
使用目的
为什么使用需要分库分表,在数据量比较小的时候,是不需要考虑使用分库分表的,一般而言,使用单库和单表就ok了,但是使用Mysql,当数据量达到400w~500w的查询时,查询速度便慢了很多了,因此就需要分库和分表了
在《阿里开发手册嵩山版》中有写到:
而分库分表中,有垂直分片和水平分片之说,可以简单理解,垂直分片,就是将一个大表,拆分成多个小表。例如将一张大的订单表分为多个表;水平分表,就是同个表,拆分成多个一样的表进行存储。例如可以按照时间进行拆分,也可以根据id取余进行拆分。
而分库分表中比较有名气的便是ShardingSphere,这里便开始介绍ShardingSphere
Apache ShardingSphere 由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的基于数据库作为存储节点的增量功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
官网如下:https://shardingsphere.apache.org/document/5.1.2/cn/overview/
详细的便不多说,自己可以参考官网阅读。下面开始实战。
单库水平分表实战场景
我们主要分为2种情况
- 全新项目
- 运行中项目的整合 - Mybatis版本- Mybatisplus版本
1、全新项目+单数据源
如果是全新项目,则可以考虑直接整合shardingjdbc即可,不需要考虑使用多数据源。因为shardingjdbc有很多不支持项,例如一些复杂函数等等。但是因为我们是重头开始开发,所以只要面对不支持项的时候,去改我们的SQL即可。但是如果是运行了一段时间的项目,就没那么容易,可能有大量的不支持项,会需要修改很多的SQL语句等。
整合步骤
1、springboot项目创建
这一步就省略了…
主要是包含以下依赖。
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
2、整合mybatis、shardingjdbc
创建表
假设我们创建订单表,但是我们需要分表,我们以4个表为例,那么就分为 order_info_0,order_info_1,order_info_2,order_info_3
CREATETABLE`order_info_0`(`id`bigintNOTNULLCOMMENT'id',`name`varchar(32)DEFAULTNULLCOMMENT'名称',`num`intDEFAULTNULL,`create_time`datetimeDEFAULTNULL,PRIMARYKEY(`id`))ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;CREATETABLE`order_info_1`(`id`bigintNOTNULLCOMMENT'id',`name`varchar(32)DEFAULTNULLCOMMENT'名称',`num`intDEFAULTNULL,`create_time`datetimeDEFAULTNULL,PRIMARYKEY(`id`))ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;CREATETABLE`order_info_2`(`id`bigintNOTNULLCOMMENT'id',`name`varchar(32)DEFAULTNULLCOMMENT'名称',`num`intDEFAULTNULL,`create_time`datetimeDEFAULTNULL,PRIMARYKEY(`id`))ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;CREATETABLE`order_info_3`(`id`bigintNOTNULLCOMMENT'id',`name`varchar(32)DEFAULTNULLCOMMENT'名称',`num`intDEFAULTNULL,`create_time`datetimeDEFAULTNULL,PRIMARYKEY(`id`))ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
引入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!-- Spring Boot Starter for MyBatis --><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.1.4</version></dependency><!-- 需要引入druid ,否则会报错:Caused by: java.lang.ClassNotFoundException: com.alibaba.druid.pool.DruidDataSource--><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.8</version></dependency><!-- <dependency>--><!-- <groupId>com.alibaba</groupId>--><!-- <artifactId>druid</artifactId>--><!-- <version>1.2.8</version>--><!-- </dependency>--><!-- Database Driver --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.19</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>5.1.2</version></dependency>
yaml配置
server:port:11001spring:autoconfigure:# 排除druid 否则报错exclude: com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure
# mybatis配置# datasource:# url: jdbc:mysql://localhost:3306/table_sharding?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai# username: root# password: 123456# driver-class-name: com.mysql.jdbc.Drivershardingsphere:# 开启sql打印enabled:trueprops:# 是否显示sqlsql-show:truedatasource:# 数据源名称names: sharding
# 数据源实例: 如果这里还有mastersharding:type: com.alibaba.druid.pool.DruidDataSource
driver-class: com.mysql.cj.jdbc.Driver
# 使用Druid,不能使用jdbc-url 得使用urlurl: jdbc:mysql://localhost:3306/table_sharding?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghaiusername: root
password:123456# 分片规则rules:sharding:# 对表进行分片tables:# 逻辑表名,代表的是需要分表的名称order_info:# 实际节点:这里代表的是 会使用sharding数据源中 order_info表 细分为0~3 4个表actual-data-nodes: sharding.order_info_$->{0..3}# 表策略table-strategy:# 标准表策略standard:# 分表的列sharding-column: id
# 分片算法名称: 来源于下面的sharding-algorithmssharding-algorithm-name: alg_hash_mod
key-generate-strategy:# 主键生成策略column: id # 主键列key-generator-name: snowflake # 策略算法名称(推荐使用雪花算法)# 主键生成规则,SNOWFLAKE 雪花算法key-generators:snowflake:type: SNOWFLAKE
# 分片算法sharding-algorithms:alg_hash_mod:# 类型:hash取余 类似于获取一个列的数,假如是3 3%4=0 数据就会进入第0个表type: HASH_MOD
# 分片的数量,因为是4个表,所以是4props:sharding-count:4mybatis:# 映射文件 配置之后,mybatis会去扫描该路径下的xml文件,才会与Mapper对应起来mapper-locations: classpath:mapper/*.xml# 别名类(实体类)所在包type-aliases-package: com.walker.simplesharding.entity
configuration:# 驼峰转换map-underscore-to-camel-case:true
3、创建测试类、测试方法
包含Entity、Mapper、Mapper.xml等
packagecom.walker.simplesharding.entity;importlombok.Data;importjava.util.Date;/**
* @Author: WalkerShen
* @DATE: 2022/3/29
* @Description:
**/@DatapublicclassOrderInfo{privateLong id;privateString name;privateInteger num;privateDate createTime;}
packagecom.walker.simplesharding.mapper;importcom.walker.simplesharding.entity.OrderInfo;importorg.apache.ibatis.annotations.Mapper;importorg.apache.ibatis.annotations.Param;importjava.util.List;/**
* @Author: WalkerShen
* @DATE: 2022/3/29
* @Description: 创建mapper接口,
**///使用@Mapper,注入容器@MapperpublicinterfaceOrderInfoMapper{List<OrderInfo>list();voidsave(OrderInfo orderInfo);voiddeleteById(@Param("id")Long id);voidupdateNameById(@Param("id")Long id,@Param("name")String name);OrderInfogetById(@Param("id")Long id);List<OrderInfo>limitOrder();List<OrderInfo>limitOrderWithOffset();}
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE mapper PUBLIC"-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><!--namespace:命名空间,用来映射对应的mapper
相当于将mapper和mapper.xml连接起来,这一步很重要--><mapper namespace="com.walker.simplesharding.mapper.OrderInfoMapper"><insert id="save">
insert into order_info(`name`,num,create_time)values(#{name},#{num},#{createTime})</insert><update id="updateNameById">
update order_info set name=#{name}
where id=#{id}</update><delete id="deleteById">
delete from order_info where id=#{id}</delete><select id="list" resultType="com.walker.simplesharding.entity.OrderInfo">
select * from order_info
</select><select id="getById" resultType="com.walker.simplesharding.entity.OrderInfo">
select * from order_info
where id=#{id}</select><select id="limitOrder" resultType="com.walker.simplesharding.entity.OrderInfo">
select * from order_info
order by num desc
limit 10</select><select id="limitOrderWithOffset" resultType="com.walker.simplesharding.entity.OrderInfo">
select * from order_info
order by num desc
limit 2,10</select></mapper>
注意:xml需要放在application.yaml配置的路径一致,否则会扫描不到方法的.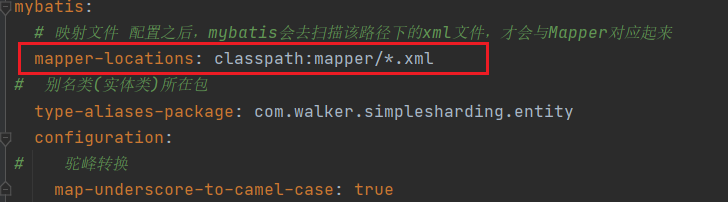
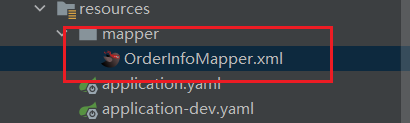
测试方法:
packagecom.walker.simplesharding;importcn.hutool.json.JSON;importcn.hutool.json.JSONUtil;importcom.walker.simplesharding.entity.OrderInfo;importcom.walker.simplesharding.mapper.OrderInfoMapper;importlombok.extern.slf4j.Slf4j;importorg.junit.jupiter.api.Test;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.boot.test.context.SpringBootTest;importjava.util.ArrayList;importjava.util.Date;importjava.util.List;@Slf4j@SpringBootTestclassSimpleShardingApplicationTests{@AutowiredprivateOrderInfoMapper orderInfoMapper;// 增@Testvoidadd(){for(int i =0; i <1000; i++){OrderInfo orderInfo =newOrderInfo();
orderInfo.setName("name"+i);
orderInfo.setCreateTime(newDate());
orderInfo.setNum(i);
orderInfoMapper.save(orderInfo);}}// 删@Testvoiddelete(){Long id=980838688239910912L;
orderInfoMapper.deleteById(id);}// 改@Testvoidupdate(){Long id=980838688269271040L;String name="hello";
orderInfoMapper.updateNameById(id,name);}// 查 列表@Testvoidlist(){List<OrderInfo> list = orderInfoMapper.list();System.out.println(list);}// 查:单个查询@TestvoidgetById(){Long id=980838688269271040L;OrderInfo info=orderInfoMapper.getById(id);System.out.println(info);}@TestvoidlimitOrder(){// 整合pageHelperList<OrderInfo> list = orderInfoMapper.limitOrder();
log.info("返回结果:{}",JSONUtil.toJsonStr(list));}// 分页、排序、跳过数据@TestvoidlimitOrderWithOffset(){// 整合pageHelperList<OrderInfo> list = orderInfoMapper.limitOrderWithOffset();
log.info("返回结果:{}",JSONUtil.toJsonStr(list));}}
4、执行测试方法

如果启动的时候,报该错误,那么就是启动命令太长了。需要更改一下启动方式
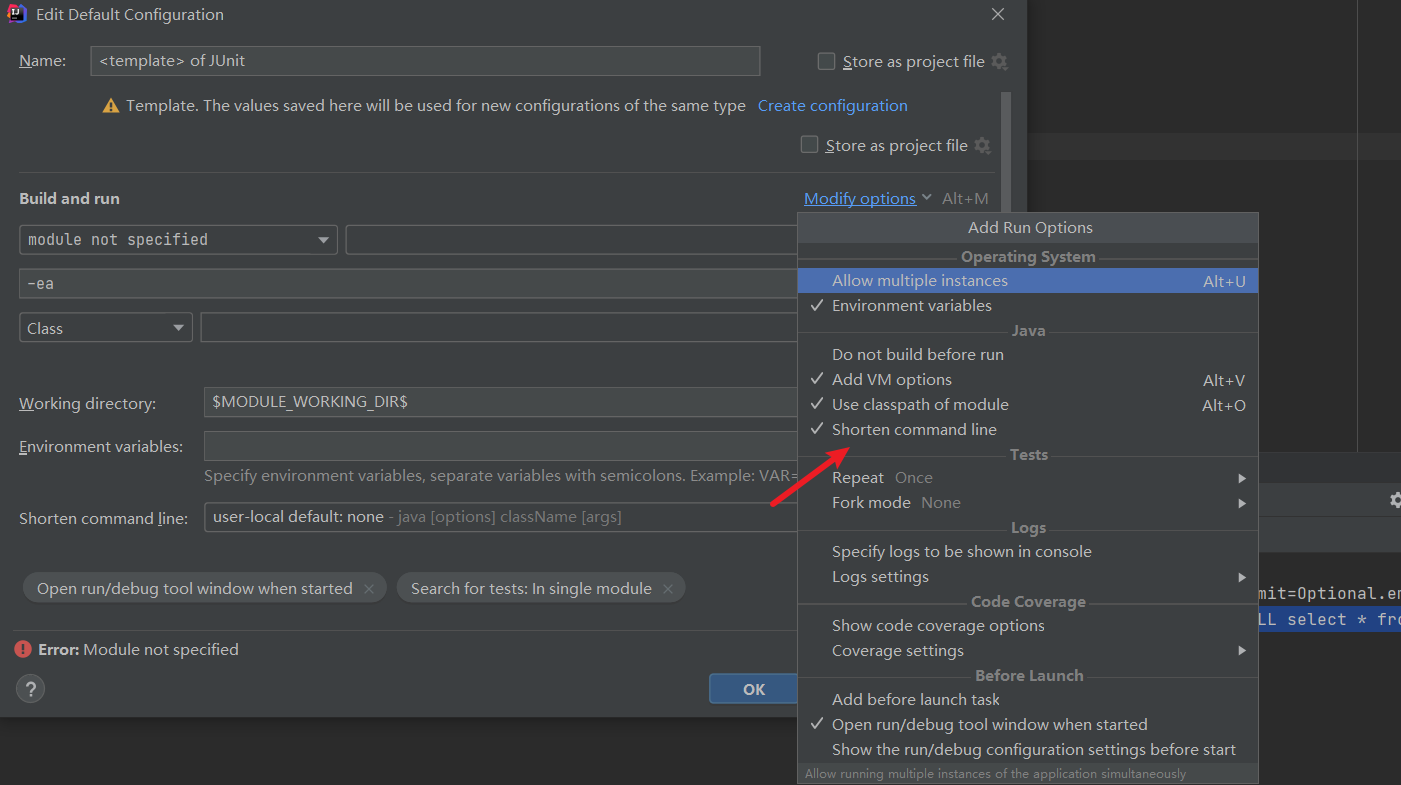
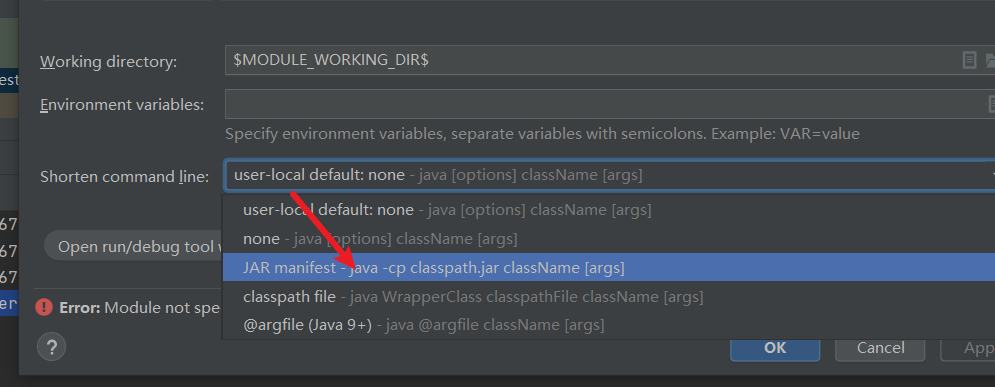
之后保存即可
新增
插入1000条数据,num分别是0~999
可以看到,自动生成雪花id,然后根据id进行取余插入不同的表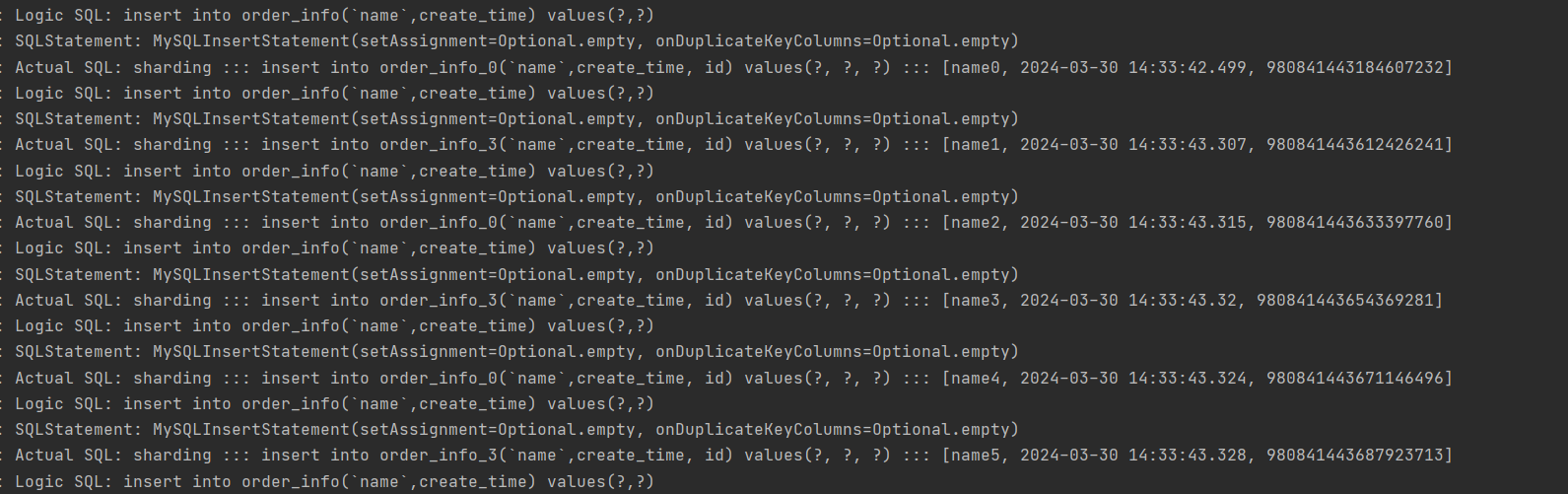
删除
从order_info_3中获取一个id,然后进行删除
可以发现会先使用id进行取余,然后路由到3表中进行删除
修改
同理
查询所有数据
打印日志:会使用union all 将数据全部拼接起来
select*from order_info_0
UNION ALL select*from order_info_1
UNION ALL select*from order_info_2
UNION ALL select*from order_info_3
查询单个
跟修改、删除一样,先路由到指定的表,然后进行查询
limit+order by
可以看到日志,是每个表先执行一次,再进行排序,然后获取10条
我们可以看一下结果是不是 num= 999~990
结果是没有问题的
limit+offset+order by
相当于跳过几条数据,这个在实际业务的分页查询中是很常见的。
查询结果我们也可以看到是正确的 num为997~988
日志如下:

但是可以看到,对比我们原来的limit 2,10
shardingjdbc会首先将每个表,进行limit 0,2+10 也就是 limit 0,12,然后将这些数据查询出来之后,再进行归并排序,获取我们想要的10条数据
当然,这个在我们跳页比较少的时候,是没问题的。但是,如果我们offset是10000,是10w呢,那么一次性可能就查询出1w条数据,10w条数据。对于sql查询和内存都有很大的压力。
所以排序问题是shardingjdbc的一个需要面对的问题
那么有几种方式呢?
1、禁止跳表,根据id和limit结合去获取数据,不使用offset
2、结合ES实现搜索引擎进行处理
后续我们再进行讲解。
遇到问题
Caused by: java.lang.ClassNotFoundException: com.alibaba.druid.pool.DruidDataSource
需要导入依赖
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.8</version></dependency>
也可以研究一下用这种方式导入,不过好像不行
<dependency>-->
<groupId>com.alibaba</groupId>-->
<artifactId>druid</artifactId>-->
<version>1.2.8</version>-->
</dependency>
Failed to determine a suitable driver class
处理方式
1、添加yaml配置
spring:autoconfigure:# 排除druid 否则报错exclude: com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure
2、运行中项目
待续…
项目源码
可以关注公众号
I am Walker
回复
项目源码
即可.
版权归原作者 WalkerShen 所有, 如有侵权,请联系我们删除。