
Hadoop的集群搭建
Linux环境下Hadoop的集群搭建过程
我使用的是Hadoop3.1.1版本,连接https://archive.apache.org/dist/hadoop/common/,在这里可以找到所有的Hadoop版本,JDK使用的是1.8,我在阿里云上租了五台服务器,具体怎么租可以字型搜索,几毛钱一个小时,不用按小时,按抢占式就可以满足需求,后期如果有需要会专门出一个教程。设备使用的ubuntu14.0
配置Java环境
我在opt目录下创建了两个文件夹,一个是software,用来存放一些安装包,一个是module用来存放一个。
cd opt
mkdir software
mkdir module
然后利用xftp将下载好的jdk上传到software目录下,然后将其解压到module目录下。
root@node1:/opt/software# tar -zxvf jdk-8u401-linux-x64.tar.gz -C /opt/module
解压后,需要配置java环境变量。
vim /etc/profile
添加java的安装路径,JAVA_HOME需要是你自己的安装路径
#JAVA_ENVIRONMENT
export JAVA_HOME=/opt/module/jdk1.8.0_401
export PATH=$JAVA_HOME/bin:$PATH
配置完成后记得重新运行一下配置文件
source /etc/profile
最后检查是否安装成功
java -version
显示如下表示配置成功
Hadoop环境变量配置
然后利用xftp将下载好的hadoop3.1.1.tar.gz上传到software目录下,然后将其解压到module目录下。
root@node1:/opt/software# tar -zxvf hadoop3.1.1.tar.gz -C /opt/module
解压后,需要配置Hadoop环境变量。
vim /etc/profile
添加Hadoop的安装路径,HADOOP_HOME需要是你自己的安装路径
#HADOOP_ENVIRONMENT
export HADOOP_HOME=/opt/module/hadoop-3.1.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
配置完成后记得重新运行一下配置文件
source /etc/profile
最后检查是否安装成功
hadoop version
显示如下表示配置成功
创建分发脚本
为了让其他机器都具备一样的环境,我们可以编写一个分发脚本,让其他机器与第一台机器同步,
我在/opt/moudle文件夹下创建了一个xsync脚本
root@node1:/opt# cd module/
root@node1:/opt/module# vim xsync
具体内容如下:
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in node1 node2 node3 node4 node5 node6
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
其中node1、node2、node3等代表着其他机器,使用域名映射地址。需要将脚本放在一个所有用户都可以访问的目录中,通常是系统路径的一部分,利用bin目标中。
cp xsync /bin/
这样以来就可以全局的使用该脚本。
配置其他机器
在配置每台机器之前需要修改主机名。
vim /etc/hostname
node2
同时需要修改域名映射,ip地址和主机名要一一对应。
vim /etc/hosts
ip地址 主机名
192.168.1.10 node1
192.168.1.11 node2
192.168.1.12 node3
修改完hosts文件后利用xync脚本将hosts文件分发到每个机器下。
想要其他机器之间互通,需要配置免密登录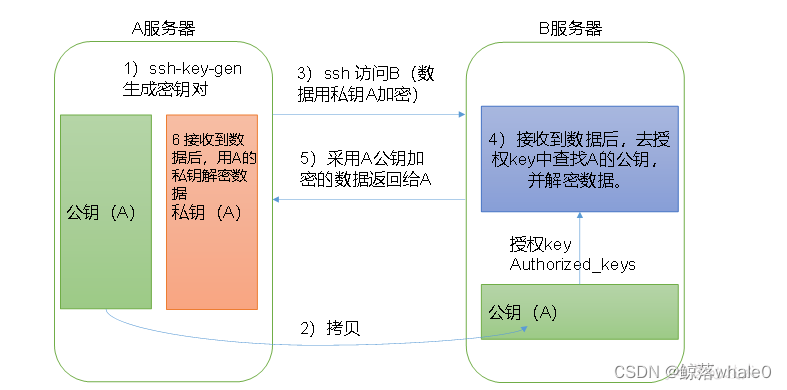 输入以下命令,获取免密登录,每台机器上都要这样配置。
输入以下命令,获取免密登录,每台机器上都要这样配置。
cd .ssh
ssh-keygen -t rsa
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
ssh-copy-id node4
ssh-copy-id node5
然后利用xsync将hadoop-3.1.1、JDK1.8、profile和xsync分发到其他机器上。
xsync /opt/module
xsync /etc/profile
配置集群核心文件
hadoop-env.sh 是 Hadoop 配置文件中的一个重要组成部分,主要负责设置 Hadoop 运行所需的环境变量。这个脚本文件在 Hadoop 启动时会被执行,以确保正确的环境配置。
hadoop-env.sh
export JAVA_HOME=/home/ncsgroup/java
export HADOOP_HOME=/home/ncsgroup/zrshen/hadoop-3.1.1
export HDFS_NAMENODE_USER=ncsgroup # replace "ncsgroup" with your username
export HDFS_DATANODE_USER=ncsgroup
export HDFS_SECONDARYNAMENODE_USER=ncsgroup
export YARN_RESOURCEMANAGER_USER=ncsgroup
export YARN_NODEMANAGER_USER=ncsgroup
core-site.xml
<configuration>
<property><name>fs.defaultFS</name><value>hdfs://192.168.10.51:9000</value></property>
<property><name>hadoop.tmp.dir</name><value>/home/ncsgroup/zrshen/hadoop-3.1.1</value></property>
</configuration>
hdfs-site.xml
<configuration>
<property><name>dfs.replication</name><value>1</value></property>
<property><name>dfs.blocksize</name><value>67108864</value></property>
</configuration>
worker
node2
node3
node4
node5
注意,这里我们仅仅配置HDFS相关的配置,如果需要使用mapreduce和yarn,请自行搜索相关配置。
在启动之前需要格式化namenode,hdfs namenode -formart
群启集群/群停集群
start-dfs.sh/stop-dfs.sh
使用jps查看集群是否启动成功。
如果在后来更换了节点,需要删除hadoop-3.1.1下面的data和logs文件
版权归原作者 鲸落whale0 所有, 如有侵权,请联系我们删除。