
其实爬虫是一个对计算机综合能力要求比较高的技术活。
首先是要对网络协议尤其是
http
协议有基本的了解, 能够分析网站的数据请求响应。学会使用一些工具,简单的情况使用 chrome devtools 的 network 面板就够了
- cheerio: 是jquery核心功能的一个快速灵活而又简洁的实现,主要是为了用在服务器端需要对DOM进行操作的地方,让你在服务器端和html愉快的玩耍。
- **axios **网络请求库可以发送http请求
第一步分析该网页
发现图片是在 article-content 下面的p标签

请求获取该图片

拼接url 拿到了第一页的数据

第二步递归读取所有图片
const baseUrl = 'xxxxxxxxxxxxxxxxxxxxxxx'
const next = '下一页'
let index = 0;
const urls: string[] = []
const getCosPlay = async () => {
console.log(index)
await axios.get(`xxxxxxxxxxxxxx/Cosplay/Cosplay10772${index ? '_'+index : ''}.html`).then(async res => {
//console.log(res.data)
const $ = cheerio.load(res.data)
const page = $('.article-content .pagination a').map(function () {
return $(this).text()
}).toArray()
if (page.includes(next)) {
$('.article-content p img').each(function () {
console.log($(this).attr('src'))
urls.push(baseUrl + $(this).attr('src'))
})
index++
await getCosPlay()
}
})
}
await getCosPlay()
console.log(urls)

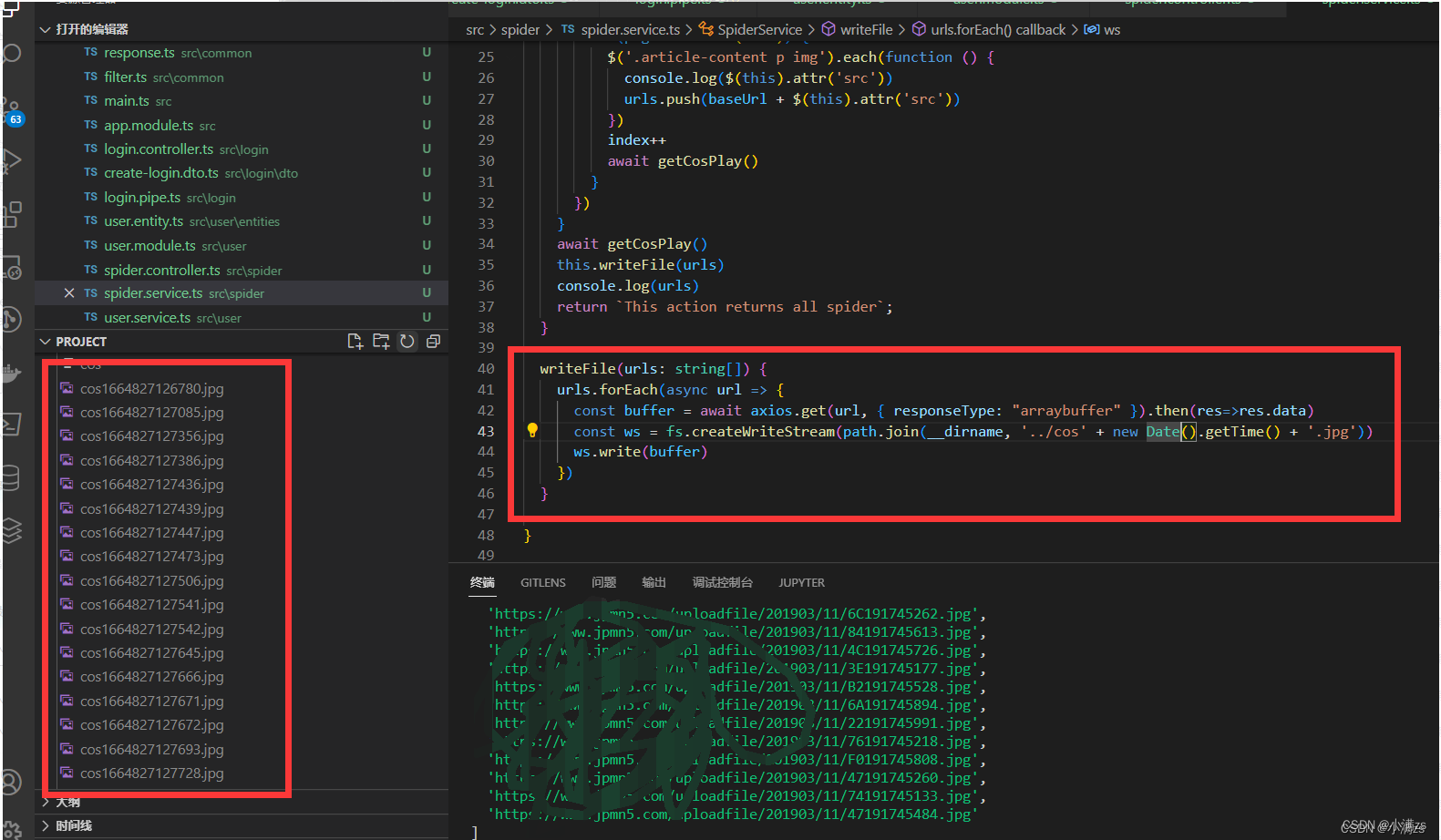
第三步写入本地
writeFile(urls: string[]) {
urls.forEach(async url => {
const buffer = await axios.get(url, { responseType: "arraybuffer" }).then(res=>res.data)
const ws = fs.createWriteStream(path.join(__dirname, '../cos' + new Date().getTime() + '.jpg'))
ws.write(buffer)
})
}

本文转载自: https://blog.csdn.net/qq1195566313/article/details/127158497
版权归原作者 小满zs 所有, 如有侵权,请联系我们删除。
版权归原作者 小满zs 所有, 如有侵权,请联系我们删除。