
之前使用Flink查询Redis数据的过程中,由于对数据一致性的要求并不是很高,当时是用MapFunction + State 的方案。先缓存一大堆数据到State中,达到一定数量之后,将批量Key提交到Redis中进行查询。
由于Redis性能极高,所以并没有出现什么问题,后来了解到了Flink异步IO机制,感觉使用异步IO机制实现会更加优雅一点。本文就是记录下自己对Flink异步IO的一个初步认识。
异步算子主要应用于和外部系统交互,提高吞吐量,减少等待延迟。用户只需关注业务逻辑即可,消息顺序性和一致性由Flink框架来处理:
图来自官网:
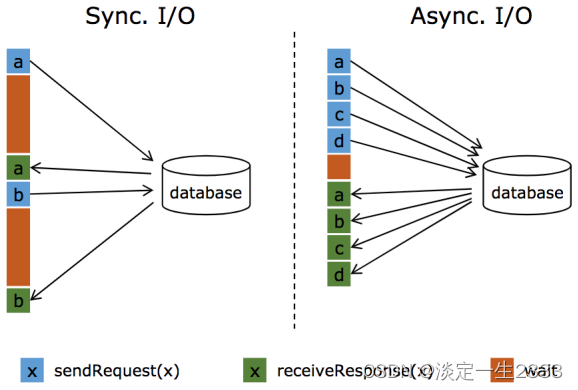
异步IO支持输出无序和有序,也支持watermark以及ExactlyOnce语义:
异步IO的核心代码都在AsyncWaitOperator里面:
switch (outputMode) { case ORDERED: queue = new OrderedStreamElementQueue<>(capacity); break; case UNORDERED: queue = new UnorderedStreamElementQueue<>(capacity); break; default: throw new IllegalStateException("Unknown async mode: " + outputMode + '.'); }
orderedWait(有序):消息的发送顺序与接收到的顺序完全相同(包括 watermark )。
unorderWait(无序):在ProcessingTime中是完全无序的,即哪个先完成先发送(最低延迟和消耗);在EventTime中,以watermark为边界,介于两个watermark之间的消息是乱序的,但是多个watermark之间的消息是有序的。
异步IO处理内部会执行 userFunction.asyncInvoke(element.getValue(), resultHandler) 调用用户自己编写的方法来处理数据。userFunction就是用户自己编写的自定义方法。resultHandler就是用户在完成异步调用自己,如何把结果传入到异步IO算子中:
(ps: userFunction是基于CompletableFuture来完成开发的。CompletableFuture是 Java 8 中引入的一个类,它实现了CompletionStage接口,提供了一组丰富的方法来处理异步操作和多个任务的结果。它支持链式操作,可以方便地处理任务的依赖关系和结果转换。相比于传统的Future接口,CompletableFuture更加灵活和强大。具体demo可以看官网示例 或者 看下面参考中的链接)
@Override public void processElement(StreamRecord<IN> element) throws Exception { // add element first to the queue final ResultFuture<OUT> entry = addToWorkQueue(element); // 这里的ResultHandler就是对数据和ResultFuture的一个封装 final ResultHandler resultHandler = new ResultHandler(element, entry); // register a timeout for the entry if timeout is configured if (timeout > 0L) { final long timeoutTimestamp = timeout + getProcessingTimeService().getCurrentProcessingTime(); final ScheduledFuture<?> timeoutTimer = getProcessingTimeService().registerTimer( timeoutTimestamp, timestamp -> userFunction.timeout(element.getValue(), resultHandler)); resultHandler.setTimeoutTimer(timeoutTimer); } // 调用用户编写的方法。 传入的resultHandler就是让用户在异步完成的时候传值用的 userFunction.asyncInvoke(element.getValue(), resultHandler); }@Override // resultHandler类内部的complete方法就是在用户自定义函数中传结果用的,最终执行结果会调用processInMainBox(results)方法,将结果发送给下游算子 public void complete(Collection<OUT> results) { Preconditions.checkNotNull(results, "Results must not be null, use empty collection to emit nothing"); // already completed (exceptionally or with previous complete call from ill-written AsyncFunction), so // ignore additional result if (!completed.compareAndSet(false, true)) { return; } processInMailbox(results); }
orderedWait 实现:
有序的话很简单,就是创建一个队列,然后从队首取元素即可
public OrderedStreamElementQueue(int capacity) { Preconditions.checkArgument(capacity > 0, "The capacity must be larger than 0."); this.capacity = capacity; // 所有的元素都放在这么一个队列里面 this.queue = new ArrayDeque<>(capacity); } @Override public boolean hasCompletedElements() { // 然后FIFO就好了 return !queue.isEmpty() && queue.peek().isDone(); }
unorderWait 实现:
无序的话实现就会稍微复杂点。queue里面放的不是一条条数据,而是一个个segment。数据存放在segment中,中间使用watermark分隔(每条watermark都会有自己单独的segment)。
public UnorderedStreamElementQueue(int capacity) { Preconditions.checkArgument(capacity > 0, "The capacity must be larger than 0."); this.capacity = capacity; // most likely scenario are 4 segments <elements, watermark, elements, watermark> this.segments = new ArrayDeque<>(4); this.numberOfEntries = 0; }// 每个segment内部会有两个队列:未完成 和 已完成。未完成的数据在完成之后会放置到已完成队列里面,然后发送到下游算子 static class Segment<OUT> { /** Unfinished input elements. */ private final Set<StreamElementQueueEntry<OUT>> incompleteElements; /** Undrained finished elements. */ private final Queue<StreamElementQueueEntry<OUT>> completedElements; Segment(int initialCapacity) { incompleteElements = new HashSet<>(initialCapacity); completedElements = new ArrayDeque<>(initialCapacity); } /** * Signals that an entry finished computation. */ void completed(StreamElementQueueEntry<OUT> elementQueueEntry) { // adding only to completed queue if not completed before // there may be a real result coming after a timeout result, which is updated in the queue entry but // the entry is not re-added to the complete queue if (incompleteElements.remove(elementQueueEntry)) { completedElements.add(elementQueueEntry); } }
一致性实现:
一致性实现看起来很简单,就是将queue中未完成/已完成的数据备份下来。这里的queue就是上面的 OrderedStreamElementQueue 和 UnorderedStreamElementQueue:
@Override public void snapshotState(StateSnapshotContext context) throws Exception { super.snapshotState(context); ListState<StreamElement> partitionableState = getOperatorStateBackend().getListState(new ListStateDescriptor<>(STATE_NAME, inStreamElementSerializer)); partitionableState.clear(); // 这里的queue == OrderedStreamElementQueue / UnorderedStreamElementQueue try { partitionableState.addAll(queue.values()); } catch (Exception e) { partitionableState.clear(); throw new Exception("Could not add stream element queue entries to operator state " + "backend of operator " + getOperatorName() + '.', e); } }
参考:
https://nightlies.apache.org/flink/flink-docs-release-1.18/zh/docs/dev/datastream/operators/asyncio/(官网文章)
[Flink] Flink异步I/O原理和实现 - 知乎
flink 异步 io(Async I/O) 示例_java.util.concurrent.cancellationexception flink-CSDN博客
本文转载自: https://blog.csdn.net/zc19921215/article/details/135045394
版权归原作者 淡定一生2333 所有, 如有侵权,请联系我们删除。
版权归原作者 淡定一生2333 所有, 如有侵权,请联系我们删除。