致的,才不会出现连接不同节点读取到不同的值是吧,也就是我们需要去保证集群节点间数据的一致性。那么接下来我们就来看一下,zookeeper集群是如何去做到这一点的,就是如何去做节点间数据的同步
zookeeper保证数据一致性的协议
而在我们的zookeeper中保证数据一致性用的是ZAB协议。通过这个协议来进行ZooKeeper集群间的数据同步,保证数据的一致性。
我们先来简单看一下zab协议是工作流程(图):
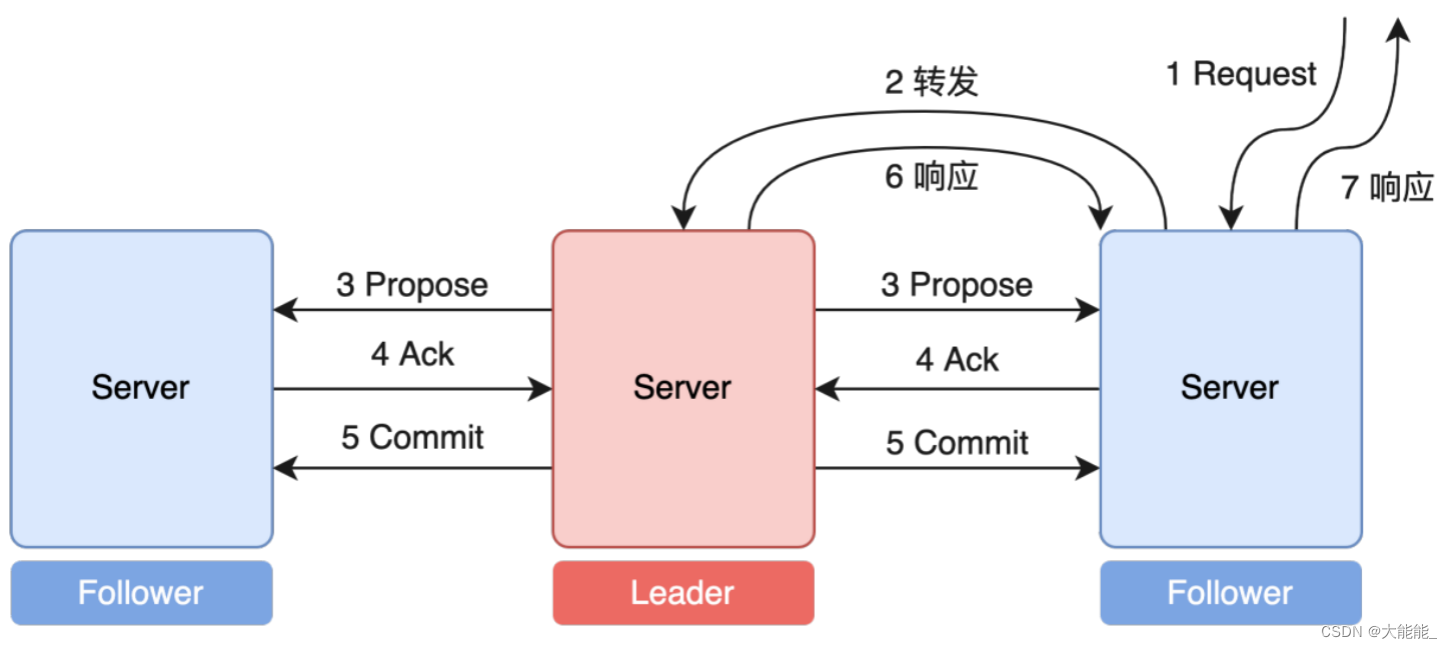
ZooKeeper写数据的机制是客户端把写请求发送到leader节点上,如果发送的是follower节点,follower节点会把写请求转发到leader节点,leader节点会把数据通过proposal请求发送到所有节点,包括自己,所有到节点接受到数据以后都会写到自己到本地磁盘上面,写好了以后会发送一个ack请求给leader,leader只要接受到过半的节点发送ack响应回来,就会发送commit消息给各个节点,各个节点就会把消息放入到内存中,放内存是为了保证高性能,该消息就会用户可见了。
那这个时候,若ZooKeeper要想保证数据一致性,就需考虑如下两个情况
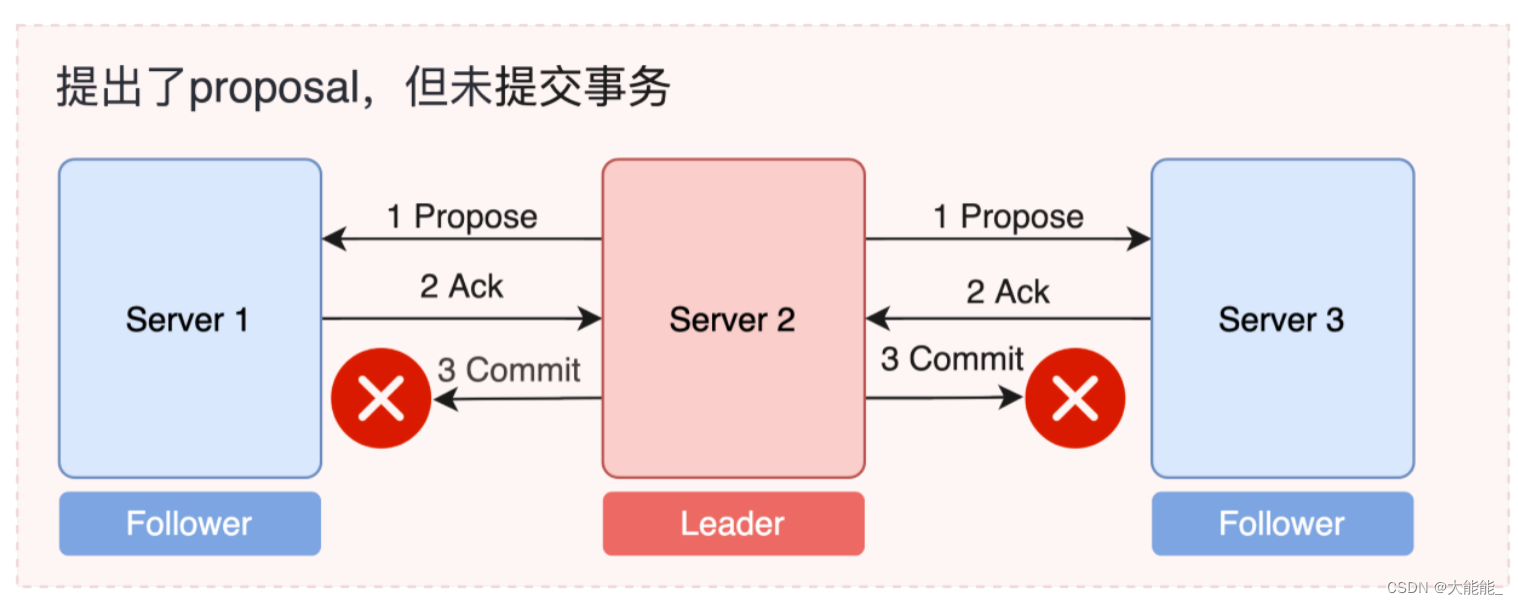
- 情况一:leader执行commit了,还没来得及给follower发送commit的时候,leader宕机了,这个时候如何保证消息一致性?
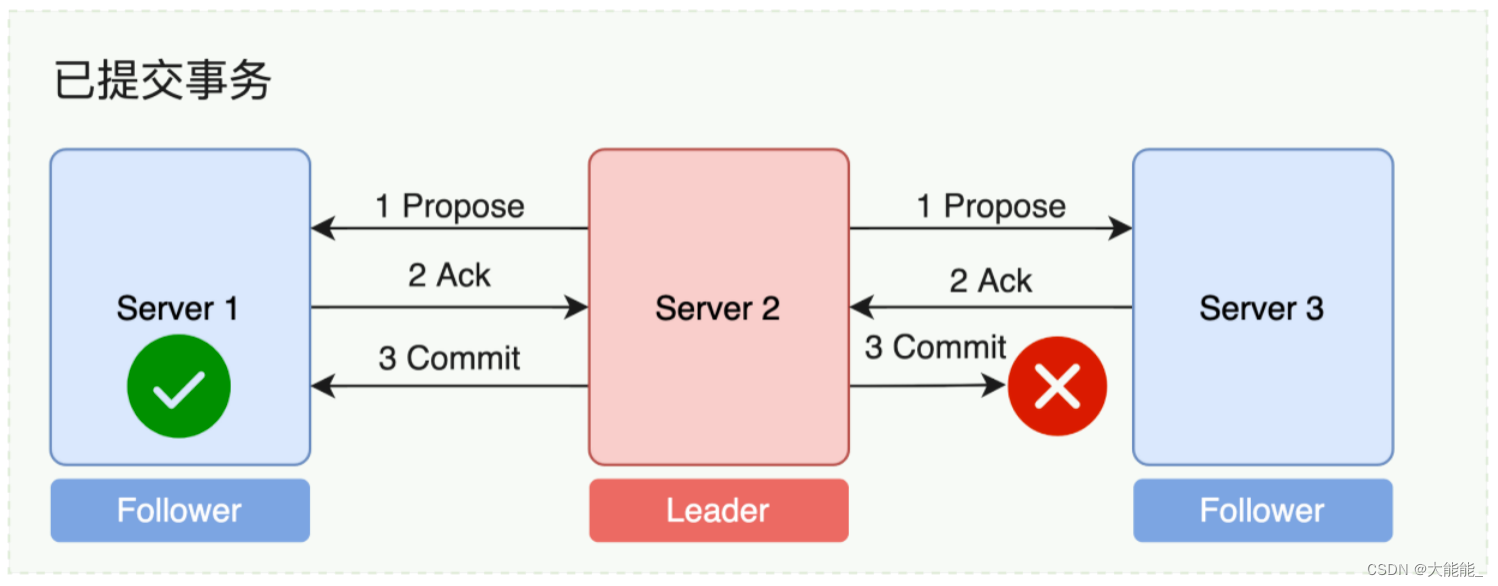
- 情况二:leader的事务性请求已经在部分节点应用了,这个时候leader挂掉了,如何保证消息一致性?
如果是Leader故障,事务型请求未提交的情况,也就是只在Leader服务器上提出但没有提交的操作的操作需要丢弃掉。因为实际上它只是完成了第一阶段。
Leader故障,事务型请求已提交的情况,也就是已在Leader服务器上提交的操作最终被所有的服务器节点都提交。等后面讲到ZAB协议,概念就更清晰了,在某个节点提交应用成功,那这个节点的zxid肯定更大,决定它会被选举为新的leader。然后再进行同步。
Zookeeper集群Leader选举
ZooKeeper集群中三种类型的节点
集群在运行过程中,节点发生故障时,这个集群是如何来应对的?
ZooKeeper中三种类型的节点是吧,我们逐个类型来看一下:
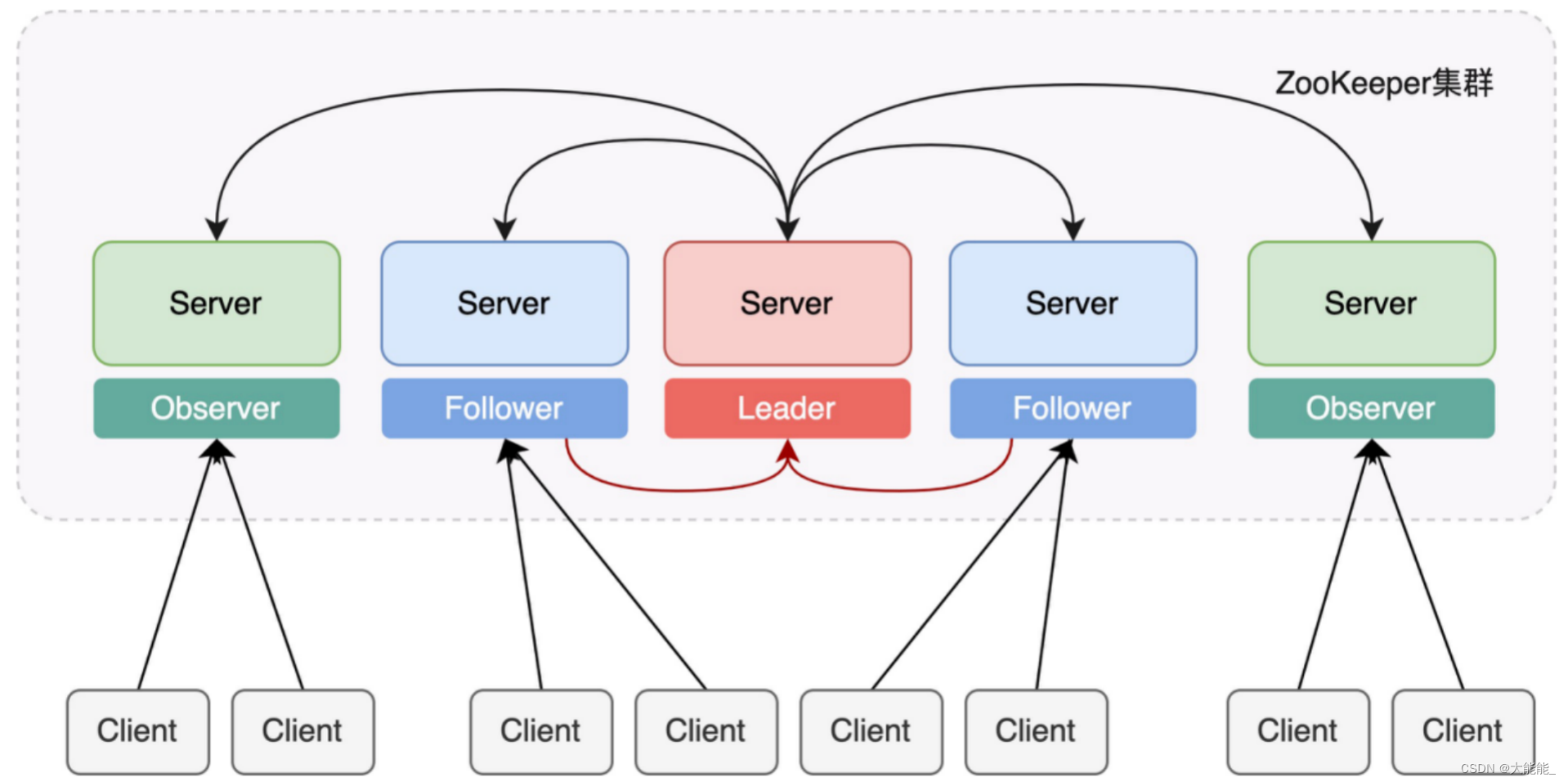
- Observer节点,这种节点它只是为了提升读性能,并不会参与到任何决策过程,所以,就算它挂了,也是不会影响集群的正常运行的。
- Follower节点,如果是少数节点挂了的话,就是没超过半数的话,那也不会影响,那如果故障节点超过半数的话,这个时候就没办法了,需要把节点恢复起来之后才可以运行
- Leader节点,通过前面的学习我们也知道,这个Leader在整个集群中起着至关重要的作用,整个集群的协调工作都是由它来发起的,所以这个时候假如Leader挂掉了,整个集群也没办法正常运行,就不是有没有超过半数的问题了。
所以当Leader节点挂掉之后,就需要尽快从可用的节点中再来选出一个节点来当新的Leader,才能让集群恢复可用。那这里怎么选新的Leader,就是一个需要解决的问题了。我们想一下,可以简单的从剩下的Follower节点随便选一个来当新的领导吗?我们可以想一下这个场景:
Leader故障,事务型请求已提交
,在这个场景中,我们这Follower节点的状态明显是不一样的,所以当时我们也说了,这个场景下,ZooKeeper集群是有机制去保证让这个Server1当上新领导的。这里就涉及到了ZooKeeper集群的Leader选举算法了,这个算法对ZooKeeper集群去保证可用性和数据一致性是非常重要的,那么我们就来详细看一下,这个算法它具体是什么样的一个处理过程。
那么在开始分析算法之前,我们先来看一下集群中节点的几种状态,因为整个选举的过程,会涉及到这几个状态的流转。
ZAB 中的节点有四种状态
- looking:节点处于选举状态
- following:当前节点是跟随者,服从 leader 节点的命令,后面它是会参与投票的
- Obsering:观察状态,同步leader状态,但是不参与投票
- leading:当前节点是 leader,负责协调事务
Leader选举过程
好,接下来我们来看一下Leader的选举过程,那么对于Zookeeper集群来说,当出现以下两种情况的时候,就需要进行Leader选举:
- 集群启动期间Leader选举
- 集群运行期间Leader故障
然后整个Leader选举的过程,就是一个投票的过程,然后当某一个节点,它接收到超过半数节点的选票的话,就可以认为它当选Leader了。但是这里要投给谁,其实还是有讲究的。
那么我们可以想一下比如我们在选村长的时候,一般我们就看谁能力大是吧,谁能力大就投给谁,然后如果能力差不多,可能就会选年纪大一点的,德高望重嘛。好那在ZooKeeper集群选举里面,当一个节点要决定这个选票要投给谁的时候,会根据两个重要的ID来进行判断:
- 首先是看事务ID(zxid),哪个服务器上的事务ID最大,就投给哪个。【对应这个场景:
Leader故障,事务型请求已提交】 - 那么当两个节点事务ID一样的话,就会看节点编号,也就是myid里面存的编号,哪个大投给哪个
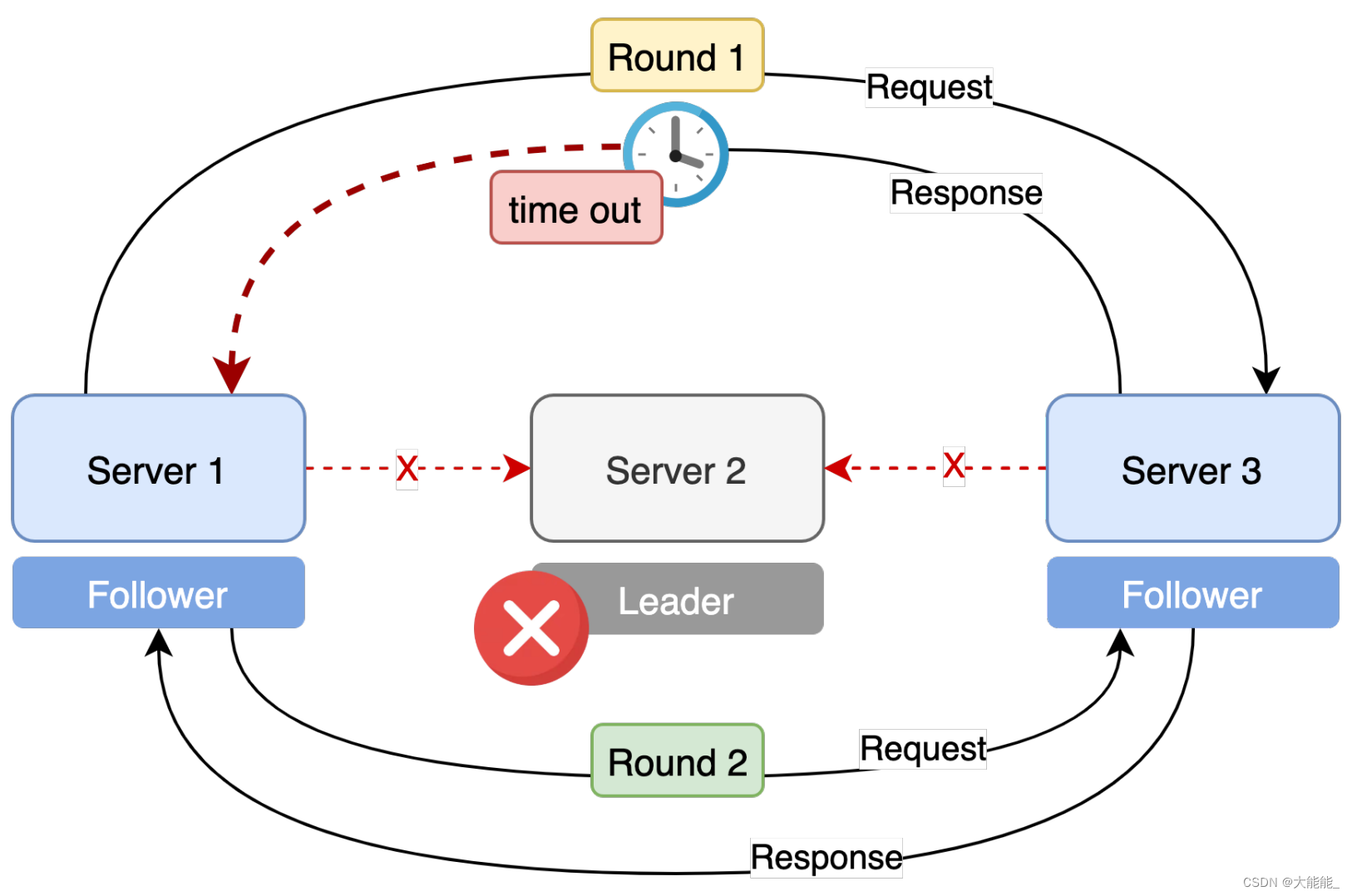
好有了投票标准之后,就可以来开始选举了,但是选举的时候,可能会有不止一轮的投票,同样跟我们选村长一样一般也会有多轮投票,那这种情况下,前一轮的选票,到下一轮的话,就应该变成无效选票了是吧。
而在ZooKeeper里面,它同样有这个轮次的概念,就是每一次投票它其实是有时间限制的【syncLimit:集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。】,如果当前投出去的票,没有收到反馈,那么在等待一段时间后,就当作超时处理,这个时候就可以发起一下轮的投票,诶但是有可能,上一轮的反馈它是因为网络延迟的问题,这个时候才收到,那么因为现在已经是开始了下一轮了,所以这个也只能当做无效选票处理了。
图:投票响应超时则进入下一轮
选举算法
好 有了这些选举的标准和规则之后,就可以来开始选举了,选举算法:
- 首先每个节点均发起选举自己为领导者的投票(自己的投给自己);因为刚开始也不知道哪个节点的事务ID最大,所以就先给自己一票再说,接着就给其它节点发消息来拉票,拉票的时候,像在选举的时候一样,拉票的时候就会说自己能力多牛,那么这里也一样,它会把当前节点上最大的事务ID给带过去
- 其它节点收到拉票请求时,就会比较发起者的事务ID,是否比自己最新的事务ID大,如果比自己的ID大,那好就给它投一票吧,否则就不投给它了。那如果事务ID相等的话,则比较发起者的服务器编号。这一点呢我们前面也说到过,就像选举的时候,先看一下能力谁强,再看一下谁的年纪大。
- 然后经过每一轮的投票之后,就看有没有哪个节点,它获得的票数(含自己的)大于集群的半数,有的话就说明这个节点竞选成功,成为了Leader节点,未超过半数且领导者未选出,则再次发起投票。
集群启动期间Leader选举
我们现在看第一种服务器启动时候对leader选举 我们来看一下这张图

假设一个 Zookeeper 集群中有5台服务器,id从1到5编号,并且它们都是最新启动的,没有历史数据
假设服务器依次启动,我们来分析一下选举过程:
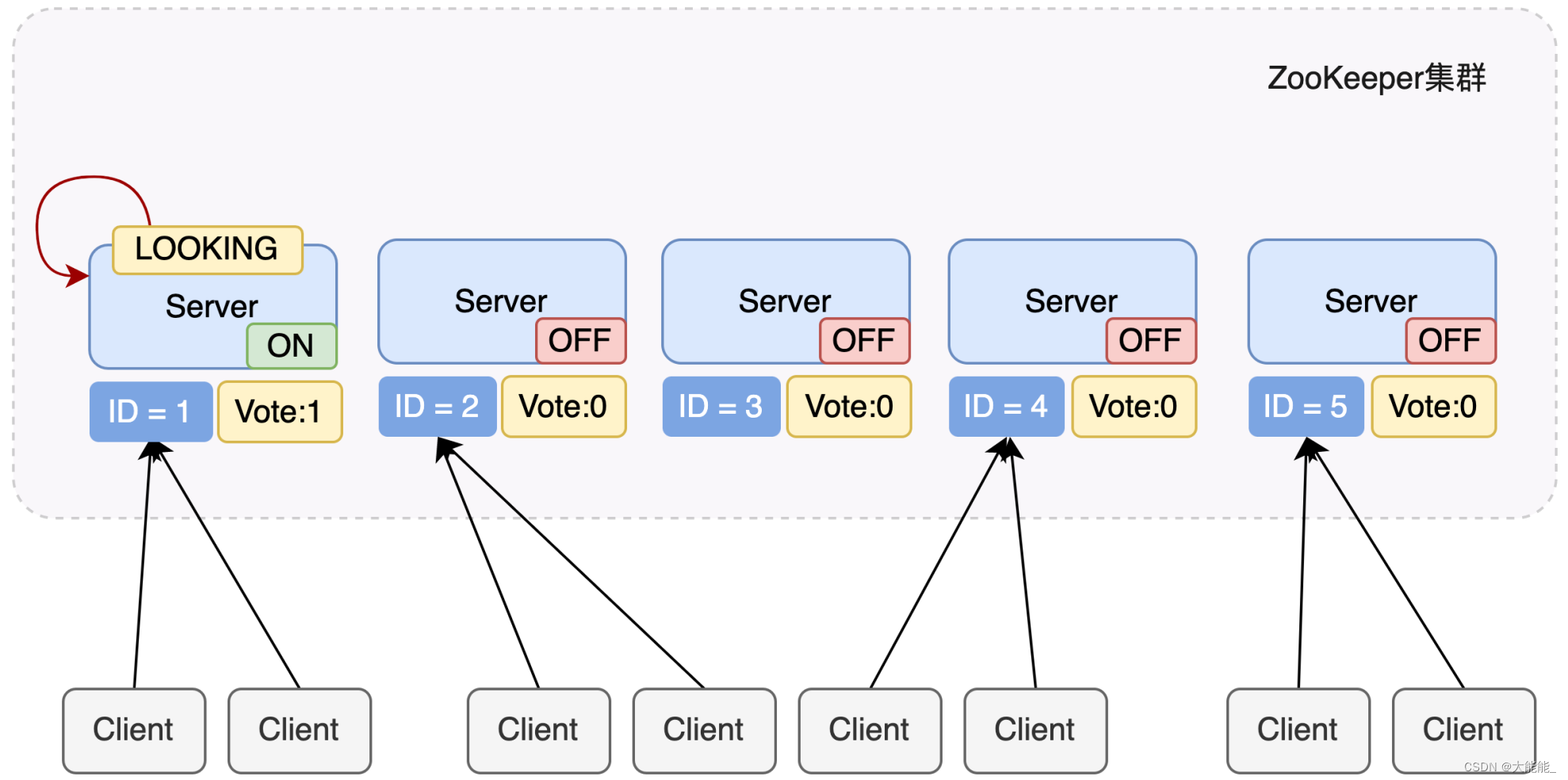
服务器1启动
服务器1启动,发起一次选举,服务器1投自己一票,此时服务器1票数一票,不够半数以上,要大于等于3票,选举无法完成。 所以,这个时候对投票结果:服务器1为1票。
服务器1状态保持为LOOKING。
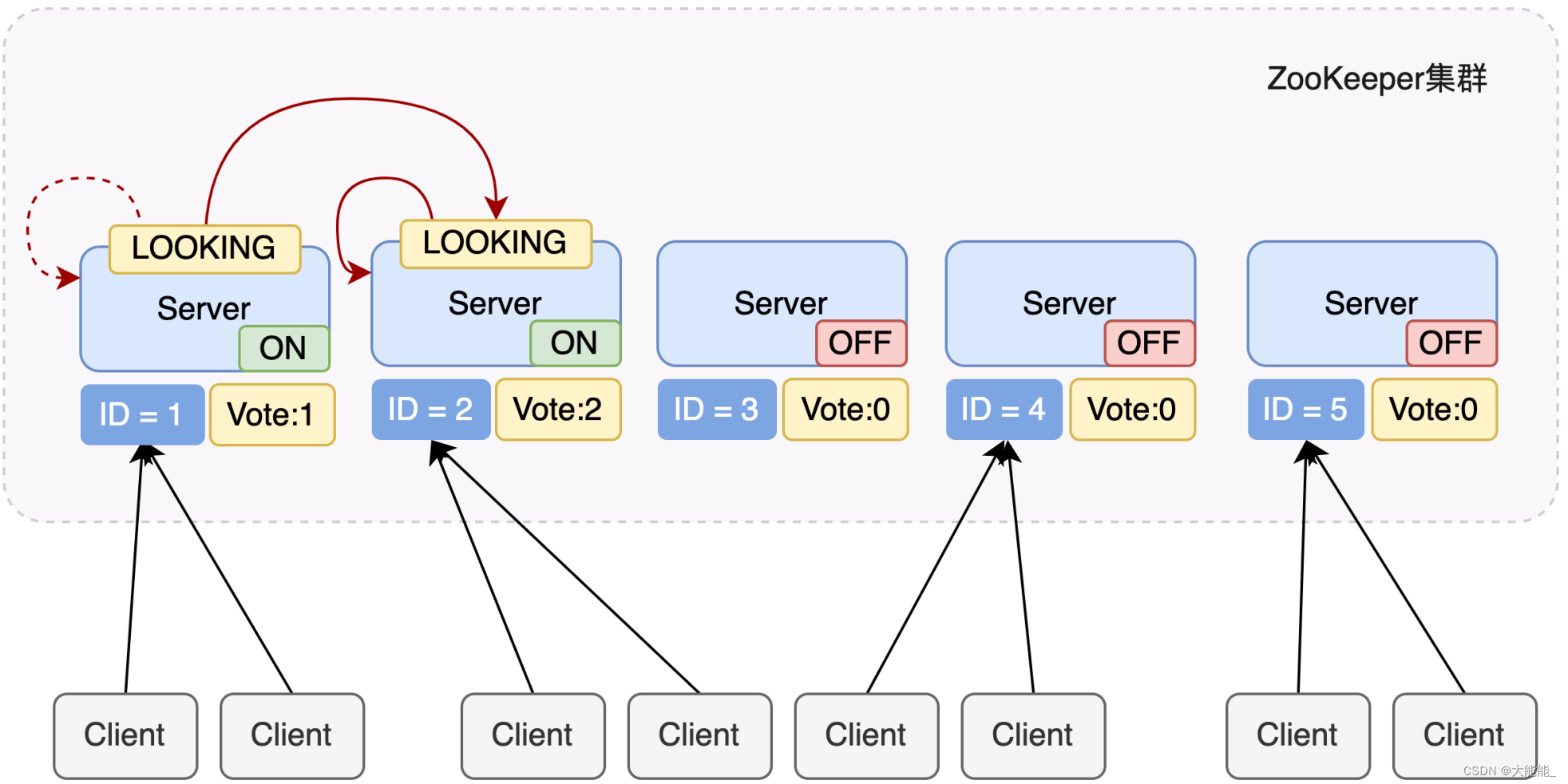
服务器2启动
服务器2启动,也发起一次选举,服务器1和2分别投自己一票,此时服务器1发现服务器2的服务id比自己大,更改选票投给服务器2。 所以投票结果:服务器1为0票,服务器2为2票。
服务器1,2状态保持LOOKING
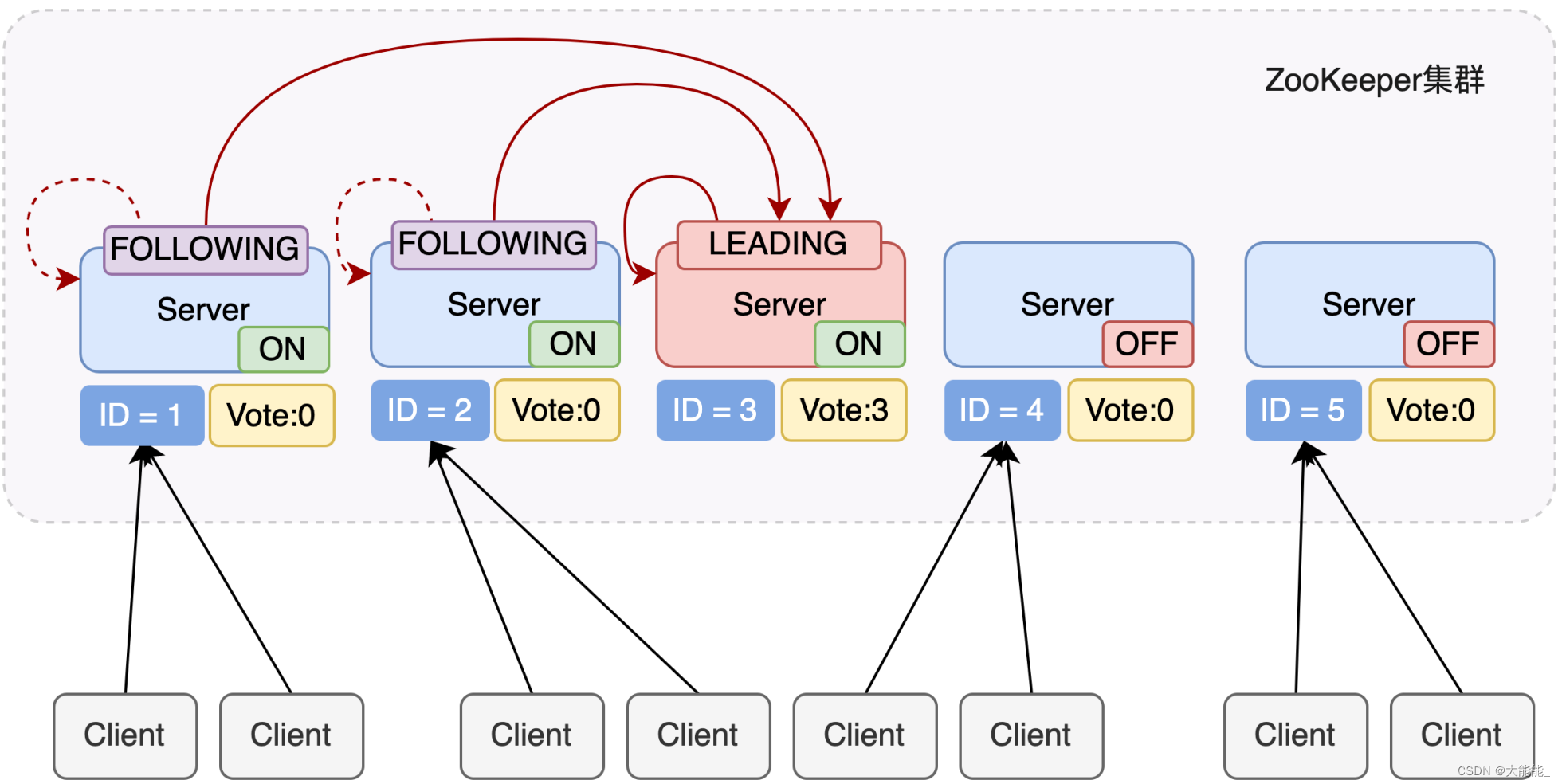
服务器3启动
服务器3也启动了,同时也发起一次选举,服务器1、2、3先投自己一票,然后因为服务器3的服务器id最大,两者更改选票投给为服务器3;
这时候,投票结果为:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。
服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING
服务器4启动
服务器4启动,也加入进来,发起一次选举,此时服务器1,2,3已经不是LOOKING 状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3。
服务器4并更改状态为FOLLOWING。
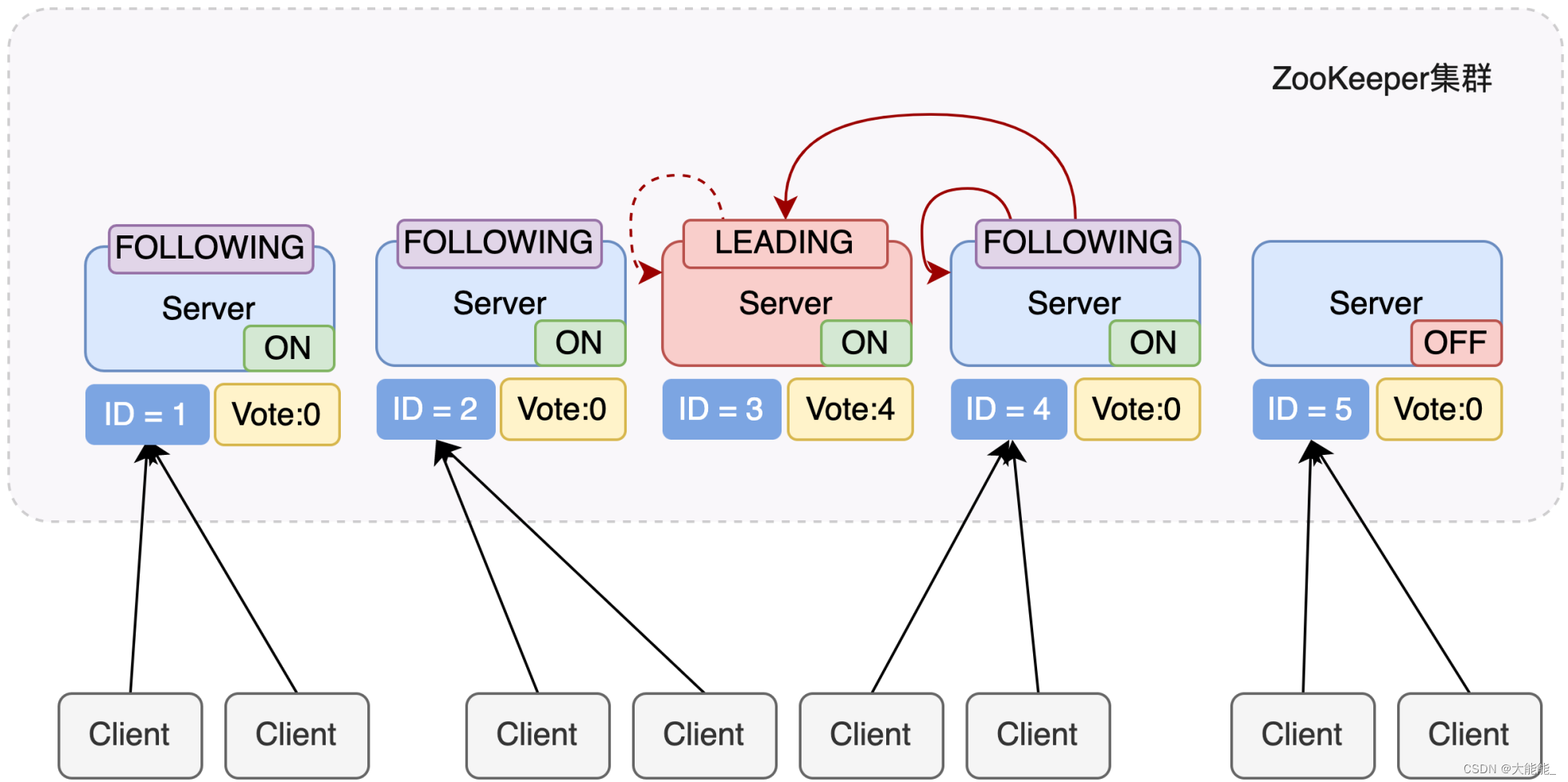
服务器5启动
与服务器4一样投票给3,此时服务器3一共5票,服务器5为0票。
服务器5并更改状态为FOLLOWING。
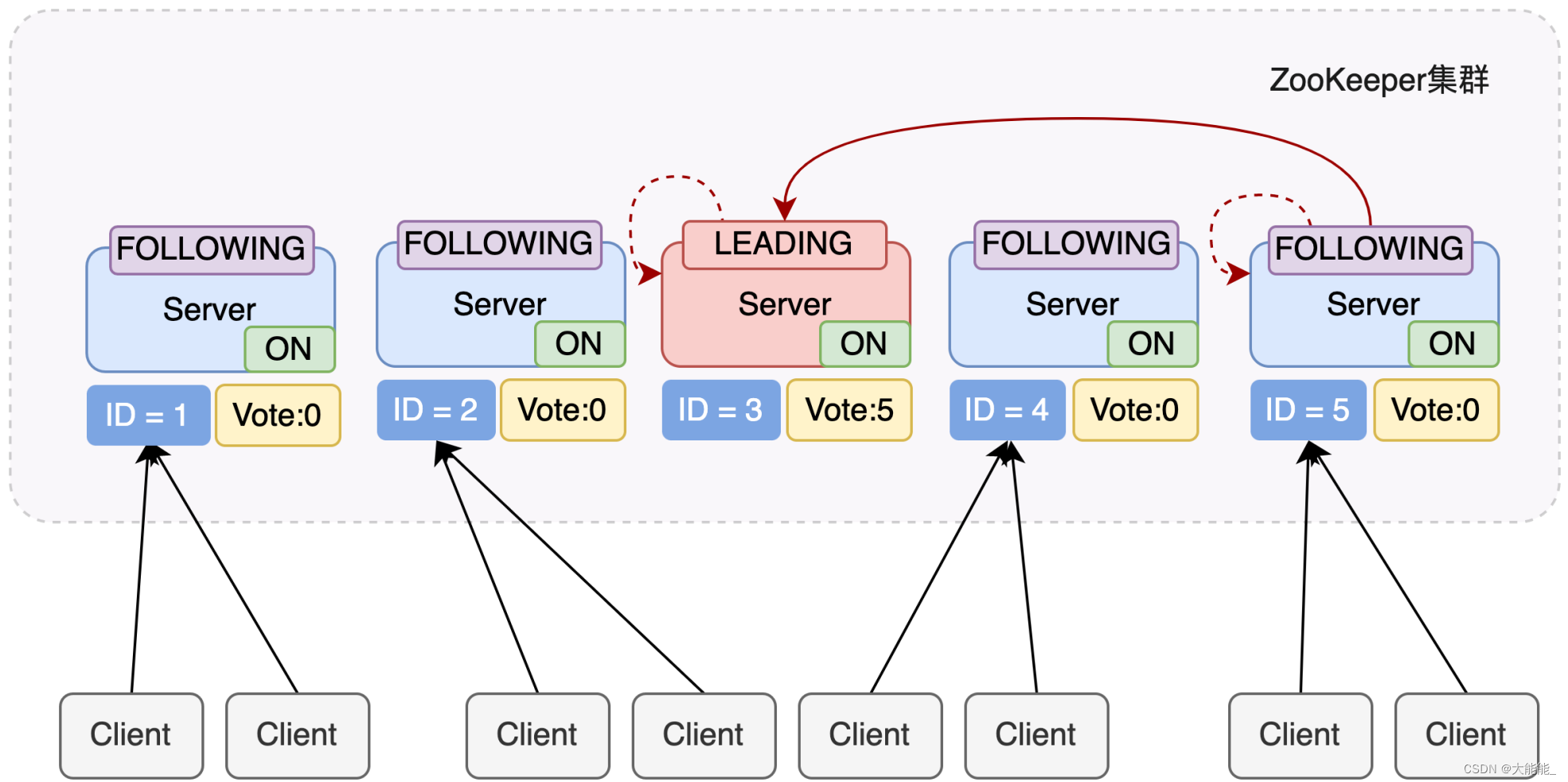
最终的结果:
服务器3是 Leader,状态为 LEADING;其余服务器是 Follower,状态为 FOLLOWING。
好,这就是服务器初始化启动时候的选举过程。
服务器运行期间 Leader 故障
那么,我们继续来看一下第二种选举过程,服务器运行期间 Leader 故障。
我们来看一下这个场景:
在 Zookeeper运行期间 Leader 和 follower 各司其职,当有follower 服务器宕机或加入不会影响 Leader,但是一旦 Leader 服务器挂了,那么整个 Zookeeper 集群将暂停对外服务,会触发新一轮的选举。
初始状态下服务器3当选为Leader,假设现在服务器3故障宕机了,此时每个服务器上zxid可能都不一样,server1为10,server2为12,server4为10,server5为10
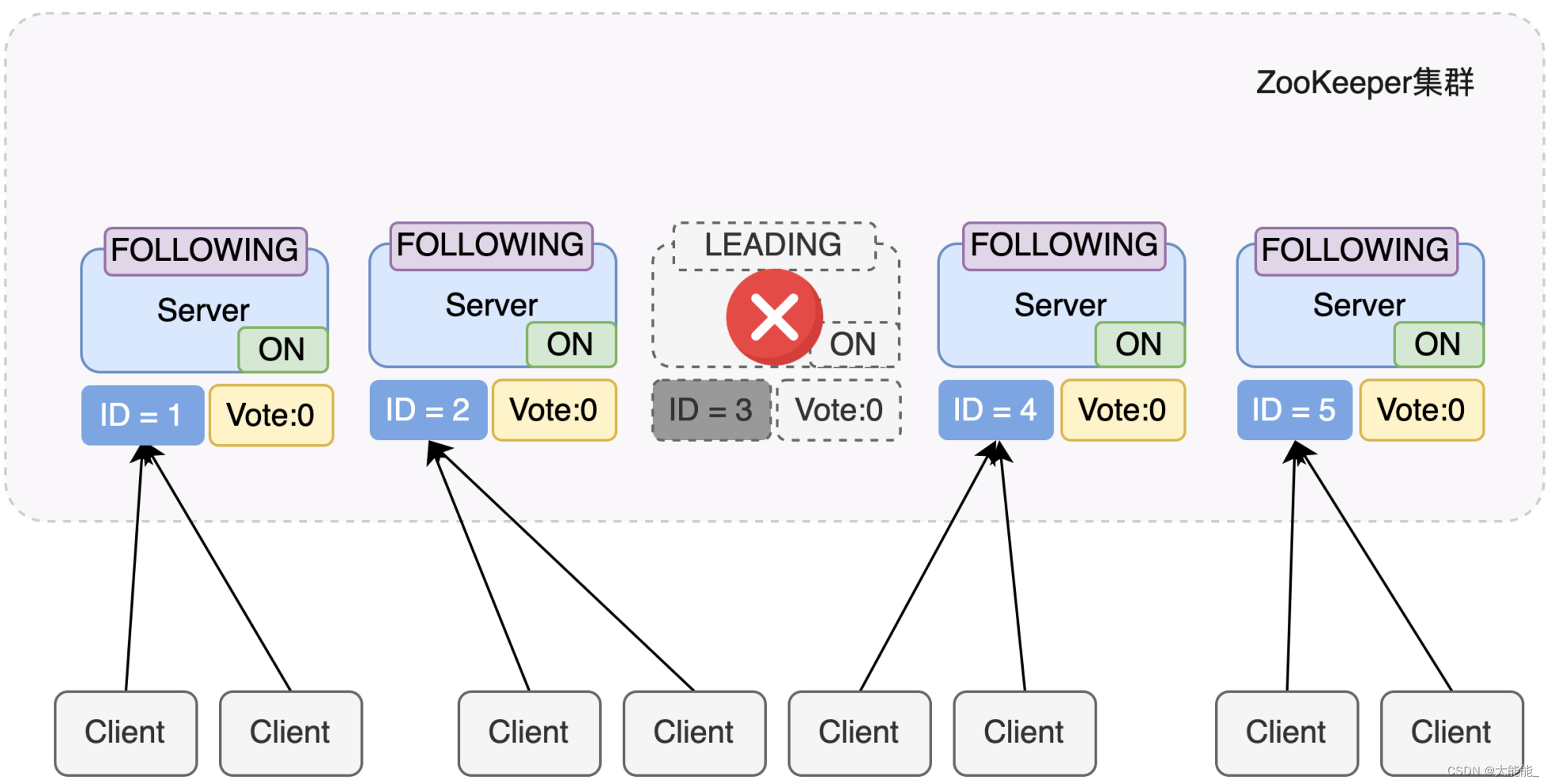
运行期选举
运行期选举与初始状态投票过程基本类似,大致可以分为以下几个步骤:
- 状态变更。Leader 故障后,剩下的follower节点因为跟Leader联系不上了,这个时候它会将自己的服务器状态变更为LOOKING,然后开始进入Leader选举过程。
- 每个Server会发出投票。
- 接收来自各个服务器的投票,如果其它服务器的数据比自己的新会改投票。
- 处理和统计投票,每一轮投票结束后都会统计投票,超过半数即可当选。
- 改变服务器的状态,宣布当选
好,这里我们以这张图来说明比较好容易理解点:
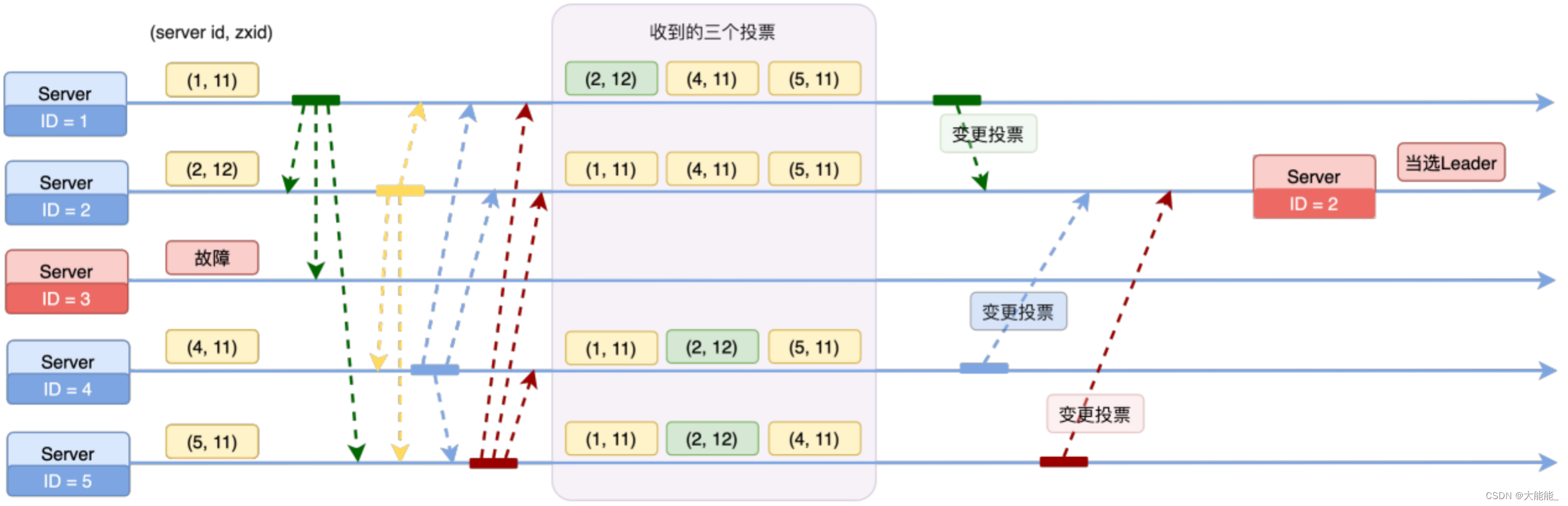
1)第一次投票,每台机器都会将票投给自己。
2)接着每台机器都会将自己的投票发给其它机器,如果发现其它机器的zxid比自己大,那么就需要改投票重新投一次。比如server1 收到了三张票,发现server2的xzid为102,pk一下发现自己输了,后面果断改投票选server2为老大,同理,因为从图中很明显看到服务器2点xzxid是最大的,所以最后是服务器2当选leader服务器。
小结
简单来将,通常哪台机器服务器上的数据越新,那么越有可能成为leader,原因也很简单,数据越新,那么它的zxid也就越大,也就越能够保证数据的恢复。如果集群中有几个相同的最大的zxid,那么服务器id较大的服务器成为leader。
好,那么关于leader选举我们就了解到这里。谢谢大家。
关于ZAB协议以及PAXOS算法我们会在下一篇文章进行介绍,敬请期待。
更多知识:
慕课网实战课程:2022全新版!Java分布式架构设计与开发实战:https://coding.imooc.com/class/539.html
版权归原作者 大能能_ 所有, 如有侵权,请联系我们删除。