
文章目录
1.简介
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume具备3大特性:
- 1.有一个简单,灵活,基于流的数据流结构
- 2.具有负载均衡机制和故障转移机制,能保证数据采集的稳定性和可靠性。
- 3.具有一个简单可扩展的数据模型(Source,Channel和Sink)
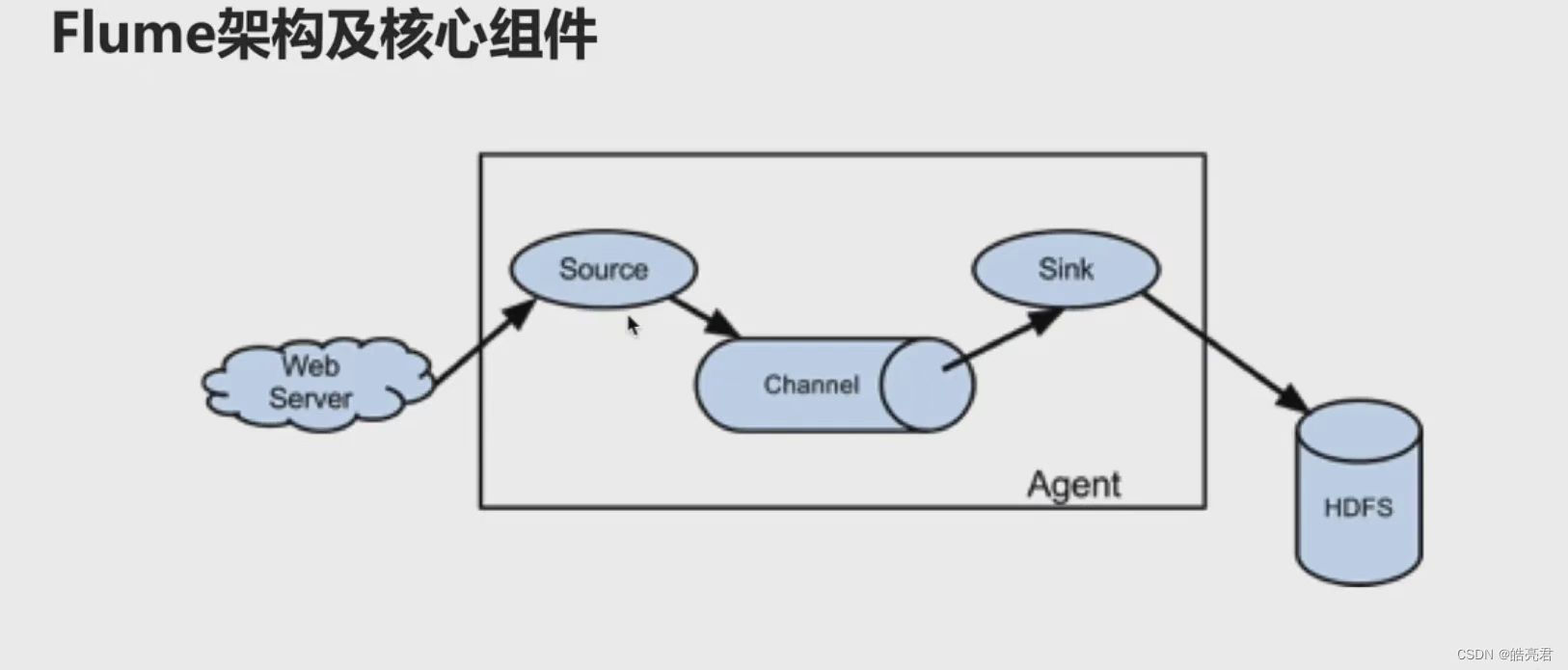
重上图可以看到,Agent是由Source,Channel和Sink这三大组件组成的。
- Source: 数据源(类似于Logstash的Input)。
- Channel: 临时存储数据的管道。
- Sink: 目的地(类似于Logstash的Output)。
2.核心三大组件
2.1.Source组件
通过Source可以指定读取哪里的数据,将数据传递给后面的Channel组件,以下为常用的数据源。
- Exec Source: 用于文件监控,可以实时监控文件中的新增内容,类似于tail -F的效果。
- NetCat TCP/UDP Source: 采集指定端口的数据,可以读取流经端口的每一行数据。
- Spooling Directory Source: 采集文件夹中新增的文件。
- Kafaka Source: 从Kafaka消息队列中采集数据。
2.2.Channel组件
接受Source发送的数据,可以把Channel理解为一个临时存储数据的管道,以下为常用的渠道类型。
- File Channel: 使用文件来作为数据的存储介质。优点是数据不会丢失,缺点是相对内存效率有的慢。
- Memory Channel: 使用内存作为数据的存储接受,优点效率高,缺点会丢失数据,会存在内存不足的情况。
- Spillable Memory Channel: 使用内存和文件作为存储介质,即内存足够把数据存内存中,不足的时候再写入到文件中。
2.3.Sink组件
Sink从Channel中读取数据并将其存储到指定目的地。以下为常见的类型:
- Logger Sink: 将数据作为日志处理,可以将其选择打印到控制台或写到文件中。
- HDFS Sink: 将数据传输到HDFS中,主要针对离线计算场景。
- Kafka Sink: 将数据传输到Kafka消息队列中,主要针对实时计算场景。
3.安装Flume
下载地址
本文下载的apache-flume-1.10.1-bin.tar.gz文件,对应的版本号是1.10.1。
上传到服务器/home/soft目录下然后解压文件。
cd /home/soft
tar-zxvf apache-flume-1.10.1-bin.tar.gz
修改环境变量配置文件名称
cd /home/soft/apache-flume-1.10.1-bin/conf
mv flume-env.sh.template flume-env.sh
4.采集数据测试
创建一个采集端口数据的配置文件
vi /home/soft/apache-flume-1.10.1-bin/conf/netcat.conf
文件内容如下
# 定义Agent内部3大组件的名称
a1.sources=r1
a1.sinks=k1
a1.channels=c1
# 配置Souce组件
#使用采集端口数据
a1.sources.r1.type=netcat
#指定当前机器Ip地址或主机名,0.0.0.0表示通用的机器ip
a1.sources.r1.bind=0.0.0.0
#指定一个未被使用的端口,用于监控当前端口的数据
a1.sources.r1.port=6666
#配置Channel组件
#使用内存存储数据
a1.channels.c1.type=memory
#event条数
a1.channels.c1.capacity=1000
#flume事务控制所需要的缓存容量600条event
a1.channels.c1.transactionCapacity=100
#配置Sink组件
#数据输出到日志中
a1.sinks.k1.type=logger
#将三大组件绑定到一起
#为名称为r1的数据源绑定输出渠道
a1.sources.r1.channels=c1
#为名称为k1的输出源绑定输入渠道
a1.sinks.k1.channel=c1
启动Agent(需要配置JAVA_HOME才能启动)
cd /home/soft/apache-flume-1.10.1-bin
bin/flume-ng agent -n a1 -c conf -f conf/netcat.conf -Dflume.root.logger=INFO,console
参数说明agent启动一个Flume的Agent代理,(参数后面的a1对应着上面配置文件中的a1)。-n指定Agent的名称(等同于 --name)-c指定Flume配置文件根目录(等同于 --conf)-f指定Agent配置文件的位置。(等同于 --conf-file)
控制台输出如下
启动另外一个终端查看实时日志
tail-f /home/soft/apache-flume-1.10.1-bin/flume.log
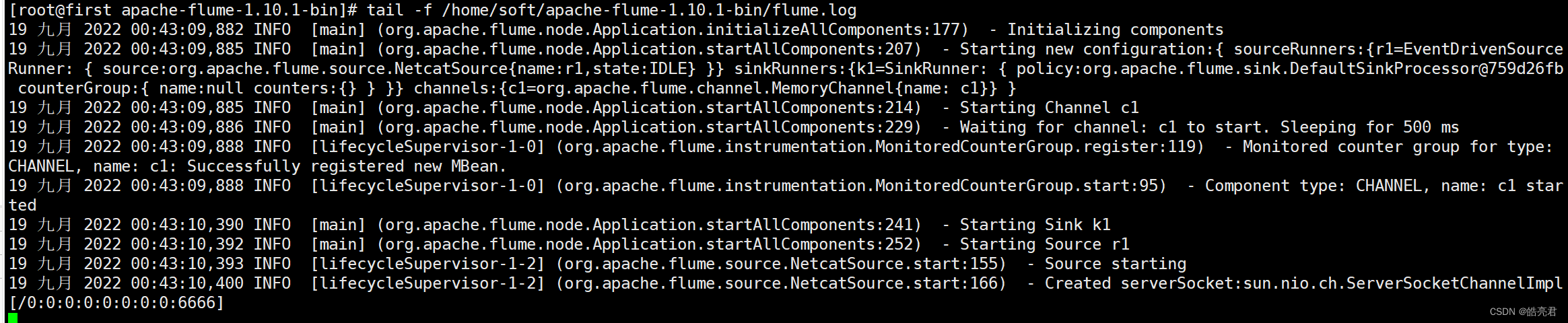
可以看到已经创建了一个Socket监听6666端口数据。
用telnet测试
telnet 127.0.0.1 6666
连接成功后输入helloword然后回车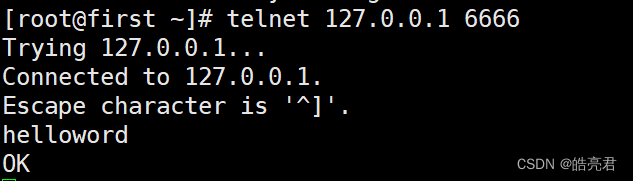
查看/home/soft/apache-flume-1.10.1-bin/flume.log文件
cat /home/soft/apache-flume-1.10.1-bin/flume.log
可以看到日志里打印了helloword信息
5.日志汇总到HDFS中
主机名IP地址A192.168.239.130B192.168.239.129C192.168.239.128
需求: 把A和B两台机器的日志数据汇总到主机C上,通过主机C将数据输出到HDFS的指定目录下。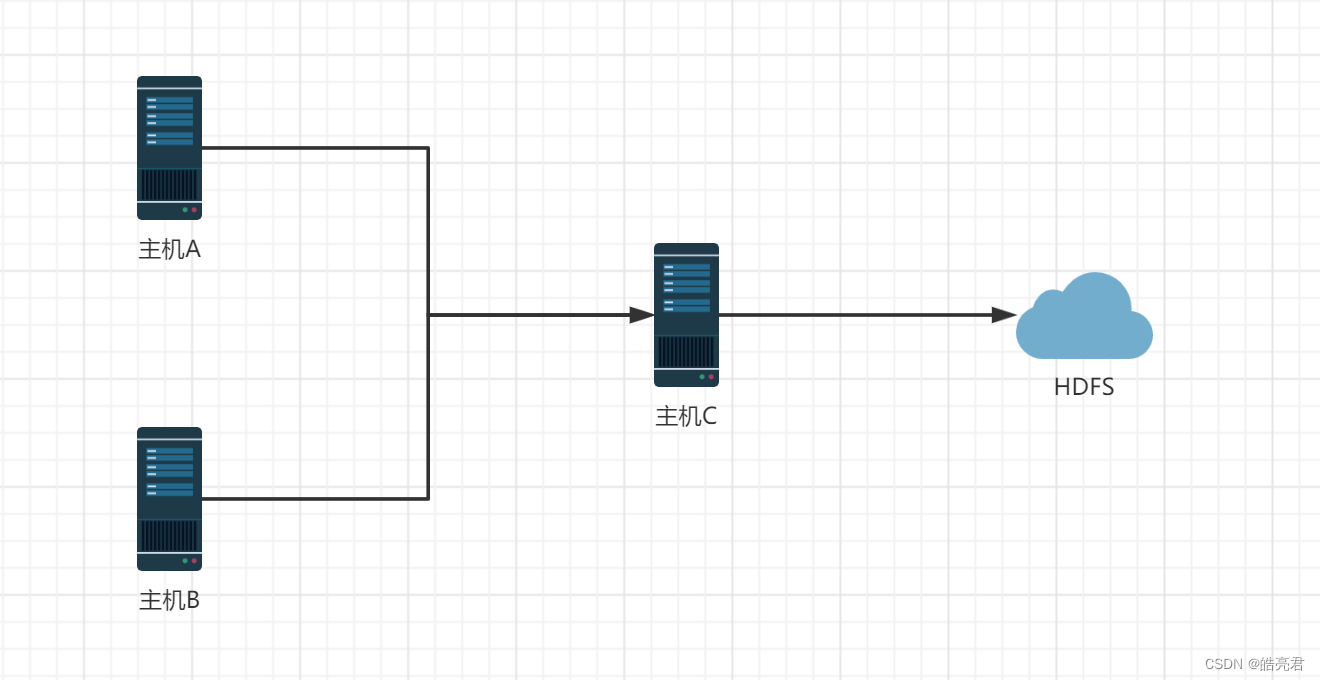
- 机器A和B因为要读取文件中数据,所以使用基于文件的Exec Source,Channel使用基于内存的Momory Channel,发送数据使用了Avro Sink。
- 机器C的数据使用Avro Source(Avro Sink和Avro Source是一组工具配合使用)
5.1.日志收集服务配置
编辑机器A和B共用的上传日志的配置file-to-avro.conf
- a1.sinks.k1.hostname=机器C的ip地址
- tail -F /home/soft/apache-flume-1.10.1-bin/logs/access.log 读取日志文件里的实时数据
vi /home/soft/apache-flume-1.10.1-bin/conf/file-to-avro.conf
# 定义Agent内部3大组件的名称a1.sources=r1
a1.channels=c1
a1.sinks=k1
# 配置Souce组件#设置数据重文件中读取a1.sources.r1.type=exec
a1.sources.r1.command=tail -F /home/soft/apache-flume-1.10.1-bin/logs/access.log
#配置Channel组件#使用内存存储数据a1.channels.c1.type=memory
#event条数a1.channels.c1.capacity=1000#flume事务控制所需要的缓存容量100条eventa1.channels.c1.transactionCapacity=100#配置Sink组件a1.sinks.k1.type=avro
a1.sinks.k1.hostname=192.168.239.128
a1.sinks.k1.port=45454#将三大组件绑定到一起#为名称为r1的数据源绑定输出渠道a1.sources.r1.channels=c1
#为名称为k1的输出源绑定输入渠道 a1.sinks.k1.channel=c1
生成测试数据的脚本
vi /home/soft/apache-flume-1.10.1-bin/logs/generate_log.sh
#!/bin/bashwhile["1"="1"]do#获取当前时间curr_time=`date +%s`#获取主机名称name=`hostname`echo${name}_${curr_time}>>/home/soft/apache-flume-1.10.1-bin/logs/access.log
sleep100done
保存退出后执行
chmod755 generate_log.sh
./generate_log.sh
运行完可以查到/home/soft/apache-flume-1.10.1-bin/logs/access.log日志有测试数据了。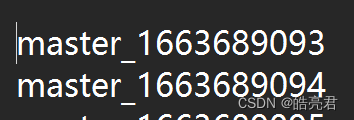
5.2.日志汇总服务配置
编辑机器C的接受数据和上传到HDFS的配置file-to-hdfs.conf
- 需要把a1.sinks.k1.hdfs.path: a1.sinks.k1.hdfs.path中的127.0.0.1换成hdfs部署机器ip地址
- 已在机器C上面安装好hadoop
vi /home/soft/apache-flume-1.10.1-bin/conf/file-to-hdfs.conf
# 定义Agent内部3大组件的名称a1.sources=r1
a1.channels=c1
a1.sinks=k1
# 配置Souce组件#设置数据重文件中读取a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=45454#配置Channel组件#使用内存存储数据a1.channels.c1.type=memory
#event条数a1.channels.c1.capacity=1000#flume事务控制所需要的缓存容量100条eventa1.channels.c1.transactionCapacity=100#配置Sink组件#采集到的数据写入到hdfs上,需要修改127.0.0.1换成你自己的hdfs部署地址a1.sinks.k1.type=hdfs
#配置上传到hdfs路径
a1.sinks.k1.hdfs.path = hdfs://127.0.0.1:9000/access/%y-%m-%d
# 指定在hdfs上生成的文件名前缀
a1.sinks.k1.hdfs.filePrefix = access
#生成的文件类型,默认是Sequencefile;可选DataStream,则为普通文本;可选CompressedStream压缩数据
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat=Text
# 每x秒生成一个文件,默认30秒,如果设置成0,则表示不根据时间来滚动文件;
a1.sinks.k1.hdfs.rollInterval =60# 每x字节,滚动生成一个文件;默认1024 (0 = 表示不根据临时文件大小来滚动文件)
a1.sinks.k1.hdfs.rollSize =0# 每x个event,滚动生成一个文件;默认10 (0 = 不根据事件滚动)
a1.sinks.k1.hdfs.rollCount =0# 使用本地时间
a1.sinks.k1.hdfs.useLocalTimeStamp =true#为名称为r1的数据源绑定输出渠道a1.sources.r1.channels=c1
#为名称为k1的输出源绑定输入渠道 a1.sinks.k1.channel=c1
5.3.运行服务测试
使用scp复制flume安装包到机器A和B上面,A和B机器的/home/soft目录必须先创建好
scp-rq /home/soft/apache-flume-1.10.1-bin 192.168.239.129:/home/soft/
scp-rq /home/soft/apache-flume-1.10.1-bin 192.168.239.130:/home/soft/
在机器A和B上面运行flume服务
cd /home/soft/apache-flume-1.10.1-bin
bin/flume-ng agent -n a1 -c conf -f conf/file-to-avro.conf -Dflume.root.logger=INFO,console
A和B都需要开启另外一个终端执行生产测试数据的日志的脚本
/home/soft/apache-flume-1.10.1-bin/logs/generate_log.sh
在机器C上面运行flume服务
cd /home/soft/apache-flume-1.10.1-bin
bin/flume-ng agent -n a1 -c conf -f conf/file-to-hdfs.conf -Dflume.root.logger=INFO,console
下面报错是flume采集数据上传到hdfs报的错误,
这是因为flume内依赖的guava.jar和hadoop内的版本不一致造成的。
查看hadoop安装目录下share/hadoop/common/lib内guava.jar版本
查看flume安装目录下lib内guava.jar的版本
如果两者不一致,删除版本低的,并拷贝高版本过去。
ctrl退出机器C的flume服务,重新执行机器C启动flume的命令。
查看hdfs文件系统里是否有flume服务上传日志文件
cd /home/soft/hadoop-3.2.4/bin
./hdfs dfs -ls-R /access

查看日志文件内容
./hdfs dfs -cat /access/22-09-20/access.1663687662824
可以看到日志里面能看到两台主机生产日志合并后的数据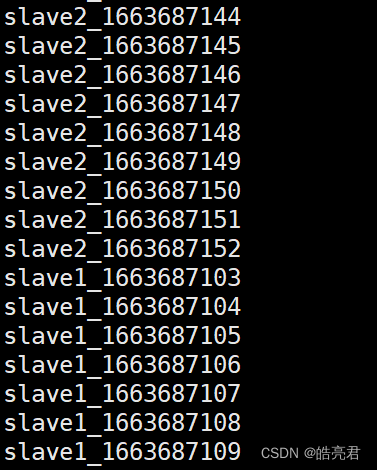
【Hadoop生态圈】其它文章如下,后续会继续更新。
- 1.Hadoop入门教程及集群环境搭建
- 2.使用Flume采集日志数据到HDFS中
- 3.Zookeeper入门教程及集群环境搭建
- 4.Kafka入门教程及集群环境搭建
- 5.HBase列存储数据库入门教程及集群环境搭建
- 6.MapReduce离线计算引擎入门教程
- 7.离线OLAP引擎Hive入门教程
- 8.Flink实时计算引擎入门教程
- 9.使用Maxwell实时采集MySQL数据到Kafka中
- 10.使用Sqoop迁移MySQL数据到HDFS中
版权归原作者 皓亮君 所有, 如有侵权,请联系我们删除。