
一、ES支持的三种分页查询方式
- From + Size 查询
- Scroll 遍历查询
- Search After 查询
二、分布式系统中的深度分页问题
为什么分布式存储系统中对深度分页支持都不怎么友好呢?
首先我们看一下分布式存储系统中分页查询的过程。
假设在一个有 4 个主分片的索引中搜索,每页返回10条记录。
当我们请求结果的第1页(结果从 1 到 10 ),每一个分片产生前 10 的结果,并且返回给 协调节点 ,协调节点对 40 个结果排序得到全部结果的前 10 个。
当我们请求第 99 页(结果从 990 到 1000),需要从每个分片中获取满足查询条件的前1000个结果,返回给协调节点, 然后协调节点对全部 4000 个结果排序,获取前10个记录。
当请求第10000页,每页10条记录,则需要先从每个分片中获取满足查询条件的前100010个结果,返回给协调节点。然后协调节点需要对全部(100010 * 分片数4)的结果进行排序,然后返回前10个记录。
可以看到,在分布式系统中,对结果排序的成本随分页的深度成指数上升。
1.from size查询
GET customer/_search
{
"from": 0,
"size": 10,
"query": {
"match_all": {}
},
"sort": [
{"id": "asc"}
]
}
max_result_window默认值为10000
分页默认只能查到10000条
解决办法:修改max_result_window
DSL语句修改配置
PUT http://localhost:9200/customer/_settings
{ "max_result_window": 2100000000 }
查询的时候带上
{
"from": 0,
"size": 10,
"track_total_hits": true,
"query": {
"match_all": {}
},
"sort": [
{"id": "asc"}
]
}
java代码
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().trackTotalHits(true);
这种深度搜索方式不推荐,性能很差
2.scroll游标查询
第一次查询的时候设置参数 scroll 的值为我们期望的游标查询的过期时间
GET /bank/_search?scroll=1m
{
"from":0,
"size":10
}
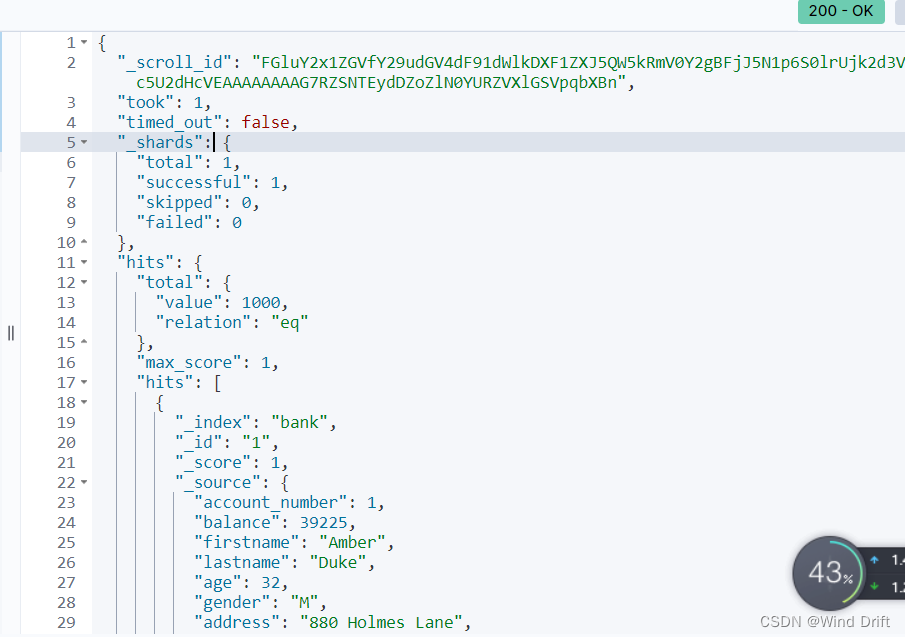
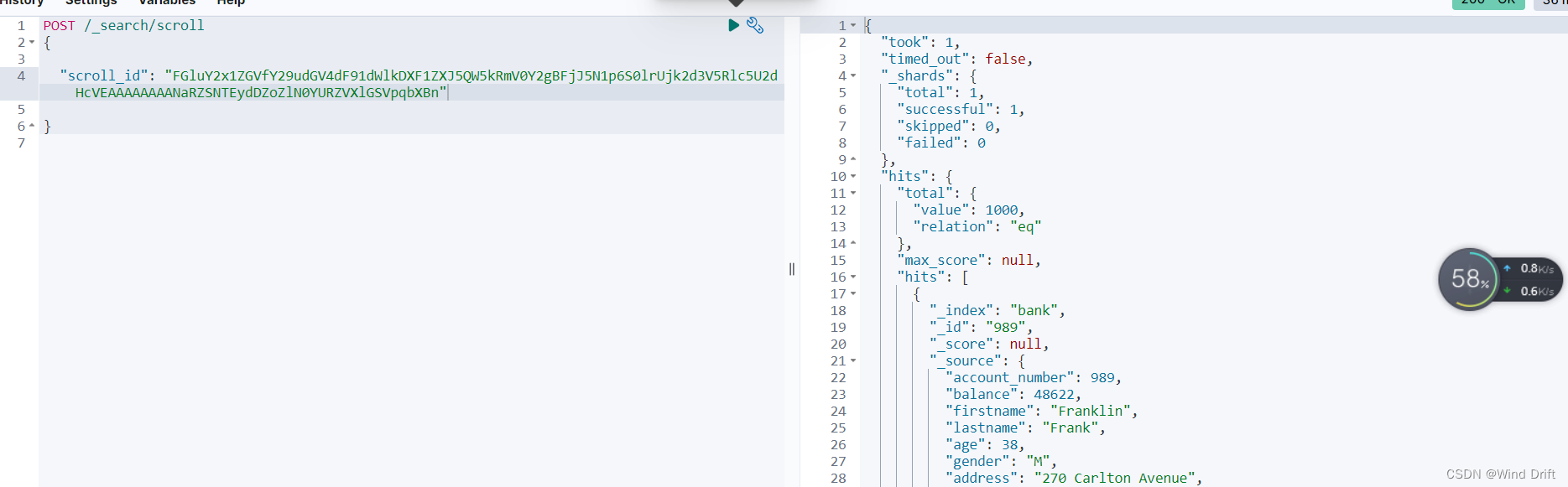
POST /_search/scroll
{
"scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFjJ5N1p6S0lrUjk2d3V5Rlc5U2dHcVEAAAAAAAAMJRZSNTEydDZoZlN0YURZVXlGSVpqbXBn"
}
删除游标
DELETE /_search/scroll
{
"scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFjJ5N1p6S0lrUjk2d3V5Rlc5U2dHcVEAAAAAAAAMJRZSNTEydDZoZlN0YURZVXlGSVpqbXBn"
}

3.search after方式(推荐使用)
GET bank/_search
{
"search_after": [10],
"sort": [
{"account_number": "asc"}
],
"size":10,
"from":0
}
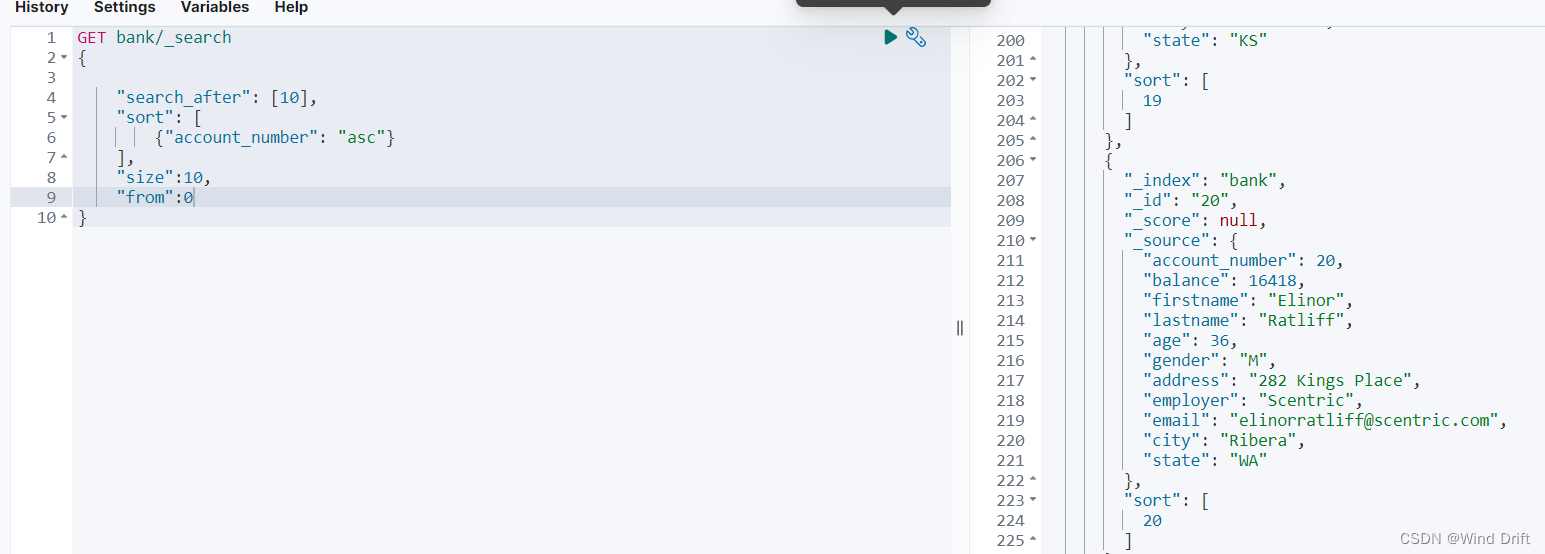
注意:使用search after分页from必须为0或-1,或者不填,排序的选项必须唯一,可以根据多个条件来排序,也可以根据pit来做search_after条件做排序,不然分页查询会漏数据,下次查询的search after的值为上次查询最后一个sort的值
本文转载自: https://blog.csdn.net/Wind___Drift/article/details/130659947
版权归原作者 Wind Drift 所有, 如有侵权,请联系我们删除。
版权归原作者 Wind Drift 所有, 如有侵权,请联系我们删除。