
定义
定义:数组是一种可变的、可索引的数据集合。
语法格式
语法格式:Scala中用Array[T]的形式来表示Java中的数组形式 T[ ]
声明数组对象 var a = Array(1,2,3,4,5)
集合操作
++ 合并数组
语法:def ++[B](that: GenTraversableOnce[B]): Array[B]
注解:合并集合,并返回一个新的数组,新数组包含左右两个集合对象的内容。
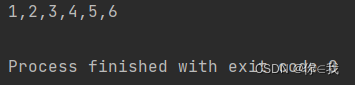
var a = Array(1, 2, 3)
var b = Array(4, 5, 6)
var c = a ++ b
println(c.mkString(","))
++: 合并数组
语法:def ++:[B >: A, That](that: collection.Traversable[B])(implicit bf: CanBuildFrom[Array[T], B, That]): That
注解:这个方法同上一个方法类似,两个加号后面多了一个冒号,但是不同的是右边操纵数的类型决定着返回结果的类型。下面代码中List和LinkedList结合,返回结果是LinkedList类型
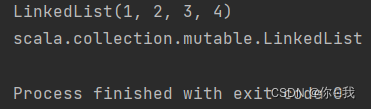
val a = List(1, 2)
val b = scala.collection.mutable.LinkedList(3, 4)
val c = a ++: b
println(c)
println(c.getClass().getName())
+: 前面添加元素
语法:def +:(elem: A): Array[A]
注解:在数组前面添加一个元素,并返回新的对象
var a = List(1, 2, 3)
var b = 0 +: a
println(b)

:+ 末尾添加元素
语法:def :+(elem: A): Array[A]
注解:在数组前面添加一个元素,并返回新的对象
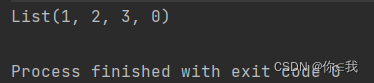
var a = List(1, 2, 3)
var b = a :+ 0
println(b)
/: 从左到右计算
语法:def /:[B](z: B)(op: (B, T) ⇒ B): B
注解:对数组中所有的元素进行相同的操作 ,foldLeft的简写(左二叉树)
var a = List(1, 2, 3, 4)
var b = (10 /: a) (_ + _)
var c = (10 /: a) (_ * _)
var d = (10 /: a) (_ - _)
println(b) // 10+1+2+3+4
println(c) // 10*1*2*3*4
println(d) // 10-1-2-3-4
:\ 从右到左计算
语法:def :[B](z: B)(op: (T, B) ⇒ B): B
注解:对数组中所有的元素进行相同的操作 ,foldRight的简写(右二叉树)
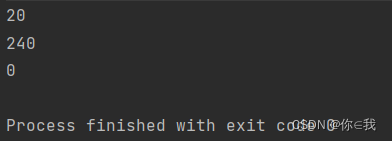
var a = Array(1, 2, 3, 4)
var b = (a :\ 10) (_ + _)
var c = (a :\ 10) (_ * _)
var d = (a :\ 10) (_ - _)
println(b)
println(c)
println(d)

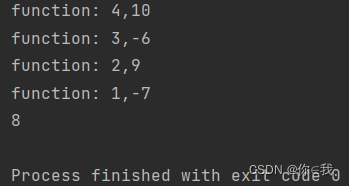
分析:
def one(p1: Int, p2: Int): Int = { println(s"function: ${p1},${p2}") p1 - p2 } var a = List(1, 2, 3,4) var b = (a :\ 10) (one) println(b)
addString 数组添加元素
语法:def addString(b: StringBuilder): StringBuilder
注解:将数组中的元素逐个添加到b中
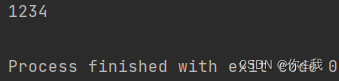
val a = List(1, 2, 3, 4)
val b = new StringBuilder()
val c = a.addString(b)
println(c)
语法: def addString(b: StringBuilder, sep: String): StringBuilder
注解:将数组中的元素逐个添加到b中,但每个元素间sep分隔符分开
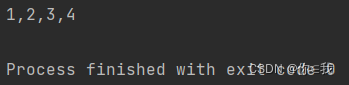
val a = List(1, 2, 3, 4)
val b = new StringBuilder()
val c = a.addString(b, ",")
println(c)
语法:def addString(b: StringBuilder, start: String, sep: String, end: String): StringBuilder
注解:将数组中的元素逐个添加到b中,同时在首尾各加一个字符串,并指定sep分隔符
val a = List(1, 2, 3, 4)
val b = new StringBuilder()
val c = a.addString(b, "{", ",", "}")
println(c)

aggregate 聚合计算
语法:def aggregate[B](z: ⇒ B)(seqop: (B, T) ⇒ B, combop: (B, B) ⇒ B): B
注解:聚合计算,aggregate是柯里化方法,参数是两个方法。
val a = List(1, 2, 3, 4)
val c = a.par.aggregate(4)(_ + _, _ + _)
println(c)

** 分析:**为了方便理解,我们把aggregate的两个参数,分别封装成两个方法,并把计算过程打印出来。
var arr = Array(1, 2, 3, 4) def one(p1: Int, p2: Int): Int = { println(s"one function: ${p1},${p2}") p1 + p2 } def two(p1: Int, p2: Int) = { println(s"two function: ${p1},${p2}") p1 + p2 } var sum = arr.par.aggregate(4)(one, two) println(sum)
分析2
val seq = Seq("nihao", "scala", "hello", "world") val result = seq.par.aggregate(0)(_ + _.length, _ + _) println(result) /* 输出: 此处,聚合函数的初始值为零,用于计算此处使用的字符串中字母的总数。 方法的长度用于枚举每个字符串的长度。让我们详细讨论以上程序中使用的以下代码。 (_ + _.length, _ + _) 在此,Seq("nihao", "scala", "hello", "world") 先执行序列操作。 (0 + "nihao".length ) // (0+5) = 5 (0 + "scala".length) // (0+5) = 5 (0 + "hello".length) // (0+5) = 5 (0 + "world".length) // (0+5) = 5 因此,从序列运算中得到(5),(5),(5),(5) 执行合并操作。 (5+5) = 10 (5+5) = 10 (10+10) = 20 */

apply 取索引处元素
语法:def apply(i: Int): T
注解:取出指定索引处的元素
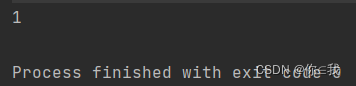
var a = List(1, 2, 3, 4)
println(a.apply(0))
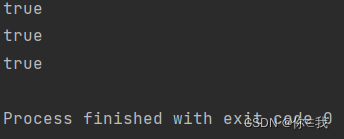
canEqual 比较
语法:def canEqual(that: Any): Boolean
注解:判断两个对象是否可以进行比较
var arr = List(1, 2, 3, 4)
println(arr.canEqual("1"))
println(arr.canEqual(None))
println(arr.canEqual("a"))
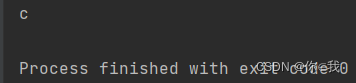
charAt 获取索引处字符
语法:def charAt(index: Int): Char
注解:获取index索引处的字符,这个方法会执行一个隐式的转换,将Array[T]转换为 ArrayCharSequence,只有当T为char类型时,这个转换才会发生。
var arr1 = Array('a', 'b', 'c')
println(arr1.charAt(2))
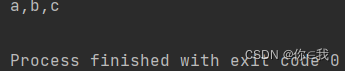
clone 克隆
语法:def clone(): Array[T]
注解:创建一个副本、克隆,这是一个浅克隆
val a = Array('a','b','c')
println(a.clone().mkString(","))
collect 并行计算(偏函数)
语法:def collect[B](pf: PartialFunction[A, B]): Array[B]
注解:通过执行一个并行计算(偏函数),得到一个新的数组对象
var arr = Array(1, 2, 3, 4, 5)
def pfun: PartialFunction[Int, Int] = {
case x if (x % 2 == 0) => x + 5 //模式守卫
}
println(arr.collect(pfun).mkString(","))
println(arr.collect { case x if (x % 2 == 0) => x + 5 }.mkString(","))
println(arr.collect({ case x if (x % 2 == 0) => x + 5 }).mkString(","))
分析

collectFirst 查找第一个符合偏函数的元素
语法:def collectFirst[B](pf: PartialFunction[T, B]): Option[B]
注解:在序列中查找第一个符合偏函数定义的元素,并执行偏函数计算
var arr = Array(1, 2, 3, 4, 5)
def pfun: PartialFunction[Int, Int] = {
case x if (x % 2 == 0) => x + 5 //模式守卫
}
println(arr.collectFirst({ case x if (x % 2 == 0) => x + 5 }))
println(arr.collectFirst({ case x if (x % 2 == 0) => x + 5 }).get)
println(arr.collectFirst({ case x if (x > 200) => x + 5 }))
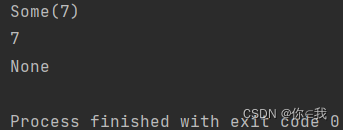
分析:
.get是获取出这个值
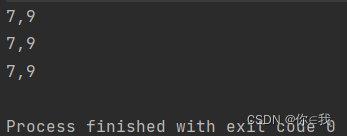
combinations 排列组合
语法: def combinations(n: Int): collection.Iterator[Array[T]]
注解:排列组合,这个排列组合会选出所有包含字符不一样的组合,(对于 “123”、“321”,只选择一个),参数n表示序列长度,即几个元素为一个组合
var arrs = Array(4, 5, 6)
arrs.combinations(2).foreach(x => println(x.mkString(",")))
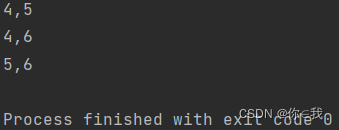
contains 判断序列中是否包含指定对象
语法: def contains[A1 >: A](elem: A1): Boolean
注解:判断序列中是否包含指定对象
var arr = Array(1, 2, 3, 4)
println(arr.contains(4))
println(arr.contains(100))
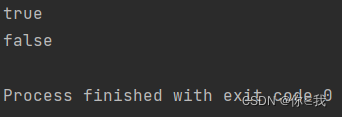
containsSlice 判断当前序列中是否包含另一个序列
语法:def containsSlice[B](that: GenSeq[B]): Boolean
注解:判断当前序列中是否包含另一个序列
var arr = Array(1, 2, 3, 4)
println(arr.containsSlice(Seq(1, 3)))
println(arr.containsSlice(List(2, 3)))

copyToArray 将元数组中的元素拷贝到新数组
语法1:def copyToArray(xs: Array[A]): Unit
注解1:将元数组中的元素拷贝到新数组,默认拷贝元数组所有元素
语法2:def copyToArray(xs: Array[A], start: Int): Unit
注解2:将元数组中的元素拷贝到新数组,从新数组索引为start的地方开始写入,默认拷贝元数组所有元素
语法3:def copyToArray(xs: Array[A], start: Int, len: Int): Unit
注解3:将元数组中的元素拷贝到新数组,从新数组索引为start的地方开始写入,拷贝元数组元素长度为len
val a = Array(1, 2, 3)
val b: Array[Int] = Array(0, 0, 0, 0)
a.copyToArray(b)
for (i: Int <- b) {
print(i + " ")
}
println()
a.copyToArray(b, 1)
for (i: Int <- b) {
print(i + " ")
}
println()
a.copyToArray(b, 1, 2)
for (i: Int <- b) {
print(i + " ")
}

copyToBuffer 将数组中的内容拷贝到Buffer中
语法:def copyToBuffer[B >: A](dest: Buffer[B]): Unit
注解:将数组中的内容拷贝到Buffer中
val a = Array(1, 2, 3)
val b: ArrayBuffer[Int] = ArrayBuffer()
a.copyToBuffer(b)
println(b.mkString(","))

corresponds 比较两个数组是否满足条件
语法:def corresponds[B](that: GenSeq[B])(p: (T, B) ⇒ Boolean): Boolean
注解:判断两个序列长度以及对应位置元素是否符合某个条件。如果两个序列具有相同的元素数量并且p(x, y)=true,返回结果为true;否则,返回false(如果元素数量不同,则直接返回false)
var arr1 = Array(1, 2, 3)
var arr2 = Array(4, 5, 6)
var arr3 = Array(4, 5, 6, 7)
println(arr1.corresponds(arr2)(_ >= _))
println(arr2.corresponds(arr1)(_ >= _))
print(arr1.corresponds(arr3)(_ >= _))
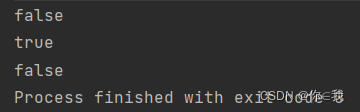
count 统计元素个数
语法:def count(p: (T) ⇒ Boolean): Int
注解:统计符合条件的元素个数
var arr = Array(1, 2, 3, 4, 5, 6, 7)
println(arr.count(x => x % 2 == 0))

diff 比较数组
语法:def diff(that: collection.Seq[T]): Array[T]
注解:计算当前数组与另一个数组的不同。将当前数组中没有在另一个数组中出现的元素返回
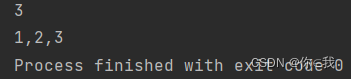
var arr1 = Array(1, 2, 3)
var arr2 = Array(1, 2)
var arr3 = Array(4,5)
println(arr1.diff(arr2).mkString(","))
print(arr1.diff(arr3).mkString(","))
distinct 去重
语法:def distinct: Array[T]
注解:去除当前集合中重复的元素,只保留一个
var a = Array(1, 2, 3, 4, 5, 5, 5)
println(a.distinct.mkString(","))

drop 删除数组元素
语法:def drop(n: Int): Array[T]
注解:将当前序列中前 n 个元素去除后,作为一个新序列返回
var a = Array(1, 2, 3, 4, 5)
print(a.drop(2).mkString(","))

dropRight 从尾部删除数组元素
语法:def dropRight(n: Int): Array[T]
注解:将当前序列中尾部 n 个元素去除后,作为一个新序列返回
var a = Array(1, 2, 3, 4, 5)
println(a.dropRight(2).mkString(","))

dropWhile 根据条件删除数组元素
语法:def dropWhile(p: (T) ⇒ Boolean): Array[T]
注解:去除当前数组中符合条件的元素(从当前数组的第一个元素起,直到碰到第一个不满足条件的元素结束,否则返回整个数组)
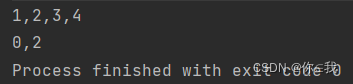
val a = Array(1, 2, 3, 4)
println(a.dropWhile({ x: Int => x > 2 }).mkString(","))
val b = Array(1, 2, 3, 0, 2)
print(b.dropWhile({ x: Int => x >= 1 }).mkString(","))
endsWith 判断是否以某个序列结尾
语法:def endsWith[B](that: GenSeq[B]): Boolean
注解:判断是否以某个序列结尾
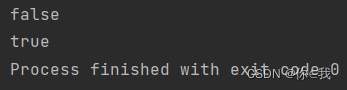
val a = Array(1, 2, 3, 4)
println(a.endsWith(Array(1, 4)))
println(a.endsWith(Array(3, 4)))
exists 判断当前数组是否包含符合条件的元素
语法:def exists(p: (T) ⇒ Boolean): Boolean
注解: 判断当前数组是否包含符合条件的元素
var arr1 = Array(1, 2, 3)
println(arr1.exists(x => x > 1))
println(arr1.exists({ x: Int => x == 3 }))
print(arr1.exists({ x: Int => x > 3 }))

filter 取得当前数组中符合条件的元素
语法:def filter(p: (T) ⇒ Boolean): Array[T]
注解:取得当前数组中符合条件的元素,组成新的数组返回,与下面一个filterNot相反
var a = Array(3, 4, 1, 5, 8, 3, 2)
println(a.filter({ x => x > 2 }).mkString(","))

filterNot 取得当前数组中不符合条件的元素
语法:def filterNot(p: (T) ⇒ Boolean): Array[T]
注解:取得当前数组中不符合条件的元素,组成新的数组返回,与上面一个filter相反
var a = Array(3, 4, 1, 5, 8, 3, 2)
print(a.filterNot({ x => x > 2 }).mkString(","))

find 查找第一个符合条件的元素
语法:def find(p: (T) ⇒ Boolean): Option[T]
注解:查找第一个符合条件的元素
val a = Array(1, 2, 3, 4)
println(a.find({ x: Int => x > 2 }))
print(a.find({ x: Int => x > 2 }).get)

flatMap 扩展数组
语法:def flatMap[B](f: (A) ⇒ GenTraversableOnce[B]): Array[B]
注解: 先执行Map对当前序列的每个元素进行操作,后执行flat将map后的结果放入新序列返回,参数要求是GenTraversableOnce及其子类
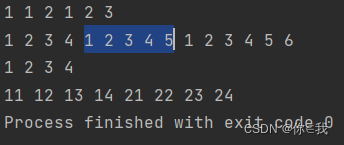
var a = Array(1, 2, 3)
var b = Array(4, 5, 6)
println(a.flatMap(x => 1 to x).mkString(" "))
println(b.flatMap(x => 1 to x).mkString(" "))
var aa = Array(Array(1, 2), Array(3, 4))
println(aa.flatMap(x => x).mkString(" "))
var bb = Array(Array(Array(11, 12), Array(13, 14)), Array(Array(21, 22), Array(23, 24)))
println(bb.flatMap(x => x).flatMap(x => x).mkString(" "))
分析:
/** 1 1 2 1 2 3 从1开始,分别于集合a的每个元素生成一个递增序列,过程如下 1 1 2 1 2 3 */ /** 11 12 13 14 21 22 23 24 一开始是两个集合先拆一层,再拆一层,过程如下 Array(Array(11,12),Array(13,14),Array(21,22,Array(23,24)) Array(11,12,13,14),Array(21,22,23,24) 11 12 13 14 21 22 23 24 */
flatten 将二维数组的所有元素联合在一起
语法:def flatten[U](implicit asTrav: (T) ⇒ collection.Traversable[U], m: ClassTag[U]): Array[U]
注解: 将二维数组的所有元素联合在一起,形成一个一维数组返回(要求数组中元素的维度保持一致,否则报错)
var bb = Array(Array(Array(11, 12), Array(13, 14)), Array(Array(21, 22), Array(23, 24)))
println(bb.flatten.flatten.mkString(" "))

fold 对数组进行二元运算
语法:def fold[A1 >: A](z: A1)(op: (A1, A1) ⇒ A1): A1
注解:对序列中的每个元素进行二元运算
var a = Array(1, 2, 3, 4)
print(a.fold(5)((x, y) => {
println(x, y);
x + y
}))
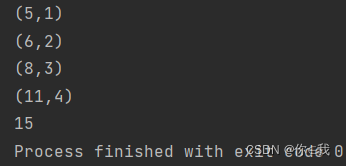
分析:
** 区分aggregate:fold同aggregate有类似的语义,但执行过程有所不同(aggregate需要两个处理方法)二者都是对序列中的每个元素进行二元运算,和aggregate有类似的语义,但执行过程有所不同,对比一下他们的执行过程。 因为aggregate需要两个处理方法**
def one(m: Int, n: Int): Int = { val s = "seq_exp=%d+%d" println(s.format(m, n)) return m + n } def two(m: Int, n: Int): Int = { val s = "com_exp=%d+%d" println(s.format(m, n)) return m + n } val a = Array(1, 2, 3, 4) val b = a.fold(5)(one) /** 运算过程 * seq_exp=5+1 * seq_exp=6+2 * seq_exp=8+3 * seq_exp=11+4 */ val c = a.par.aggregate(5)(one, two) /** 运算过程 * seq_exp=5+1 * seq_exp=5+3 * seq_exp=5+2 * seq_exp=5+4 * com_exp=6+7 * com_exp=8+9 * com_exp=13+17 */看上面的运算过程发现,fold中,one是把初始值顺序和每个元素相加,把得到的结果与下一个元素进行运算
而aggregate中,one是把初始值与每个元素相加,但结果不参与下一步运算,而是放到另一个序列中,由第二个方法two进行处理
foldLeft 从左到右计算
语法:def foldLeft[B](z: B)(op: (B, T) ⇒ B): B
简写方式:def /:[B](z: B)(op: (B, T) ⇒ B): B
注解:从左到右计算
var a = Array(1, 2, 3,4)
println(a.foldLeft(5)((x, y) => {
println(x, y);
x + y
}))
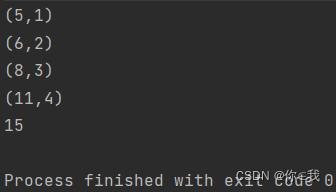
**分析: **
def one(m:Int,n:Int): Int ={ val s = "seq_exp=%d+%d" println(s.format(m,n)) return m+n } val a = Array(1, 2, 3,4) val b = a.foldLeft(5)(one) /** 运算过程 seq_exp=5+1 seq_exp=6+2 seq_exp=8+3 seq_exp=11+4 */ /** 简写 (5 /: a)(_+_) */
foldRight 从右到左计算
语法:def foldRight[B](z: B)(op: (B, T) ⇒ B): B
简写方式:def :[B](z: B)(op: (T, B) ⇒ B): B
注解:从右到左计算
var a = Array(1, 2, 3, 4)
println(a.foldRight(5)((x, y) => {
println(x, y);
x + y
}))
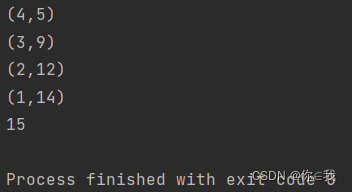
分析:
def one(m:Int,n:Int): Int ={ val s = "seq_exp=%d+%d" println(s.format(m,n)) return m+n } val a = Array(1, 2, 3,4) val b = a.foldRight(5)(one) /** 运算过程 seq_exp=4+5 seq_exp=3+9 seq_exp=2+12 seq_exp=1+14 */ /** 简写 (a :\ 5)(_+_) */
forall 检测序列中的元素是否都满足条件
语法:def forall(p: (T) ⇒ Boolean): Boolean
注解:检测序列中的元素是否都满足条件 p,如果序列为空,返回true
var a = Array(1, 2, 3)
println(a.forall(x => x > 0))
print(a.forall(x => x > 2))
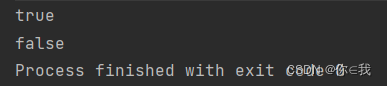
foreach 遍历数组
语法:def foreach(f: (A) ⇒ Unit): Unit
注解:遍历序列中的元素,进行 f 操作
val a = Array(1, 2, 3, 4)
a.foreach(x => print(x))

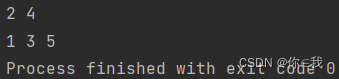
groupBy 按条件分组
语法:def groupBy[K](f: (T) ⇒ K): Map[K, Array[T]]
注解:按条件分组,条件由 f 匹配,返回值是Map类型,每个key对应一个序列。(条件最多23个)
var a = Array(1, 2, 3, 4, 5)
var b = a.groupBy(x => {
if (x % 2 == 0) 0 else 1
})
println(b(0).mkString(" "))
print(b(1).mkString(" "))
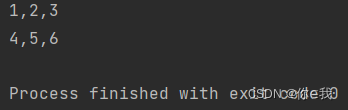
grouped 按指定数量分组
语法:def grouped(size: Int): collection.Iterator[Array[T]]
注解:按指定数量将序列分为2组,每组有 size 数量个元素,返回一个集合(若序列元素数量 > size*2,则超出的元素不参与分组)
val a = Array(1, 2, 3, 4, 5, 6)
val b = a.grouped(3)
b.foreach(x => println(x.mkString(",")))
hasDefiniteSize 检测长度
语法:def hasDefiniteSize: Boolean
注解:检测序列是否存在有限的长度,对应Stream这样的流数据,返回false
var a = Array(1, 2, 3, 4, 5, 6, 7)
print(a.hasDefiniteSize)

head 获取第一个元素
语法:def head: T
注解:返回序列的第一个元素,如果序列为空,将引发错误
var a = Array(1, 2, 3, 4, 5, 6, 7)
var b: Array[Int] = Array()
println(a.head)
print(b.head)

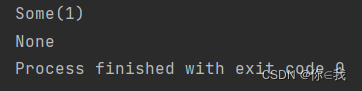
headOption 返回类型对象
语法:def headOption: Option[T]
注解:返回Option类型对象,(scala.Some 或者 None)如果序列是空,返回None
var a = Array(1, 2, 3, 4, 5, 6, 7)
var b: Array[Int] = Array()
println(a.headOption)
print(b.headOption)
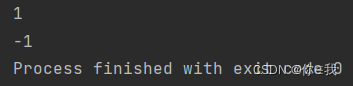
indexOf 返回索引
indexOf(elem: T) 返回索引从头开始
语法:def indexOf(elem: T): Int
注解:返回elem在序列中的索引,找到第一个就返回索引值,找不到返回-1
var a = Array(1, 2, 3, 4, 5, 6, 7)
println(a.indexOf(2))
print(a.indexOf(8))
indexOf(elem: T, from: Int) 返回索引 从指定位置开始
语法:def indexOf(elem: T, from: Int): Int
注解:返回elem在序列中的索引,可以指定从某个索引处(from)开始查找,找到第一个就返回索引值,找不到返回-1
var a = Array(1, 2, 3, 4, 5, 6, 7)
println(a.indexOf(2, 0))
print(a.indexOf(2, 2))
indexOfSlice 检测当前序列中是否包含另一个序列
语法:def indexOfSlice[B >: A](that: GenSeq[B]): Int
注解:检测当前序列中是否包含另一个序列(that),并返回第一个匹配出现的元素的索引,找不到返回-1
var a = Array(1, 2, 3, 4, 5, 6, 7)
var b = Array(3, 4)
var c = Array(1, 3)
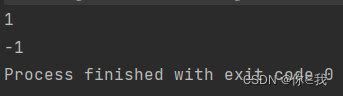
println(a.indexOfSlice(b))
print(a.indexOfSlice(c))
indexOfSlice 检测当前序列中是否包含另一个序列 从指定位置开始
语法:def indexOfSlice[B >: A](that: GenSeq[B], from: Int): Int
注解:检测当前序列中是否包含另一个序列(that),并返回第一个匹配出现的元素的索引,指定从 from 索引处开始,找不到返回-1
var a = Array(1, 2, 3, 4, 5, 6, 7)
var b = Array(3, 4)
var c = Array(2, 3)
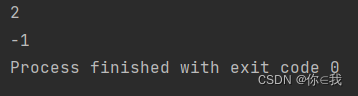
println(a.indexOfSlice(b, 1))
print(a.indexOfSlice(c, 3))

indexWhere 返回序列中满足条件元素索引
语法:def indexWhere(p: (T) ⇒ Boolean): Int
注解:返回当前序列中第一个满足 p 条件的元素的索引
var a = Array(1, 2, 3, 4, 5, 6, 7)
print(a.indexWhere({ x: Int => x >= 3 }))

indexWhere 返回序列中满足条件元素索引 从指定位置开始
语法:def indexWhere(p: (T) ⇒ Boolean, from: Int): Int
注解:返回当前序列中第一个满足 p 条件的元素的索引,可以指定从 from 索引处开始
var a = Array(1, 2, 3, 4, 5, 6, 7)
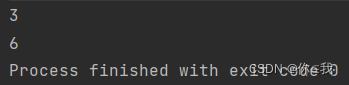
println(a.indexWhere({ x: Int => x >= 3 }, 3))
print(a.indexWhere({ x: Int => x >= 3 }, 6))
indices 返回当前序列索引
语法:def indices: collection.immutable.Range
注解:返回当前序列索引集合(对Map无效)
var a = Array(1, 2, 3, 4, 5, 6, 7)
print(a.indices.mkString(","))

版权归原作者 你∈我 所有, 如有侵权,请联系我们删除。