
相关文章
- 【数仓】基本概念、知识普及、核心技术
- 【数仓】数据分层概念以及相关逻辑
- 【数仓】Hadoop软件安装及使用(集群配置)
- 【数仓】Hadoop集群配置常用参数说明
- 【数仓】zookeeper软件安装及集群配置
- 【数仓】kafka软件安装及集群配置
- 【数仓】flume软件安装及配置
- 【数仓】flume常见配置总结,以及示例
一、flume有什么作用
Apache Flume是一个分布式、可靠且可用的大数据日志采集、聚合和传输系统。它主要用于将大量的日志数据从不同的数据源收集起来,然后通过通道(Channel)进行传输,最终将数据传输到指定的目的地,如HDFS、HBase等。Flume具有高度可扩展性、容错性和灵活性,可以适应各种复杂的数据采集场景。
Flume的核心组件包括Source、Channel和Sink。Source负责从数据源中读取数据,可以是文件、网络套接字、消息队列等;Channel是数据的缓冲区,用于在Source和Sink之间传输数据;Sink负责将数据写入目标存储系统,如HDFS、HBase、Kafka等。此外,Flume还支持多种类型的Source、Channel和Sink,用户可以根据实际需求进行选择和配置。
Flume的主要作用是实现大规模数据采集和传输,实现数据的实时处理和分析,从而为企业提供更好的业务决策支持。在实际应用中,Flume可以用于日志收集、事件跟踪、数据流处理等场景。通过将数据从不同的数据源采集并传输到指定的目的地,Flume可以帮助企业实现数据的集中存储和管理,为后续的数据分析和挖掘提供基础。
此外,Flume还具有可靠性机制和故障转移和恢复机制,能够保证数据传输的可靠性和安全性。同时,Flume还支持客户扩展和自定义开发,用户可以根据自己的需求进行扩展和优化,使其更加适合特定的应用场景。
总的来说,Apache Flume是一个功能强大、灵活可靠的大数据日志采集、聚合和传输系统,它在大数据处理中起到了至关重要的作用。
二、环境准备
准备1台虚拟机
- Hadoop131:192.168.56.131
本例系统版本 CentOS-7.8,已安装jdk1.8
关闭防火墙
systemctl stop firewalld
zookeeper、kafka 已安装,且已启动
三、flume安装配置
1、配置flume agent
1)本例演示 flume 去掉kafka数据,然后存储到hdfs中
2)完整数据通道是:log文件 > flume > kafka > flume > hdfs
3)flume 安装目录是 /data/flume
4)kafka 、Hadoop在前面已经安装过
新建配置文件
/data/flume/conf/job/kafka_to_hdfs_log.conf
,内容如下:
# 定义组件
# 这里定义了Flume agent的三个主要组件:source(数据源)、channel(通道)和sink(数据接收器)。
a2.sources=r2
a2.channels=c2
a2.sinks=k2
# 配置source
# 配置数据源为Kafka,指定了Kafka的相关参数,如服务器地址、主题等。
a2.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
# 每次从Kafka拉取的数据量
a2.sources.r2.batchSize=5000
# 拉取数据的间隔时间(毫秒)
a2.sources.r2.batchDurationMillis=2000
# Kafka服务器地址列表
a2.sources.r2.kafka.bootstrap.servers = hadoop131:9092,hadoop132:9092,hadoop133:9092
# 从Kafka的哪个主题拉取数据
a2.sources.r2.kafka.topics=topic_log
# 注释掉的部分是关于拦截器的配置,拦截器可以用来对数据源的数据进行预处理。
#a2.sources.r2.interceptors=i2
#a2.sources.r2.interceptors.i2.type = com.my.flume.interceptor.TimestampInterceptor
# 配置channel
# 配置通道为文件通道,指定了通道的相关参数,如检查点目录、数据目录等。
a2.channels.c2.type = file
# 检查点目录,用于存储通道的状态信息
a2.channels.c2.checkpointDir = /data/flume/checkpoint/behaviorl
# 数据目录,用于存储通道中的数据
a2.channels.c2.dataDirs = /data/flume/data/behaviorl
# 通道中文件的最大大小(字节)
a2.channels.c2.maxFileSize = 2146435071
# 通道的容量,即可以存储的最大事件数
a2.channels.c2.capacity = 1000000
# 通道的keepalive时间(秒)
a2.channels.c2.keepalive = 6
# 配置sink
# 配置数据接收器为HDFS,指定了HDFS的相关参数,如文件路径、文件前缀等。
a2.sinks.k2.type =hdfs
# HDFS上的文件路径,使用了时间变量来动态生成目录
a2.sinks.k2.hdfs.path = /origin_data/user/log/topic_log/%Y-%m-%d
# HDFS上的文件前缀
a2.sinks.k2.hdfs.filePrefix=log
# 是否按照时间轮转文件,这里设置为false,表示不按照时间轮转
a2.sinks.k2.hdfs.round =false
# 文件轮转的时间间隔(秒)
a2.sinks.k2.hdfs.rollInterval=10
# 文件轮转的大小阈值(字节)
a2.sinks.k2.hdfs.rollSize=134217728
# 文件轮转的事件数阈值,这里设置为0,表示不按照事件数轮转
a2.sinks.k2.hdfs.rollCount=0
# 控制输出文件类型
# 设置输出文件的类型为压缩流格式,并使用gzip压缩算法。
a2.sinks.k2.hdfs.fileType = CompressedStream
a2.sinks.k2.hdfs.codeC = gzip
# 组装
# 将数据源、通道和数据接收器组装在一起,形成一个完整的Flume agent。
a2.sources.r2.channels=c2
a2.sinks.k2.channel=c2
这个配置文件定义了一个Flume agent,它从Kafka中读取数据,通过文件通道进行缓存,并最终将数据写入到HDFS中。在写入HDFS时,使用了压缩流格式,并对输出文件进行了gzip压缩。同时,还通过一些参数对文件的轮转进行了控制。
2、启动flume
1)创建flume启动脚本
f2.sh
vi /usr/bin/f2.sh
# 修改文件权限chmod777 /usr/bin/f2.sh
2)复制如下内容
#!/bin/bash#1. 判断参数个数if[$#-lt1]thenecho Not Enough Arguement!exit;ficase$1in"start")#遍历集群所有机器forhostin hadoop131
doecho -------------------- $host 日志收集 flume 启动 --------------------
ssh$host"nohup /data/flume/bin/flume-ng agent -n a2 -c /data/flume/conf/ -f /data/flume/conf/job/kafka_to_hdfs_log.conf >/dev/null 2>&1 &"done;;"stop")#遍历集群所有机器forhostin hadoop131
doecho -------------------- $host 日志收集 flume 停止 --------------------
ssh$host"ps -ef | grep kafka_to_hdfs_log | grep -v grep | awk '{print \$2}' |xargs -n1 kill 9"done;;
*)echo"Input Args Error...";;esac
3)通过集群脚本
f2.sh
操作
f2.sh start
flume启动命令说明
以下是flume启动命令的常用参数:
参数默认值说明
--name
或
-n
无默认值,必须指定指定启动的Flume Agent的名称。这个名称应该与配置文件中定义的agent的名称一致。
--conf
或
-c
无默认值,通常设置为flume配置文件的目录指定Flume配置文件的目录。这个目录下应该包含flume的配置文件。
--conf-file
或
-f
无默认值,必须指定指定具体的Flume配置文件名。这个文件应该包含了Flume Agent的配置信息。
--zkConnString
或
-z
无默认值当Flume配置使用Zookeeper进行集群管理时,指定Zookeeper的连接字符串。格式为主机名:端口号,多个节点用逗号分隔。
-Dflume.root.logger
无默认值,通常设置为
INFO,console
设置Flume的日志级别和输出方式。例如,
INFO,console
表示日志级别为INFO,并输出到控制台。也可以设置为输出到日志文件。
--no-reload-conf
false如果设置为true,那么Flume将不会重新加载配置文件,即使配置文件发生了变化。
--help
或
-h
无默认值显示帮助信息,列出所有可用的启动参数。
需要注意的是,Flume的启动参数可能会因版本和具体的使用场景而有所不同。上表中的参数是最常用的,但并不是所有的参数都在所有版本的Flume中都可用。在实际使用时,建议查阅对应版本的Flume官方文档或使用
flume-ng agent --help
命令查看可用的参数列表。
3、验证日志采集通路
1)在指定的log目录中生成日志文件
cat app.log >> /data/applog/log/app_test.log
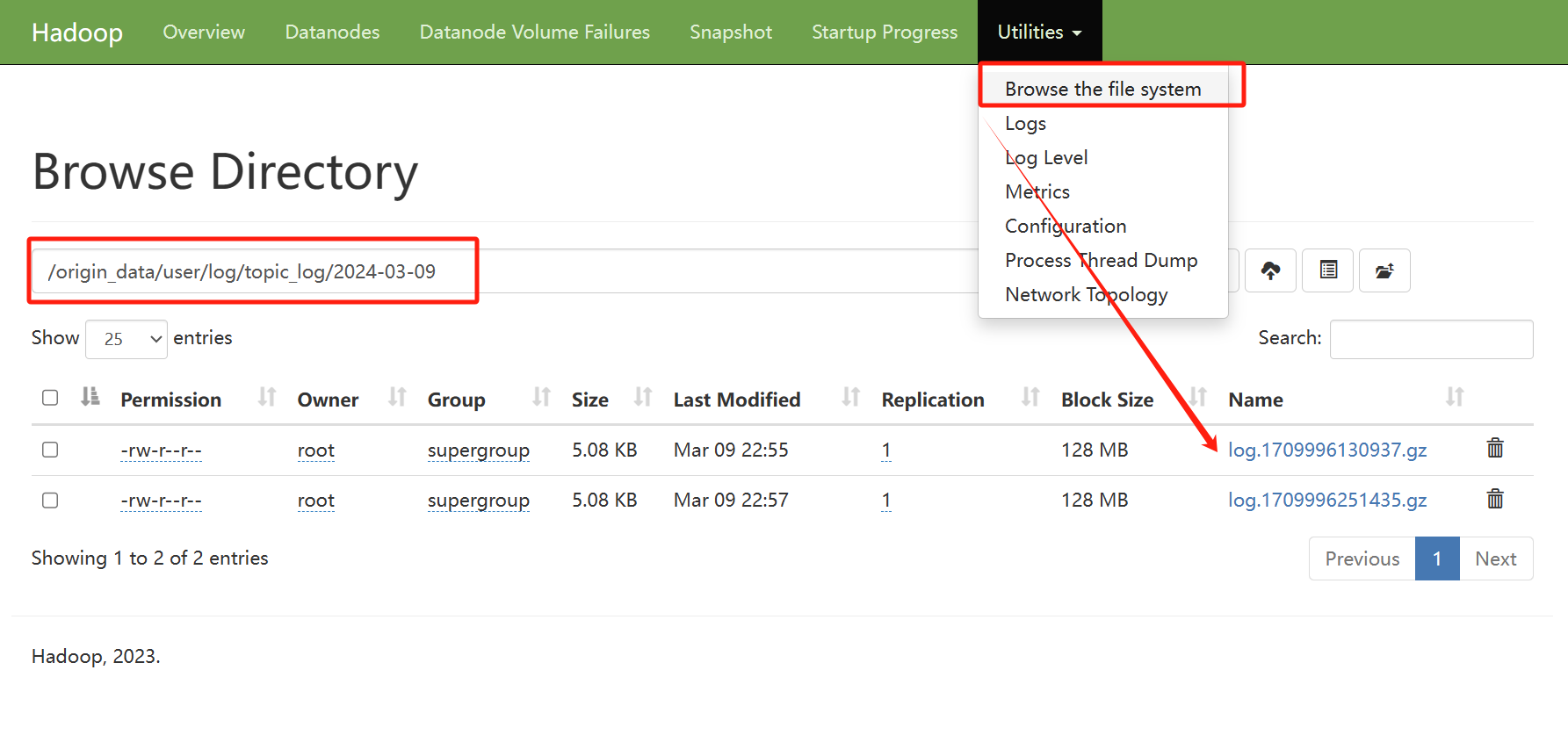
2)打开Hadoop查看数据,http://192.168.56.131:9870/
Hadoop在前面已经安装过
参考
版权归原作者 顽石九变 所有, 如有侵权,请联系我们删除。